
Począwszy od wersji 6.14, Studio Amazon EMR obsługuje interaktywne analizy wł Bezserwerowe Amazon EMR. Możesz teraz używać aplikacji EMR Serverless jako zasobów obliczeniowych, oprócz Amazon EMR w klastrach EC2 i Amazon EMR na EKS klastry wirtualne do uruchamiania notatników JupyterLab z obszarów roboczych EMR Studio.
EMR Studio to zintegrowane środowisko programistyczne (IDE), które ułatwia analitykom i inżynierom danych tworzenie, wizualizację i debugowanie aplikacji analitycznych napisanych w językach PySpark, Python i Scala. EMR Serverless to opcja bezserwerowa dla Amazon EMR dzięki temu uruchamianie platform analizy dużych zbiorów danych typu open source, takich jak Apache Spark, jest proste, bez konieczności konfigurowania, zarządzania i skalowania klastrów lub serwerów.
W poście pokazujemy, jak wykonać następujące czynności:
- Utwórz bezserwerowy punkt końcowy EMR dla aplikacji interaktywnych
- Podłącz punkt końcowy do istniejącego środowiska EMR Studio
- Utwórz notatnik i uruchom interaktywną aplikację
- Bezproblemowo diagnozuj aplikacje interaktywne z poziomu EMR Studio
Wymagania wstępne
W typowej organizacji administrator konta AWS skonfiguruje zasoby AWS, takie jak Zarządzanie tożsamością i dostępem w AWS (IAM) role, Usługa Amazon Simple Storage (Amazon S3) łyżki i Wirtualna prywatna chmura Amazon Zasoby (Amazon VPC) umożliwiające dostęp do Internetu i dostęp do innych zasobów w VPC. Przydzielają administratorów EMR Studio, którzy zarządzają konfiguracją EMR Studios i przypisywaniem użytkowników do konkretnego EMR Studio. Po przypisaniu programiści EMR Studio mogą używać EMR Studio do tworzenia i monitorowania obciążeń.
Upewnij się, że skonfigurowałeś zasoby, takie jak zasobnik S3, podsieci VPC i EMR Studio w tym samym regionie AWS.
Wykonaj następujące kroki, aby wdrożyć te wymagania wstępne:
- Uruchom następujące Tworzenie chmury AWS stos.

- Wprowadź wartości dla Hasło administratora i Hasło dewelopera i zanotuj utworzone hasła.
- Dodaj Następna.
- Zachowaj ustawienia domyślne i wybierz Następna ponownie.
- Wybierz Potwierdzam, że AWS CloudFormation może tworzyć zasoby IAM o niestandardowych nazwach.
- Wybierz opcję Prześlij.
Udostępniliśmy także instrukcje dotyczące ręcznego wdrażania tych zasobów przy użyciu przykładowych zasad uprawnień w pliku GitHub repo.
Skonfiguruj EMR Studio i interaktywną aplikację bezserwerową
Gdy administrator konta AWS spełni wymagania wstępne, administrator EMR Studio może zalogować się do Konsola zarządzania AWS aby utworzyć aplikację EMR Studio, Workspace i EMR Serverless.
Utwórz studio i przestrzeń roboczą EMR
Administrator EMR Studio powinien zalogować się do konsoli za pomocą komendy emrs-interactive-app-admin-user Poświadczenia użytkownika. Jeśli wdrożyłeś wstępnie wymagane zasoby przy użyciu dostarczonego szablonu CloudFormation, użyj hasła podanego jako parametru wejściowego.
- W konsoli Amazon EMR wybierz EMR bez serwera w okienku nawigacji.

- Dodaj Rozpocznij.
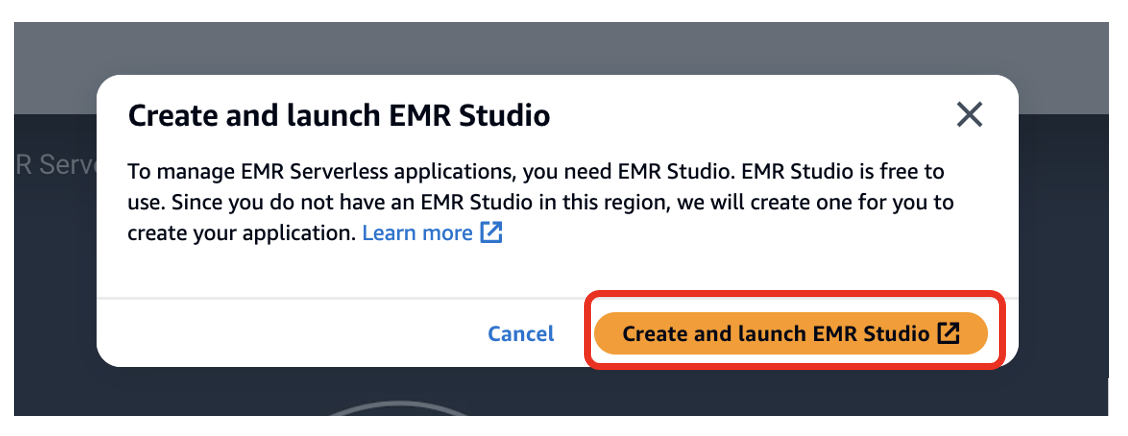
- Wybierz Utwórz i uruchom EMR Studio.
Spowoduje to utworzenie Studio z domyślną nazwą studio_1 oraz obszar roboczy z domyślną nazwą My_First_Workspace. Otworzy się nowa karta przeglądarki Studio_1 interfejs użytkownika.
Utwórz aplikację bezserwerową EMR
Wykonaj następujące kroki, aby utworzyć aplikację EMR Serverless:
- W konsoli EMR Studio wybierz Konsultacje w okienku nawigacji.
- Stwórz nową aplikację.
- W razie zamówieenia projektu Imięwprowadź nazwę (na przykład
my-serverless-interactive-application). - W razie zamówieenia projektu Opcje konfiguracji aplikacji, Wybierz Użyj ustawień niestandardowych do zadań interaktywnych.
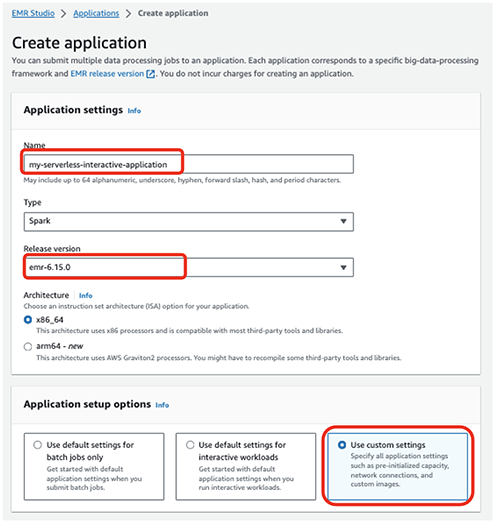
W przypadku aplikacji interaktywnych jako najlepszą praktykę zalecamy wstępną inicjalizację sterownika i procesów roboczych poprzez skonfigurowanie pliku wstępnie zainicjowana pojemność w momencie tworzenia aplikacji. To skutecznie tworzy ciepłą pulę procesów roboczych dla aplikacji i utrzymuje zasoby gotowe do użycia, umożliwiając aplikacji reakcję w ciągu kilku sekund. Dalsze najlepsze praktyki dotyczące tworzenia aplikacji EMR Serverless można znaleźć w artykule Zdefiniuj limity zasobów na zespół dla obciążeń Big Data za pomocą Amazon EMR Serverless.
- W Interaktywny punkt końcowy sekcja, wybierz Włącz interaktywny punkt końcowy.
- W Połączenia sieciowe wybierz utworzoną wcześniej sieć VPC, podsieci prywatne i grupę zabezpieczeń.
Jeśli wdrożyłeś stos CloudFormation podany w tym poście, wybierz emr-serverless-sg jako grupa bezpieczeństwa.
Aby obciążenie mogło uzyskać dostęp do Internetu z poziomu aplikacji EMR Serverless w celu pobrania zewnętrznych pakietów Pythona, wymagana jest platforma VPC. VPC umożliwia także dostęp do zasobów takich jak Usługa relacyjnych baz danych Amazon (Amazon RDS) i Amazonka Przesunięcie ku czerwieni które znajdują się w VPC z tej aplikacji. Podłączenie aplikacji bezserwerowej do VPC może prowadzić do wyczerpania adresu IP w podsieci, dlatego upewnij się, że w Twojej podsieci jest wystarczająca liczba adresów IP.
- Dodaj Utwórz i uruchom aplikację.

Na stronie aplikacji możesz sprawdzić, czy stan aplikacji bezserwerowej zmienia się na Rozpoczęty.
- Wybierz swoją aplikację i wybierz Jak to działa?.
- Dodaj Przeglądaj i uruchamiaj obszary robocze.
- Dodaj Skonfiguruj studio.

- W razie zamówieenia projektu Rola usługi¸ jako warunek wstępny podaj utworzoną rolę usługi EMR Studio (
emr-studio-service-role). - W razie zamówieenia projektu Przechowywanie przestrzeni roboczej, jako warunek wstępny wprowadź ścieżkę do segmentu S3, który utworzyłeś (
emrserverless-interactive-blog-<account-id>-<region-name>). - Dodaj Zapisz zmiany.
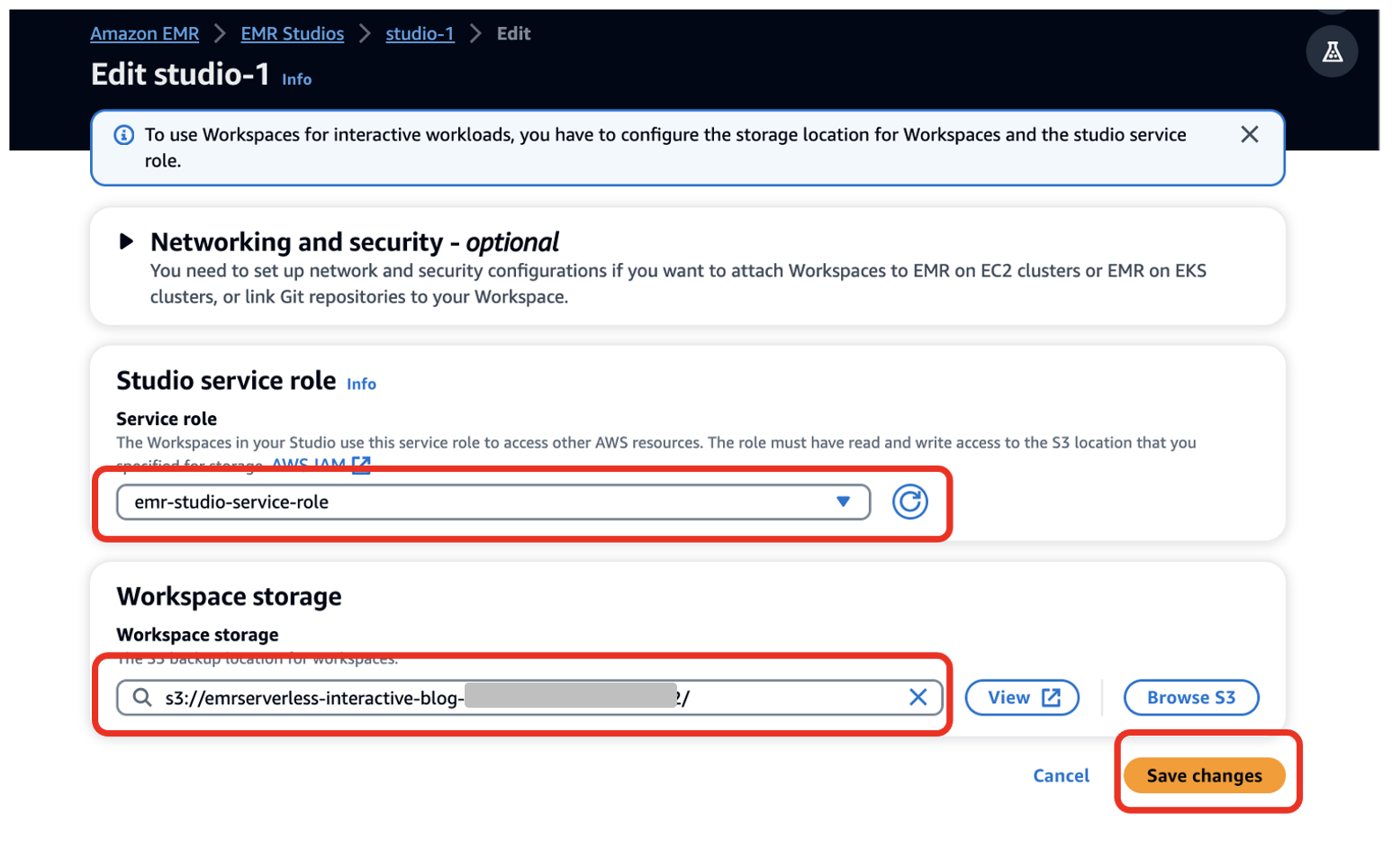
14. Przejdź do konsoli Studios, wybierając Studios w lewym menu nawigacyjnym w Studio EM Sekcja. Zanotuj Adres URL dostępu do studia z konsoli Studios i udostępnij ją programistom, aby mogli uruchamiać aplikacje Spark.
Uruchom swoją pierwszą aplikację Spark
Po utworzeniu przez administratora EMR Studio aplikacji Studio, Workspace i aplikacji bezserwerowej użytkownik Studio może używać Workspace i aplikacji do tworzenia i monitorowania obciążeń Spark.
Uruchom obszar roboczy i podłącz aplikację bezserwerową
Wykonaj następujące kroki:
- Korzystając z adresu URL Studio podanego przez administratora EMR Studio, zaloguj się przy użyciu
emrs-interactive-app-dev-userpoświadczenia użytkownika udostępnione przez administratora konta AWS.
Jeśli wdrożyłeś wstępnie wymagane zasoby przy użyciu dostarczonego szablonu CloudFormation, użyj hasła podanego jako parametru wejściowego.
Na Przestrzenie robocze możesz sprawdzić stan swojego obszaru roboczego. Po uruchomieniu Workspace zobaczysz zmianę statusu na Gotowy.
- Uruchom obszar roboczy, wybierając nazwę obszaru roboczego (
My_First_Workspace).
Spowoduje to otwarcie nowej karty. Upewnij się, że Twoja przeglądarka zezwala na wyskakujące okienka.
- W obszarze roboczym wybierz obliczać (ikona klastra) w panelu nawigacji.
- W razie zamówieenia projektu Aplikacja bezserwerowa EMR, wybierz swoją aplikację (
my-serverless-interactive-application). - W razie zamówieenia projektu Interaktywna rola środowiska uruchomieniowego, wybierz interaktywną rolę środowiska wykonawczego (w tym poście używamy
emr-serverless-runtime-role). - Dodaj Dołączać aby dołączyć aplikację bezserwerową jako typ obliczeń dla wszystkich notesów w tym obszarze roboczym.

Uruchom aplikację Spark interaktywnie
Wykonaj następujące kroki:
- Wybierz Próbki notatników (ikona trzech kropek) w panelu nawigacji i otwórz
Getting-started-with-emr-serverlessnotatnik. - Dodaj Zapisz w obszarze roboczym.
Istnieją trzy możliwości wyboru jądra dla naszego notebooka: Python 3, PySpark i Spark (dla Scali).
- Po wyświetleniu monitu wybierz PySpark jako jądro.
- Dodaj Wybierz.

Teraz możesz uruchomić aplikację Spark. Aby to zrobić, użyj %%configure Iskramagia polecenie, które konfiguruje parametry tworzenia sesji. Aplikacje interaktywne obsługują środowiska wirtualne Python. Używamy niestandardowego środowiska w węzłach roboczych, określając ścieżkę do innego środowiska wykonawczego Pythona dla środowiska wykonawczego za pomocą spark.executorEnv.PYSPARK_PYTHON. Zobacz następujący kod:
Zainstaluj pakiety zewnętrzne
Teraz, gdy masz niezależne środowisko wirtualne dla pracowników, notebooki EMR Studio umożliwiają instalowanie pakietów zewnętrznych z poziomu aplikacji bezserwerowej za pomocą platformy Spark install_pypi_package działać poprzez kontekst Spark. Użycie tej funkcji sprawia, że pakiet jest dostępny dla wszystkich pracowników EMR Serverless.
Najpierw zainstaluj matplotlib, pakiet Pythona, z PyPi:
Jeśli poprzedni krok nie odpowiada, sprawdź konfigurację VPC i upewnij się, że jest ona poprawnie skonfigurowana pod kątem dostępu do Internetu.
Teraz możesz korzystać ze zbioru danych i wizualizować swoje dane.
Twórz wizualizacje
Do tworzenia wizualizacji korzystamy z publicznego zbioru danych na temat żółtych taksówek w Nowym Jorku:
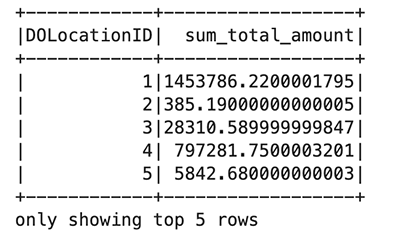
W poprzednim bloku kodu czytasz plik Parquet z publicznego segmentu w Amazon S3. Plik ma nagłówki i chcemy, aby Spark wywnioskował schemat. Następnie używasz ramki danych Spark do grupowania i zliczania określonych kolumn taxi_df:
Zastosowanie %%display magic, aby wyświetlić wynik w formacie tabeli:

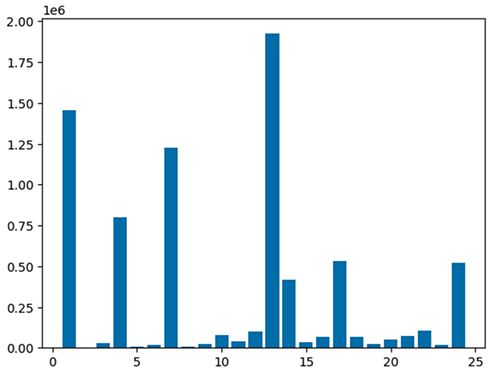
Możesz także szybko wizualizować swoje dane za pomocą pięciu typów wykresów. Możesz wybrać typ wyświetlania, a wykres zostanie odpowiednio zmieniony. Na poniższym zrzucie ekranu używamy wykresu słupkowego do wizualizacji naszych danych.

Wejdź w interakcję z EMR Serverless za pomocą Spark SQL
Możesz wchodzić w interakcję z tabelami w pliku Katalog danych kleju AWS przy użyciu Spark SQL na platformie EMR Serverless. W przykładowym notesie pokazujemy, jak można przekształcić dane za pomocą ramki danych Spark.
Najpierw utwórz nowy widok tymczasowy o nazwie taksówki. Dzięki temu można używać Spark SQL do wybierania danych z tego widoku. Następnie utwórz ramkę danych taksówki do dalszego przetwarzania:
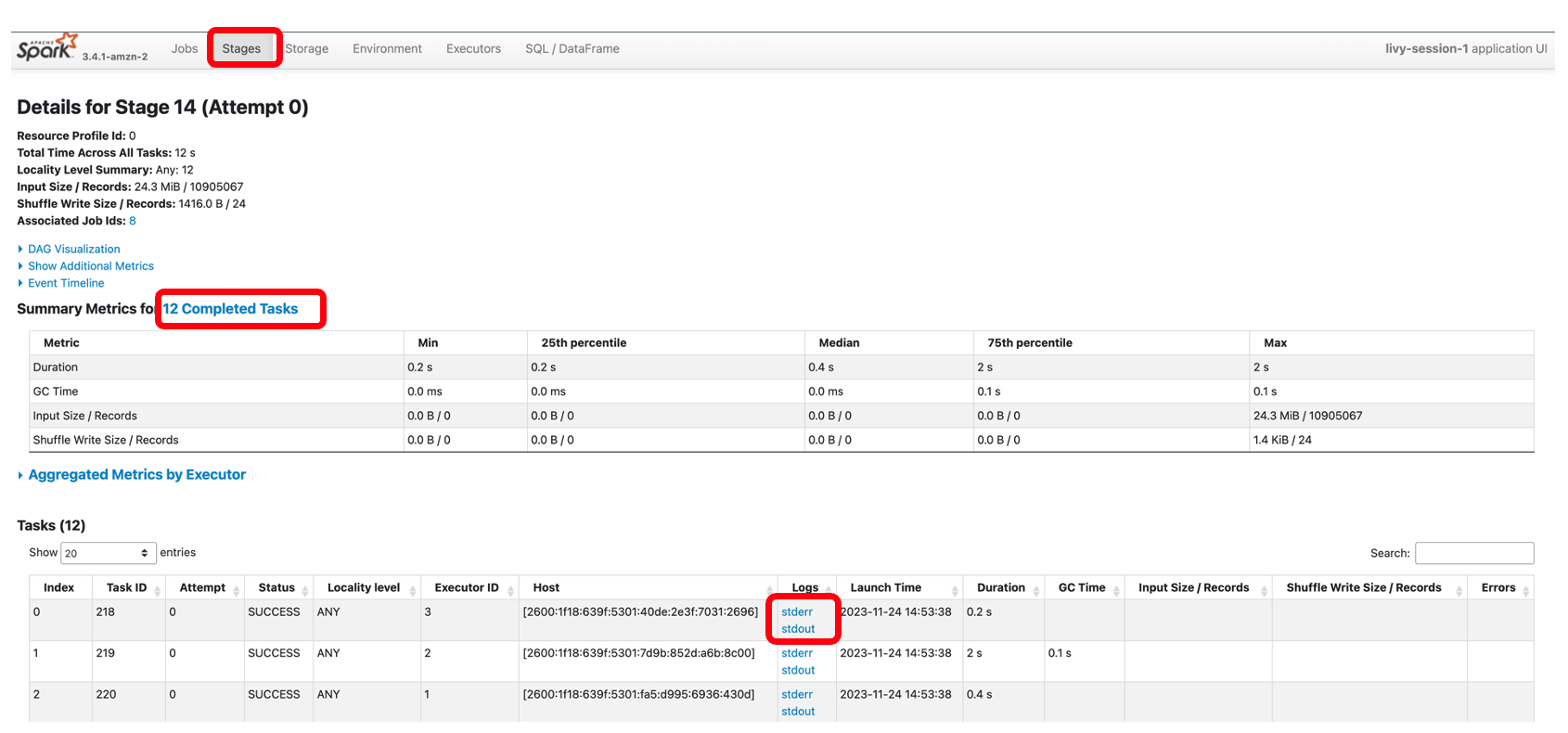
W każdej komórce w notatniku EMR Studio możesz rozwinąć Postęp pracy w trybie Spark aby wyświetlić różne etapy zadania przesłanego do EMR Serverless podczas uruchamiania tej konkretnej komórki. Możesz zobaczyć czas potrzebny na ukończenie każdego etapu. W poniższym przykładzie etap 14 zadania obejmuje 12 ukończonych zadań. Ponadto w przypadku jakiejkolwiek awarii można wyświetlić dzienniki, dzięki czemu rozwiązywanie problemów będzie przebiegać bezproblemowo. Omówimy to szerzej w następnej sekcji.
![Job[14]: showString w NativeMethodAccessorImpl.java:0 i Job[15]: showString w NativeMethodAccessorImpl.java:0](https://xlera8.com/wp-content/uploads/2024/04/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio-amazon-web-services-11.png)
Użyj poniższego kodu, aby zwizualizować przetworzoną ramkę danych przy użyciu pakietu matplotlib. Do wykreślenia lokalizacji zrzutu i całkowitej kwoty w postaci wykresu słupkowego służy biblioteka maptplotlib.
Diagnozuj aplikacje interaktywne
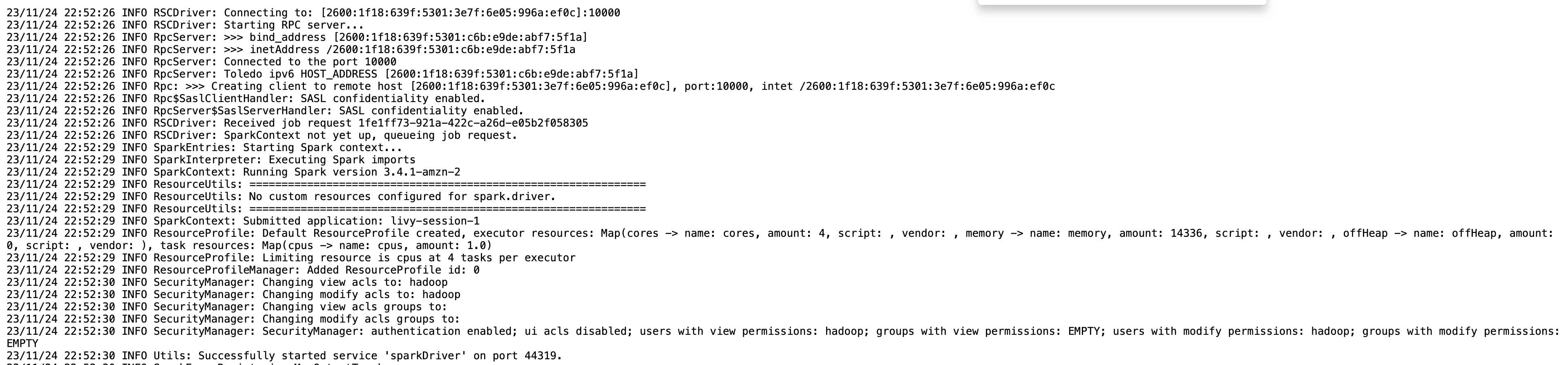
Informacje o sesji dla punktu końcowego usługi Livy można uzyskać za pomocą pliku %%info Iskramagia. Dzięki temu uzyskasz łącza umożliwiające dostęp do interfejsu użytkownika platformy Spark oraz dziennika sterowników bezpośrednio w notatniku.

Poniższy zrzut ekranu to fragment dziennika sterownika naszej aplikacji, który otworzyliśmy poprzez łącze w naszym notatniku.
Podobnie możesz wybrać poniższy link Interfejs Spark aby otworzyć interfejs użytkownika. Poniższy zrzut ekranu przedstawia Wykonawcy zakładka, która zapewnia dostęp do dzienników sterownika i modułu wykonawczego.

Poniższy zrzut ekranu przedstawia etap 14, który odpowiada etapowi Spark SQL, który widzieliśmy wcześniej, w którym obliczyliśmy sumę lokalizacji wszystkich taksówek, która została podzielona na 12 zadań. Dzięki interfejsowi Spark interaktywna aplikacja zapewnia szczegółowe informacje o stanie na poziomie zadania, operacjach we/wy i losowaniu, a także łącza do odpowiednich dzienników każdego zadania na tym etapie bezpośrednio z poziomu notebooka, umożliwiając bezproblemowe rozwiązywanie problemów.
Sprzątać
Jeśli nie chcesz już zachować zasobów utworzonych w tym poście, wykonaj następujące kroki czyszczenia:
- Usuń aplikację EMR Serverless.
- Usuń Studio EMR oraz powiązane obszary robocze i notesy.
- Aby usunąć resztę zasobów, przejdź do konsoli CloudFormation, wybierz stos i wybierz Usuń.
Wszystkie zasoby zostaną usunięte z wyjątkiem zasobnika S3, dla którego ustawiono zasady usuwania.
Wnioski
W poście pokazano, jak uruchamiać interaktywne obciążenia PySpark w EMR Studio przy użyciu EMR Serverless jako obliczeń. Możesz także tworzyć i monitorować aplikacje Spark w interaktywnym obszarze roboczym JupyterLab.
W nadchodzącym poście omówimy dodatkowe możliwości aplikacji EMR Serverless Interactive, takie jak:
- Praca z zasobami takimi jak Amazon RDS i Amazon Redshift w Twoim VPC (na przykład dla łączności JDBC/ODBC)
- Uruchamianie obciążeń transakcyjnych przy użyciu bezserwerowych punktów końcowych
Jeśli po raz pierwszy spotykasz się z EMR Studio, zalecamy sprawdzenie Warsztaty Amazon EMR i powołując się na Utwórz studio EMR.
O autorach
 Sekar Srinivasan jest głównym architektem rozwiązań specjalistycznych w AWS, specjalizującym się w analizie danych i sztucznej inteligencji. Sekar ma ponad 20-letnie doświadczenie w pracy z danymi. Pasjonuje się pomaganiem klientom w budowaniu skalowalnych rozwiązań, modernizując ich architekturę i generując wnioski z ich danych. W wolnym czasie lubi pracować nad projektami non-profit, skupiającymi się na edukacji dzieci upośledzonych.
Sekar Srinivasan jest głównym architektem rozwiązań specjalistycznych w AWS, specjalizującym się w analizie danych i sztucznej inteligencji. Sekar ma ponad 20-letnie doświadczenie w pracy z danymi. Pasjonuje się pomaganiem klientom w budowaniu skalowalnych rozwiązań, modernizując ich architekturę i generując wnioski z ich danych. W wolnym czasie lubi pracować nad projektami non-profit, skupiającymi się na edukacji dzieci upośledzonych.
 Disha Umarwani jest starszym architektem danych w Amazon Professional Services w działach Global Health Care i LifeSciences. Współpracowała z klientami przy projektowaniu, architekturze i wdrażaniu strategii danych na dużą skalę. Specjalizuje się w projektowaniu architektur Data Mesh dla platform Enterprise.
Disha Umarwani jest starszym architektem danych w Amazon Professional Services w działach Global Health Care i LifeSciences. Współpracowała z klientami przy projektowaniu, architekturze i wdrażaniu strategii danych na dużą skalę. Specjalizuje się w projektowaniu architektur Data Mesh dla platform Enterprise.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio/