
Przepływy pracy zarządzane przez Amazon dla Apache Airflow (Amazon MWAA) to zarządzana usługa orkiestracji dla Przepływ powietrza Apache których można używać do konfigurowania i obsługi potoków danych w chmurze na dużą skalę. Apache Airflow to narzędzie typu open source służące do programowego tworzenia, planowania i monitorowania sekwencji procesów i zadań, zwanych przepływów pracy. Dzięki Amazon MWAA możesz używać Apache Airflow i Python do tworzenia przepływów pracy bez konieczności zarządzania podstawową infrastrukturą pod kątem skalowalności, dostępności i bezpieczeństwa.
Korzystając z wielu kont AWS, organizacje mogą skutecznie skalować swoje obciążenia i zarządzać ich złożonością w miarę ich wzrostu. Takie podejście zapewnia solidny mechanizm łagodzenia potencjalnego wpływu zakłóceń lub awarii, zapewniając ciągłość działania krytycznych obciążeń. Dodatkowo umożliwia optymalizację kosztów poprzez dopasowywanie zasobów do konkretnych przypadków użycia, zapewniając dobrą kontrolę wydatków. Izolując obciążenia o określonych wymaganiach dotyczących bezpieczeństwa lub zgodności, organizacje mogą zachować najwyższy poziom prywatności i bezpieczeństwa danych. Co więcej, możliwość uporządkowania wielu kont AWS pozwala na dostosowanie procesów biznesowych i zasobów do unikalnych wymagań operacyjnych, regulacyjnych i budżetowych. Takie podejście promuje wydajność, elastyczność i skalowalność, umożliwiając dużym przedsiębiorstwom zaspokajanie ich zmieniających się potrzeb i osiąganie celów.
W tym poście pokazano, jak zaaranżować kompleksowe wyodrębnianie, przekształcanie i ładowanie potoku (ETL) przy użyciu Usługa Amazon Simple Storage (Amazonka S3), Klej AWS, Bezserwerowe Amazon Redshift z Amazonem MWAA.
Omówienie rozwiązania
W tym poście rozważamy przypadek użycia, w którym zespół inżynierów danych chce zbudować proces ETL i zapewnić użytkownikom końcowym najlepsze doświadczenia, gdy chcą zapytać o najnowsze dane po dodaniu nowych nieprzetworzonych plików do Amazon S3 w centrali konto (konto A na poniższym schemacie architektury). Zespół inżynierów danych chce oddzielić surowe dane na własne konto AWS (konto B na diagramie) w celu zwiększenia bezpieczeństwa i kontroli. Chcą także wykonywać prace związane z przetwarzaniem i transformacją danych na swoim własnym koncie (konto B), aby rozdzielić obowiązki i zapobiec niezamierzonym zmianom w surowych danych źródłowych znajdujących się na rachunku centralnym (konto A). Takie podejście pozwala zespołowi przetwarzać surowe dane pobrane z Konta A na Konto B, które jest dedykowane do zadań związanych z obsługą danych. Dzięki temu surowe i przetworzone dane można w razie potrzeby bezpiecznie przechowywać oddzielnie na wielu kontach, co zapewnia lepsze zarządzanie danymi i bezpieczeństwo.
Nasze rozwiązanie wykorzystuje kompleksowy potok ETL zaaranżowany przez Amazon MWAA, który wyszukuje nowe pliki przyrostowe w lokalizacji Amazon S3 na koncie A, gdzie obecne są surowe dane. Odbywa się to poprzez wywołanie zadań ETL AWS Glue i zapisanie do obiektów danych w klastrze Redshift Serverless na koncie B. Następnie rozpoczyna się działanie potoku procedury składowane i polecenia SQL w systemie Redshift Serverless. Gdy zapytania zakończą się, an ROZŁADOWAĆ operacja jest wywoływana z hurtowni danych Redshift do segmentu S3 na koncie A.
Ponieważ bezpieczeństwo jest ważne, w tym poście opisano również, jak skonfigurować połączenie Airflow za pomocą Menedżer tajemnic AWS aby uniknąć przechowywania poświadczeń bazy danych w połączeniach i zmiennych Airflow.
Poniższy diagram ilustruje przegląd architektury komponentów zaangażowanych w orkiestrację przepływu pracy.
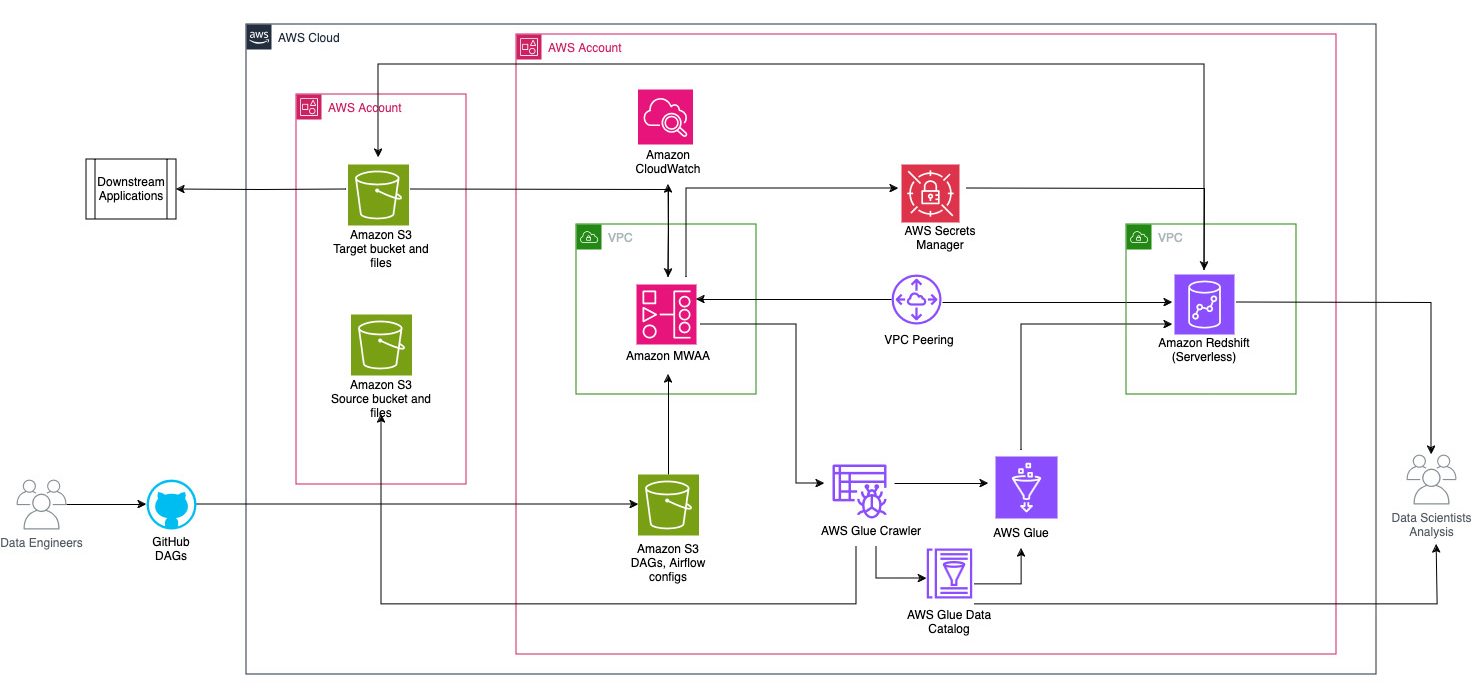
Przepływ pracy składa się z następujących elementów:
- Źródłowy i docelowy zasobnik S3 znajdują się na koncie centralnym (konto A), natomiast Amazon MWAA, AWS Glue i Amazon Redshift znajdują się na innym koncie (konto B). Skonfigurowano dostęp między kontami pomiędzy segmentami S3 na koncie A i zasobami na koncie B, aby móc ładować i rozładowywać dane.
- Na drugim koncie Amazon MWAA jest hostowany w jednym VPC, a Redshift Serverless w innym VPC, które są połączone poprzez peering VPC. Grupa robocza Redshift Serverless jest zabezpieczona w prywatnych podsieciach w trzech strefach dostępności.
- Sekrety takie jak nazwa użytkownika, hasło, port DB i region AWS dla Redshift Serverless są przechowywane w Menedżerze sekretów.
- Punkty końcowe VPC są tworzone dla Amazon S3 i Secrets Manager w celu interakcji z innymi zasobami.
- Zwykle inżynierowie danych tworzą acykliczny wykres ukierunkowany przepływem powietrza (DAG) i przesyłają swoje zmiany do GitHub. W przypadku akcji GitHub są one wdrażane w zasobniku S3 na koncie B (w tym poście przesyłamy pliki bezpośrednio do zasobnika S3). Wiadro S3 przechowuje pliki związane z przepływem powietrza, takie jak pliki DAG,
requirements.txtpliki i wtyczki. Skrypty i zasoby AWS Glue ETL są przechowywane w innym wiadrze S3. To oddzielenie pomaga utrzymać organizację i uniknąć zamieszania. - Airflow DAG wykorzystuje różnych operatorów, czujniki, połączenia, zadania i reguły do uruchamiania potoku danych w razie potrzeby.
- Dzienniki Airflow są zalogowane Amazon Cloud Watchi alerty można skonfigurować do zadań monitorowania. Aby uzyskać więcej informacji, zobacz Monitorowanie pulpitów nawigacyjnych i alarmów w Amazon MWAA.
Wymagania wstępne
Ponieważ to rozwiązanie koncentruje się wokół wykorzystania usługi Amazon MWAA do koordynowania potoku ETL, należy wcześniej skonfigurować pewne podstawowe zasoby na kontach. W szczególności musisz utworzyć segmenty i foldery S3, zasoby AWS Glue i zasoby Redshift Serverless na odpowiednich kontach przed wdrożeniem pełnej integracji przepływu pracy za pomocą Amazon MWAA.
Wdróż zasoby na koncie A przy użyciu AWS CloudFormation
Na koncie A uruchom dostarczone Tworzenie chmury AWS stos, aby utworzyć następujące zasoby:
- Źródłowe i docelowe zasobniki i foldery S3. Zgodnie z najlepszą praktyką struktury zasobników wejściowych i wyjściowych są formatowane przy użyciu partycjonowania w stylu gałęzi jako
s3://<bucket>/products/YYYY/MM/DD/. - Przykładowy zbiór danych o nazwie
products.csv, którego używamy w tym poście.
![]()
Prześlij zadanie klejenia AWS do Amazon S3 na koncie B
Na koncie B utwórz lokalizację Amazon S3 o nazwie aws-glue-assets-<account-id>-<region>/scripts (jeśli nie występuje). Zastąp parametry identyfikatora konta i regionu w pliku sample_glue_job.py skrypt i prześlij plik zadania AWS Glue do lokalizacji Amazon S3.
Wdróż zasoby na koncie B za pomocą AWS CloudFormation
Na koncie B uruchom dostarczony szablon stosu CloudFormation, aby utworzyć następujące zasoby:
- Łyżka S3
airflow-<username>-bucketdo przechowywania plików związanych z Airflow o następującej strukturze:- dagi – Folder plików DAG.
- wtyczki – Plik dowolnych niestandardowych lub społecznościowych wtyczek Airflow.
- wymagania -
requirements.txtplik dla dowolnych pakietów Pythona. - skrypty – Wszelkie skrypty SQL używane w DAG.
- dane – Wszelkie zbiory danych wykorzystywane w DAG.
- Środowisko bezserwerowe Redshift. Nazwa grupy roboczej i przestrzeni nazw są poprzedzone prefiksem
sample. - Środowisko AWS Glue, które zawiera:
- Klej AWS crawler, który przeszukuje dane z zasobnika źródłowego S3
sample-inp-bucket-etl-<username>na koncie A. - Baza danych tzw
products_dbw Katalogu danych kleju AWS. - ELT praca nazywa
sample_glue_job. To zadanie może czytać pliki zproductstabeli w katalogu danych i załaduj dane do tabeli przesunięcia ku czerwieniproducts.
- Klej AWS crawler, który przeszukuje dane z zasobnika źródłowego S3
- Punkt końcowy bramy VPC do Amazon S3.
- Środowisko Amazon MWAA. Szczegółowe instrukcje dotyczące tworzenia środowiska Amazon MWAA przy użyciu konsoli Amazon MWAA można znaleźć w artykule Przedstawiamy przepływy pracy zarządzane przez Amazon dla Apache Airflow (MWAA).
![]()
Twórz zasoby Amazon Redshift
Utwórz dwie tabele i procedurę składowaną w grupie roboczej Redshift Serverless za pomocą produkty.sql plik.
W tym przykładzie tworzymy dwie tabele o nazwie products i products_f. Nazwa procedury składowanej to sp_products.
Skonfiguruj uprawnienia przepływu powietrza
Po pomyślnym utworzeniu środowiska Amazon MWAA status będzie wyświetlany jako Dostępny, Wybierać Otwórz interfejs przepływu powietrza , aby wyświetlić interfejs Airflow. DAG są automatycznie synchronizowane z segmentu S3 i widoczne w interfejsie użytkownika. Jednak na tym etapie w folderze S3 nie ma żadnych DAG-ów.
Dodaj zasady zarządzane przez klienta AmazonMWAAFullConsoleAccess, który przyznaje użytkownikom Airflow uprawnienia dostępu AWS Zarządzanie tożsamością i dostępem (IAM) i dołącz tę politykę do roli Amazon MWAA. Aby uzyskać więcej informacji, zobacz Dostęp do środowiska Amazon MWAA.
Zasady powiązane z rolą Amazon MWAA mają pełny dostęp i można ich używać wyłącznie do celów testowych w bezpiecznym środowisku testowym. W przypadku wdrożeń produkcyjnych postępuj zgodnie z zasadą najmniejszych uprawnień.
Skonfiguruj środowisko
W tej sekcji opisano kroki konfigurowania środowiska. Proces obejmuje następujące etapy wysokiego poziomu:
- Zaktualizuj wszystkich niezbędnych dostawców.
- Skonfiguruj dostęp dla wielu kont.
- Ustanów połączenie równorzędne VPC pomiędzy Amazon MWAA VPC i Amazon Redshift VPC.
- Skonfiguruj Menedżera sekretów do integracji z Amazon MWAA.
- Zdefiniuj połączenia przepływu powietrza.
Zaktualizuj dostawców
Wykonaj kroki opisane w tej sekcji, jeśli Twoja wersja Amazon MWAA jest starsza niż 2.8.1 (najnowsza wersja w momencie pisania tego posta).
Dostawcy to pakiety utrzymywane przez społeczność i zawierające wszystkich podstawowych operatorów, haczyki i czujniki dla danej usługi. Dostawca Amazon jest używany do interakcji z usługami AWS, takimi jak Amazon S3, Amazon Redshift Serverless, AWS Glue i nie tylko. W ramach dostawcy Amazon istnieje ponad 200 modułów.
Chociaż wersja Airflow obsługiwana w Amazon MWAA to 2.6.3 i jest dołączona do pakietu dostarczonego przez Amazon w wersji 8.2.0, obsługa Amazon Redshift Serverless została dodana dopiero w pakiecie dostarczonym przez Amazon w wersji 8.4.0. Ponieważ domyślna wersja dostawcy w pakiecie jest starsza niż w momencie wprowadzenia obsługi Redshift Serverless, wersja dostawcy musi zostać uaktualniona, aby móc korzystać z tej funkcjonalności.
Pierwszym krokiem jest aktualizacja pliku ograniczeń i requirements.txt plik z poprawnymi wersjami. Odnosić się do Określanie nowszych pakietów dostawców aby zapoznać się z instrukcjami aktualizacji pakietu dostawcy Amazon.
- Określ wymagania w następujący sposób:
- Zaktualizuj wersję w pliku ograniczeń do wersji 8.4.0 lub nowszej.
- Dodaj ograniczenia-3.11-updated.txt plik do
/dagsteczka.
Odnosić się do Wersje Apache Airflow w Amazon Managed Workflows dla Apache Airflow dla poprawnych wersji pliku ograniczeń w zależności od wersji Airflow.
- Przejdź do środowiska Amazon MWAA i wybierz Edytuj.
- Pod Kod DAG w Amazon S3, Dla Plik wymagań, wybierz najnowszą wersję.
- Dodaj Zapisz.
Spowoduje to aktualizację środowiska i włączenie nowych dostawców.
- Aby zweryfikować wersję dostawcy, przejdź do Dostawcy pod Admin tabela.
Wersja pakietu dostawcy Amazon powinna być 8.4.0, jak pokazano na poniższym zrzucie ekranu. Jeśli nie, wystąpił błąd podczas ładowania requirements.txt. Aby debugować błędy, przejdź do konsoli CloudWatch i otwórz plik requirements_install_ip Zaloguj Się Rejestruj strumienie, gdzie wyszczególnione są błędy. Odnosić się do Włączanie logów na konsoli Amazon MWAA by uzyskać więcej szczegółów.

Skonfiguruj dostęp dla wielu kont
Aby uzyskać dostęp do zasobników S3 w celu ładowania i rozładowywania danych, musisz skonfigurować zasady i role dotyczące wielu kont między kontami A i kontami B. Wykonaj następujące kroki:
- Na koncie A skonfiguruj zasady zasobnika dla zasobnika
sample-inp-bucket-etl-<username>aby przyznać uprawnienia do ról AWS Glue i Amazon MWAA na koncie B dla obiektów w wiadrzesample-inp-bucket-etl-<username>: - Podobnie skonfiguruj zasady segmentu dla segmentu
sample-opt-bucket-etl-<username>aby przyznać uprawnienia rolom Amazon MWAA na koncie B w celu umieszczenia obiektów w tym zasobniku: - Na koncie A utwórz politykę uprawnień o nazwie
policy_for_roleA, co pozwala na niezbędne działania Amazon S3 na wiadrze wyjściowym: - Utwórz nową rolę IAM o nazwie
RoleAz kontem B jako rolą zaufanej jednostki i dodaj tę politykę do tej roli. Dzięki temu konto B może przyjąć rolę A w celu wykonania niezbędnych działań Amazon S3 w zasobniku wyjściowym. - Na koncie B utwórz politykę uprawnień o nazwie
s3-cross-account-accessz uprawnieniami dostępu do obiektów w wiadrzesample-inp-bucket-etl-<username>, który znajduje się na koncie A. - Dodaj tę politykę do roli AWS Glue i Amazon MWAA:
- Na koncie B utwórz politykę uprawnień
policy_for_roleBokreślając Konto A jako podmiot zaufany. Poniżej przedstawiono politykę zaufania, jaką należy przyjąćRoleAna koncie A: - Utwórz nową rolę IAM o nazwie
RoleBz Amazon Redshift jako typem zaufanej jednostki i dodaj tę politykę do roli. To pozwalaRoleBzakładaćRoleAna koncie A, a także do przejęcia przez Amazon Redshift. - Dołączać
RoleBdo przestrzeni nazw Redshift Serverless, dzięki czemu Amazon Redshift może zapisywać obiekty w zasobniku wyjściowym S3 na koncie A. - Dołącz politykę
policy_for_roleBdo roli Amazon MWAA, która umożliwia Amazon MWAA dostęp do zasobnika wyjściowego na koncie A.
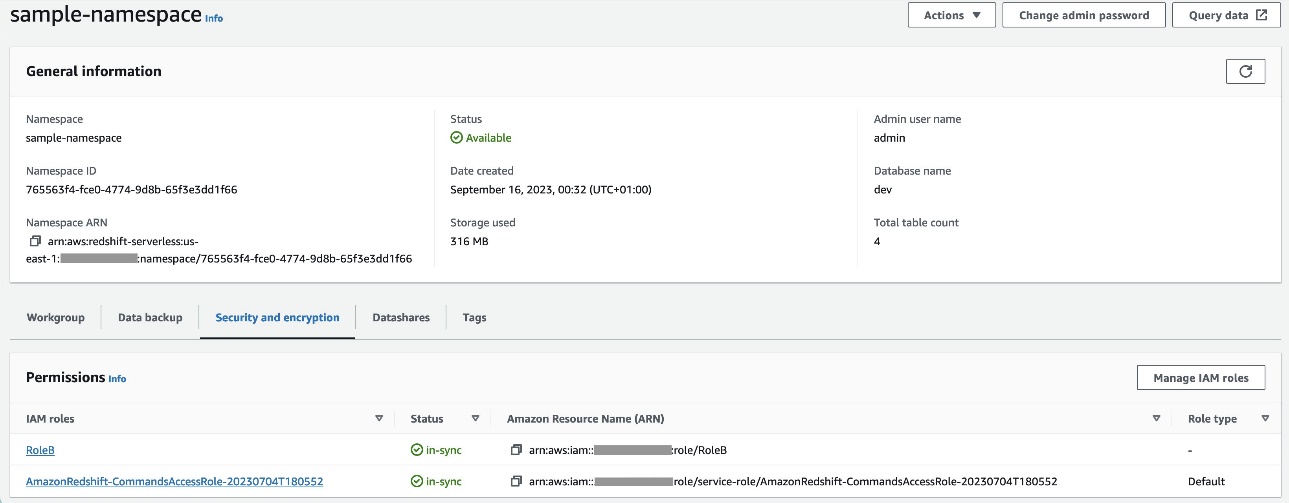
Odnosić się do Jak zapewnić dostęp dla wielu kont do obiektów znajdujących się w zasobnikach Amazon S3? aby uzyskać więcej informacji na temat konfigurowania dostępu między kontami do obiektów w Amazon S3 z AWS Glue i Amazon MWAA. Odnosić się do Jak KOPIOWAĆ lub WYŁADUĆ dane z Amazon Redshift do segmentu Amazon S3 na innym koncie? aby uzyskać więcej informacji na temat konfigurowania ról do przesyłania danych z Amazon Redshift do Amazon S3 z Amazon MWAA.
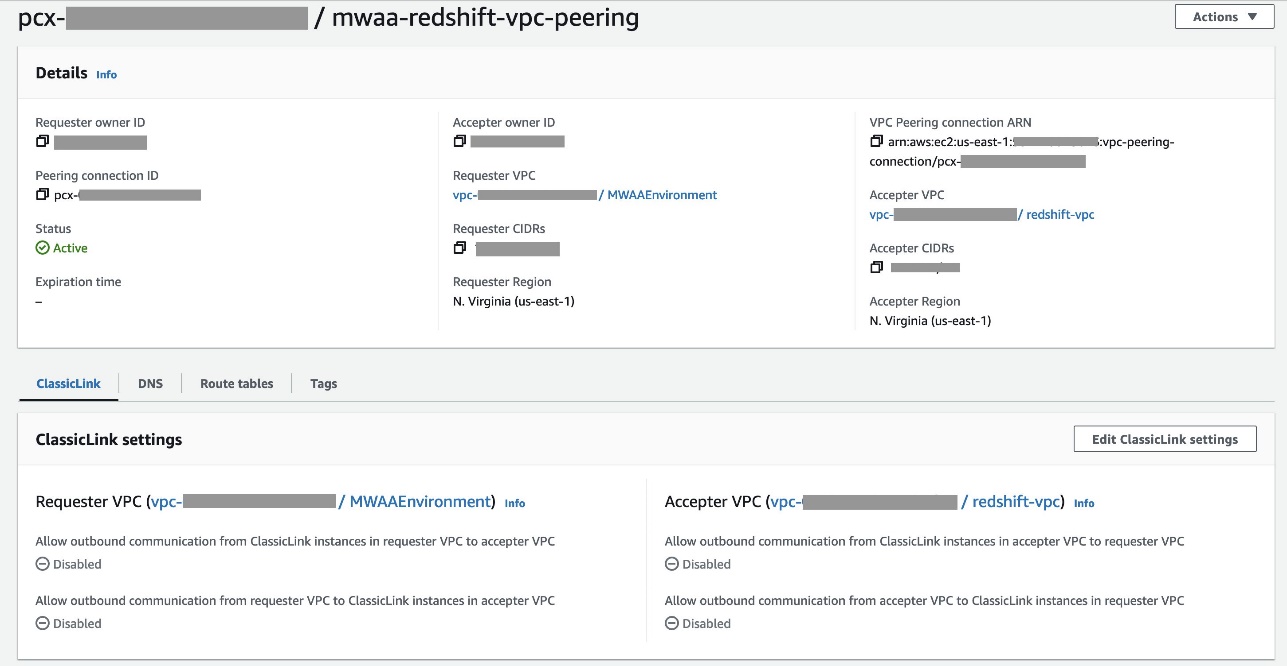
Skonfiguruj połączenie równorzędne VPC pomiędzy Amazon MWAA i Amazon Redshift VPC
Ponieważ Amazon MWAA i Amazon Redshift znajdują się w dwóch oddzielnych VPC, musisz skonfigurować między nimi komunikację równorzędną VPC. Należy dodać trasę do tabel tras powiązanych z podsieciami obu usług. Odnosić się do Pracuj z połączeniami równorzędnymi VPC aby uzyskać szczegółowe informacje na temat komunikacji równorzędnej VPC.
Upewnij się, że zakres CIDR Amazon MWAA VPC jest dozwolony w grupie zabezpieczeń Redshift, a zakres CIDR Amazon Redshift VPC jest dozwolony w grupie zabezpieczeń Amazon MWAA, jak pokazano na poniższym zrzucie ekranu.
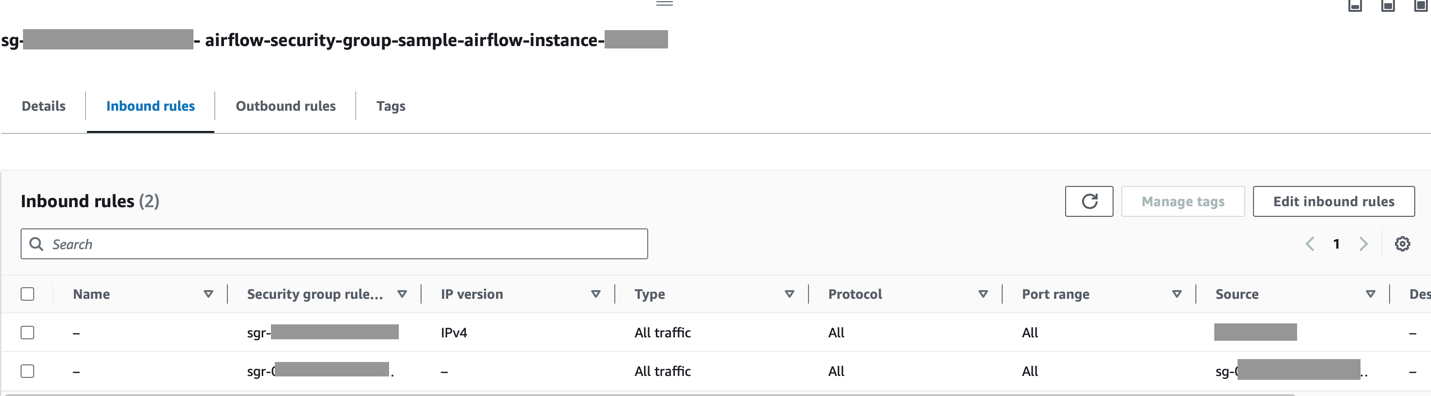
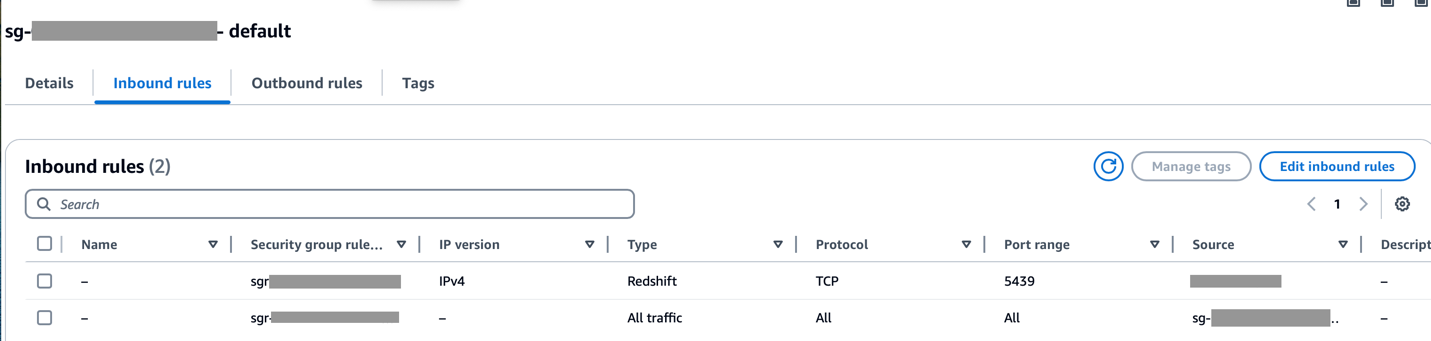
Jeśli którykolwiek z powyższych kroków zostanie skonfigurowany nieprawidłowo, w przebiegu DAG prawdopodobnie wystąpi błąd „Przekroczono limit czasu połączenia”.
Skonfiguruj połączenie Amazon MWAA z Menedżerem sekretów
Gdy potok Amazon MWAA jest skonfigurowany do korzystania z Menedżera sekretów, najpierw będzie szukać połączeń i zmiennych w alternatywnym zapleczu (np. Menedżerze sekretów). Jeśli alternatywny backend zawiera potrzebną wartość, jest ona zwracana. W przeciwnym razie sprawdzi bazę danych metadanych pod kątem wartości i zamiast tego zwróci ją. Więcej szczegółów znajdziesz w Konfigurowanie połączenia Apache Airflow przy użyciu klucza tajnego AWS Secrets Manager.
Wykonaj następujące kroki:
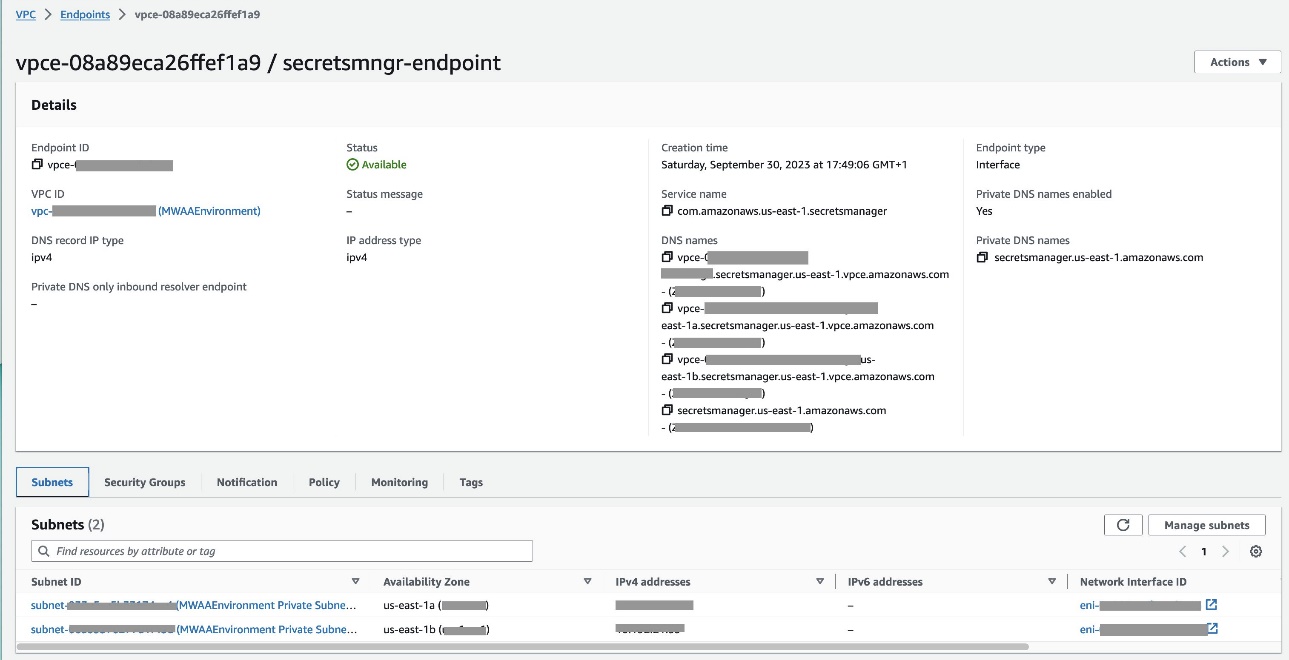
- Skonfiguruj plik Punkt końcowy VPC aby połączyć Amazon MWAA i Menedżera sekretów (
com.amazonaws.us-east-1.secretsmanager).
Dzięki temu usługa Amazon MWAA może uzyskać dostęp do poświadczeń przechowywanych w Menedżerze sekretów.
- Aby zapewnić Amazon MWAA pozwolenie na dostęp do tajnych kluczy Secrets Manager, dodaj zasadę o nazwie
SecretsManagerReadWritedo roli IAM środowiska. - Aby utworzyć zaplecze Menedżera sekretów jako opcję konfiguracji Apache Airflow, przejdź do opcji konfiguracji Airflow, dodaj następujące pary klucz-wartość i zapisz swoje ustawienia.
To konfiguruje Airflow tak, aby szukał parametrów połączenia i zmiennych w pliku airflow/connections/* i airflow/variables/* ścieżki:

- Aby wygenerować ciąg URI połączenia Airflow, przejdź do Chmura AWS i wejdź do powłoki Pythona.
- Uruchom następujący kod, aby wygenerować ciąg URI połączenia:
Ciąg połączenia powinien zostać wygenerowany w następujący sposób:
- Dodaj połączenie w Menedżerze sekretów, używając następującego polecenia w pliku Interfejs wiersza poleceń AWS (interfejs wiersza poleceń AWS).
Można to również zrobić z konsoli Menedżera sekretów. Zostanie to dodane w Menedżerze sekretów jako zwykły tekst.
Skorzystaj z połączenia airflow/connections/secrets_redshift_connection w DAG-u. Po uruchomieniu DAG będzie szukać tego połączenia i pobiera sekrety z Menedżera sekretów. W przypadku RedshiftDataOperator, przekaż secret_arn jako parametr zamiast nazwy połączenia.
Możesz także dodawać wpisy tajne za pomocą konsoli Menedżera kluczy tajnych jako pary klucz-wartość.
- Dodaj kolejny sekret w Menedżerze sekretów i zapisz go jako
airflow/connections/redshift_conn_test.

Utwórz połączenie Airflow za pośrednictwem bazy danych metadanych
Połączenia można także tworzyć w interfejsie użytkownika. W takim przypadku szczegóły połączenia zostaną zapisane w bazie danych metadanych Airflow. Jeśli środowisko Amazon MWAA nie jest skonfigurowane do korzystania z zaplecza Menedżera sekretów, sprawdzi wartość w bazie danych metadanych i zwróci ją. Możesz utworzyć połączenie Airflow za pomocą interfejsu użytkownika, interfejsu wiersza polecenia AWS lub interfejsu API. W tej sekcji pokazujemy, jak utworzyć połączenie za pomocą interfejsu użytkownika Airflow.
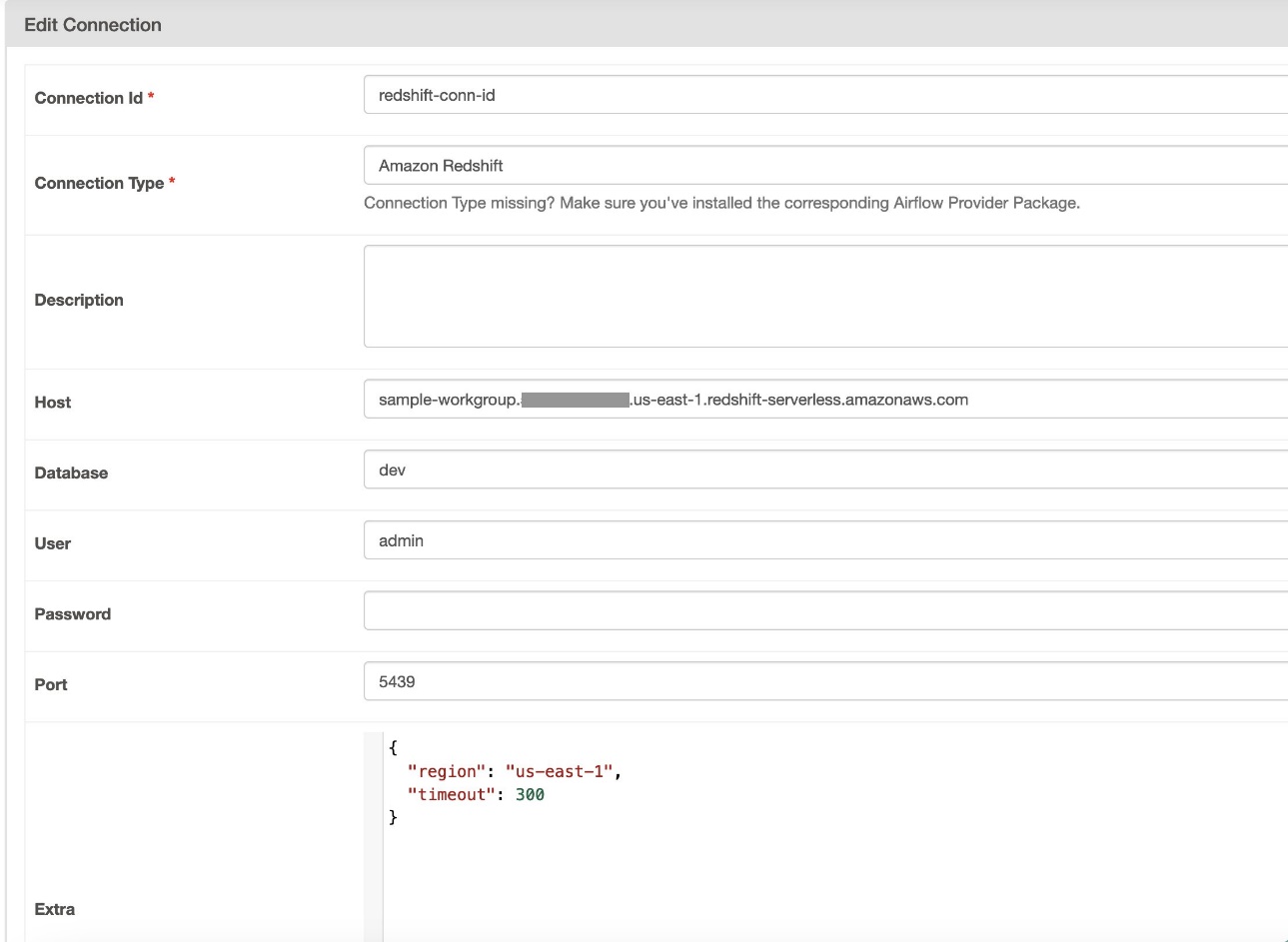
- W razie zamówieenia projektu Identyfikator połączenia, wprowadź nazwę połączenia.
- W razie zamówieenia projektu Rodzaj zasilaniawybierz Amazonka Przesunięcie ku czerwieni.
- W razie zamówieenia projektu Gospodarz, wprowadź punkt końcowy Redshift (bez portu i bazy danych) dla Redshift Serverless.
- W razie zamówieenia projektu Baza danych, wchodzić
dev. - W razie zamówieenia projektu Użytkownik, wprowadź swoją nazwę użytkownika administratora.
- W razie zamówieenia projektu Hasło, Wprowadź hasło.
- W razie zamówieenia projektu Port, użyj portu 5439.
- W razie zamówieenia projektu Extra, Ustaw
regionitimeoutparametry. - Przetestuj połączenie, a następnie zapisz ustawienia.
Utwórz i uruchom DAG
W tej sekcji opisujemy, jak utworzyć DAG przy użyciu różnych komponentów. Po utworzeniu i uruchomieniu DAG możesz zweryfikować wyniki, wysyłając zapytania do tabel Redshift i sprawdzając docelowe segmenty S3.
Utwórz DAG
W Airflow potoki danych są zdefiniowane w kodzie Pythona jako DAG. Tworzymy DAG, który składa się z różnych operatorów, czujników, połączeń, zadań i reguł:
- DAG rozpoczyna się od wyszukania plików źródłowych w wiadrze S3
sample-inp-bucket-etl-<username>na koncie A na bieżący dzieńS3KeySensor. S3KeySensor służy do oczekiwania na obecność jednego lub wielu kluczy w segmencie S3.- Na przykład nasz wiadro S3 jest podzielony na partycje
s3://bucket/products/YYYY/MM/DD/, więc nasz czujnik powinien sprawdzić foldery z aktualną datą. Wyprowadziliśmy aktualną datę z DAG i przekazaliśmy ją doS3KeySensor, który szuka nowych plików w folderze bieżącego dnia. - Ustawiamy również
wildcard_matchasTrue, który umożliwia wyszukiwanie wbucket_keynależy interpretować jako wzór wieloznaczny Uniksa. Ustawmodedorescheduletak, aby zadanie czujnika zwalniało miejsce pracownika w przypadku niespełnienia kryteriów i zostało przełożone na później. Najlepszym rozwiązaniem jest używanie tego trybu, gdypoke_intervaltrwa dłużej niż 1 minutę, aby zapobiec zbyt dużemu obciążeniu programu planującego.
- Na przykład nasz wiadro S3 jest podzielony na partycje
- Gdy plik będzie już dostępny w zasobniku S3, robot AWS Glue uruchamia się przy użyciu pliku
GlueCrawlerOperatoraby przeszukać segment źródłowy S3sample-inp-bucket-etl-<username>w obszarze Konto A i aktualizuje metadane tabeli w obszarzeproducts_dbbazy danych w Katalogu Danych. Robot wykorzystuje rolę AWS Glue i bazę danych Data Catalog utworzoną w poprzednich krokach. - DAG używa
GlueCrawlerSensorpoczekać na zakończenie działania robota. - Po zakończeniu zadania przeszukiwacza
GlueJobOperatorsłuży do uruchamiania zadania klejenia AWS. Nazwa skryptu AWS Glue (wraz z lokalizacją) jest przekazywana operatorowi wraz z rolą AWS Glue IAM. Inne parametry, npGlueVersion,NumberofWorkers,WorkerTypesą przekazywane za pomocącreate_job_kwargsparametr. - DAG używa
GlueJobSensorpoczekać na zakończenie zadania klejenia AWS. Po zakończeniu pojawi się tabela pomostowa Redshiftproductszostaną załadowane dane z pliku S3. - Możesz połączyć się z Amazon Redshift z Airflow za pomocą trzech różnych operatorzy:
PythonOperator.SQLExecuteQueryOperator, który wykorzystuje połączenie PostgreSQL iredshift_defaultjako połączenie domyślne.RedshiftDataOperator, który korzysta z interfejsu API danych Redshift iaws_defaultjako połączenie domyślne.
W naszym DAG używamy SQLExecuteQueryOperator i RedshiftDataOperator aby pokazać, jak używać tych operatorów. Uruchamiane są procedury składowane Redshift RedshiftDataOperator. DAG uruchamia również polecenia SQL w Amazon Redshift, aby usunąć dane z tabeli pomostowej za pomocą SQLExecuteQueryOperator.
Ponieważ skonfigurowaliśmy nasze środowisko Amazon MWAA do wyszukiwania połączeń w Menedżerze sekretów, po uruchomieniu DAG pobiera szczegóły połączenia Redshift, takie jak nazwa użytkownika, hasło, host, port i region z Menedżera sekretów. Jeśli połączenie nie zostanie znalezione w Menedżerze sekretów, wartości zostaną pobrane z połączeń domyślnych.
In SQLExecuteQueryOperator, przekazujemy nazwę połączenia, którą utworzyliśmy w Menedżerze sekretów. To szuka airflow/connections/secrets_redshift_connection i odzyskuje sekrety od Menedżera sekretów. Jeśli Menedżer sekretów nie jest skonfigurowany, połączenie utworzone ręcznie (na przykład redshift-conn-id) można przejść.
In RedshiftDataOperator, przekazujemy sekret_arn pliku airflow/connections/redshift_conn_test połączenie utworzone w Menedżerze sekretów jako parametr.
- Jako ostatnie zadanie,
RedshiftToS3Operatorsłuży do wyładowywania danych z tabeli przesunięcia ku czerwieni do segmentu S3sample-opt-bucket-etlna koncie B.airflow/connections/redshift_conn_testz Menedżera sekretów służy do rozładowywania danych. TriggerRulejest ustawione naALL_DONE, co umożliwia uruchomienie następnego kroku po zakończeniu wszystkich zadań nadrzędnych.- Zależność zadań definiuje się za pomocą
chain()funkcję, która w razie potrzeby pozwala na równoległe wykonywanie zadań. W naszym przypadku chcemy, aby wszystkie zadania przebiegały po kolei.
Poniżej znajduje się pełny kod DAG. The dag_id powinna odpowiadać nazwie skryptu DAG, w przeciwnym razie nie zostanie zsynchronizowana z interfejsem użytkownika Airflow.
Sprawdź działanie DAG
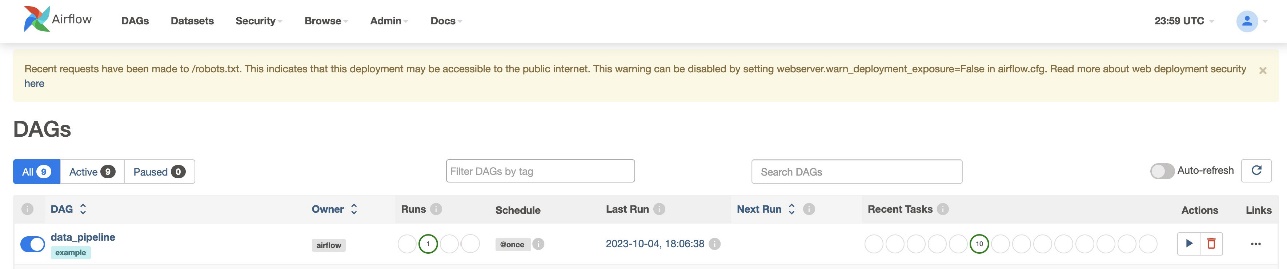
Po utworzeniu pliku DAG (zamień zmienne w skrypcie DAG) i przesłaniu go do s3://sample-airflow-instance/dags folderze, zostanie on automatycznie zsynchronizowany z interfejsem użytkownika Airflow. Wszystkie DAG-y pojawiają się na DAG-i patka. Przełącz ON opcja umożliwienia uruchomienia DAG. Ponieważ nasz DAG jest ustawiony na schedule="@once", musisz ręcznie uruchomić zadanie, wybierając ikonę uruchamiania poniżej Akcje. Po zakończeniu DAG status zostanie zaktualizowany na zielono, jak pokazano na poniższym zrzucie ekranu.
W Linki sekcji dostępne są opcje przeglądania kodu, wykresu, siatki, dziennika i innych. Wybierać Wykres wizualizować DAG w formie wykresu. Jak pokazano na poniższym zrzucie ekranu, każdy kolor węzła oznacza konkretnego operatora, a kolor konturu węzła oznacza konkretny status.

Sprawdź wyniki
W konsoli Amazon Redshift przejdź do Edytor zapytań v2 i wybierz dane w pliku products_f tabela. Tabela powinna zostać załadowana i posiadać taką samą liczbę rekordów jak pliki S3.

Na konsoli Amazon S3 przejdź do segmentu S3 s3://sample-opt-bucket-etl na koncie B. The product_f pliki należy utworzyć w ramach struktury folderów s3://sample-opt-bucket-etl/products/YYYY/MM/DD/.

Sprzątać
Wyczyść zasoby utworzone w ramach tego posta, aby uniknąć ponoszenia bieżących opłat:
- Usuń stosy CloudFormation i zasobnik S3 utworzone jako wymagania wstępne.
- Usuń VPC i połączenia równorzędne VPC, zasady i role dla wielu kont oraz wpisy tajne w Menedżerze sekretów.
Wnioski
Dzięki Amazon MWAA możesz tworzyć złożone przepływy pracy przy użyciu Airflow i Python bez zarządzania klastrami, węzłami lub innymi narzutami operacyjnymi zwykle związanymi z wdrażaniem i skalowaniem Airflow w środowisku produkcyjnym. W tym poście pokazaliśmy, jak Amazon MWAA zapewnia zautomatyzowany sposób przyjmowania, przekształcania, analizowania i dystrybucji danych pomiędzy różnymi kontami i usługami w AWS. Więcej przykładów innych operatorów AWS można znaleźć poniżej Repozytorium GitHub; zachęcamy do dowiedzenia się więcej poprzez wypróbowanie niektórych z tych przykładów.
O autorach

Radhika Jakkula jest architektem rozwiązań prototypowania Big Data w AWS. Pomaga klientom budować prototypy przy użyciu usług analitycznych AWS i specjalnie zbudowanych baz danych. Jest specjalistką w ocenie szerokiego zakresu wymagań i zastosowaniu odpowiednich usług AWS, narzędzi i frameworków Big Data do stworzenia solidnej architektury.
 Sidhantha Muralidhara jest głównym menedżerem ds. technicznych w AWS. Współpracuje z dużymi klientami korporacyjnymi, którzy uruchamiają swoje obciążenia na platformie AWS. Pasjonuje się pracą z klientami i pomaganiem im w projektowaniu obciążeń pod kątem kosztów, niezawodności, wydajności i doskonałości operacyjnej na dużą skalę w ich podróży do chmury. Interesuje się także analizą danych.
Sidhantha Muralidhara jest głównym menedżerem ds. technicznych w AWS. Współpracuje z dużymi klientami korporacyjnymi, którzy uruchamiają swoje obciążenia na platformie AWS. Pasjonuje się pracą z klientami i pomaganiem im w projektowaniu obciążeń pod kątem kosztów, niezawodności, wydajności i doskonałości operacyjnej na dużą skalę w ich podróży do chmury. Interesuje się także analizą danych.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/orchestrate-an-end-to-end-etl-pipeline-using-amazon-s3-aws-glue-and-amazon-redshift-serverless-with-amazon-mwaa/