
Este post foi co-escrito por Goktug Cinar, Michael Binder e Adrian Horvath do Bosch Center for Artificial Intelligence (BCAI).
A previsão de receita é uma tarefa desafiadora, mas crucial, para decisões estratégicas de negócios e planejamento fiscal na maioria das organizações. Muitas vezes, a previsão de receita é realizada manualmente por analistas financeiros e é demorada e subjetiva. Esses esforços manuais são especialmente desafiadores para organizações empresariais multinacionais de grande escala que exigem previsões de receita em uma ampla variedade de grupos de produtos e áreas geográficas em vários níveis de granularidade. Isso requer não apenas precisão, mas também coerência hierárquica das previsões.
Bosch é uma corporação multinacional com entidades que operam em vários setores, incluindo automotivo, soluções industriais e bens de consumo. Dado o impacto da previsão de receita precisa e coerente em operações comerciais saudáveis, o Centro Bosch para Inteligência Artificial (BCAI) vem investindo fortemente no uso de machine learning (ML) para melhorar a eficiência e precisão dos processos de planejamento financeiro. O objetivo é aliviar os processos manuais fornecendo previsões de receita de linha de base razoáveis por meio de ML, com apenas ajustes ocasionais necessários pelos analistas financeiros usando seu conhecimento do setor e do domínio.
Para atingir este objetivo, o BCAI desenvolveu uma estrutura de previsão interna capaz de fornecer previsões hierárquicas em larga escala por meio de conjuntos personalizados de uma ampla gama de modelos de base. Um meta-aprendiz seleciona os modelos de melhor desempenho com base nos recursos extraídos de cada série temporal. As previsões dos modelos selecionados são então calculadas para obter a previsão agregada. O projeto arquitetônico é modularizado e extensível por meio da implementação de uma interface no estilo REST, que permite a melhoria contínua do desempenho por meio da inclusão de modelos adicionais.
O BCAI fez parceria com o Laboratório de soluções de ML da Amazon (MLSL) para incorporar os mais recentes avanços em modelos baseados em redes neurais profundas (DNN) para previsão de receita. Avanços recentes em previsões neurais demonstraram desempenho de ponta para muitos problemas práticos de previsão. Em comparação com os modelos de previsão tradicionais, muitos previsores neurais podem incorporar covariáveis ou metadados adicionais da série temporal. Incluímos CNN-QR e DeepAR+, dois modelos de prateleira em Previsão da Amazônia, bem como um modelo personalizado do Transformer treinado usando Amazon Sage Maker. Os três modelos cobrem um conjunto representativo de backbones de codificadores frequentemente usados em previsões neurais: rede neural convolucional (CNN), rede neural recorrente sequencial (RNN) e codificadores baseados em transformador.
Um dos principais desafios enfrentados pela parceria BCAI-MLSL foi fornecer previsões robustas e razoáveis sob o impacto do COVID-19, um evento global sem precedentes que causa grande volatilidade nos resultados financeiros corporativos globais. Como os previsores neurais são treinados em dados históricos, as previsões geradas com base em dados fora de distribuição dos períodos mais voláteis podem ser imprecisas e não confiáveis. Portanto, propusemos a adição de um mecanismo de atenção mascarada na arquitetura do Transformer para resolver esse problema.
Os previsores neurais podem ser agrupados como um único modelo de conjunto ou incorporados individualmente no universo de modelos da Bosch e acessados facilmente por meio de terminais da API REST. Propomos uma abordagem para ensemble dos previsores neurais por meio de resultados de backtest, que fornece desempenho competitivo e robusto ao longo do tempo. Além disso, investigamos e avaliamos várias técnicas clássicas de reconciliação hierárquica para garantir que as previsões sejam agregadas de forma coerente entre grupos de produtos, geografias e organizações comerciais.
Neste post, demonstramos o seguinte:
- Como aplicar o treinamento de modelo personalizado do Forecast e do SageMaker para problemas de previsão de séries temporais hierárquicas e em grande escala
- Como combinar modelos personalizados com modelos prontos da Forecast
- Como reduzir o impacto de eventos disruptivos como o COVID-19 em problemas de previsão
- Como criar um fluxo de trabalho de previsão de ponta a ponta na AWS
Desafios
Abordamos dois desafios: criar uma previsão de receita hierárquica em larga escala e o impacto da pandemia de COVID-19 na previsão de longo prazo.
Previsão de receita hierárquica e em larga escala
Os analistas financeiros têm a tarefa de prever os principais números financeiros, incluindo receita, custos operacionais e despesas de P&D. Essas métricas fornecem insights de planejamento de negócios em diferentes níveis de agregação e permitem a tomada de decisões orientada por dados. Qualquer solução de previsão automatizada precisa fornecer previsões em qualquer nível arbitrário de agregação de linha de negócios. Na Bosch, as agregações podem ser imaginadas como séries temporais agrupadas como uma forma mais geral de estrutura hierárquica. A figura a seguir mostra um exemplo simplificado com uma estrutura de dois níveis, que imita a estrutura hierárquica de previsão de receita na Bosch. A receita total é dividida em vários níveis de agregações com base no produto e na região.
O número total de séries temporais que precisam ser previstas na Bosch está na escala de milhões. Observe que a série temporal de nível superior pode ser dividida por produtos ou regiões, criando vários caminhos para as previsões de nível inferior. A receita precisa ser prevista em cada nó na hierarquia com um horizonte de previsão de 12 meses no futuro. Dados históricos mensais estão disponíveis.
A estrutura hierárquica pode ser representada usando o seguinte formulário com a notação de uma matriz de soma S (Hyndman e Athanasopoulos):
![]()
Nesta equação, Y é igual ao seguinte:

Aqui, b representa a série temporal de nível inferior no momento t.
Impactos da pandemia de COVID-19
A pandemia do COVID-19 trouxe desafios significativos para a previsão devido aos seus efeitos disruptivos e sem precedentes em quase todos os aspectos do trabalho e da vida social. Para a previsão de receita de longo prazo, a interrupção também trouxe impactos inesperados a jusante. Para ilustrar esse problema, a figura a seguir mostra uma série temporal de amostra em que a receita do produto sofreu uma queda significativa no início da pandemia e se recuperou gradualmente depois. Um modelo de previsão neural típico levará dados de receita, incluindo o período COVID fora de distribuição (OOD) como a entrada do contexto histórico, bem como a verdade básica para o treinamento do modelo. Como resultado, as previsões produzidas não são mais confiáveis.

Abordagens de modelagem
Nesta seção, discutimos nossas várias abordagens de modelagem.
Previsão da Amazônia
O Forecast é um serviço de IA/ML totalmente gerenciado da AWS que fornece modelos de previsão de séries temporais de última geração e pré-configurados. Ele combina essas ofertas com seus recursos internos para otimização automatizada de hiperparâmetros, modelagem de conjunto (para os modelos fornecidos pelo Forecast) e geração de previsão probabilística. Isso permite que você ingira facilmente conjuntos de dados personalizados, pré-processe dados, treine modelos de previsão e gere previsões robustas. O design modular do serviço nos permite consultar e combinar facilmente previsões de modelos personalizados adicionais desenvolvidos em paralelo.
Incorporamos dois previsores neurais da Forecast: CNN-QR e DeepAR+. Ambos são métodos de aprendizado profundo supervisionados que treinam um modelo global para todo o conjunto de dados de séries temporais. Os modelos CNNQR e DeepAR+ podem receber informações de metadados estáticas sobre cada série temporal, que é o produto, região e organização de negócios correspondente em nosso caso. Eles também adicionam automaticamente recursos temporais, como mês do ano, como parte da entrada do modelo.
Transformador com máscaras de atenção para COVID
A arquitetura do Transformer (Vaswani et ai.), originalmente projetado para processamento de linguagem natural (NLP), surgiu recentemente como uma escolha arquitetônica popular para previsão de séries temporais. Aqui, usamos a arquitetura Transformer descrita em Zhou et ai. sem atenção esparsa de log probabilístico. O modelo usa um projeto de arquitetura típico combinando um codificador e um decodificador. Para previsão de receita, configuramos o decodificador para emitir diretamente a previsão do horizonte de 12 meses, em vez de gerar a previsão mês a mês de maneira autorregressiva. Com base na frequência da série temporal, recursos adicionais relacionados ao tempo, como mês do ano, são adicionados como variável de entrada. Variáveis categóricas adicionais que descrevem as metainformações (produto, região, organização de negócios) são alimentadas na rede por meio de uma camada de incorporação treinável.
O diagrama a seguir ilustra a arquitetura do Transformer e o mecanismo de mascaramento de atenção. O mascaramento de atenção é aplicado em todas as camadas do codificador e do decodificador, conforme destacado em laranja, para evitar que os dados OOD afetem as previsões.

Mitigamos o impacto das janelas de contexto OOD adicionando máscaras de atenção. O modelo é treinado para dar pouca atenção ao período COVID que contém outliers por meio de mascaramento e realiza a previsão com informações mascaradas. A máscara de atenção é aplicada em todas as camadas da arquitetura do decodificador e do codificador. A janela mascarada pode ser especificada manualmente ou por meio de um algoritmo de detecção de valores discrepantes. Além disso, ao usar uma janela de tempo contendo valores discrepantes como rótulos de treinamento, as perdas não são propagadas de volta. Esse método baseado em mascaramento de atenção pode ser aplicado para lidar com interrupções e casos OOD trazidos por outros eventos raros e melhorar a robustez das previsões.
Conjunto de modelos
O conjunto de modelos geralmente supera modelos únicos para previsão – melhora a generalização do modelo e é melhor para lidar com dados de séries temporais com características variadas em periodicidade e intermitência. Incorporamos uma série de estratégias de conjunto de modelos para melhorar o desempenho do modelo e a robustez das previsões. Uma forma comum de conjunto de modelos de aprendizado profundo é agregar resultados de execuções de modelos com diferentes inicializações de peso aleatório ou de diferentes épocas de treinamento. Utilizamos essa estratégia para obter previsões para o modelo Transformer.
Para construir ainda mais um ensemble em cima de diferentes arquiteturas de modelo, como Transformer, CNNQR e DeepAR+, usamos uma estratégia de ensemble pan-model que seleciona os modelos de melhor desempenho top-k para cada série temporal com base nos resultados do backtest e obtém suas médias. Como os resultados do backtest podem ser exportados diretamente de modelos de previsão treinados, essa estratégia nos permite tirar proveito de serviços prontos para uso, como o Forecast, com melhorias obtidas de modelos personalizados, como o Transformer. Essa abordagem de conjunto de modelos de ponta a ponta não requer o treinamento de um meta-aprendiz ou o cálculo de recursos de séries temporais para a seleção de modelos.
Reconciliação hierárquica
A estrutura é adaptável para incorporar uma ampla gama de técnicas como etapas de pós-processamento para reconciliação de previsão hierárquica, incluindo bottom-up (BU), reconciliação de cima para baixo com proporções de previsão (TDFP), mínimo quadrado ordinário (OLS) e mínimo quadrado ponderado ( WLS). Todos os resultados experimentais neste post são relatados usando a reconciliação de cima para baixo com proporções de previsão.
Visão geral da arquitetura
Desenvolvemos um fluxo de trabalho automatizado de ponta a ponta na AWS para gerar previsões de receita utilizando serviços como Forecast, SageMaker, Serviço de armazenamento simples da Amazon (Amazon S3), AWS Lambda, Funções de etapa da AWS e Kit de desenvolvimento em nuvem da AWS (AWS CDK). A solução implantada fornece previsões de séries temporais individuais por meio de uma API REST usando Gateway de API da Amazon, retornando os resultados no formato JSON predefinido.
O diagrama a seguir ilustra o fluxo de trabalho de previsão de ponta a ponta.

As principais considerações de design para a arquitetura são versatilidade, desempenho e facilidade de uso. O sistema deve ser suficientemente versátil para incorporar um conjunto diversificado de algoritmos durante o desenvolvimento e a implantação, com o mínimo de alterações necessárias, e pode ser facilmente estendido ao adicionar novos algoritmos no futuro. O sistema também deve adicionar sobrecarga mínima e oferecer suporte ao treinamento paralelizado para o Forecast e o SageMaker para reduzir o tempo de treinamento e obter a previsão mais recente mais rapidamente. Finalmente, o sistema deve ser simples de usar para fins de experimentação.
O fluxo de trabalho de ponta a ponta é executado sequencialmente pelos seguintes módulos:
- Um módulo de pré-processamento para reformatação e transformação de dados
- Um módulo de treinamento de modelo que incorpora o modelo Forecast e o modelo personalizado no SageMaker (ambos estão sendo executados em paralelo)
- Um módulo de pós-processamento que suporta conjunto de modelos, reconciliação hierárquica, métricas e geração de relatórios
O Step Functions organiza e orquestra o fluxo de trabalho de ponta a ponta como uma máquina de estado. A execução da máquina de estado é configurada com um arquivo JSON contendo todas as informações necessárias, incluindo a localização dos arquivos CSV de receita histórica no Amazon S3, a hora de início da previsão e as configurações de hiperparâmetro do modelo para executar o fluxo de trabalho de ponta a ponta. As chamadas assíncronas são criadas para paralelizar o treinamento do modelo na máquina de estado usando funções do Lambda. Todos os dados históricos, arquivos de configuração, resultados de previsão, bem como resultados intermediários, como resultados de backtesting, são armazenados no Amazon S3. A API REST foi criada com base no Amazon S3 para fornecer uma interface consultável para consultar resultados de previsão. O sistema pode ser estendido para incorporar novos modelos de previsão e funções de suporte, como geração de relatórios de visualização de previsão.
Avaliação
Nesta seção, detalhamos a configuração do experimento. Os principais componentes incluem o conjunto de dados, métricas de avaliação, janelas de backtest e configuração e treinamento do modelo.
Conjunto de dados
Para proteger a privacidade financeira da Bosch ao usar um conjunto de dados significativo, usamos um conjunto de dados sintético com características estatísticas semelhantes a um conjunto de dados de receita do mundo real de uma unidade de negócios da Bosch. O conjunto de dados contém 1,216 séries temporais no total com receita registrada em uma frequência mensal, abrangendo janeiro de 2016 a abril de 2022. O conjunto de dados é entregue com 877 séries temporais no nível mais granular (série temporal inferior), com uma estrutura de série temporal agrupada correspondente representada como uma matriz de soma S. Cada série temporal está associada a três atributos categóricos estáticos, que correspondem à categoria do produto, região e unidade organizacional no conjunto de dados real (anonimizado nos dados sintéticos).
Métricas de avaliação
Usamos o erro percentual absoluto do arco-tangente mediano (mediano-MAAPE) e o MAAPE ponderado para avaliar o desempenho do modelo e realizar análises comparativas, que são as métricas padrão usadas na Bosch. MAAPE aborda as deficiências da métrica de erro percentual médio absoluto (MAPE) comumente usado no contexto de negócios. O Median-MAAPE fornece uma visão geral do desempenho do modelo calculando a mediana dos MAAPEs calculados individualmente em cada série temporal. O MAAPE ponderado relata uma combinação ponderada dos MAAPEs individuais. Os pesos são a proporção da receita para cada série temporal em comparação com a receita agregada de todo o conjunto de dados. O MAAPE ponderado reflete melhor os impactos de negócios a jusante da precisão da previsão. Ambas as métricas são relatadas em todo o conjunto de dados de 1,216 séries temporais.
Janelas de backtest
Usamos janelas de backtest de 12 meses para comparar o desempenho do modelo. A figura a seguir ilustra as janelas de backtest usadas nos experimentos e destaca os dados correspondentes usados para treinamento e otimização de hiperparâmetros (HPO). Para janelas de backtest após o início do COVID-19, o resultado é afetado pelas entradas OOD de abril a maio de 2020, com base no que observamos na série temporal de receita.

Configuração e treinamento do modelo
Para o treinamento do Transformer, usamos a perda de quantil e dimensionamos cada série temporal usando seu valor médio histórico antes de alimentá-lo no Transformer e calcular a perda de treinamento. As previsões finais são redimensionadas para calcular as métricas de precisão, usando o MeanScaler implementado em GlúonTS. Usamos uma janela de contexto com dados de receita mensal dos últimos 18 meses, selecionados via HPO na janela de backtest de julho de 2018 a junho de 2019. Metadados adicionais sobre cada série temporal na forma de variáveis categóricas estáticas são inseridos no modelo por meio de uma incorporação camada antes de alimentá-lo para as camadas do transformador. Treinamos o Transformer com cinco inicializações de peso aleatório diferentes e calculamos a média dos resultados de previsão das últimas três épocas para cada execução, totalizando uma média de 15 modelos. As cinco execuções de treinamento do modelo podem ser paralelizadas para reduzir o tempo de treinamento. Para o Transformer mascarado, indicamos os meses de abril a maio de 2020 como discrepantes.
Para todo o treinamento do modelo de previsão, habilitamos o HPO automático, que pode selecionar o modelo e os parâmetros de treinamento com base em um período de backtest especificado pelo usuário, definido para os últimos 12 meses na janela de dados usada para treinamento e HPO.
Resultados da experiência
Treinamos Transformers mascarados e não mascarados usando o mesmo conjunto de hiperparâmetros e comparamos seu desempenho para janelas de backtest imediatamente após o choque do COVID-19. No Transformer mascarado, os dois meses mascarados são abril e maio de 2020. A tabela a seguir mostra os resultados de uma série de períodos de backtest com janelas de previsão de 12 meses a partir de junho de 2020. Podemos observar que o Transformer mascarado supera consistentemente a versão não mascarada .

Também realizamos a avaliação da estratégia de conjunto de modelos com base nos resultados do backtest. Em particular, comparamos os dois casos em que apenas o modelo de melhor desempenho é selecionado versus quando os dois modelos de melhor desempenho são selecionados, e a média do modelo é realizada calculando o valor médio das previsões. Comparamos o desempenho dos modelos base e dos modelos ensemble nas figuras a seguir. Observe que nenhum dos previsores neurais supera consistentemente os outros nas janelas de backtest de rolagem.


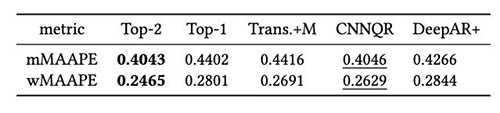
A tabela a seguir mostra que, em média, a modelagem de conjunto dos dois principais modelos oferece o melhor desempenho. CNNQR fornece o segundo melhor resultado.
Conclusão
Esta postagem demonstrou como criar uma solução de ML de ponta a ponta para problemas de previsão em larga escala combinando Forecast e um modelo personalizado treinado no SageMaker. Dependendo de suas necessidades de negócios e conhecimento de ML, você pode usar um serviço totalmente gerenciado, como o Forecast, para descarregar o processo de criação, treinamento e implantação de um modelo de previsão; construa seu modelo personalizado com mecanismos de ajuste específicos com o SageMaker; ou execute o conjunto de modelos combinando os dois serviços.
Se você precisar de ajuda para acelerar o uso do ML em seus produtos e serviços, entre em contato com o Laboratório de soluções de ML da Amazon .
Referências
Hyndman RJ, Athanasopoulos G. Previsão: princípios e prática. Textos O; 2018 de maio de 8.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Atenção é tudo que você precisa. Avanços em sistemas de processamento de informação neural. 2017;30.
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Informador: Além do transformador eficiente para previsão de séries temporais de seqüência longa. InProceedings of AAAI 2021 2 de fevereiro.
Sobre os autores
 Goktug Cinar é cientista líder de ML e líder técnico da previsão baseada em ML e estatísticas na Robert Bosch LLC e no Bosch Center for Artificial Intelligence. Ele lidera a pesquisa dos modelos de previsão, consolidação hierárquica e técnicas de combinação de modelos, bem como a equipe de desenvolvimento de software que dimensiona esses modelos e os atende como parte do software interno de previsão financeira de ponta a ponta.
Goktug Cinar é cientista líder de ML e líder técnico da previsão baseada em ML e estatísticas na Robert Bosch LLC e no Bosch Center for Artificial Intelligence. Ele lidera a pesquisa dos modelos de previsão, consolidação hierárquica e técnicas de combinação de modelos, bem como a equipe de desenvolvimento de software que dimensiona esses modelos e os atende como parte do software interno de previsão financeira de ponta a ponta.
 Michael Binder é proprietário do produto na Bosch Global Services, onde coordena o desenvolvimento, a implantação e a implementação do aplicativo de análise preditiva em toda a empresa para a previsão automatizada de dados financeiros em larga escala, orientada por dados.
Michael Binder é proprietário do produto na Bosch Global Services, onde coordena o desenvolvimento, a implantação e a implementação do aplicativo de análise preditiva em toda a empresa para a previsão automatizada de dados financeiros em larga escala, orientada por dados.
 Adriano Horvath é desenvolvedor de software no Bosch Center for Artificial Intelligence, onde desenvolve e mantém sistemas para criar previsões com base em vários modelos de previsão.
Adriano Horvath é desenvolvedor de software no Bosch Center for Artificial Intelligence, onde desenvolve e mantém sistemas para criar previsões com base em vários modelos de previsão.
 Pan Pan Xu é Cientista Aplicado Sênior e Gerente do Amazon ML Solutions Lab na AWS. Ela está trabalhando em pesquisa e desenvolvimento de algoritmos de aprendizado de máquina para aplicativos de clientes de alto impacto em uma variedade de verticais industriais para acelerar sua adoção de IA e nuvem. Seu interesse de pesquisa inclui interpretabilidade de modelos, análise causal, IA human-in-the-loop e visualização interativa de dados.
Pan Pan Xu é Cientista Aplicado Sênior e Gerente do Amazon ML Solutions Lab na AWS. Ela está trabalhando em pesquisa e desenvolvimento de algoritmos de aprendizado de máquina para aplicativos de clientes de alto impacto em uma variedade de verticais industriais para acelerar sua adoção de IA e nuvem. Seu interesse de pesquisa inclui interpretabilidade de modelos, análise causal, IA human-in-the-loop e visualização interativa de dados.
 Jasleen Grewal é Cientista Aplicada da Amazon Web Services, onde trabalha com clientes da AWS para resolver problemas do mundo real usando aprendizado de máquina, com foco especial em medicina de precisão e genômica. Ela tem uma sólida formação em bioinformática, oncologia e genômica clínica. Ela é apaixonada por usar IA/ML e serviços em nuvem para melhorar o atendimento ao paciente.
Jasleen Grewal é Cientista Aplicada da Amazon Web Services, onde trabalha com clientes da AWS para resolver problemas do mundo real usando aprendizado de máquina, com foco especial em medicina de precisão e genômica. Ela tem uma sólida formação em bioinformática, oncologia e genômica clínica. Ela é apaixonada por usar IA/ML e serviços em nuvem para melhorar o atendimento ao paciente.
 Selvan Sentivel é engenheiro de ML sênior do Amazon ML Solutions Lab na AWS, com foco em ajudar os clientes em machine learning, problemas de deep learning e soluções de ML de ponta a ponta. Ele foi líder de engenharia fundador da Amazon Comprehend Medical e contribuiu para o design e a arquitetura de vários serviços de IA da AWS.
Selvan Sentivel é engenheiro de ML sênior do Amazon ML Solutions Lab na AWS, com foco em ajudar os clientes em machine learning, problemas de deep learning e soluções de ML de ponta a ponta. Ele foi líder de engenharia fundador da Amazon Comprehend Medical e contribuiu para o design e a arquitetura de vários serviços de IA da AWS.
 Ruilin Zhang é um SDE do Amazon ML Solutions Lab na AWS. Ele ajuda os clientes a adotar os serviços de IA da AWS criando soluções para resolver problemas comuns de negócios.
Ruilin Zhang é um SDE do Amazon ML Solutions Lab na AWS. Ele ajuda os clientes a adotar os serviços de IA da AWS criando soluções para resolver problemas comuns de negócios.
 Shane Rai é estrategista sênior de ML do Amazon ML Solutions Lab na AWS. Ele trabalha com clientes em um espectro diversificado de setores para resolver suas necessidades de negócios mais urgentes e inovadoras usando a variedade de serviços de IA/ML baseados em nuvem da AWS.
Shane Rai é estrategista sênior de ML do Amazon ML Solutions Lab na AWS. Ele trabalha com clientes em um espectro diversificado de setores para resolver suas necessidades de negócios mais urgentes e inovadoras usando a variedade de serviços de IA/ML baseados em nuvem da AWS.
 Lin Lee Cheong é gerente de ciências aplicadas da equipe do Amazon ML Solutions Lab na AWS. Ela trabalha com clientes estratégicos da AWS para explorar e aplicar inteligência artificial e aprendizado de máquina para descobrir novos insights e resolver problemas complexos.
Lin Lee Cheong é gerente de ciências aplicadas da equipe do Amazon ML Solutions Lab na AWS. Ela trabalha com clientes estratégicos da AWS para explorar e aplicar inteligência artificial e aprendizado de máquina para descobrir novos insights e resolver problemas complexos.