
A partir da versão 6.14, Estúdio Amazon EMR suporta análises interativas em Amazon EMR sem servidor. Agora você pode usar aplicativos EMR Serverless como computação, além do Amazon EMR em clusters EC2 e Amazon EMR no EKS clusters virtuais, para executar notebooks JupyterLab no EMR Studio Workspaces.
EMR Studio é um ambiente de desenvolvimento integrado (IDE) que torna mais fácil para cientistas e engenheiros de dados desenvolver, visualizar e depurar aplicativos analíticos escritos em PySpark, Python e Scala. EMR Serverless é uma opção sem servidor para Amazon EMR isso facilita a execução de estruturas de análise de big data de código aberto, como o Apache Spark, sem configurar, gerenciar e dimensionar clusters ou servidores.
Na postagem, demonstramos como fazer o seguinte:
- Crie um endpoint EMR Serverless para aplicativos interativos
- Anexe o endpoint a um ambiente existente do EMR Studio
- Crie um notebook e execute um aplicativo interativo
- Diagnostique perfeitamente aplicativos interativos no EMR Studio
Pré-requisitos
Em uma organização típica, um administrador de conta da AWS configurará recursos da AWS, como Gerenciamento de identidade e acesso da AWS (IAM) funções, Serviço de armazenamento simples da Amazon (Amazon S3) baldes e Nuvem virtual privada da Amazon (Amazon VPC) recursos para acesso à Internet e acesso a outros recursos na VPC. Eles atribuem administradores do EMR Studio que gerenciam a configuração do EMR Studios e a atribuição de usuários a um EMR Studio específico. Depois de atribuídos, os desenvolvedores do EMR Studio podem usar o EMR Studio para desenvolver e monitorar cargas de trabalho.
Certifique-se de configurar recursos como bucket S3, sub-redes VPC e EMR Studio na mesma região da AWS.
Conclua as etapas a seguir para implementar esses pré-requisitos:
- Inicie o seguinte Formação da Nuvem AWS pilha.

- Insira valores para Senha do administrador e Senha do desenvolvedor e anote as senhas que você cria.
- Escolha Próximo.
- Mantenha as configurações como padrão e escolha Próximo novamente.
- Selecionar Eu reconheço que o AWS CloudFormation pode criar recursos IAM com nomes personalizados.
- Escolha Enviar.
Também fornecemos instruções para implantar esses recursos manualmente com exemplos de políticas do IAM no GitHub repo.
Configure o EMR Studio e um aplicativo interativo sem servidor
Depois que o administrador da conta da AWS concluir os pré-requisitos, o administrador do EMR Studio poderá fazer login no Console de gerenciamento da AWS para criar um aplicativo EMR Studio, Workspace e EMR Serverless.
Crie um estúdio e espaço de trabalho EMR
O administrador do EMR Studio deve fazer login no console usando o emrs-interactive-app-admin-user as credenciais do usuário. Se você implantou os recursos de pré-requisito usando o modelo CloudFormation fornecido, use a senha fornecida como parâmetro de entrada.
- No console do Amazon EMR, escolha EMR sem servidor no painel de navegação.

- Escolha COMECE AGORA.
- Selecionar Criar e iniciar o EMR Studio.
Isso cria um Studio com o nome padrão studio_1 e um espaço de trabalho com o nome padrão My_First_Workspace. Uma nova guia do navegador será aberta para o Studio_1 interface de usuário.
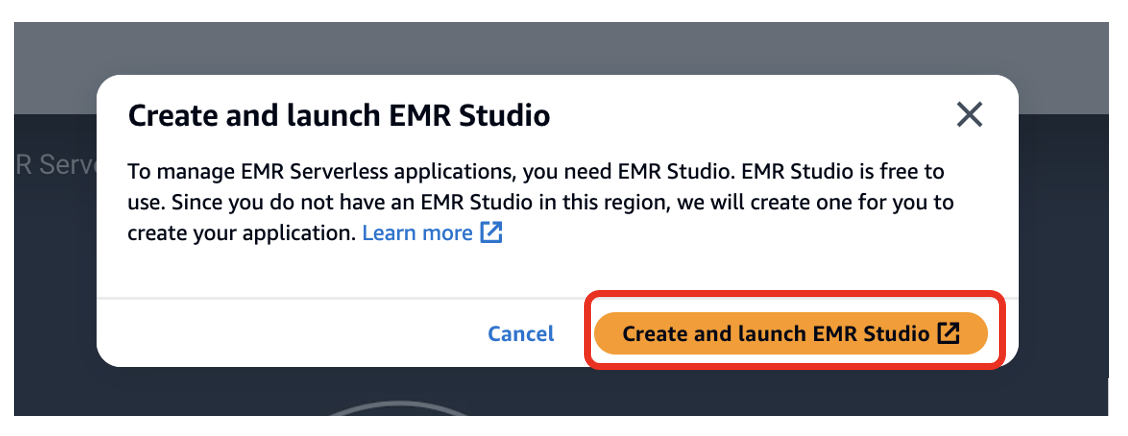
Crie um aplicativo EMR sem servidor
Conclua as etapas a seguir para criar um aplicativo EMR Serverless:
- No console do EMR Studio, escolha Aplicações no painel de navegação.
- Criar uma nova aplicação.
- Escolha Nome, insira um nome (por exemplo,
my-serverless-interactive-application). - Escolha Opções de configuração do aplicativo, selecione Usar configurações personalizadas para cargas de trabalho interativas.
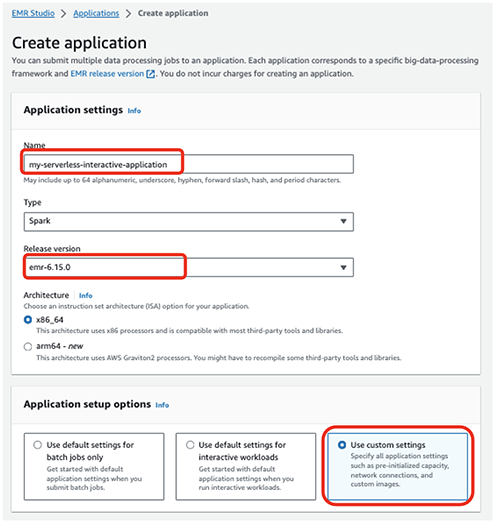
Para aplicativos interativos, como prática recomendada, recomendamos manter o driver e os trabalhadores pré-inicializados configurando o capacidade pré-inicializada no momento da criação do aplicativo. Isso cria efetivamente um pool quente de trabalhadores para um aplicativo e mantém os recursos prontos para serem consumidos, permitindo que o aplicativo responda em segundos. Para obter mais práticas recomendadas para a criação de aplicativos EMR Serverless, consulte Defina limites de recursos por equipe para cargas de trabalho de big data usando o Amazon EMR Serverless.
- No Ponto de extremidade interativo seção, selecione Habilitar endpoint interativo.
- No Conexões de rede seção, escolha a VPC, as sub-redes privadas e o grupo de segurança que você criou anteriormente.
Se você implantou a pilha CloudFormation fornecida nesta postagem, escolha emr-serverless-sg como o grupo de segurança.
Uma VPC é necessária para que a carga de trabalho possa acessar a Internet de dentro do aplicativo EMR Serverless para fazer download de pacotes Python externos. A VPC também permite acessar recursos como Serviço de banco de dados relacional da Amazon (Amazon RDS) e Amazon RedShift que estão na VPC deste aplicativo. Anexar um aplicativo sem servidor a uma VPC pode levar ao esgotamento do IP na sub-rede, portanto, certifique-se de que haja endereços IP suficientes na sua sub-rede.
- Escolha Criar e iniciar aplicativo.

Na página de aplicativos, você pode verificar se o status do seu aplicativo sem servidor muda para Iniciado.
- Selecione sua aplicação e escolha Como Funciona.
- Escolha Visualizar e iniciar espaços de trabalho.
- Escolha Configurar estúdio.

- Escolha Função de serviço¸ forneça a função de serviço do EMR Studio que você criou como pré-requisito (
emr-studio-service-role). - Escolha Armazenamento do espaço de trabalho, insira o caminho do bucket S3 criado como pré-requisito (
emrserverless-interactive-blog-<account-id>-<region-name>). - Escolha Salvar as alterações .
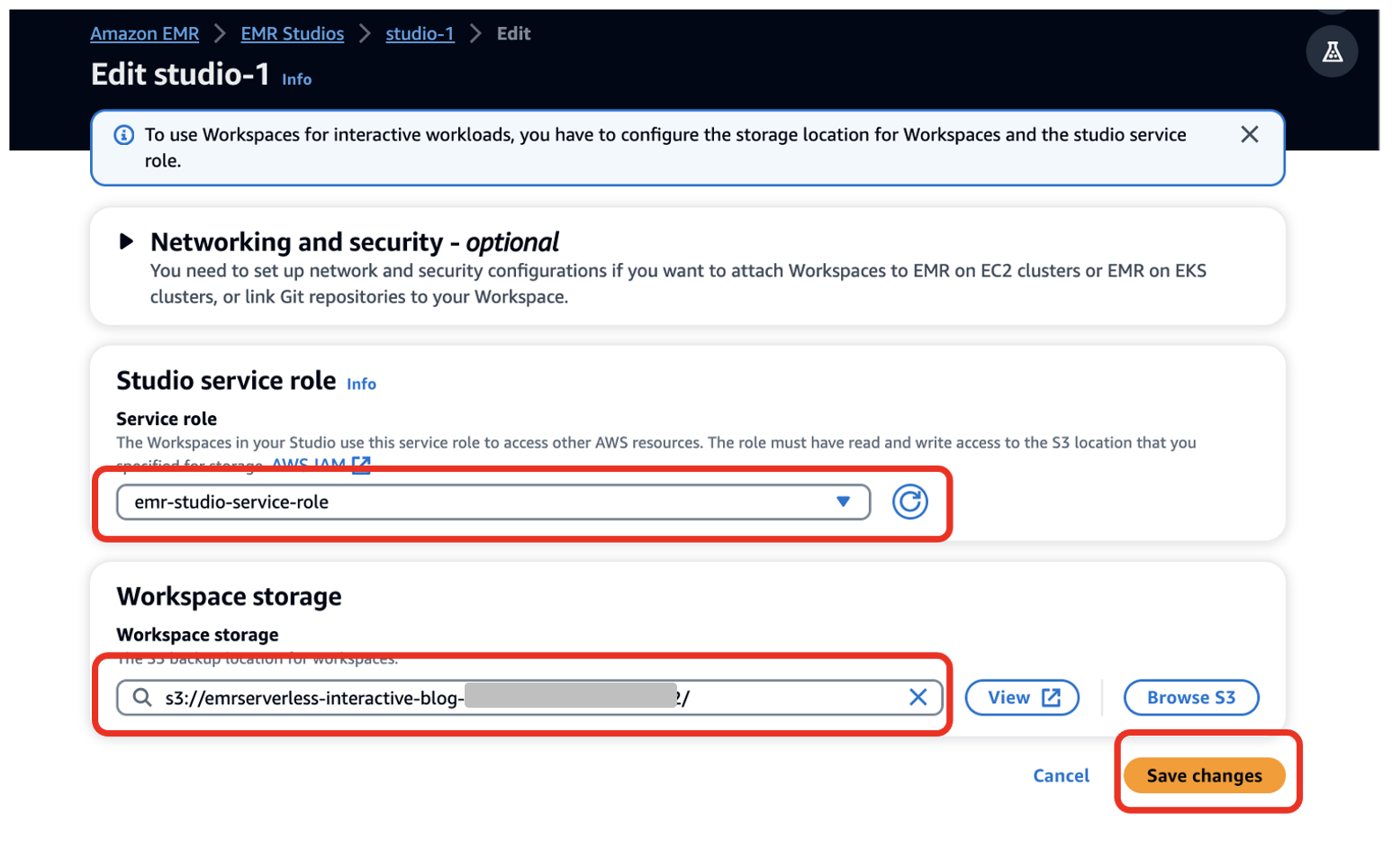
14. Navegue até o console do Studios escolhendo Studios no menu de navegação esquerdo na Estúdio EMR seção. Note o URL de acesso ao estúdio do console do Studios e forneça-o aos seus desenvolvedores para executar seus aplicativos Spark.
Execute seu primeiro aplicativo Spark
Depois que o administrador do EMR Studio criar o Studio, o Workspace e o aplicativo sem servidor, o usuário do Studio poderá usar o Workspace e o aplicativo para desenvolver e monitorar cargas de trabalho do Spark.
Inicie o Workspace e anexe o aplicativo sem servidor
Conclua as seguintes etapas:
- Usando o URL do Studio fornecido pelo administrador do EMR Studio, faça login usando o
emrs-interactive-app-dev-usercredenciais de usuário compartilhadas pelo administrador da conta da AWS.
Se você implantou os recursos de pré-requisito usando o modelo CloudFormation fornecido, use a senha fornecida como parâmetro de entrada.
No Espaços de trabalho página, você pode verificar o status do seu espaço de trabalho. Quando o espaço de trabalho for iniciado, você verá a mudança de status para Pronto.
- Inicie o espaço de trabalho escolhendo o nome do espaço de trabalho (
My_First_Workspace).
Isso abrirá uma nova guia. Certifique-se de que seu navegador permite pop-ups.
- Na área de trabalho, escolha Computar (ícone de cluster) no painel de navegação.
- Escolha Aplicativo EMR sem servidor, escolha seu aplicativo (
my-serverless-interactive-application). - Escolha Função de tempo de execução interativo, escolha uma função de tempo de execução interativa (para esta postagem, usamos
emr-serverless-runtime-role). - Escolha Anexar para anexar o aplicativo sem servidor como o tipo de computação para todos os notebooks neste espaço de trabalho.

Execute seu aplicativo Spark de forma interativa
Conclua as seguintes etapas:
- Escolha o Amostras de caderno (ícone de três pontos) no painel de navegação e abra
Getting-started-with-emr-serverlessnotebook. - Escolha Salvar no espaço de trabalho.
Existem três opções de kernels para nosso notebook: Python 3, PySpark e Spark (para Scala).
- Quando solicitado, escolha PySparkGenericName como o kernel.
- Escolha Selecionar.

Agora você pode executar seu aplicativo Spark. Para fazer isso, use o %%configure Magia de faísca comando, que configura os parâmetros de criação da sessão. Aplicativos interativos oferecem suporte a ambientes virtuais Python. Usamos um ambiente personalizado nos nós de trabalho, especificando um caminho para um tempo de execução Python diferente para o ambiente executor usando spark.executorEnv.PYSPARK_PYTHON. Veja o seguinte código:
Instale pacotes externos
Agora que você tem um ambiente virtual independente para os trabalhadores, os notebooks EMR Studio permitem instalar pacotes externos de dentro do aplicativo sem servidor usando o Spark install_pypi_package funcionar por meio do contexto Spark. O uso desta função disponibiliza o pacote para todos os trabalhadores sem servidor do EMR.
Primeiro, instale matplotlib, um pacote Python, do PyPi:
Se a etapa anterior não responder, verifique a configuração da VPC e certifique-se de que ela esteja configurada corretamente para acesso à Internet.
Agora você pode usar um conjunto de dados e visualizar seus dados.
Crie visualizações
Para criar visualizações, usamos um conjunto de dados públicos sobre os táxis amarelos de Nova York:
No bloco de código anterior, você leu o arquivo Parquet de um bucket público no Amazon S3. O arquivo possui cabeçalhos e queremos que o Spark infira o esquema. Em seguida, você usa um dataframe do Spark para agrupar e contar colunas específicas de taxi_df:
Use %%display magia para ver o resultado em formato de tabela:

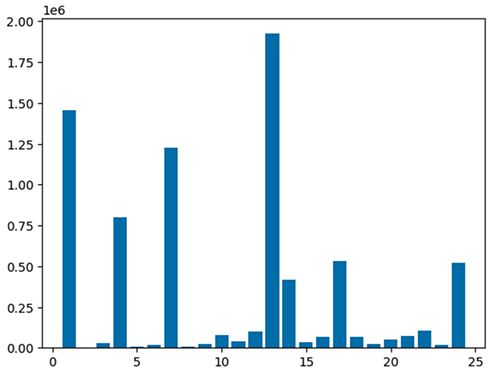
Você também pode visualizar rapidamente seus dados com cinco tipos de gráficos. Você pode escolher o tipo de exibição e o gráfico mudará de acordo. Na captura de tela a seguir, usamos um gráfico de barras para visualizar nossos dados.

Interaja com o EMR Serverless usando Spark SQL
Você pode interagir com tabelas no Catálogo de dados do AWS Glue usando Spark SQL no EMR Serverless. No notebook de exemplo, mostramos como você pode transformar dados usando um dataframe Spark.
Primeiro, crie uma nova visualização temporária chamada táxis. Isso permite que você use o Spark SQL para selecionar dados desta visualização. Em seguida, crie um dataframe de táxi para processamento posterior:
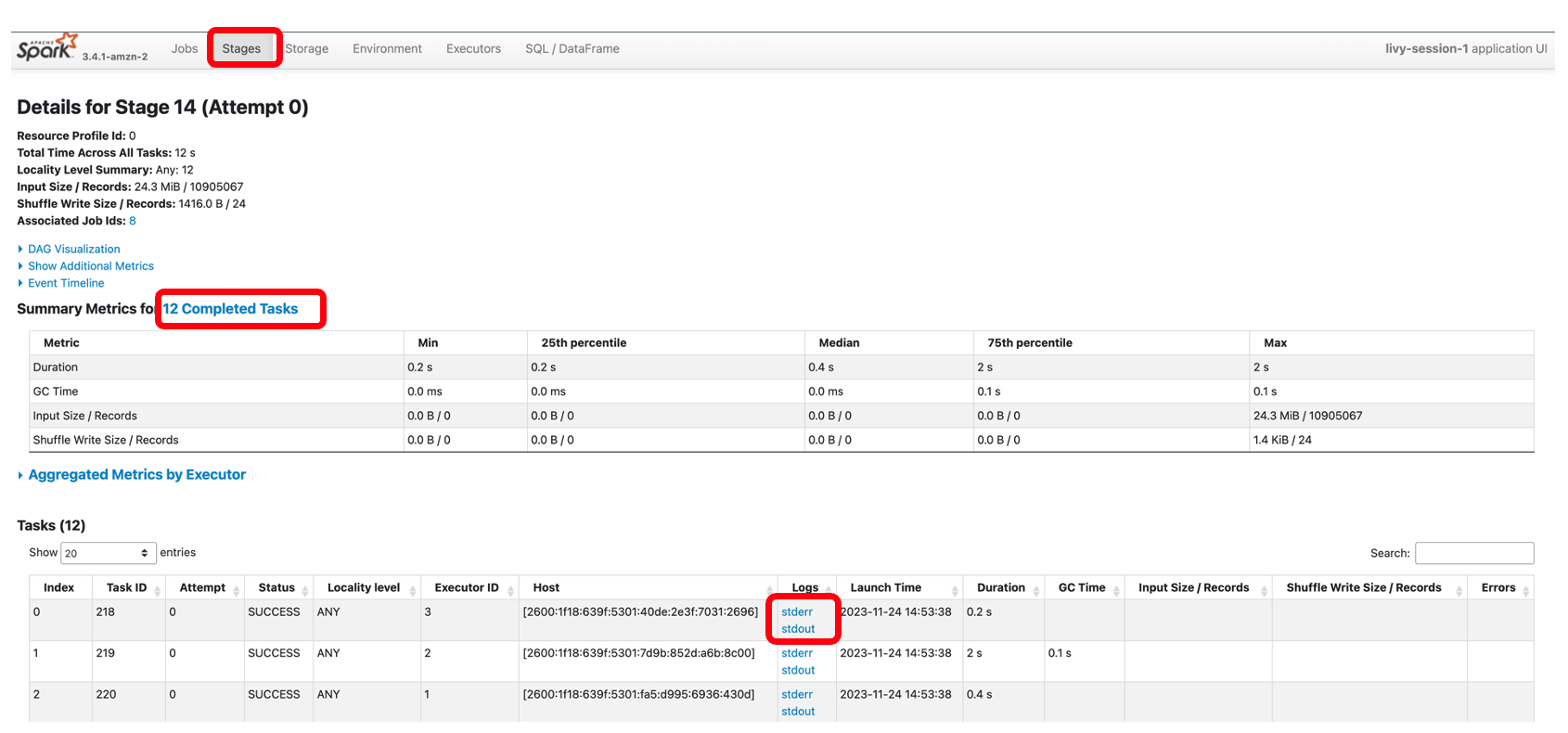
Em cada célula do seu notebook EMR Studio, você pode expandir Progresso do trabalho do Spark para visualizar os vários estágios do trabalho enviado ao EMR Serverless durante a execução desta célula específica. Você pode ver o tempo necessário para concluir cada etapa. No exemplo a seguir, o estágio 14 do trabalho possui 12 tarefas concluídas. Além disso, se houver alguma falha, você poderá ver os logs, tornando a solução de problemas uma experiência perfeita. Discutiremos isso mais na próxima seção.
![Job[14]: showString em NativeMethodAccessorImpl.java:0 e Job[15]: showString em NativeMethodAccessorImpl.java:0](https://xlera8.com/wp-content/uploads/2024/04/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio-amazon-web-services-11.png)
Use o código a seguir para visualizar o dataframe processado usando o pacote matplotlib. Você usa a biblioteca maptplotlib para traçar o local de entrega e o valor total como um gráfico de barras.
Diagnosticar aplicativos interativos
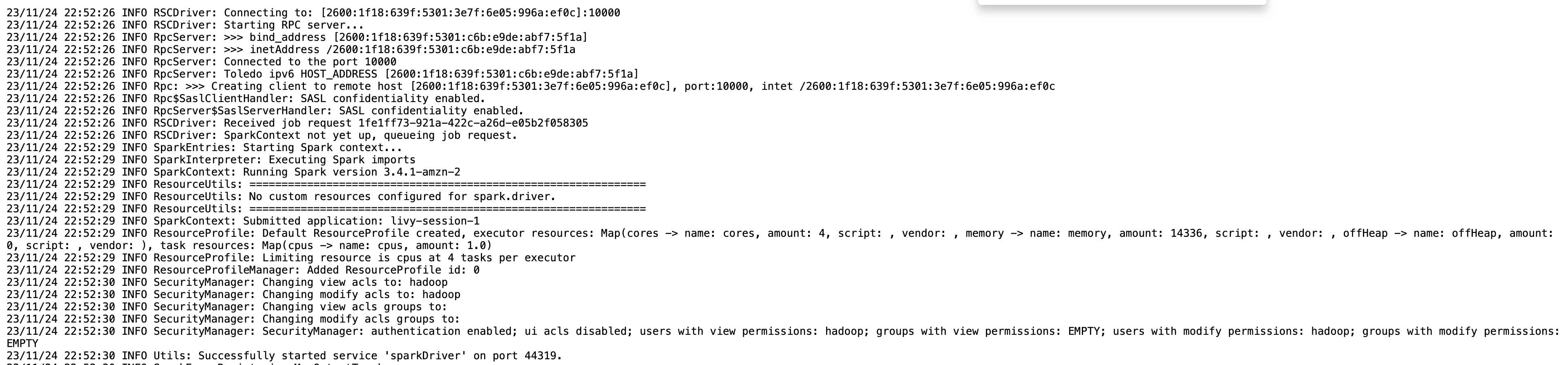
Você pode obter as informações da sessão para seu endpoint Livy usando o %%info Faísca mágica. Isso fornece links para acessar a UI do Spark, bem como o log do driver diretamente no seu notebook.

A captura de tela a seguir é um trecho de log do driver para nosso aplicativo, que abrimos por meio do link em nosso notebook.
Da mesma forma, você pode escolher o link abaixo IU do Spark para abrir a IU. A captura de tela a seguir mostra o Executores guia, que fornece acesso aos logs do driver e do executor.

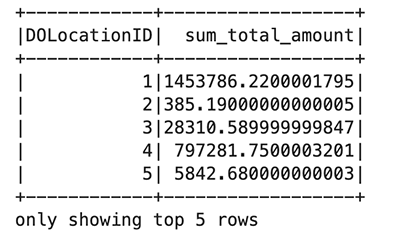
A captura de tela a seguir mostra o estágio 14, que corresponde à etapa do Spark SQL que vimos anteriormente, na qual calculamos a soma da localização do total de coletas de táxi, que foi dividida em 12 tarefas. Por meio da IU do Spark, o aplicativo interativo fornece status detalhado no nível da tarefa, E/S e detalhes de embaralhamento, bem como links para logs correspondentes para cada tarefa neste estágio diretamente do seu notebook, permitindo uma experiência de solução de problemas perfeita.
limpar
Se você não quiser mais manter os recursos criados nesta postagem, conclua as seguintes etapas de limpeza:
- Exclua o aplicativo EMR Serverless.
- Exclua o EMR Studio e os espaços de trabalho e notebooks associados.
- Para excluir o restante dos recursos, navegue até o console do CloudFormation, selecione a pilha e escolha Apagar.
Todos os recursos serão excluídos, exceto o bucket S3, que tem sua política de exclusão definida para retenção.
Conclusão
A postagem mostrou como executar cargas de trabalho PySpark interativas no EMR Studio usando EMR Serverless como computação. Você também pode criar e monitorar aplicativos Spark em um JupyterLab Workspace interativo.
Em uma próxima postagem, discutiremos recursos adicionais de aplicativos EMR Serverless Interactive, como:
- Trabalhar com recursos como Amazon RDS e Amazon Redshift em sua VPC (por exemplo, para conectividade JDBC/ODBC)
- Executando cargas de trabalho transacionais usando endpoints sem servidor
Se esta é a primeira vez que você explora o EMR Studio, recomendamos verificar o Workshops Amazon EMR e referindo-se a Criar um estúdio EMR.
Sobre os autores
 Sekar Srinivasan é arquiteto de soluções especialista principal na AWS com foco em análise de dados e IA. Sekar tem mais de 20 anos de experiência trabalhando com dados. Ele é apaixonado por ajudar os clientes a criar soluções escaláveis, modernizando sua arquitetura e gerando insights a partir de seus dados. Nas horas vagas gosta de trabalhar em projetos sem fins lucrativos, focados na educação de crianças carentes.
Sekar Srinivasan é arquiteto de soluções especialista principal na AWS com foco em análise de dados e IA. Sekar tem mais de 20 anos de experiência trabalhando com dados. Ele é apaixonado por ajudar os clientes a criar soluções escaláveis, modernizando sua arquitetura e gerando insights a partir de seus dados. Nas horas vagas gosta de trabalhar em projetos sem fins lucrativos, focados na educação de crianças carentes.
 Disha Umarwani é arquiteto de dados sênior da Amazon Professional Services nas áreas de Global Health Care e LifeSciences. Ela trabalhou com clientes para projetar, arquitetar e implementar estratégias de dados em escala. Ela é especialista em arquitetar arquiteturas Data Mesh para plataformas corporativas.
Disha Umarwani é arquiteto de dados sênior da Amazon Professional Services nas áreas de Global Health Care e LifeSciences. Ela trabalhou com clientes para projetar, arquitetar e implementar estratégias de dados em escala. Ela é especialista em arquitetar arquiteturas Data Mesh para plataformas corporativas.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio/