
Asistenții de inteligență artificială (AI) conversaționale sunt proiectați pentru a oferi răspunsuri precise, în timp real, prin direcționarea inteligentă a interogărilor către cele mai potrivite funcții AI. Cu servicii AI generative AWS, cum ar fi Amazon Bedrock, dezvoltatorii pot crea sisteme care gestionează în mod expert și răspund solicitărilor utilizatorilor. Amazon Bedrock este un serviciu complet gestionat care oferă o gamă de modele de fundație (FM) de înaltă performanță de la companii de IA de vârf, cum ar fi AI21 Labs, Anthropic, Cohere, Meta, Stability AI și Amazon folosind un singur API, împreună cu un set larg de capabilități de care aveți nevoie pentru a construi aplicații AI generative cu securitate, confidențialitate și AI responsabilă.
Acest post evaluează două abordări principale pentru dezvoltarea asistenților AI: utilizarea serviciilor gestionate, cum ar fi Agenți pentru Amazon Bedrockși utilizând tehnologii open source precum LangChain. Explorăm avantajele și provocările fiecăruia, astfel încât să puteți alege calea cea mai potrivită nevoilor dumneavoastră.
Ce este un asistent AI?
Un asistent AI este un sistem inteligent care înțelege interogările în limbaj natural și interacționează cu diverse instrumente, surse de date și API-uri pentru a efectua sarcini sau a prelua informații în numele utilizatorului. Asistenții AI eficienți posedă următoarele capacități cheie:
- Procesarea limbajului natural (NLP) și fluxul conversațional
- Integrarea bazei de cunoștințe și căutări semantice pentru a înțelege și a regăsi informații relevante pe baza nuanțelor contextului conversației
- Rularea sarcinilor, cum ar fi interogări de baze de date și personalizate AWS Lambdas funcții
- Gestionarea conversațiilor specializate și a solicitărilor utilizatorilor
Demonstrăm beneficiile asistenților AI folosind managementul dispozitivelor Internet of Things (IoT) ca exemplu. În acest caz de utilizare, AI îi poate ajuta pe tehnicieni să gestioneze eficient utilajele cu comenzi care preiau date sau automatizează sarcini, simplificând operațiunile din producție.
Agenții pentru Amazon Bedrock se apropie
Agenți pentru Amazon Bedrock vă permite să construiți aplicații AI generative care pot rula sarcini în mai mulți pași în sistemele și sursele de date ale unei companii. Oferă următoarele capacități cheie:
- Creare automată promptă din instrucțiuni, detalii API și informații despre sursa de date, economisind săptămâni de efort de inginerie promptă
- Retrieval Augmented Generation (RAG) pentru a conecta în siguranță agenții la sursele de date ale unei companii și pentru a oferi răspunsuri relevante
- Orchestrarea și rularea sarcinilor în mai mulți pași prin împărțirea cererilor în secvențe logice și apelarea API-urilor necesare
- Vizibilitate în raționamentul agentului printr-o urmărire a lanțului de gândire (CoT), permițând depanarea și direcționarea comportamentului modelului
- Abilități de inginerie promptă pentru a modifica șablonul de prompt generat automat pentru un control îmbunătățit asupra agenților
Puteți utiliza agenți pentru Amazon Bedrock și Baze de cunoștințe pentru Amazon Bedrock pentru a construi și a implementa asistenți AI pentru cazuri de utilizare complexe de rutare. Acestea oferă un avantaj strategic pentru dezvoltatori și organizații prin simplificarea managementului infrastructurii, îmbunătățirea scalabilității, îmbunătățirea securității și reducerea sarcinilor grele nediferențiate. Ele permit, de asemenea, un cod de nivel de aplicație mai simplu, deoarece logica de rutare, vectorizarea și memoria sunt gestionate complet.
Prezentare generală a soluțiilor
Această soluție introduce un asistent AI conversațional adaptat pentru gestionarea și operațiunile dispozitivelor IoT atunci când utilizați Claude v2.1 de la Anthropic pe Amazon Bedrock. Funcționalitatea de bază a asistentului AI este guvernată de un set cuprinzător de instrucțiuni, cunoscut sub numele de a prompt de sistem, care își delimitează capacitățile și domeniile de expertiză. Acest ghid se asigură că asistentul AI poate gestiona o gamă largă de sarcini, de la gestionarea informațiilor despre dispozitiv până la rularea comenzilor operaționale.
Echipat cu aceste capabilități, așa cum este detaliat în promptul de sistem, asistentul AI urmează un flux de lucru structurat pentru a răspunde întrebărilor utilizatorilor. Următoarea figură oferă o reprezentare vizuală a acestui flux de lucru, ilustrând fiecare pas de la interacțiunea inițială a utilizatorului până la răspunsul final.
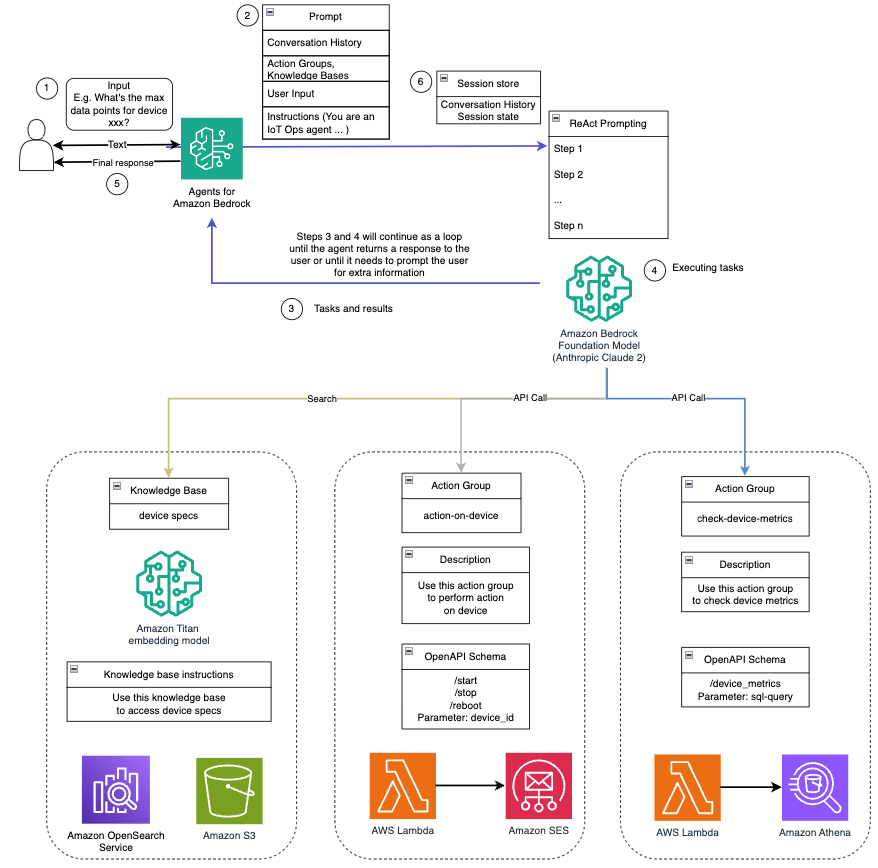
Fluxul de lucru este compus din următorii pași:
- Procesul începe atunci când un utilizator solicită asistentului să efectueze o sarcină; de exemplu, solicitarea punctelor de date maxime pentru un anumit dispozitiv IoT
device_xxx. Această introducere de text este capturată și trimisă asistentului AI. - Asistentul AI interpretează textul introdus de utilizator. Utilizează istoricul conversațiilor furnizate, grupurile de acțiune și bazele de cunoștințe pentru a înțelege contextul și a determina sarcinile necesare.
- După ce intenția utilizatorului este analizată și înțeleasă, asistentul AI definește sarcinile. Aceasta se bazează pe instrucțiunile care sunt interpretate de asistent conform promptului de sistem și a intrării utilizatorului.
- Sarcinile sunt apoi rulate printr-o serie de apeluri API. Acest lucru se face folosind Reacţiona prompting, care descompune sarcina într-o serie de pași care sunt procesați secvențial:
- Pentru verificările valorilor dispozitivului, folosim
check-device-metricsgrup de acțiuni, care implică un apel API la funcțiile Lambda care apoi interogează Amazon Atena pentru datele solicitate. - Pentru acțiuni directe ale dispozitivului, cum ar fi pornirea, oprirea sau repornirea, folosim
action-on-devicegrup de acțiuni, care invocă o funcție Lambda. Această funcție inițiază un proces care trimite comenzi către dispozitivul IoT. Pentru această postare, funcția Lambda trimite notificări folosind Serviciul de e-mail simplu Amazon (Amazon SES). - Folosim baze de cunoștințe pentru Amazon Bedrock pentru a prelua din datele istorice stocate ca încorporare în Serviciul Amazon OpenSearch baza de date vectoriala.
- Pentru verificările valorilor dispozitivului, folosim
- După ce sarcinile sunt finalizate, răspunsul final este generat de Amazon Bedrock FM și transmis înapoi utilizatorului.
- Agenții pentru Amazon Bedrock stochează automat informații folosind o sesiune cu stare pentru a menține aceeași conversație. Starea este ștearsă după expirarea unui timeout configurabil de inactivitate.
Prezentare tehnică
Următoarea diagramă ilustrează arhitectura pentru implementarea unui asistent AI cu agenți pentru Amazon Bedrock.
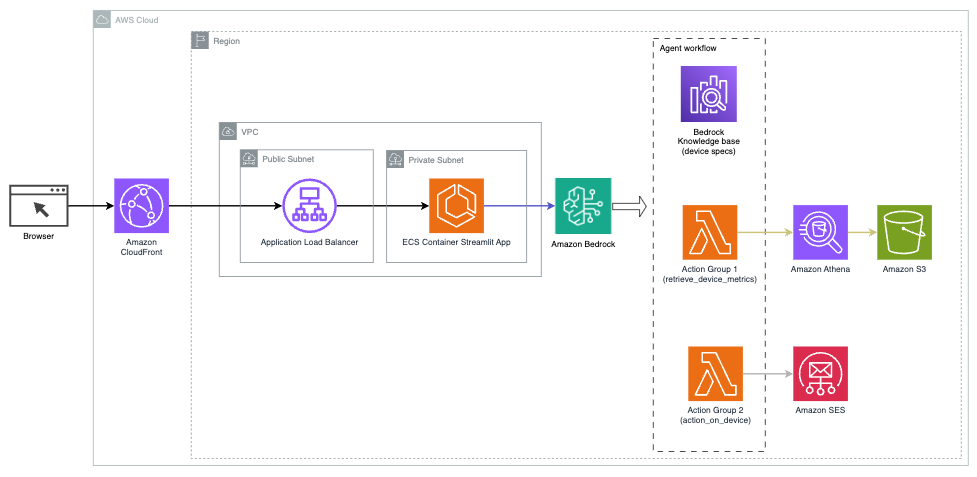
Este alcătuit din următoarele componente cheie:
- Interfață conversațională – Interfața conversațională folosește Streamlit, o bibliotecă open source Python care simplifică crearea de aplicații web personalizate, atractive vizual pentru învățarea automată (ML) și știința datelor. Este găzduit pe Serviciul Amazon de containere elastice (Amazon ECS) cu AWS Fargateși este accesat folosind un aplicație Load Balancer. Puteți utiliza Fargate cu Amazon ECS pentru a rula containere fără a fi nevoie să gestionați servere, clustere sau mașini virtuale.
- Agenți pentru Amazon Bedrock – Agenții pentru Amazon Bedrock completează interogările utilizatorilor printr-o serie de pași de raționament și acțiuni corespunzătoare bazate pe Solicitarea ReAct:
- Baze de cunoștințe pentru Amazon Bedrock – Bazele de cunoștințe pentru Amazon Bedrock oferă complet gestionate CÂRPĂ pentru a oferi asistentului AI acces la datele dvs. În cazul nostru de utilizare, am încărcat specificațiile dispozitivului într-un Serviciul Amazon de stocare simplă (Amazon S3) găleată. Acesta servește ca sursă de date pentru baza de cunoștințe.
- Grupuri de acțiune – Acestea sunt scheme API definite care invocă anumite funcții Lambda pentru a interacționa cu dispozitivele IoT și alte servicii AWS.
- Anthropic Claude v2.1 pe Amazon Bedrock – Acest model interpretează interogările utilizatorilor și orchestrează fluxul de sarcini.
- Amazon Titan Embeddings – Acest model servește ca model de încorporare a textului, transformând textul în limbaj natural – de la cuvinte simple la documente complexe – în vectori numerici. Acest lucru permite capabilități de căutare vectorială, permițând sistemului să potrivească semantic interogările utilizatorilor cu cele mai relevante intrări din baza de cunoștințe pentru o căutare eficientă.
Soluția este integrată cu servicii AWS, cum ar fi Lambda pentru rularea codului ca răspuns la apelurile API, Athena pentru interogarea seturi de date, OpenSearch Service pentru căutarea prin baze de cunoștințe și Amazon S3 pentru stocare. Aceste servicii lucrează împreună pentru a oferi o experiență perfectă pentru gestionarea operațiunilor dispozitivelor IoT prin comenzi în limbaj natural.
Beneficii
Această soluție oferă următoarele beneficii:
- Complexitatea implementării:
- Sunt necesare mai puține linii de cod, deoarece agenții pentru Amazon Bedrock retrag o mare parte din complexitatea de bază, reducând efortul de dezvoltare
- Gestionarea bazelor de date vectoriale precum OpenSearch Service este simplificată, deoarece bazele de cunoștințe pentru Amazon Bedrock gestionează vectorizarea și stocarea
- Integrarea cu diverse servicii AWS este mai eficientă prin grupuri de acțiuni predefinite
- Experiență de dezvoltator:
- Consola Amazon Bedrock oferă o interfață ușor de utilizat pentru dezvoltare rapidă, testare și analiza cauzei principale (RCA), îmbunătățind experiența generală a dezvoltatorului
- Agilitate și flexibilitate:
- Agenții pentru Amazon Bedrock permit upgrade-uri fără probleme la FM mai noi (cum ar fi Claude 3.0) atunci când acestea devin disponibile, astfel încât soluția dvs. să fie la curent cu cele mai recente progrese
- Cotele și limitările de servicii sunt gestionate de AWS, reducând costul general al infrastructurii de monitorizare și scalare
- De securitate:
- Amazon Bedrock este un serviciu complet gestionat, care aderă la standardele stricte de securitate și conformitate ale AWS, simplificând potențial analizele de securitate organizaționale
Deși Agents for Amazon Bedrock oferă o soluție simplificată și gestionată pentru construirea de aplicații AI conversaționale, unele organizații pot prefera o abordare open source. În astfel de cazuri, puteți utiliza cadre precum LangChain, despre care vom discuta în secțiunea următoare.
Abordarea dinamică de rutare LangChain
LangChain este un cadru open source care simplifică construirea IA conversațională, permițând integrarea modelelor de limbaj mari (LLM) și a capabilităților de rutare dinamică. Cu LangChain Expression Language (LCEL), dezvoltatorii pot defini rutare, care vă permite să creați lanțuri nedeterministe în care rezultatul unui pas anterior definește pasul următor. Rutarea ajută la asigurarea structurii și coerenței interacțiunilor cu LLM-urile.
Pentru această postare, folosim același exemplu ca asistentul AI pentru gestionarea dispozitivelor IoT. Cu toate acestea, principala diferență este că trebuie să gestionăm solicitările de sistem separat și să tratăm fiecare lanț ca pe o entitate separată. Lanțul de rutare decide lanțul de destinație în funcție de intrarea utilizatorului. Decizia este luată cu sprijinul unui LLM prin transmiterea promptului de sistem, a istoricului de chat și a întrebării utilizatorului.
Prezentare generală a soluțiilor
Următoarea diagramă ilustrează fluxul de lucru al soluției de rutare dinamică.
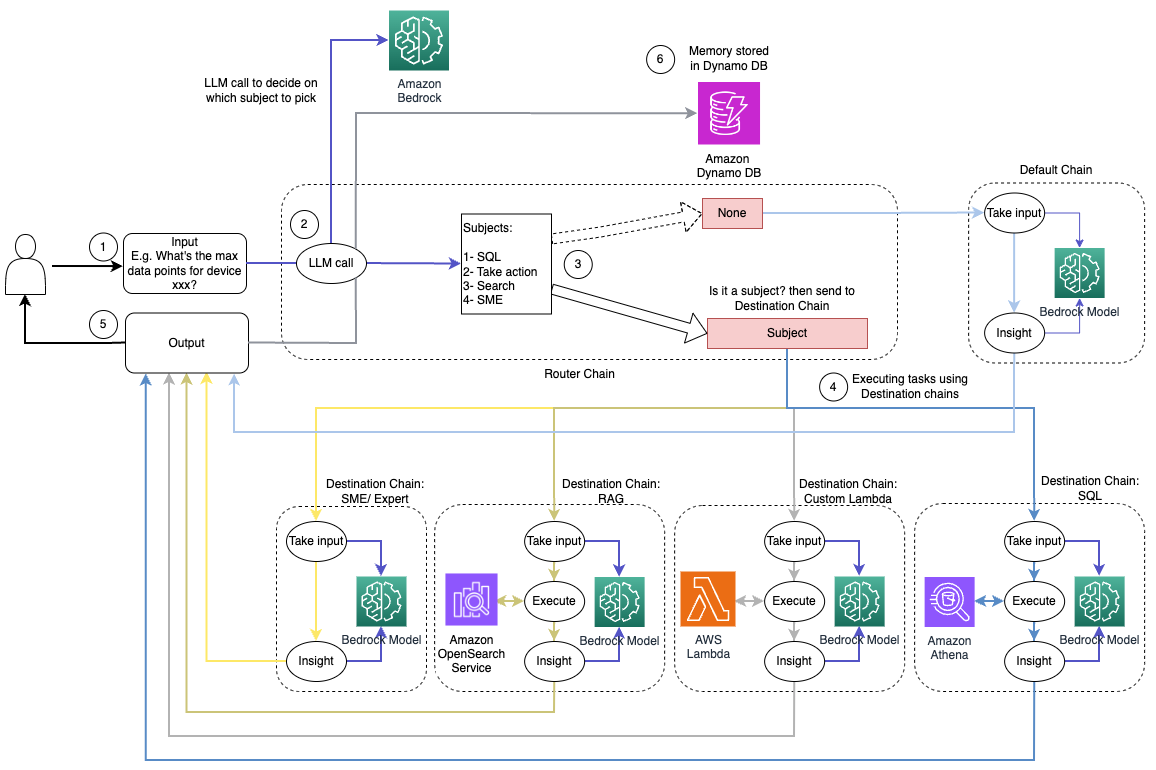
Fluxul de lucru constă din următorii pași:
- Utilizatorul prezintă o întrebare asistentului AI. De exemplu, „Care sunt valorile maxime pentru dispozitivul 1009?”
- Un LLM evaluează fiecare întrebare împreună cu istoricul chat-ului din aceeași sesiune pentru a determina natura acesteia și în ce domeniu se încadrează (cum ar fi SQL, acțiune, căutare sau SME). LLM clasifică intrarea, iar lanțul de rutare LCEL preia acea intrare.
- Lanțul de router selectează lanțul de destinație pe baza intrării, iar LLM este furnizat cu următorul prompt de sistem:
LLM evaluează întrebarea utilizatorului împreună cu istoricul chat-ului pentru a determina natura interogării și în ce domeniu se încadrează. LLM clasifică apoi intrarea și emite un răspuns JSON în următorul format:
Lanțul de router folosește acest răspuns JSON pentru a invoca lanțul de destinație corespunzător. Există patru lanțuri de destinații specifice unui subiect, fiecare cu propriul prompt de sistem:
- Interogările legate de SQL sunt trimise la lanțul de destinație SQL pentru interacțiunile bazei de date. Puteți utiliza LCEL pentru a construi Lanț SQL.
- Întrebările orientate spre acțiune invocă lanțul de destinații Lambda personalizat pentru operațiunile de rulare. Cu LCEL, vă puteți defini propriul dvs funcție personalizată; în cazul nostru, este o funcție pentru a rula o funcție Lambda predefinită pentru a trimite un e-mail cu un ID de dispozitiv analizat. Un exemplu de intrare de utilizator ar putea fi „Opriți dispozitivul 1009”.
- Cererile axate pe căutare trec la CÂRPĂ lanț de destinație pentru regăsirea informațiilor.
- Întrebările legate de IMM-uri sunt adresate lanțului de destinații pentru IMM-uri/experți pentru informații specializate.
- Fiecare lanț de destinații preia intrarea și rulează modelele sau funcțiile necesare:
- Lanțul SQL folosește Athena pentru a rula interogări.
- Lanțul RAG utilizează serviciul OpenSearch pentru căutare semantică.
- Lanțul Lambda personalizat rulează funcții Lambda pentru acțiuni.
- Lanțul de IMM-uri/experți oferă informații folosind modelul Amazon Bedrock.
- Răspunsurile din fiecare lanț de destinații sunt formulate în perspective coerente de către LLM. Aceste informații sunt apoi livrate utilizatorului, completând ciclul de interogare.
- Intrările și răspunsurile utilizatorului sunt stocate în Amazon DynamoDB pentru a oferi context LLM pentru sesiunea curentă și din interacțiunile anterioare. Durata informațiilor persistente în DynamoDB este controlată de aplicație.
Prezentare tehnică
Următoarea diagramă ilustrează arhitectura soluției de rutare dinamică LangChain.

Aplicația web este construită pe Streamlit găzduit pe Amazon ECS cu Fargate și este accesată folosind un aplicație Load Balancer. Utilizăm Claude v2.1 de la Anthropic pe Amazon Bedrock ca LLM. Aplicația web interacționează cu modelul folosind bibliotecile LangChain. De asemenea, interacționează cu o varietate de alte servicii AWS, cum ar fi OpenSearch Service, Athena și DynamoDB, pentru a satisface nevoile utilizatorilor finali.
Beneficii
Această soluție oferă următoarele beneficii:
- Complexitatea implementării:
- Deși necesită mai mult cod și dezvoltare personalizată, LangChain oferă o mai mare flexibilitate și control asupra logicii de rutare și integrarea cu diferite componente.
- Gestionarea bazelor de date vectoriale precum OpenSearch Service necesită eforturi suplimentare de configurare și configurare. Procesul de vectorizare este implementat în cod.
- Integrarea cu serviciile AWS poate implica mai multe coduri și configurații personalizate.
- Experiență de dezvoltator:
- Abordarea bazată pe Python a lui LangChain și documentația extinsă pot fi atrăgătoare pentru dezvoltatorii deja familiarizați cu Python și instrumentele open source.
- Dezvoltarea și depanarea promptă pot necesita mai mult efort manual în comparație cu utilizarea consolei Amazon Bedrock.
- Agilitate și flexibilitate:
- LangChain acceptă o gamă largă de LLM, permițându-vă să comutați între diferite modele sau furnizori, favorizând flexibilitatea.
- Natura open source a LangChain permite îmbunătățiri și personalizări conduse de comunitate.
- De securitate:
- Ca cadru open source, LangChain poate necesita revizuiri și verificări de securitate mai riguroase în cadrul organizațiilor, adăugând potențial cheltuieli generale.
Concluzie
Asistenții AI conversaționali sunt instrumente transformatoare pentru eficientizarea operațiunilor și îmbunătățirea experienței utilizatorilor. Această postare a explorat două abordări puternice folosind serviciile AWS: agenții gestionați pentru Amazon Bedrock și rutarea dinamică LangChain, flexibilă, open source. Alegerea dintre aceste abordări depinde de cerințele organizației dvs., de preferințele de dezvoltare și de nivelul dorit de personalizare. Indiferent de calea urmată, AWS vă dă putere să creați asistenți inteligenți AI care revoluționează interacțiunile de afaceri și cu clienții
Găsiți codul soluției și elementele de implementare în sistemul nostru GitHub depozit, unde puteți urma pașii detaliați pentru fiecare abordare AI conversațională.
Despre Autori
 Ameer Hakme este un arhitect de soluții AWS cu sediul în Pennsylvania. El colaborează cu furnizori independenți de software (ISV) din regiunea de nord-est, asistându-i în proiectarea și construirea de platforme scalabile și moderne pe AWS Cloud. Expert în AI/ML și AI generativă, Ameer ajută clienții să deblocheze potențialul acestor tehnologii de ultimă oră. În timpul liber, îi place să meargă cu motocicleta și să petreacă timp de calitate cu familia.
Ameer Hakme este un arhitect de soluții AWS cu sediul în Pennsylvania. El colaborează cu furnizori independenți de software (ISV) din regiunea de nord-est, asistându-i în proiectarea și construirea de platforme scalabile și moderne pe AWS Cloud. Expert în AI/ML și AI generativă, Ameer ajută clienții să deblocheze potențialul acestor tehnologii de ultimă oră. În timpul liber, îi place să meargă cu motocicleta și să petreacă timp de calitate cu familia.
 Sharon Li este arhitect de soluții AI/ML la Amazon Web Services cu sediul în Boston, cu o pasiune pentru proiectarea și construirea de aplicații AI generative pe AWS. Ea colaborează cu clienții pentru a folosi serviciile AWS AI/ML pentru soluții inovatoare.
Sharon Li este arhitect de soluții AI/ML la Amazon Web Services cu sediul în Boston, cu o pasiune pentru proiectarea și construirea de aplicații AI generative pe AWS. Ea colaborează cu clienții pentru a folosi serviciile AWS AI/ML pentru soluții inovatoare.
 Kawsar Kamal este un arhitect senior de soluții la Amazon Web Services cu peste 15 ani de experiență în domeniul automatizării infrastructurii și al securității. El îi ajută pe clienți să proiecteze și să construiască soluții scalabile DevSecOps și AI/ML în cloud.
Kawsar Kamal este un arhitect senior de soluții la Amazon Web Services cu peste 15 ani de experiență în domeniul automatizării infrastructurii și al securității. El îi ajută pe clienți să proiecteze și să construiască soluții scalabile DevSecOps și AI/ML în cloud.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/