
Această postare este co-scrisă de Goktug Cinar, Michael Binder și Adrian Horvath de la Bosch Center for Artificial Intelligence (BCAI).
Prognoza veniturilor este o sarcină provocatoare, dar crucială pentru deciziile strategice de afaceri și planificarea fiscală în majoritatea organizațiilor. Adesea, prognoza veniturilor este efectuată manual de analiștii financiari și este atât consumatoare de timp, cât și subiectivă. Astfel de eforturi manuale sunt deosebit de provocatoare pentru organizațiile de afaceri multinaționale la scară largă, care necesită previziuni ale veniturilor într-o gamă largă de grupuri de produse și zone geografice la mai multe niveluri de granularitate. Acest lucru necesită nu numai acuratețe, ci și coerență ierarhică a previziunilor.
Bosch este o corporație multinațională cu entități care operează în mai multe sectoare, inclusiv auto, soluții industriale și bunuri de larg consum. Având în vedere impactul previziunilor precise și coerente ale veniturilor asupra operațiunilor de afaceri sănătoase, Centrul Bosch pentru Inteligență Artificială (BCAI) a investit masiv în utilizarea învățării automate (ML) pentru a îmbunătăți eficiența și acuratețea proceselor de planificare financiară. Scopul este de a atenua procesele manuale prin furnizarea de previziuni rezonabile privind veniturile de bază prin ML, cu doar ajustări ocazionale necesare de către analiștii financiari folosind cunoștințele lor din domeniu și domeniu.
Pentru a atinge acest obiectiv, BCAI a dezvoltat un cadru intern de prognoză capabil să ofere prognoze ierarhice la scară largă prin ansambluri personalizate ale unei game largi de modele de bază. Un meta-învățator selectează cele mai performante modele pe baza caracteristicilor extrase din fiecare serie temporală. Prognozele din modelele selectate sunt apoi mediate pentru a obține prognoza agregată. Designul arhitectural este modularizat și extensibil prin implementarea unei interfețe în stil REST, care permite îmbunătățirea continuă a performanței prin includerea de modele suplimentare.
BCAI a colaborat cu Laboratorul Amazon ML Solutions (MLSL) pentru a încorpora cele mai recente progrese în modelele bazate pe rețelele neuronale profunde (DNN) pentru prognoza veniturilor. Progresele recente în prognozele neuronale au demonstrat performanțe de ultimă generație pentru multe probleme practice de prognoză. În comparație cu modelele tradiționale de prognoză, mulți meteorologi neuronali pot încorpora covariate sau metadate suplimentare ale seriei de timp. Includem CNN-QR și DeepAR+, două modele standard Prognoza Amazon, precum și un model personalizat Transformer antrenat folosind Amazon SageMaker. Cele trei modele acoperă un set reprezentativ al codificatoarelor folosite adesea în prognozele neuronale: rețeaua neuronală convoluțională (CNN), rețeaua neuronală recurentă secvențială (RNN) și codificatoarele bazate pe transformator.
Una dintre provocările cheie cu care se confruntă parteneriatul BCAI-MLSL a fost furnizarea de previziuni solide și rezonabile sub impactul COVID-19, un eveniment global fără precedent care provoacă o mare volatilitate asupra rezultatelor financiare globale ale companiilor. Deoarece prognozatorii neuronali sunt instruiți pe date istorice, prognozele generate pe baza datelor din afara distribuției din perioadele mai volatile ar putea fi inexacte și nesigure. Prin urmare, am propus adăugarea unui mecanism de atenție mascat în arhitectura Transformer pentru a aborda această problemă.
Prognozatorii neuronali pot fi grupați ca un singur model de ansamblu sau încorporați individual în universul modelului Bosch și accesați cu ușurință prin punctele finale REST API. Propunem o abordare a ansamblului prognozatorilor neuronali prin rezultate backtest, care oferă performanțe competitive și robuste în timp. În plus, am investigat și evaluat o serie de tehnici clasice de reconciliere ierarhică pentru a ne asigura că previziunile sunt agregate în mod coerent între grupurile de produse, zonele geografice și organizațiile de afaceri.
În această postare, demonstrăm următoarele:
- Cum să aplicați instruirea pentru modele personalizate Forecast și SageMaker pentru probleme ierarhice, la scară largă de prognoză a serii de timp
- Cum să asociezi modele personalizate cu modele disponibile de la Forecast
- Cum să reduceți impactul evenimentelor perturbatoare, cum ar fi COVID-19, asupra problemelor de prognoză
- Cum să construiți un flux de lucru de prognoză end-to-end pe AWS
Provocări
Am abordat două provocări: crearea de previziuni ierarhice, pe scară largă, a veniturilor și impactul pandemiei de COVID-19 asupra prognozei pe termen lung.
Estimare ierarhică a veniturilor pe scară largă
Analiștii financiari au sarcina de a prognoza cifrele financiare cheie, inclusiv veniturile, costurile operaționale și cheltuielile de cercetare și dezvoltare. Aceste valori oferă informații despre planificarea afacerii la diferite niveluri de agregare și permit luarea deciziilor bazate pe date. Orice soluție automată de prognoză trebuie să ofere prognoze la orice nivel arbitrar de agregare a liniilor de afaceri. La Bosch, agregările pot fi imaginate ca serii de timp grupate ca o formă mai generală de structură ierarhică. Figura următoare prezintă un exemplu simplificat cu o structură pe două niveluri, care imită structura ierarhică de prognoză a veniturilor la Bosch. Venitul total este împărțit în mai multe niveluri de agregare în funcție de produs și regiune.
Numărul total de serii temporale care trebuie prognozate la Bosch este la scara de milioane. Observați că seria temporală de nivel superior poate fi împărțită fie pe produse, fie pe regiuni, creând mai multe căi către prognozele de nivel inferior. Venitul trebuie prognozat la fiecare nod din ierarhie cu un orizont de prognoză de 12 luni în viitor. Datele istorice lunare sunt disponibile.
Structura ierarhică poate fi reprezentată folosind următoarea formă cu notarea unei matrice de însumare S (Hyndman și Athanasopoulos):
![]()
În această ecuație, Y este egal cu următoarele:

Aici, b reprezintă seria temporală de nivel inferior la timp t.
Impactul pandemiei de COVID-19
Pandemia de COVID-19 a adus provocări semnificative pentru prognoză, datorită efectelor sale perturbatoare și fără precedent asupra aproape tuturor aspectelor muncii și vieții sociale. Pentru prognoza veniturilor pe termen lung, întreruperea a adus și efecte neașteptate în aval. Pentru a ilustra această problemă, următoarea figură prezintă un exemplu de serie de timp în care veniturile din produse au cunoscut o scădere semnificativă la începutul pandemiei și s-au recuperat treptat ulterior. Un model tipic de prognoză neuronală va lua date despre venituri, inclusiv perioada COVID în afara distribuției (OOD) ca intrare de context istoric, precum și adevărul de bază pentru formarea modelului. Ca urmare, prognozele produse nu mai sunt de încredere.

Abordări de modelare
În această secțiune, discutăm diferitele noastre abordări de modelare.
Prognoza Amazon
Forecast este un serviciu AI/ML complet gestionat de la AWS, care oferă modele preconfigurate, de ultimă generație, de prognoză în serie de timp. Combină aceste oferte cu capabilitățile sale interne pentru optimizarea automată a hiperparametrilor, modelarea ansamblului (pentru modelele furnizate de Forecast) și generarea de prognoze probabilistice. Acest lucru vă permite să ingerați cu ușurință seturi de date personalizate, să preprocesați datele, să pregătiți modele de prognoză și să generați previziuni solide. Designul modular al serviciului ne permite în continuare să interogăm cu ușurință și să combinăm predicții din modele personalizate suplimentare dezvoltate în paralel.
Încorporăm doi prognozatori neuronali de la Forecast: CNN-QR și DeepAR+. Ambele sunt metode de învățare profundă supravegheate care antrenează un model global pentru întregul set de date din seria temporală. Atât modelele CNNQR, cât și DeepAR+ pot prelua informații de metadate statice despre fiecare serie de timp, care sunt produsul, regiunea și organizația comercială corespunzătoare în cazul nostru. De asemenea, adaugă automat caracteristici temporale, cum ar fi luna anului, ca parte a intrării în model.
Transformator cu măști de atenție pentru COVID
Arhitectura transformatorului (Vaswani şi colab.), conceput inițial pentru procesarea limbajului natural (NLP), a apărut recent ca o alegere arhitecturală populară pentru prognoza serii cronologice. Aici, am folosit arhitectura Transformer descrisă în Zhou şi colab. fără log probabilistică atenție rară. Modelul folosește un design tipic de arhitectură prin combinarea unui encoder și a unui decodor. Pentru prognoza veniturilor, configurăm decodorul să scoată direct prognoza orizontului de 12 luni, în loc să generăm prognoza lună de lună într-o manieră autoregresivă. Pe baza frecvenței seriei de timp, sunt adăugate caracteristici suplimentare legate de timp, cum ar fi luna anului, ca variabilă de intrare. Variabilele categoriale suplimentare care descriu metainformațiile (produs, regiune, organizație comercială) sunt introduse în rețea printr-un strat de încorporare care poate fi antrenat.
Următoarea diagramă ilustrează arhitectura Transformerului și mecanismul de mascare a atenției. Mascarea atenției este aplicată în toate straturile de codificator și decodor, așa cum este evidențiat în portocaliu, pentru a preveni ca datele OOD să afecteze prognozele.

Atenuăm impactul ferestrelor de context OOD adăugând măști de atenție. Modelul este antrenat să acorde foarte puțină atenție perioadei COVID care conține valori aberante prin mascare și efectuează prognoze cu informații mascate. Masca de atenție este aplicată în fiecare strat al arhitecturii decodorului și codificatorului. Fereastra mascata poate fi specificata manual sau printr-un algoritm de detectare a valorii aberante. În plus, atunci când se utilizează o fereastră de timp care conține valori aberante ca etichete de antrenament, pierderile nu sunt propagate înapoi. Această metodă bazată pe mascarea atenției poate fi aplicată pentru a gestiona întreruperile și cazurile OOD aduse de alte evenimente rare și pentru a îmbunătăți robustețea prognozelor.
Ansamblu model
Ansamblul de modele depășește adesea modelele individuale pentru prognoză – îmbunătățește generalizarea modelului și este mai bine să gestioneze datele din seria temporală cu caracteristici diferite de periodicitate și intermitență. Încorporăm o serie de strategii de ansamblu de modele pentru a îmbunătăți performanța modelului și robustețea prognozelor. O formă comună de ansamblu de modele de învățare profundă este agregarea rezultatelor din rulări de model cu diferite inițializări aleatorii ale greutății sau din diferite epoci de antrenament. Utilizăm această strategie pentru a obține prognoze pentru modelul Transformer.
Pentru a construi în continuare un ansamblu pe deasupra diferitelor arhitecturi de model, cum ar fi Transformer, CNNQR și DeepAR+, folosim o strategie de ansamblu pan-model care selectează cele mai bune modele cu cele mai bune performanțe pentru fiecare serie de timp pe baza rezultatelor backtestului și le obținem. medii. Deoarece rezultatele backtest pot fi exportate direct din modele de prognoză instruite, această strategie ne permite să profităm de servicii la cheie precum Forecast cu îmbunătățiri obținute din modele personalizate, cum ar fi Transformer. O astfel de abordare a ansamblului de modele de la capăt la capăt nu necesită formarea unui meta-învățator sau calcularea caracteristicilor seriei temporale pentru selectarea modelului.
Reconcilierea ierarhică
Cadrul este adaptabil pentru a încorpora o gamă largă de tehnici ca pași de postprocesare pentru reconcilierea ierarhică a prognozei, inclusiv de jos în sus (BU), reconciliere de sus în jos cu proporții de prognoză (TDFP), cel mai mic pătrat obișnuit (OLS) și cel mai mic pătrat ponderat ( WLS). Toate rezultatele experimentale din această postare sunt raportate folosind reconcilierea de sus în jos cu proporții de prognoză.
Privire de ansamblu asupra arhitecturii
Am dezvoltat un flux de lucru automatizat end-to-end pe AWS pentru a genera previziuni de venituri utilizând servicii precum Forecast, SageMaker, Serviciul Amazon de stocare simplă (Amazon S3), AWS Lambdas, Funcții pas AWS, și Kit AWS Cloud Development (AWS CDK). Soluția implementată oferă previziuni individuale în serie de timp printr-un API REST folosind Gateway API Amazon, prin returnarea rezultatelor în format JSON predefinit.
Următoarea diagramă ilustrează fluxul de lucru de prognoză end-to-end.

Considerațiile cheie de proiectare pentru arhitectură sunt versatilitatea, performanța și ușurința în utilizare. Sistemul ar trebui să fie suficient de versatil pentru a încorpora un set divers de algoritmi în timpul dezvoltării și implementării, cu modificări minime necesare și poate fi extins cu ușurință atunci când se adaugă noi algoritmi în viitor. Sistemul ar trebui, de asemenea, să adauge o suprasarcină minimă și să suporte formarea paralelă atât pentru Forecast, cât și pentru SageMaker, pentru a reduce timpul de antrenament și pentru a obține cea mai recentă prognoză mai rapid. În cele din urmă, sistemul ar trebui să fie simplu de utilizat în scopuri de experimentare.
Fluxul de lucru end-to-end rulează secvenţial prin următoarele module:
- Un modul de preprocesare pentru reformatarea și transformarea datelor
- Un modul de formare model care încorporează atât modelul Forecast, cât și modelul personalizat pe SageMaker (ambele rulează în paralel)
- Un modul de postprocesare care sprijină ansamblul modelului, reconcilierea ierarhică, valorile și generarea de rapoarte
Step Functions organizează și orchestrează fluxul de lucru de la un capăt la altul ca o mașină de stare. Rularea mașinii de stare este configurată cu un fișier JSON care conține toate informațiile necesare, inclusiv locația fișierelor CSV ale veniturilor istorice în Amazon S3, ora de începere estimată și setările modelului de hiperparametri pentru a rula fluxul de lucru de la capăt la capăt. Apelurile asincrone sunt create pentru a paraleliza antrenamentul modelului în mașina de stări folosind funcții Lambda. Toate datele istorice, fișierele de configurare, rezultatele prognozelor, precum și rezultatele intermediare, cum ar fi rezultatele backtesting, sunt stocate în Amazon S3. API-ul REST este construit pe Amazon S3 pentru a oferi o interfață interogabilă pentru interogarea rezultatelor prognozei. Sistemul poate fi extins pentru a încorpora noi modele de prognoză și funcții de sprijin, cum ar fi generarea de rapoarte de vizualizare a prognozei.
Evaluare
În această secțiune, detaliem configurarea experimentului. Componentele cheie includ setul de date, valorile de evaluare, ferestrele de backtest și configurarea și instruirea modelului.
Setul de date
Pentru a proteja confidențialitatea financiară a Bosch în timp ce folosim un set de date semnificativ, am folosit un set de date sintetice care are caracteristici statistice similare cu un set de date despre venituri din lumea reală de la o unitate de afaceri la Bosch. Setul de date conține 1,216 serii temporale în total, cu venituri înregistrate cu o frecvență lunară, acoperind din ianuarie 2016 până în aprilie 2022. Setul de date este livrat cu 877 serii temporale la cel mai granul nivel (seria temporală de jos), cu o structură de serie temporală grupată corespunzătoare reprezentată ca o matrice de însumare S. Fiecare serie de timp este asociată cu trei atribute categoriale statice, care corespund categoriei de produs, regiunii și unității organizaționale din setul de date real (anonimizate în datele sintetice).
Valori de evaluare
Folosim eroarea procentuală medie a arctangentului mediu (median-MAAPE) și MAAPE ponderat pentru a evalua performanța modelului și a efectua analize comparative, care sunt valorile standard utilizate la Bosch. MAAPE abordează deficiențele metricii MAPE (Mean Absolute Percentage Error) utilizată în mod obișnuit în contextul afacerilor. Median-MAAPE oferă o imagine de ansamblu asupra performanței modelului, calculând mediana MAAPE-urilor calculate individual pe fiecare serie de timp. Weighted-MAAPE raportează o combinație ponderată a MAAPE-urilor individuale. Ponderile sunt proporția veniturilor pentru fiecare serie de timp în comparație cu veniturile agregate ale întregului set de date. Weighted-MAAPE reflectă mai bine impactul afacerii din aval al acurateței prognozelor. Ambele valori sunt raportate pe întregul set de date de 1,216 serii temporale.
Backtest ferestre
Folosim ferestre rulante de backtest de 12 luni pentru a compara performanța modelului. Următoarea figură ilustrează ferestrele backtest utilizate în experimente și evidențiază datele corespunzătoare utilizate pentru antrenament și optimizarea hiperparametrului (HPO). Pentru ferestrele backtest după începerea COVID-19, rezultatul este afectat de intrările OOD din aprilie până în mai 2020, pe baza a ceea ce am observat din seria cronologică a veniturilor.

Configurare model și antrenament
Pentru antrenamentul Transformer, am folosit pierderea cuantilă și am scalat fiecare serie de timp folosind valoarea medie istorică înainte de a o introduce în Transformer și de a calcula pierderea de antrenament. Prognozele finale sunt redimensionate pentru a calcula valorile de precizie, folosind MeanScaler implementat în GluonTS. Folosim o fereastră de context cu date lunare privind veniturile din ultimele 18 luni, selectate prin HPO în fereastra backtest din iulie 2018 până în iunie 2019. Metadate suplimentare despre fiecare serie temporală sub formă de variabile categoriale statice sunt introduse în model printr-o încorporare. strat înainte de a-l alimenta straturile transformatorului. Antrenăm Transformerul cu cinci inițializări aleatorii ale greutății diferite și facem o medie a rezultatelor prognozei din ultimele trei epoci pentru fiecare rulare, în total, având o medie de 15 modele. Cele cinci modele de antrenament pot fi paralelizate pentru a reduce timpul de antrenament. Pentru Transformerul mascat, indicăm lunile din aprilie până în mai 2020 ca valori aberante.
Pentru toate antrenamentele modelului Forecast, am activat HPO automat, care poate selecta modelul și parametrii de antrenament pe baza unei perioade de backtest specificate de utilizator, care este setată la ultimele 12 luni în fereastra de date utilizată pentru antrenament și HPO.
Rezultatele experimentului
Antrenăm transformatoare mascate și demascate folosind același set de hiperparametri și le-am comparat performanța pentru ferestrele backtest imediat după șocul COVID-19. În Transformerul mascat, cele două luni mascate sunt aprilie și mai 2020. Următorul tabel arată rezultatele unei serii de perioade de backtest cu ferestre de prognoză de 12 luni începând din iunie 2020. Putem observa că Transformerul mascat depășește constant versiunea nemascata. .

Am efectuat în continuare evaluarea strategiei ansamblului modelului pe baza rezultatelor backtest. În special, comparăm cele două cazuri în care este selectat doar modelul cu cele mai bune performanțe vs. atunci când sunt selectate cele două modele cu cele mai bune performanțe, iar medierea modelului este realizată prin calculul valorii medii a prognozelor. Comparăm performanța modelelor de bază și a modelelor de ansamblu în figurile următoare. Observați că niciunul dintre prognozatorii neuronali nu îi depășește în mod constant pe alții pentru ferestrele rolling backtest.


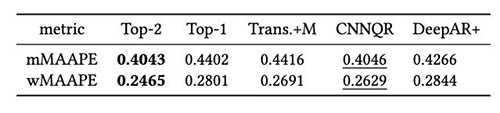
Următorul tabel arată că, în medie, modelarea ansamblului celor două modele de top oferă cele mai bune performanțe. CNNQR oferă al doilea cel mai bun rezultat.
Concluzie
Această postare a demonstrat cum să construiți o soluție ML end-to-end pentru problemele de prognoză la scară largă combinând Forecast și un model personalizat antrenat pe SageMaker. În funcție de nevoile dvs. de afaceri și de cunoștințele ML, puteți utiliza un serviciu complet gestionat, cum ar fi Forecast, pentru a descărca procesul de construire, instruire și implementare a unui model de prognoză; construiește-ți modelul personalizat cu mecanisme de reglare specifice cu SageMaker; sau efectuați asamblarea modelului prin combinarea celor două servicii.
Dacă doriți ajutor pentru accelerarea utilizării ML în produsele și serviciile dvs., vă rugăm să contactați Laboratorul Amazon ML Solutions programul.
Referinte
Hyndman RJ, Athanasopoulos G. Prognoza: principii și practică. OTexte; 2018 mai 8.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Atenția este tot ce ai nevoie. Progrese în sistemele de procesare a informațiilor neuronale. 2017;30.
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Informator: Dincolo de transformatorul eficient pentru prognoza serii temporale cu secvențe lungi. În Proceedings of AAAI 2021 2 februarie.
Despre Autori
 Goktug Cinar este un om de știință principal în ML și responsabil tehnic al ML și al prognozei bazate pe statistici la Robert Bosch LLC și Bosch Center for Artificial Intelligence. El conduce cercetarea modelelor de prognoză, consolidarea ierarhică și tehnicile de combinare a modelelor, precum și echipa de dezvoltare software care scalează aceste modele și le servește ca parte a software-ului intern de prognoză financiară end-to-end.
Goktug Cinar este un om de știință principal în ML și responsabil tehnic al ML și al prognozei bazate pe statistici la Robert Bosch LLC și Bosch Center for Artificial Intelligence. El conduce cercetarea modelelor de prognoză, consolidarea ierarhică și tehnicile de combinare a modelelor, precum și echipa de dezvoltare software care scalează aceste modele și le servește ca parte a software-ului intern de prognoză financiară end-to-end.
 Michael Binder este proprietar de produs la Bosch Global Services, unde coordonează dezvoltarea, implementarea și implementarea aplicației de analiză predictivă la scară largă a companiei pentru prognoza automată la scară largă, bazată pe date, a cifrelor cheie financiare.
Michael Binder este proprietar de produs la Bosch Global Services, unde coordonează dezvoltarea, implementarea și implementarea aplicației de analiză predictivă la scară largă a companiei pentru prognoza automată la scară largă, bazată pe date, a cifrelor cheie financiare.
 Adrian Horvath este dezvoltator de software la Bosch Center for Artificial Intelligence, unde dezvoltă și întreține sisteme pentru a crea predicții bazate pe diverse modele de prognoză.
Adrian Horvath este dezvoltator de software la Bosch Center for Artificial Intelligence, unde dezvoltă și întreține sisteme pentru a crea predicții bazate pe diverse modele de prognoză.
 Panpan Xu este un senior Applied Scientist și manager cu Amazon ML Solutions Lab la AWS. Ea lucrează la cercetarea și dezvoltarea algoritmilor de învățare automată pentru aplicații cu impact ridicat pentru clienți într-o varietate de verticale industriale pentru a accelera adoptarea AI și a cloud-ului. Interesul ei de cercetare include interpretabilitatea modelului, analiza cauzală, IA umană în buclă și vizualizarea interactivă a datelor.
Panpan Xu este un senior Applied Scientist și manager cu Amazon ML Solutions Lab la AWS. Ea lucrează la cercetarea și dezvoltarea algoritmilor de învățare automată pentru aplicații cu impact ridicat pentru clienți într-o varietate de verticale industriale pentru a accelera adoptarea AI și a cloud-ului. Interesul ei de cercetare include interpretabilitatea modelului, analiza cauzală, IA umană în buclă și vizualizarea interactivă a datelor.
 Jasleen Grewal este un om de știință aplicat la Amazon Web Services, unde lucrează cu clienții AWS pentru a rezolva problemele din lumea reală folosind învățarea automată, cu accent special pe medicina de precizie și genomica. Ea are o experiență solidă în bioinformatică, oncologie și genomică clinică. Este pasionată de utilizarea AI/ML și a serviciilor cloud pentru a îmbunătăți îngrijirea pacienților.
Jasleen Grewal este un om de știință aplicat la Amazon Web Services, unde lucrează cu clienții AWS pentru a rezolva problemele din lumea reală folosind învățarea automată, cu accent special pe medicina de precizie și genomica. Ea are o experiență solidă în bioinformatică, oncologie și genomică clinică. Este pasionată de utilizarea AI/ML și a serviciilor cloud pentru a îmbunătăți îngrijirea pacienților.
 Selvan Senthivel este inginer senior ML cu Amazon ML Solutions Lab de la AWS, concentrându-se pe sprijinirea clienților cu privire la învățarea automată, problemele de deep learning și soluțiile ML end-to-end. A fost liderul de inginerie fondator al Amazon Comprehend Medical și a contribuit la proiectarea și arhitectura mai multor servicii AWS AI.
Selvan Senthivel este inginer senior ML cu Amazon ML Solutions Lab de la AWS, concentrându-se pe sprijinirea clienților cu privire la învățarea automată, problemele de deep learning și soluțiile ML end-to-end. A fost liderul de inginerie fondator al Amazon Comprehend Medical și a contribuit la proiectarea și arhitectura mai multor servicii AWS AI.
 Ruilin Zhang este un SDE cu Amazon ML Solutions Lab la AWS. El îi ajută pe clienți să adopte serviciile AWS AI prin construirea de soluții pentru a aborda problemele comune de afaceri.
Ruilin Zhang este un SDE cu Amazon ML Solutions Lab la AWS. El îi ajută pe clienți să adopte serviciile AWS AI prin construirea de soluții pentru a aborda problemele comune de afaceri.
 Shane Rai este un strateg senior ML cu Amazon ML Solutions Lab la AWS. El lucrează cu clienți dintr-un spectru divers de industrii pentru a-și rezolva nevoile de afaceri cele mai presante și inovatoare, utilizând gama AWS de servicii AI/ML bazate pe cloud.
Shane Rai este un strateg senior ML cu Amazon ML Solutions Lab la AWS. El lucrează cu clienți dintr-un spectru divers de industrii pentru a-și rezolva nevoile de afaceri cele mai presante și inovatoare, utilizând gama AWS de servicii AI/ML bazate pe cloud.
 Lin Lee Cheong este manager de știință aplicată cu echipa Amazon ML Solutions Lab de la AWS. Ea lucrează cu clienți strategici AWS pentru a explora și aplica inteligența artificială și învățarea automată pentru a descoperi noi perspective și pentru a rezolva probleme complexe.
Lin Lee Cheong este manager de știință aplicată cu echipa Amazon ML Solutions Lab de la AWS. Ea lucrează cu clienți strategici AWS pentru a explora și aplica inteligența artificială și învățarea automată pentru a descoperi noi perspective și pentru a rezolva probleme complexe.