
Этот пост написан в соавторстве с Гоктугом Чинаром, Майклом Биндером и Адрианом Хорватом из Центра искусственного интеллекта Bosch (BCAI).
Прогнозирование доходов является сложной, но важной задачей для принятия стратегических бизнес-решений и финансового планирования в большинстве организаций. Часто прогнозирование доходов выполняется финансовыми аналитиками вручную и требует много времени и субъективно. Такие ручные операции особенно сложны для крупных многонациональных бизнес-организаций, которым требуются прогнозы доходов по широкому спектру групп продуктов и географических областей с различными уровнями детализации. Это требует не только точности, но и иерархической согласованности прогнозов.
Bosch является многонациональной корпорацией с предприятиями, работающими в нескольких секторах, включая автомобилестроение, промышленные решения и потребительские товары. Учитывая влияние точного и последовательного прогнозирования доходов на здоровые бизнес-операции, Центр искусственного интеллекта Bosch (BCAI) вкладывает значительные средства в использование машинного обучения (ML) для повышения эффективности и точности процессов финансового планирования. Цель состоит в том, чтобы упростить ручные процессы, предоставив разумные базовые прогнозы доходов с помощью ML, с лишь периодическими корректировками, необходимыми финансовым аналитикам, используя свои знания в отрасли и предметной области.
Для достижения этой цели BCAI разработал внутреннюю структуру прогнозирования, способную предоставлять крупномасштабные иерархические прогнозы с помощью настраиваемых ансамблей широкого спектра базовых моделей. Мета-обучающийся выбирает наиболее эффективные модели на основе признаков, извлеченных из каждого временного ряда. Затем прогнозы выбранных моделей усредняются для получения агрегированного прогноза. Архитектурный проект является модульным и расширяемым за счет реализации интерфейса в стиле REST, который позволяет постоянно улучшать производительность за счет включения дополнительных моделей.
BCAI сотрудничает с Лаборатория решений Amazon ML (MLSL) для включения последних достижений в модели на основе глубоких нейронных сетей (DNN) для прогнозирования доходов. Недавние достижения в нейронных прогнозах продемонстрировали современную производительность для многих практических задач прогнозирования. По сравнению с традиционными моделями прогнозирования многие нейронные прогнозисты могут включать дополнительные ковариаты или метаданные временных рядов. Мы включаем CNN-QR и DeepAR+, две готовые модели в Прогноз Амазонки, а также пользовательскую модель Transformer, обученную с использованием Создатель мудреца Амазонки. Эти три модели охватывают репрезентативный набор основ кодировщика, часто используемых в нейронных прогнозистах: сверточная нейронная сеть (CNN), последовательная рекуррентная нейронная сеть (RNN) и кодировщики на основе преобразователя.
Одной из ключевых задач, с которыми столкнулось партнерство BCAI-MLSL, было предоставление надежных и обоснованных прогнозов в условиях воздействия COVID-19, беспрецедентного глобального события, вызвавшего большую волатильность глобальных корпоративных финансовых результатов. Поскольку нейронные прогнозисты обучаются на исторических данных, прогнозы, созданные на основе данных вне распределения за более волатильные периоды, могут быть неточными и ненадежными. Поэтому мы предложили добавить механизм маскированного внимания в архитектуру Transformer для решения этой проблемы.
Нейронные прогнозисты могут быть объединены в единую ансамблевую модель или включены по отдельности во вселенную моделей Bosch, и к ним можно легко получить доступ через конечные точки REST API. Мы предлагаем подход к объединению нейронных прогнозистов с помощью результатов ретроспективного тестирования, который обеспечивает конкурентоспособную и надежную работу с течением времени. Кроме того, мы исследовали и оценили ряд классических иерархических методов согласования, чтобы гарантировать согласованное агрегирование прогнозов по группам продуктов, географическим регионам и бизнес-организациям.
В этом посте мы демонстрируем следующее:
- Как применить обучение пользовательской модели Forecast и SageMaker для иерархических, крупномасштабных задач прогнозирования временных рядов
- Как объединить пользовательские модели с готовыми моделями из прогноза
- Как уменьшить влияние разрушительных событий, таких как COVID-19, на проблемы прогнозирования
- Как построить сквозной рабочий процесс прогнозирования на AWS
Вызовы
Мы решили две задачи: создание иерархического крупномасштабного прогнозирования доходов и влияние пандемии COVID-19 на долгосрочное прогнозирование.
Иерархическое крупномасштабное прогнозирование доходов
Финансовым аналитикам поручено прогнозировать ключевые финансовые показатели, включая доходы, операционные расходы и расходы на НИОКР. Эти показатели обеспечивают понимание бизнес-планирования на разных уровнях агрегирования и позволяют принимать решения на основе данных. Любое решение для автоматизированного прогнозирования должно предоставлять прогнозы на любом произвольном уровне агрегирования бизнес-направлений. В Bosch агрегаты можно представить как сгруппированные временные ряды как более общую форму иерархической структуры. На следующем рисунке показан упрощенный пример с двухуровневой структурой, которая имитирует иерархическую структуру прогнозирования доходов в Bosch. Общий доход делится на несколько уровней агрегирования в зависимости от продукта и региона.
Общее количество временных рядов, которые необходимо спрогнозировать в Bosch, исчисляется миллионами. Обратите внимание, что временные ряды верхнего уровня могут быть разделены либо по продуктам, либо по регионам, создавая несколько путей к прогнозам нижнего уровня. Доход необходимо прогнозировать на каждом узле иерархии с горизонтом прогнозирования 12 месяцев в будущем. Доступны ежемесячные исторические данные.
Иерархическую структуру можно представить, используя следующую форму с обозначением суммирующей матрицы S (Гайндман и Атанасопулос):
![]()
В этом уравнении Y равно следующему:

Здесь, b представляет временной ряд нижнего уровня в момент времени t.
Последствия пандемии COVID-19
Пандемия COVID-19 создала серьезные проблемы для прогнозирования из-за ее разрушительного и беспрецедентного воздействия практически на все аспекты работы и социальной жизни. Для долгосрочного прогнозирования доходов сбой также привел к неожиданным последствиям. Чтобы проиллюстрировать эту проблему, на следующем рисунке показан примерный временной ряд, в котором доход от продукта значительно упал в начале пандемии, а затем постепенно восстановился. Типичная модель нейронного прогнозирования будет использовать данные о доходах, включая период отсутствия распространения COVID-XNUMX, в качестве исходных данных исторического контекста, а также исходную информацию для обучения модели. В результате полученные прогнозы перестают быть надежными.

Подходы к моделированию
В этом разделе мы обсудим наши различные подходы к моделированию.
Прогноз Амазонки
Прогноз — это полностью управляемый сервис AI/ML от AWS, который предоставляет предварительно настроенные современные модели прогнозирования временных рядов. Он сочетает эти предложения со своими внутренними возможностями для автоматической оптимизации гиперпараметров, ансамблевого моделирования (для моделей, предоставляемых Forecast) и создания вероятностных прогнозов. Это позволяет легко получать пользовательские наборы данных, предварительно обрабатывать данные, обучать модели прогнозирования и создавать надежные прогнозы. Модульная структура сервиса также позволяет нам легко запрашивать и комбинировать прогнозы из дополнительных пользовательских моделей, разработанных параллельно.
Мы привлекаем двух нейронных прогнозистов из Forecast: CNN-QR и DeepAR+. Оба являются контролируемыми методами глубокого обучения, которые обучают глобальную модель для всего набора данных временных рядов. И модели CNNQR, и DeepAR+ могут принимать статическую информацию метаданных о каждом временном ряду, который в нашем случае является соответствующим продуктом, регионом и бизнес-организацией. Они также автоматически добавляют временные характеристики, такие как месяц года, как часть входных данных для модели.
Трансформер с масками внимания для COVID
Трансформаторная архитектура (англ.Васвани и др.), первоначально предназначенный для обработки естественного языка (NLP), недавно стал популярным архитектурным выбором для прогнозирования временных рядов. Здесь мы использовали архитектуру Transformer, описанную в Чжоу и соавт. без вероятностного журнала редкого внимания. Модель использует типичную архитектуру, объединяя кодер и декодер. Для прогнозирования доходов мы настраиваем декодер для прямого вывода прогноза на 12-месячный горизонт вместо создания прогноза месяц за месяцем авторегрессивным способом. В зависимости от частоты временных рядов в качестве входной переменной добавляются дополнительные функции, связанные со временем, такие как месяц года. Дополнительные категориальные переменные, описывающие метаинформацию (продукт, регион, бизнес-организация), передаются в сеть через обучаемый слой внедрения.
Следующая диаграмма иллюстрирует архитектуру Transformer и механизм маскировки внимания. Маскировка внимания применяется ко всем слоям кодировщика и декодера, выделенным оранжевым цветом, чтобы данные OOD не влияли на прогнозы.

Мы смягчаем влияние окон контекста OOD, добавляя маски внимания. Модель обучена уделять очень мало внимания периоду COVID, который содержит выбросы за счет маскирования, и выполняет прогнозирование с замаскированной информацией. Маска внимания применяется на каждом уровне архитектуры декодера и кодировщика. Маскированное окно может быть задано либо вручную, либо с помощью алгоритма обнаружения выбросов. Кроме того, при использовании временного окна, содержащего выбросы, в качестве обучающих меток, потери не распространяются обратно. Этот метод, основанный на маскировании внимания, может применяться для обработки сбоев и случаев OOD, вызванных другими редкими событиями, и повышения надежности прогнозов.
Модельный ансамбль
Ансамбль моделей часто превосходит отдельные модели для прогнозирования — он улучшает обобщаемость модели и лучше обрабатывает данные временных рядов с различными характеристиками периодичности и прерывистости. Мы включили ряд стратегий ансамбля моделей, чтобы улучшить производительность модели и надежность прогнозов. Одной из распространенных форм ансамбля моделей глубокого обучения является объединение результатов прогонов модели с разными инициализациями случайного веса или разных периодов обучения. Мы используем эту стратегию для получения прогнозов для модели Transformer.
Для дальнейшего построения ансамбля на основе различных архитектур моделей, таких как Transformer, CNNQR и DeepAR+, мы используем стратегию ансамбля панмоделей, которая выбирает k самых эффективных моделей для каждого временного ряда на основе результатов ретроспективного тестирования и получает их. средние. Поскольку результаты ретроспективного тестирования можно экспортировать непосредственно из обученных моделей Forecast, эта стратегия позволяет нам использовать готовые услуги, такие как Forecast, с улучшениями, полученными от пользовательских моделей, таких как Transformer. Такой сквозной подход к ансамблю моделей не требует обучения мета-обучающего или вычисления характеристик временных рядов для выбора модели.
Иерархическое согласование
Платформа является адаптивной для включения широкого спектра методов в качестве шагов постобработки для иерархического согласования прогнозов, включая восходящее (BU), нисходящее согласование с пропорциями прогнозирования (TDFP), обычный метод наименьших квадратов (OLS) и взвешенный метод наименьших квадратов ( ВЛС). Все экспериментальные результаты в этом посте сообщаются с использованием нисходящей сверки с пропорциями прогнозирования.
Обзор архитектуры
Мы разработали автоматизированный сквозной рабочий процесс на AWS для создания прогнозов доходов с использованием таких сервисов, как Forecast, SageMaker, Простой сервис хранения Amazon (Амазон С3), AWS Lambda, Шаговые функции AWSи Комплект для разработки облачных сервисов AWS (АВС CDK). Развернутое решение предоставляет прогнозы отдельных временных рядов через REST API с использованием Шлюз API Amazon, возвращая результаты в предопределенном формате JSON.
На следующей диаграмме показан сквозной рабочий процесс прогнозирования.

Ключевыми соображениями при проектировании архитектуры являются универсальность, производительность и удобство для пользователя. Система должна быть достаточно универсальной, чтобы включать разнообразный набор алгоритмов во время разработки и развертывания с минимальными необходимыми изменениями, и ее можно легко расширять при добавлении новых алгоритмов в будущем. Система также должна добавлять минимальные накладные расходы и поддерживать параллельное обучение как для Forecast, так и для SageMaker, чтобы сократить время обучения и быстрее получать последний прогноз. Наконец, система должна быть простой в использовании для экспериментов.
Сквозной рабочий процесс последовательно проходит через следующие модули:
- Модуль предварительной обработки для переформатирования и преобразования данных
- Модуль обучения модели, включающий как модель прогноза, так и пользовательскую модель в SageMaker (обе работают параллельно)
- Модуль постобработки, поддерживающий ансамбль моделей, иерархическое согласование, метрики и создание отчетов.
Step Functions организует и управляет рабочим процессом от начала до конца как конечный автомат. Запуск конечного автомата настраивается с помощью файла JSON, содержащего всю необходимую информацию, включая расположение CSV-файлов истории доходов в Amazon S3, время начала прогноза и настройки гиперпараметров модели для запуска сквозного рабочего процесса. Асинхронные вызовы создаются для распараллеливания обучения модели в конечном автомате с использованием функций Lambda. Все исторические данные, файлы конфигурации, результаты прогнозов, а также промежуточные результаты, такие как результаты ретроспективного тестирования, хранятся в Amazon S3. REST API создан на основе Amazon S3 и предоставляет интерфейс с поддержкой запросов для запроса результатов прогнозирования. Система может быть расширена для включения новых моделей прогнозов и вспомогательных функций, таких как создание отчетов визуализации прогнозов.
Оценка
В этом разделе мы подробно описываем установку эксперимента. Ключевые компоненты включают в себя набор данных, метрики оценки, окна ретроспективного тестирования, а также настройку и обучение модели.
Dataset
Чтобы защитить финансовую конфиденциальность Bosch при использовании значимого набора данных, мы использовали синтетический набор данных, статистические характеристики которого аналогичны реальному набору данных о доходах от одного бизнес-подразделения Bosch. Набор данных содержит в общей сложности 1,216 временных рядов с ежемесячной регистрацией доходов, охватывающих период с января 2016 года по апрель 2022 года. в виде суммирующей матрицы S. Каждый временной ряд связан с тремя статическими категориальными атрибутами, которые соответствуют категории продукта, региону и организационной единице в реальном наборе данных (анонимизированы в синтетических данных).
Метрики оценки
Мы используем медианную среднюю арктангенсную абсолютную ошибку в процентах (медиану-MAAPE) и взвешенную-MAAPE для оценки производительности модели и выполнения сравнительного анализа, которые являются стандартными показателями, используемыми в Bosch. MAAPE устраняет недостатки показателя средней абсолютной погрешности в процентах (MAPE), обычно используемого в бизнес-контексте. Median-MAAPE дает обзор производительности модели путем вычисления медианы MAAPE, рассчитанной индивидуально для каждого временного ряда. Weighted-MAAPE сообщает о взвешенной комбинации отдельных MAAPE. Веса представляют собой долю дохода для каждого временного ряда по сравнению с совокупным доходом всего набора данных. Weighted-MAAPE лучше отражает влияние точности прогнозирования на бизнес-процессы. Обе метрики представлены для всего набора данных из 1,216 временных рядов.
Окна тестирования на истории
Мы используем скользящие 12-месячные периоды ретроспективного тестирования для сравнения производительности моделей. На следующем рисунке показаны окна ретроспективного тестирования, используемые в экспериментах, и выделены соответствующие данные, используемые для обучения и оптимизации гиперпараметров (HPO). Для периодов ретроспективного тестирования после начала COVID-19 на результат влияют входные данные OOD с апреля по май 2020 года, исходя из того, что мы наблюдали из временного ряда доходов.

Настройка модели и обучение
Для обучения Transformer мы использовали квантильные потери и масштабировали каждый временной ряд, используя его историческое среднее значение, прежде чем вводить его в Transformer и вычислять потери при обучении. Окончательные прогнозы повторно масштабируются для расчета показателей точности с использованием MeanScaler, реализованного в ГлюонТС. Мы используем контекстное окно с ежемесячными данными о доходах за последние 18 месяцев, выбранными с помощью HPO в окне ретроспективного тестирования с июля 2018 года по июнь 2019 года. Дополнительные метаданные о каждом временном ряду в виде статических категориальных переменных вводятся в модель через встраивание. слой перед подачей его на слои преобразователя. Мы обучаем Преобразователь с пятью различными инициализациями случайного веса и усредняем результаты прогноза из последних трех эпох для каждого прогона, всего усредняя 15 моделей. Пять учебных прогонов модели можно распараллелить, чтобы сократить время обучения. Для Трансформера в маске мы указываем месяцы с апреля по май 2020 года как выбросы.
Для обучения всех моделей прогнозирования мы включили автоматический HPO, который может выбирать модель и параметры обучения на основе указанного пользователем периода ретроспективного тестирования, который установлен на последние 12 месяцев в окне данных, используемом для обучения и HPO.
Результаты эксперимента
Мы обучали трансформеров в масках и без масок, используя один и тот же набор гиперпараметров, и сравнивали их производительность для периодов ретроспективного тестирования сразу после шока COVID-19. В замаскированном Transformer два замаскированных месяца — это апрель и май 2020 года. В следующей таблице показаны результаты серии периодов ретроспективного тестирования с 12-месячными окнами прогнозирования, начиная с июня 2020 года. Мы можем заметить, что замаскированный Transformer постоянно превосходит незамаскированную версию. .

Далее мы провели оценку стратегии ансамбля моделей на основе результатов ретроспективного тестирования. В частности, мы сравниваем два случая, когда выбирается только самая эффективная модель, и когда выбираются две самые эффективные модели, а усреднение модели выполняется путем вычисления среднего значения прогнозов. Мы сравниваем производительность базовых моделей и ансамблевых моделей на следующих рисунках. Обратите внимание, что ни один из нейронных прогнозистов постоянно не превосходит других в скользящих окнах ретроспективного тестирования.


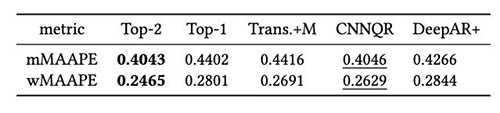
В следующей таблице показано, что в среднем ансамблевое моделирование двух лучших моделей дает наилучшую производительность. CNNQR дает второй лучший результат.
Заключение
В этом посте показано, как создать комплексное решение машинного обучения для крупномасштабных задач прогнозирования, сочетающее прогнозирование и пользовательскую модель, обученную в SageMaker. В зависимости от потребностей вашего бизнеса и знаний в области машинного обучения вы можете использовать полностью управляемую службу, такую как Forecast, чтобы разгрузить процесс сборки, обучения и развертывания модели прогнозирования; создайте собственную модель с помощью специальных механизмов настройки с помощью SageMaker; или выполнить сборку модели, объединив два сервиса.
Если вам нужна помощь в ускорении использования машинного обучения в ваших продуктах и услугах, обратитесь в Лаборатория решений Amazon ML программу.
Рекомендации
Хайндман Р.Дж., Атанасопулос Г. Прогнозирование: принципы и практика. Отексты; 2018 8 мая.
Васвани А., Шазир Н., Пармар Н., Ушкорейт Дж., Джонс Л., Гомес А.Н., Кайзер Л., Полосухин И. Внимание - это все, что вам нужно. Достижения в области нейронных систем обработки информации. 2017;30.
Чжоу Х., Чжан С., Пэн Дж., Чжан С., Ли Дж., Сюн Х., Чжан В. Информер: сверхэффективный преобразователь для прогнозирования временных рядов с длинными последовательностями. В материалах AAAI 2021 2 февраля.
Об авторах
 Гоктуг Чинар является ведущим ученым в области машинного обучения и техническим руководителем отдела машинного обучения и прогнозирования на основе статистики в Robert Bosch LLC и Центре искусственного интеллекта Bosch. Он возглавляет исследование моделей прогнозирования, иерархической консолидации и методов комбинирования моделей, а также команду разработчиков программного обеспечения, которая масштабирует эти модели и обслуживает их как часть внутреннего комплексного программного обеспечения для финансового прогнозирования.
Гоктуг Чинар является ведущим ученым в области машинного обучения и техническим руководителем отдела машинного обучения и прогнозирования на основе статистики в Robert Bosch LLC и Центре искусственного интеллекта Bosch. Он возглавляет исследование моделей прогнозирования, иерархической консолидации и методов комбинирования моделей, а также команду разработчиков программного обеспечения, которая масштабирует эти модели и обслуживает их как часть внутреннего комплексного программного обеспечения для финансового прогнозирования.
 Майкл Биндер является владельцем продукта в Bosch Global Services, где он координирует разработку, развертывание и внедрение общекорпоративного приложения прогнозной аналитики для крупномасштабного автоматизированного прогнозирования финансовых показателей на основе данных.
Майкл Биндер является владельцем продукта в Bosch Global Services, где он координирует разработку, развертывание и внедрение общекорпоративного приложения прогнозной аналитики для крупномасштабного автоматизированного прогнозирования финансовых показателей на основе данных.
 Адриан Хорват является разработчиком программного обеспечения в Центре искусственного интеллекта Bosch, где он разрабатывает и обслуживает системы для создания прогнозов на основе различных моделей прогнозирования.
Адриан Хорват является разработчиком программного обеспечения в Центре искусственного интеллекта Bosch, где он разрабатывает и обслуживает системы для создания прогнозов на основе различных моделей прогнозирования.
 Панпан Сюй является старшим научным сотрудником и менеджером лаборатории решений Amazon ML в AWS. Она занимается исследованием и разработкой алгоритмов машинного обучения для высокоэффективных клиентских приложений в различных отраслях промышленности, чтобы ускорить внедрение ИИ и облачных технологий. Ее исследовательский интерес включает интерпретируемость моделей, причинно-следственный анализ, искусственный интеллект с участием человека и интерактивную визуализацию данных.
Панпан Сюй является старшим научным сотрудником и менеджером лаборатории решений Amazon ML в AWS. Она занимается исследованием и разработкой алгоритмов машинного обучения для высокоэффективных клиентских приложений в различных отраслях промышленности, чтобы ускорить внедрение ИИ и облачных технологий. Ее исследовательский интерес включает интерпретируемость моделей, причинно-следственный анализ, искусственный интеллект с участием человека и интерактивную визуализацию данных.
 Джаслин Гревал — ученый-прикладник в Amazon Web Services, где она работает с клиентами AWS над решением реальных проблем с помощью машинного обучения, уделяя особое внимание точной медицине и геномике. У нее большой опыт работы в области биоинформатики, онкологии и клинической геномики. Она увлечена использованием AI/ML и облачных сервисов для улучшения ухода за пациентами.
Джаслин Гревал — ученый-прикладник в Amazon Web Services, где она работает с клиентами AWS над решением реальных проблем с помощью машинного обучения, уделяя особое внимание точной медицине и геномике. У нее большой опыт работы в области биоинформатики, онкологии и клинической геномики. Она увлечена использованием AI/ML и облачных сервисов для улучшения ухода за пациентами.
 Селван Сентивель — старший инженер по машинному обучению в лаборатории решений Amazon ML в AWS, специализирующийся на оказании помощи клиентам в решении проблем машинного обучения, глубокого обучения и комплексных решений машинного обучения. Он был ведущим инженером-основателем Amazon Comprehend Medical и участвовал в разработке и архитектуре нескольких сервисов AWS AI.
Селван Сентивель — старший инженер по машинному обучению в лаборатории решений Amazon ML в AWS, специализирующийся на оказании помощи клиентам в решении проблем машинного обучения, глубокого обучения и комплексных решений машинного обучения. Он был ведущим инженером-основателем Amazon Comprehend Medical и участвовал в разработке и архитектуре нескольких сервисов AWS AI.
 Жуйлинь Чжан — это SDE в лаборатории решений Amazon ML в AWS. Он помогает клиентам внедрять сервисы AWS AI, создавая решения для решения распространенных бизнес-проблем.
Жуйлинь Чжан — это SDE в лаборатории решений Amazon ML в AWS. Он помогает клиентам внедрять сервисы AWS AI, создавая решения для решения распространенных бизнес-проблем.
 Шейн Рай является старшим стратегом машинного обучения в лаборатории решений Amazon ML в AWS. Он работает с клиентами из самых разных отраслей, чтобы решить их самые насущные и инновационные бизнес-потребности, используя широкий спектр облачных сервисов AWS AI/ML.
Шейн Рай является старшим стратегом машинного обучения в лаборатории решений Amazon ML в AWS. Он работает с клиентами из самых разных отраслей, чтобы решить их самые насущные и инновационные бизнес-потребности, используя широкий спектр облачных сервисов AWS AI/ML.
 Лин Ли Чеонг является менеджером по прикладным наукам в команде Amazon ML Solutions Lab в AWS. Она работает со стратегическими клиентами AWS, исследуя и применяя искусственный интеллект и машинное обучение для получения новых идей и решения сложных проблем.
Лин Ли Чеонг является менеджером по прикладным наукам в команде Amazon ML Solutions Lab в AWS. Она работает со стратегическими клиентами AWS, исследуя и применяя искусственный интеллект и машинное обучение для получения новых идей и решения сложных проблем.