
Теперь вы можете повторно обучать модели машинного обучения (ML) и автоматизировать рабочие процессы пакетного прогнозирования с помощью обновленных наборов данных в Холст Amazon SageMaker, тем самым упрощая постоянное обучение и улучшение производительности модели и эффективности привода. Эффективность модели машинного обучения зависит от качества и актуальности данных, на которых она обучается. С течением времени основные закономерности, тенденции и распределения данных могут измениться. Обновляя набор данных, вы гарантируете, что модель учится на самых последних и репрезентативных данных, тем самым улучшая ее способность делать точные прогнозы. Canvas теперь поддерживает автоматическое и ручное обновление наборов данных, что позволяет использовать последнюю версию набора данных в виде таблиц, изображений и документов для обучения моделей машинного обучения.
После того, как модель обучена, вы можете выполнить для нее прогнозы. Выполнение пакетных прогнозов в модели машинного обучения позволяет одновременно обрабатывать несколько точек данных, а не делать прогнозы один за другим. Автоматизация этого процесса обеспечивает эффективность, масштабируемость и своевременное принятие решений. После того, как прогнозы сгенерированы, их можно дополнительно проанализировать, агрегировать или визуализировать, чтобы получить представление, выявить закономерности или принять обоснованные решения на основе прогнозируемых результатов. Canvas теперь поддерживает настройку автоматической конфигурации пакетного прогнозирования и связывание с ней набора данных. Когда связанный набор данных обновляется вручную или по расписанию, автоматически запускается рабочий процесс пакетного прогнозирования для соответствующей модели. Результаты прогнозов можно просмотреть в режиме онлайн или загрузить для последующего просмотра.
В этом посте мы покажем, как переобучить модели ML и автоматизировать пакетные прогнозы с использованием обновленных наборов данных в Canvas.
Обзор решения
В нашем случае мы играем роль бизнес-аналитика в компании электронной коммерции. Наша продуктовая команда хочет, чтобы мы определили наиболее важные показатели, влияющие на решение покупателя о покупке. Для этого мы обучаем модель ML в Canvas с набором данных онлайн-сеансов веб-сайта клиента от компании. Мы оцениваем производительность модели и, при необходимости, переобучаем модель с дополнительными данными, чтобы увидеть, улучшает ли она производительность существующей модели или нет. Для этого мы используем возможность автоматического обновления набора данных в Canvas и переобучаем нашу существующую модель машинного обучения с помощью последней версии обучающего набора данных. Затем мы настраиваем рабочие процессы автоматического пакетного прогнозирования — когда соответствующий набор данных прогнозирования обновляется, он автоматически запускает задание пакетного прогнозирования в модели и делает результаты доступными для просмотра.
Этапы рабочего процесса следующие:
- Загрузите загруженные данные онлайн-сеанса веб-сайта клиента в Простой сервис хранения Amazon (Amazon S3) и создайте новый набор обучающих данных Canvas. Полный список поддерживаемых источников данных см. Импорт данных в Amazon SageMaker Canvas.
- Создавайте модели машинного обучения и анализируйте показатели их производительности. Обратитесь к инструкциям о том, как создать пользовательскую модель ML в Canvas и оценить производительность модели.
- Настройте автоматическое обновление существующего набора обучающих данных и загрузите новые данные в хранилище Amazon S3, поддерживающее этот набор данных. По завершении он должен создать новую версию набора данных.
- Используйте последнюю версию набора данных, чтобы переобучить модель машинного обучения и проанализировать ее производительность.
- Создавать автоматические пакетные прогнозы на более эффективной версии модели и просмотрите результаты прогноза.
Вы можете выполнить эти шаги в Canvas, не написав ни одной строки кода.
Обзор данных
Набор данных состоит из векторов признаков, принадлежащих 12,330 1 сеансам. Набор данных был сформирован таким образом, чтобы каждый сеанс принадлежал другому пользователю в течение XNUMX года, чтобы избежать какой-либо тенденции к конкретной кампании, особому дню, профилю пользователя или периоду. В следующей таблице показана схема данных.
| Имя столбца | Тип данных | Описание |
Administrative |
Числовой | Количество страниц, посещенных пользователем для действий, связанных с управлением учетной записью пользователя. |
Administrative_Duration |
Числовой | Количество времени, проведенное в этой категории страниц. |
Informational |
Числовой | Количество страниц данного типа (информационных), которые посетил пользователь. |
Informational_Duration |
Числовой | Количество времени, проведенное в этой категории страниц. |
ProductRelated |
Числовой | Количество страниц этого типа (связанных с товаром), которые посетил пользователь. |
ProductRelated_Duration |
Числовой | Количество времени, проведенное в этой категории страниц. |
BounceRates |
Числовой | Процент посетителей, которые заходят на веб-сайт через эту страницу и выходят без выполнения каких-либо дополнительных задач. |
ExitRates |
Числовой | Средняя скорость выхода со страниц, посещенных пользователем. Это процент людей, которые покинули ваш сайт с этой страницы. |
Page Values |
Числовой | Средняя ценность страниц, посещенных пользователем. Это среднее значение для страницы, которую пользователь посетил перед тем, как перейти на целевую страницу или совершить транзакцию электронной торговли (или и то, и другое). |
SpecialDay |
Двоичный | Функция «Особый день» указывает на близость времени посещения сайта к определенному особому дню (например, Дню матери или Дню святого Валентина), когда сеансы с большей вероятностью завершатся транзакцией. |
Month |
категорический | Месяц визита. |
OperatingSystems |
категорический | Операционные системы посетителя. |
Browser |
категорический | Браузер, используемый пользователем. |
Region |
категорический | Географический регион, из которого посетитель начал сеанс. |
TrafficType |
категорический | Источник трафика, через который пользователь зашел на сайт. |
VisitorType |
категорический | Является ли клиент новым пользователем, вернувшимся пользователем или другим пользователем. |
Weekend |
Двоичный | Если клиент посетил сайт в выходной день. |
Revenue |
Двоичный | Если покупка была совершена. |
Доход — это целевой столбец, который поможет нам предсказать, купит ли покупатель продукт или нет.
Первым шагом является загрузить набор данных что мы будем использовать. Обратите внимание, что этот набор данных предоставлен репозиторием машинного обучения UCI.
Предпосылки
Для этого пошагового руководства выполните следующие предварительные шаги:
- Разделите загруженный файл CSV, содержащий 20,000 XNUMX строк, на несколько файлов фрагментов меньшего размера.
Это сделано для того, чтобы мы могли продемонстрировать функциональность обновления набора данных. Убедитесь, что все файлы CSV имеют одинаковые заголовки, иначе вы можете столкнуться с ошибками несоответствия схемы при создании набора обучающих данных в Canvas.

- Создайте корзину S3 и загрузите
online_shoppers_intentions1-3.csvв ведро S3.

- Выделите 1,500 строк из скачанного CSV-файла для запуска пакетных прогнозов после обучения модели машинного обучения.
- Удалить
Revenueстолбец из этих файлов, чтобы при запуске пакетного прогнозирования в модели машинного обучения именно это значение будет прогнозировать ваша модель.
Убедитесь, что все predict*.csv файлы имеют одинаковые заголовки, иначе вы можете столкнуться с ошибками несоответствия схемы при создании набора данных прогнозирования (вывода) в Canvas.

- Выполните необходимые действия, чтобы настроить домен SageMaker и приложение Canvas.
Создать набор данных
Чтобы создать набор данных в Canvas, выполните следующие шаги:
- В Холсте выберите Datasets в навигационной панели.
- Выберите Создавай , а затем выбрать табличный.

- Дайте вашему набору данных имя. Для этого поста мы называем наш обучающий набор данных
OnlineShoppersIntentions. - Выберите Создавай.

- Выберите источник данных (для этого поста нашим источником данных является Amazon S3).
Обратите внимание, что на момент написания этой статьи функция обновления набора данных поддерживается только для Amazon S3 и локально загруженных источников данных.
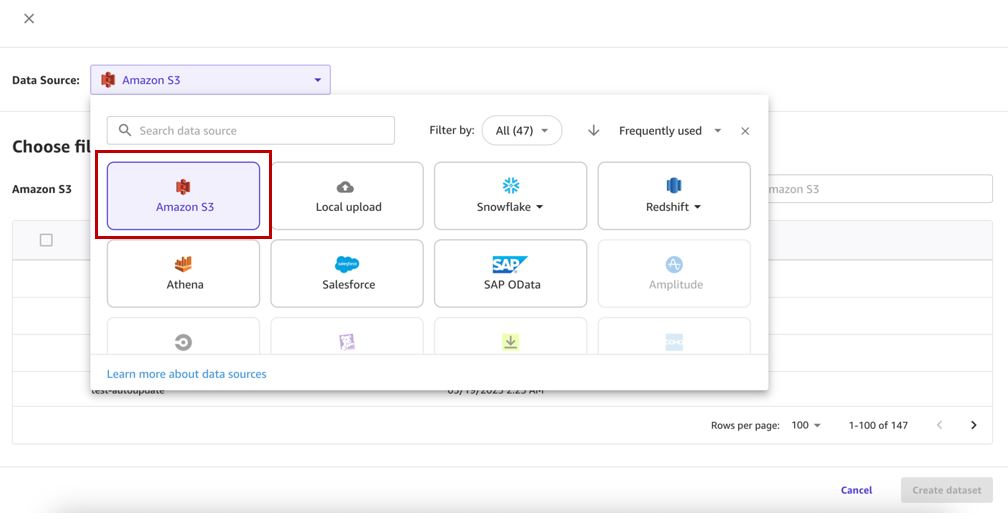
- Выберите соответствующую корзину и загрузите CSV-файлы для набора данных.
Теперь вы можете создать набор данных с несколькими файлами.

- Предварительно просмотрите все файлы в наборе данных и выберите Создать набор данных.

Теперь у нас есть версия 1 OnlineShoppersIntentions набор данных с тремя созданными файлами.
- Выберите набор данных, чтобы просмотреть подробности.

Ассоциация Данные Вкладка показывает предварительный просмотр набора данных.
- Выберите Детали набора данных для просмотра файлов, содержащихся в наборе данных.
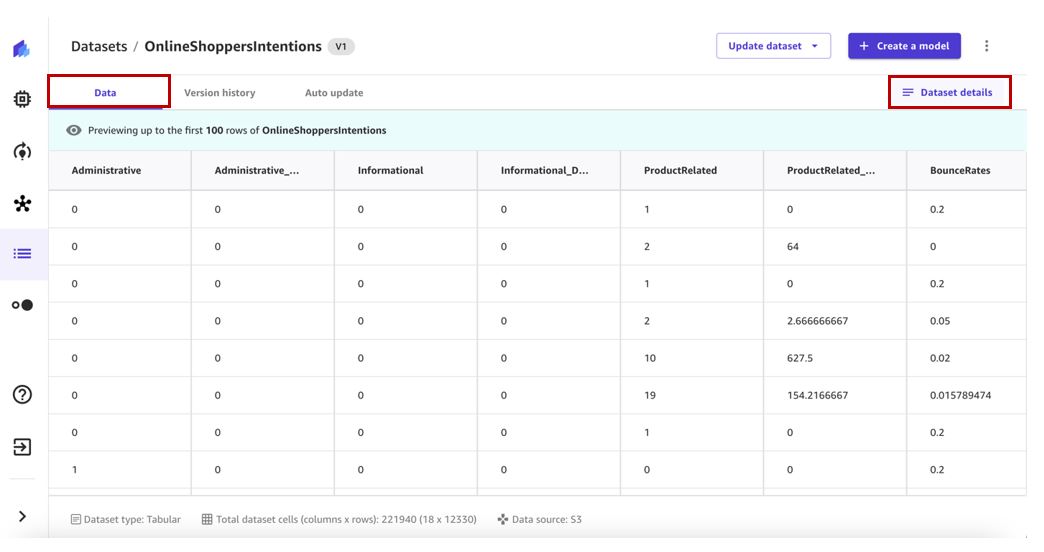
Ассоциация Файлы набора данных панели перечислены доступные файлы.

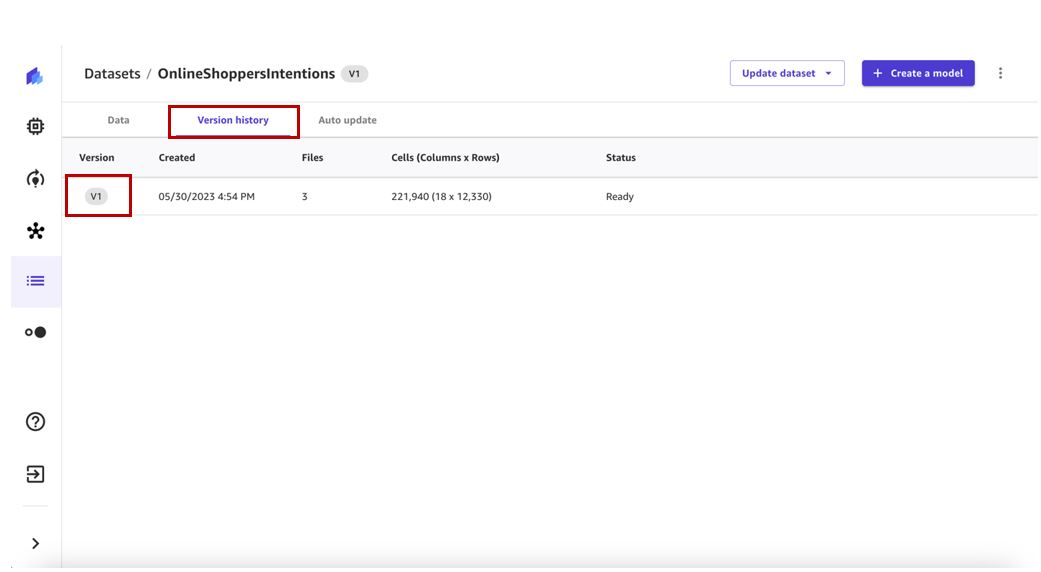
- Выберите История версий вкладку, чтобы просмотреть все версии для этого набора данных.
Мы видим, что наша первая версия набора данных состоит из трех файлов. Любая последующая версия будет включать все файлы из предыдущих версий и будет предоставлять кумулятивное представление данных.
Обучите модель ML с версией 1 набора данных
Давайте обучим модель машинного обучения с версией 1 нашего набора данных.
- В Холсте выберите Мои модели в навигационной панели.
- Выберите Новая модель.
- Введите название модели (например,
OnlineShoppersIntentionsModel), выберите тип проблемы и выберите Создавай.
- Выберите набор данных. Для этого поста мы выбираем
OnlineShoppersIntentionsнабор данных.
По умолчанию Canvas выбирает самую последнюю версию набора данных для обучения.

- На строить выберите целевой столбец для прогнозирования. Для этого поста мы выбираем столбец «Доход».
- Выберите Быстрая сборка.

Обучение модели займет 2–5 минут. В нашем случае обученная модель дает нам оценку 89%.

Настройка автоматического обновления набора данных
Давайте обновим наш набор данных, используя функцию автоматического обновления, добавим больше данных и посмотрим, улучшится ли производительность модели с новой версией набора данных. Наборы данных также можно обновлять вручную.
- На Datasets страницы, выберите
OnlineShoppersIntentionsнабор данных и выбрать Обновить набор данных. - Вы можете выбрать Ручное обновление, который является разовым вариантом обновления, или Автоматическое обновление, что позволяет автоматически обновлять набор данных по расписанию. В этом посте мы демонстрируем функцию автоматического обновления.

Вы перенаправлены на Автоматическое обновление вкладка для соответствующего набора данных. Мы видим, что Включить автоматическое обновление в настоящее время отключен.

- Переключать Включить автоматическое обновление включить и указать источник данных (на момент написания этой статьи источники данных Amazon S3 поддерживаются для автоматического обновления).
- Выберите частоту и введите время начала.
- Сохраните параметры конфигурации.

Создана конфигурация набора данных автоматического обновления. Его можно редактировать в любое время. Когда соответствующее задание обновления набора данных запускается по указанному расписанию, оно появляется в История вакансий .

- Далее, давайте загрузим
online_shoppers_intentions4.csv,online_shoppers_intentions5.csvкачестваonline_shoppers_intentions6.csvфайлы в нашу корзину S3.

Мы можем просматривать наши файлы в dataset-update-demo Ведро S3.

Задание обновления набора данных будет запущено по указанному расписанию и создаст новую версию набора данных.

Когда задание будет завершено, в наборе данных версии 2 будут все файлы из версии 1 и дополнительные файлы, обработанные заданием обновления набора данных. В нашем случае версия 1 содержит три файла, и задание обновления выбрало три дополнительных файла, поэтому в окончательной версии набора данных будет шесть файлов.
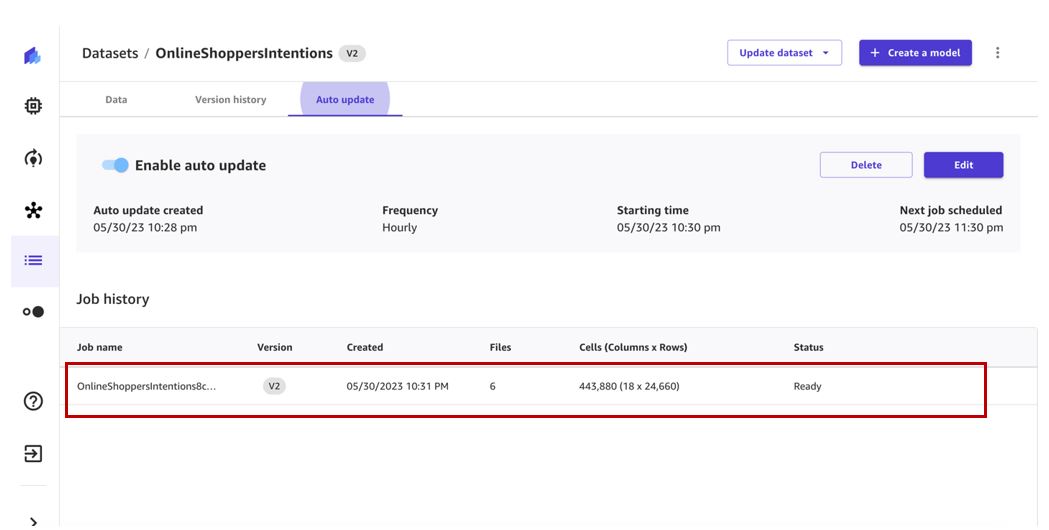
Мы можем просмотреть новую версию, которая была создана на История версий меню.

Ассоциация Данные Вкладка содержит предварительный просмотр набора данных и предоставляет список всех файлов в последней версии набора данных.

Переобучите модель машинного обучения с обновленным набором данных.
Давайте переобучим нашу модель ML с последней версией набора данных.
- На Мои модели страницу, выберите свою модель.
- Выберите Добавить версию.
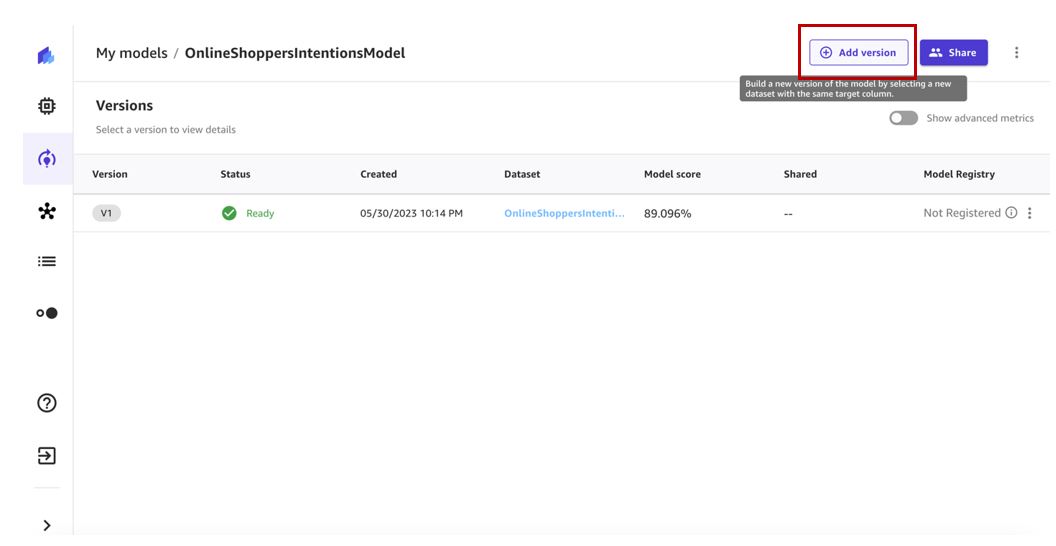
- Выберите последнюю версию набора данных (в нашем случае v2) и выберите Выбрать набор данных.
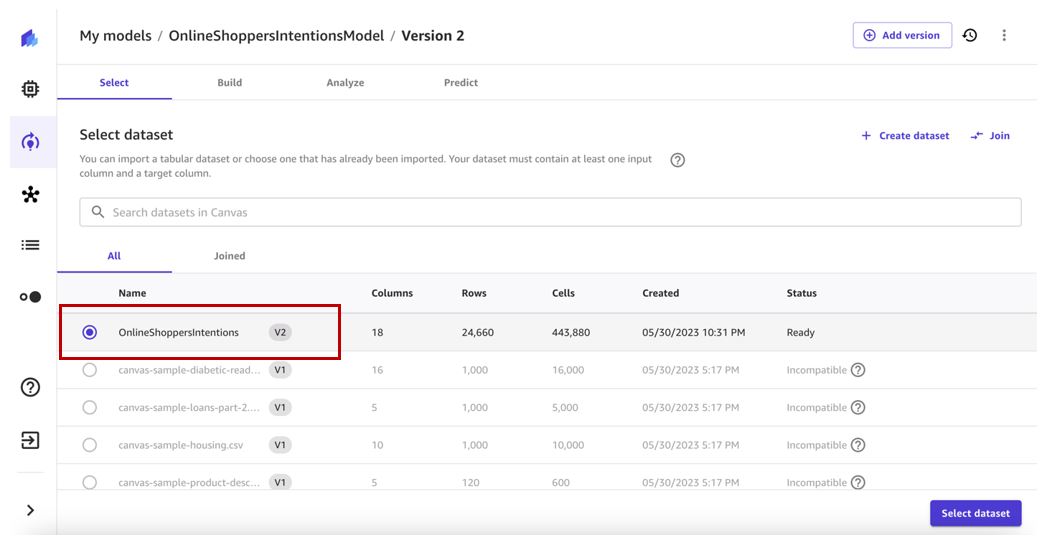
- Сохраните целевой столбец и конфигурацию сборки, аналогичную предыдущей версии модели.

Когда обучение завершено, давайте оценим производительность модели. На следующем снимке экрана показано, что добавление дополнительных данных и переобучение нашей модели машинного обучения помогли улучшить производительность нашей модели.

Создание набора данных для прогнозирования
Обучив модель машинного обучения, давайте создадим набор данных для прогнозов и запустим для него пакетные прогнозы.
- На Datasets страницу, создайте табличный набор данных.
- Введите имя и выберите Создавай.

- В нашу корзину S3 загрузите один файл с 500 строками для прогнозирования.

Затем мы настраиваем автоматические обновления в наборе данных прогнозирования.
- Переключать Включить автоматическое обновление включить и указать источник данных.
- Выберите частоту и укажите время начала.
- Сохраните конфигурацию.
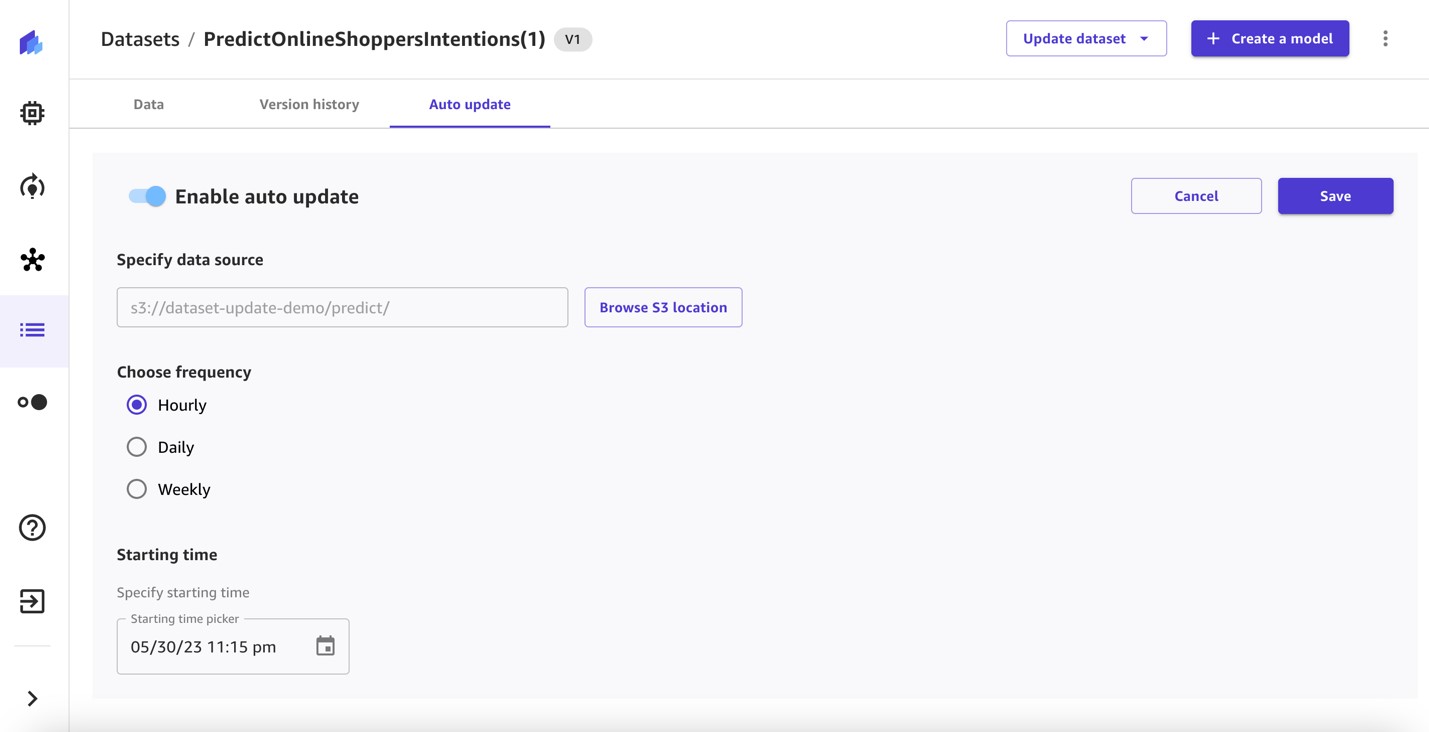
Автоматизируйте рабочий процесс пакетного прогнозирования в автоматически обновляемом наборе данных прогнозов.
На этом этапе мы настраиваем рабочие процессы автоматического пакетного прогнозирования.
- На Мои модели перейдите к версии 2 вашей модели.
- На прогнозировать , выберите Пакетный прогноз и Автоматический.
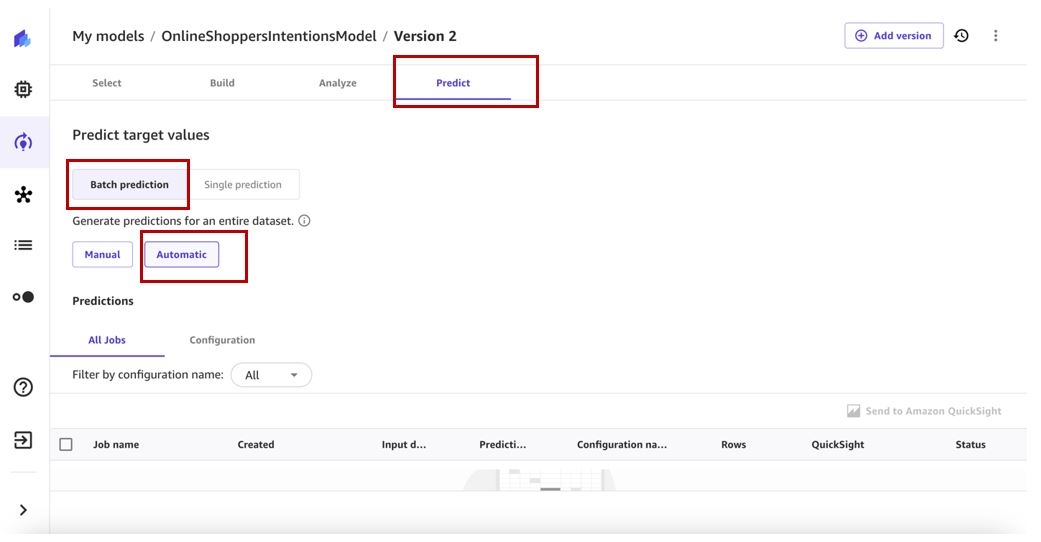
- Выберите Выбрать набор данных чтобы указать набор данных для создания прогнозов.

- Выберите
predictнабор данных, который мы создали ранее, и выберите Выберите набор данных.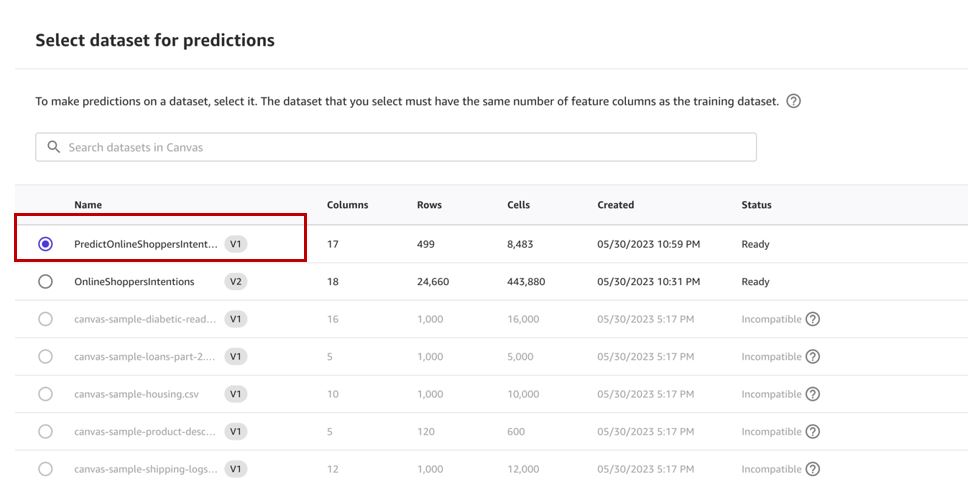
- Выберите Создавать.

Теперь у нас есть автоматический рабочий процесс пакетного прогнозирования. Это сработает, когда Predict набор данных автоматически обновляется.

Теперь давайте загрузим больше файлов CSV в predict Папка S3.
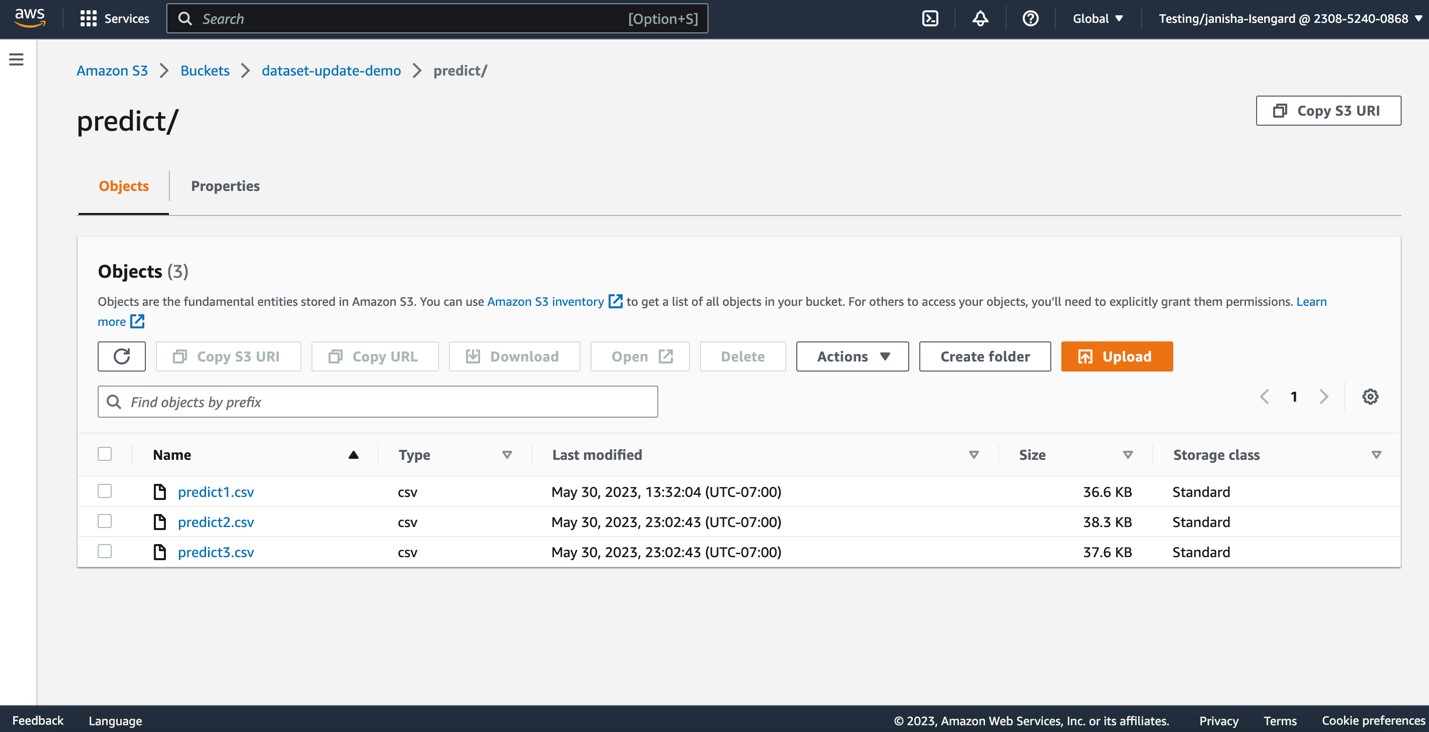
Эта операция вызовет автоматическое обновление predict набор данных.
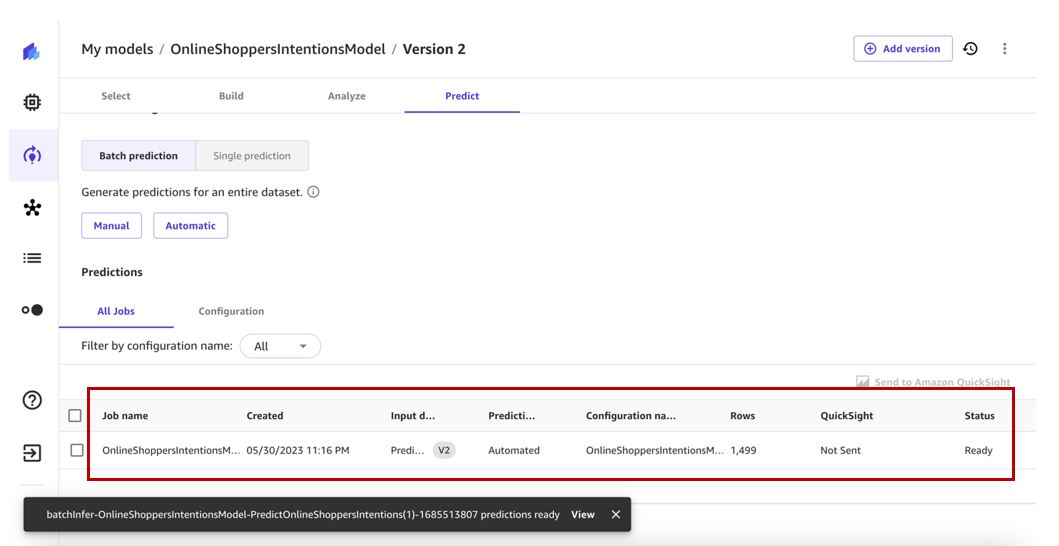
Это, в свою очередь, запускает рабочий процесс автоматического пакетного прогнозирования и генерирует прогнозы для просмотра.

Мы можем просмотреть все автоматы на Automations стр.

Благодаря автоматическому обновлению набора данных и рабочим процессам автоматического пакетного прогнозирования мы можем использовать последнюю версию набора данных в виде таблиц, изображений и документов для обучения моделей машинного обучения и создавать рабочие процессы пакетного прогнозирования, которые автоматически запускаются при каждом обновлении набора данных.
Убирать
Чтобы избежать будущих расходов, выйдите из Canvas. Canvas выставляет вам счет за время сеанса, и мы рекомендуем выходить из Canvas, когда вы его не используете. Ссылаться на Выход из Amazon SageMaker Canvas Больше подробностей.
Заключение
В этом посте мы обсудили, как мы можем использовать новую возможность обновления набора данных для создания новых версий набора данных и обучения наших моделей машинного обучения последним данным в Canvas. Мы также показали, как можно эффективно автоматизировать процесс пакетного прогнозирования обновленных данных.
Чтобы начать свое путешествие по машинному обучению с низким кодом/без кода, см. Руководство разработчика Amazon SageMaker Canvas для разработчиков.
Отдельное спасибо всем, кто участвовал в запуске.
Об авторах
 Яниша Ананд является старшим менеджером по продукту в команде SageMaker No/Low-Code ML, в которую входят SageMaker Canvas и SageMaker Autopilot. Она любит кофе, ведет активный образ жизни и проводит время со своей семьей.
Яниша Ананд является старшим менеджером по продукту в команде SageMaker No/Low-Code ML, в которую входят SageMaker Canvas и SageMaker Autopilot. Она любит кофе, ведет активный образ жизни и проводит время со своей семьей.
 Prashanth является инженером по разработке программного обеспечения в Amazon SageMaker и в основном работает с продуктами SageMaker с низким и нулевым кодом.
Prashanth является инженером по разработке программного обеспечения в Amazon SageMaker и в основном работает с продуктами SageMaker с низким и нулевым кодом.
 Эша Датта работает инженером-разработчиком программного обеспечения в Amazon SageMaker. Она занимается созданием инструментов и продуктов машинного обучения для клиентов. Вне работы она любит прогулки на свежем воздухе, йогу и пешие прогулки.
Эша Датта работает инженером-разработчиком программного обеспечения в Amazon SageMaker. Она занимается созданием инструментов и продуктов машинного обучения для клиентов. Вне работы она любит прогулки на свежем воздухе, йогу и пешие прогулки.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- ЭВМ Финанс. Единый интерфейс для децентрализованных финансов. Доступ здесь.
- Квантум Медиа Групп. ИК/PR усиление. Доступ здесь.
- ПлатонАйСтрим. Анализ данных Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/retrain-ml-models-and-automate-batch-predictions-in-amazon-sagemaker-canvas-using-updated-datasets/