
Обучение больших языковых моделей (LLM) с миллиардами параметров может быть сложной задачей. Помимо разработки архитектуры модели, исследователям необходимо настроить современные методы обучения для распределенного обучения, такие как поддержка смешанной точности, накопление градиентов и контрольные точки. С большими моделями настройка обучения еще более сложна, потому что доступная память в одном ускорительном устройстве ограничивает размер моделей, обученных с использованием только параллелизма данных, а использование параллельного обучения моделей требует дополнительного уровня модификаций обучающего кода. Библиотеки, такие как Глубокая скорость (библиотека оптимизации глубокого обучения с открытым исходным кодом для PyTorch) решает некоторые из этих проблем и может помочь ускорить разработку и обучение моделей.
В этом посте мы настроили обучение на базе Intel Habana Gaudi. Эластичное вычислительное облако Amazon (Амазон EC2) DL1 экземпляров и количественно оценить преимущества использования платформы масштабирования, такой как DeepSpeed. Мы представляем результаты масштабирования для модели преобразователя типа энкодера (BERT с параметрами от 340 до 1.5 миллиардов). Для модели с 1.5 миллиардами параметров мы достигли эффективности масштабирования 82.7 % на 128 ускорителях (16 экземпляров dl1.24xlarge) с использованием DeepSpeed Zero Оптимизация 1 этапа. Состояния оптимизатора были разделены DeepSpeed для обучения больших моделей с использованием парадигмы параллельных данных. Этот подход был расширен для обучения модели с 5 миллиардами параметров с использованием параллелизма данных. Мы также использовали встроенную поддержку Gaudi типа данных BF16 для уменьшения объема памяти и повышения эффективности обучения по сравнению с использованием типа данных FP32. В результате мы добились сходимости модели перед обучением (фаза 1) в течение 16 часов (наша цель состояла в том, чтобы обучить большую модель в течение дня) для модели BERT с 1.5 миллиардами параметров с использованием набор данных wikicorpus-en.
Настройка обучения
Мы подготовили управляемый вычислительный кластер, состоящий из 16 экземпляров dl1.24xlarge, используя Пакет AWS. Мы разработали Семинар по пакетной обработке AWS который иллюстрирует шаги по настройке распределенного учебного кластера с помощью AWS Batch. Каждый экземпляр dl1.24xlarge имеет восемь ускорителей Habana Gaudi, каждый с 32 ГБ памяти и полносвязной сетью RoCE между картами с общей пропускной способностью двунаправленного межсоединения 700 Гбит/с каждая (см. Подробное описание инстансов Amazon EC2 DL1 Чтобы получить больше информации). Кластер dl1.24xlarge также использовал четыре Адаптеры эластичной ткани AWS (EFA) с общей пропускной способностью 400 Гбит/с между узлами.
Семинар распределенного обучения иллюстрирует шаги по настройке кластера распределенного обучения. На семинаре показана конфигурация распределенного обучения с использованием AWS Batch и, в частности, функция параллельных заданий с несколькими узлами для запуска крупномасштабных заданий обучения в контейнерах на полностью управляемых кластерах. В частности, полностью управляемая среда пакетных вычислений AWS создается с помощью экземпляров DL1. Контейнеры вытаскиваются из Реестр Amazon Elastic Container (Amazon ECR) и автоматически запускается в инстансы в кластере на основе определения параллельного задания с несколькими узлами. Семинар завершается параллельным обучением данных модели BERT (от 340 миллионов до 1.5 миллиардов параметров) с несколькими узлами и несколькими HPU с использованием PyTorch и DeepSpeed.
Предварительная тренировка BERT 1.5B с DeepSpeed
Гавана СинапсАИ v1.5 и v1.6 поддержка оптимизации DeepSpeed ZeRO1. Форк Habana репозитория DeepSpeed GitHub включает модификации, необходимые для поддержки ускорителей Gaudi. Существует полная поддержка параллельных распределенных данных (несколько карт, несколько экземпляров), оптимизация ZeRO1 и типы данных BF16.
Все эти функции включены на Репозиторий эталонных моделей BERT 1.5B, который представляет модель двунаправленного кодировщика с 48 уровнями, 1600 скрытых измерений и 25 головок, полученную из реализации BERT. Репозиторий также содержит базовую реализацию модели BERT Large: 24-уровневую, 1024 скрытую, 16-головную архитектуру нейронной сети с 340 миллионами параметров. Сценарии моделирования перед обучением получены из Репозиторий примеров глубокого обучения NVIDIA для загрузки данных wikicorpus_en, предварительной обработки необработанных данных в токены и разделения данных на меньшие наборы данных h5 для параллельного обучения распределенных данных. Вы можете применить этот общий подход для обучения пользовательских архитектур моделей PyTorch с использованием наборов данных с использованием экземпляров DL1.
Результаты масштабирования перед обучением (фаза 1)
Для предварительного обучения больших моделей в масштабе мы в основном сосредоточились на двух аспектах решения: производительность обучения, измеряемая временем обучения, и экономическая эффективность получения полностью конвергентного решения. Далее мы углубимся в эти две метрики на примере предварительного обучения BERT 1.5B.
Масштабирование производительности и времени на обучение
Мы начнем с измерения производительности реализации BERT Large в качестве основы для масштабируемости. В следующей таблице указана измеренная пропускная способность последовательностей в секунду от 1–8 экземпляров dl1.24xlarge (с восемью ускорителями на экземпляр). Используя пропускную способность одного экземпляра в качестве базового уровня, мы измерили эффективность масштабирования для нескольких экземпляров, что является важным рычагом для понимания метрики обучения цена-производительность.
| Количество экземпляров | Количество ускорителей | Последовательности в секунду | Последовательности в секунду на ускоритель | Эффективность масштабирования |
| 1 | 8 | 1,379.76 | 172.47 | 100.0% |
| 2 | 16 | 2,705.57 | 169.10 | 98.04% |
| 4 | 32 | 5,291.58 | 165.36 | 95.88% |
| 8 | 64 | 9,977.54 | 155.90 | 90.39% |
На следующем рисунке показана эффективность масштабирования.

Для BERT 1.5B мы изменили гиперпараметры модели в эталонном репозитории, чтобы гарантировать сходимость. Эффективный размер партии на ускоритель был установлен равным 384 (для максимального использования памяти), с микропакетами по 16 на шаг и 24 шагами накопления градиента. Скорость обучения 0.0015 и 0.003 использовалась для 8 и 16 узлов соответственно. С этими конфигурациями мы добились сходимости фазы 1 предварительного обучения BERT 1.5B на 8 экземплярах dl1.24xlarge (64 ускорителя) примерно за 25 часов и 15 часов на 16 экземплярах dl1.24xlarge (128 ускорителей). На следующем рисунке показаны средние потери в зависимости от количества эпох обучения по мере увеличения количества ускорителей.

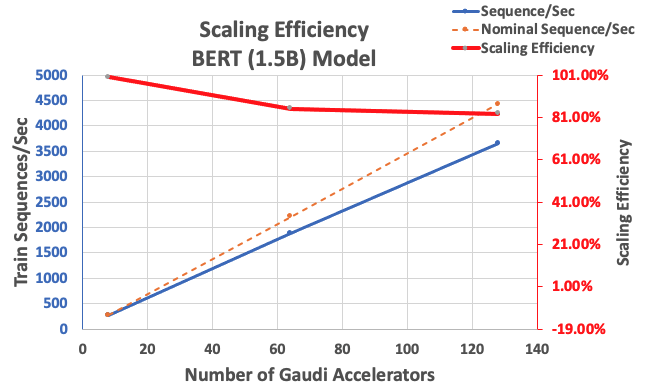
С описанной ранее конфигурацией мы получили высокую эффективность масштабирования на уровне 85 % при использовании 64 ускорителей и 83 % при использовании 128 ускорителей по сравнению с базовым уровнем, состоящим из 8 ускорителей в одном экземпляре. В следующей таблице приведены параметры.
| Количество экземпляров | Количество ускорителей | Последовательности в секунду | Последовательности в секунду на ускоритель | Эффективность масштабирования |
| 1 | 8 | 276.66 | 34.58 | 100.0% |
| 8 | 64 | 1,883.63 | 29.43 | 85.1% |
| 16 | 128 | 3,659.15 | 28.59 | 82.7% |
На следующем рисунке показана эффективность масштабирования.
Заключение
В этом посте мы оценили поддержку DeepSpeed Habana SynapseAI v1.5/v1.6 и то, как это помогает масштабировать обучение LLM на ускорителях Habana Gaudi. Предварительное обучение модели BERT с 1.5 миллиардами параметров заняло 16 часов, чтобы сойтись на кластере из 128 ускорителей Gaudi с масштабированием 85%. Мы рекомендуем вам взглянуть на архитектуру, продемонстрированную в Семинар AWS и рассмотрите возможность его внедрения для обучения пользовательских архитектур моделей PyTorch с использованием экземпляров DL1.
Об авторах
 Махадеван Баласубраманиам является главным архитектором решений для автономных вычислений с почти 20-летним опытом работы в области глубокого обучения, создания и развертывания цифровых двойников для промышленных систем в масштабе. Махадеван получил докторскую степень в области машиностроения в Массачусетском технологическом институте и имеет более 25 патентов и публикаций.
Махадеван Баласубраманиам является главным архитектором решений для автономных вычислений с почти 20-летним опытом работы в области глубокого обучения, создания и развертывания цифровых двойников для промышленных систем в масштабе. Махадеван получил докторскую степень в области машиностроения в Массачусетском технологическом институте и имеет более 25 патентов и публикаций.
 RJ — инженер команды Search M5, возглавляющей усилия по созданию крупномасштабных систем глубокого обучения для обучения и логического вывода. Вне работы он пробует разные кухни и занимается спортом с ракеткой.
RJ — инженер команды Search M5, возглавляющей усилия по созданию крупномасштабных систем глубокого обучения для обучения и логического вывода. Вне работы он пробует разные кухни и занимается спортом с ракеткой.
 Сундар Ранганатан является руководителем отдела развития бизнеса, ML Frameworks в команде Amazon EC2. Он занимается крупномасштабными рабочими нагрузками машинного обучения в таких сервисах AWS, как Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch и Amazon SageMaker. Его опыт включает в себя руководящие должности в области управления продуктами и разработки продуктов в NetApp, Micron Technology, Qualcomm и Mentor Graphics.
Сундар Ранганатан является руководителем отдела развития бизнеса, ML Frameworks в команде Amazon EC2. Он занимается крупномасштабными рабочими нагрузками машинного обучения в таких сервисах AWS, как Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch и Amazon SageMaker. Его опыт включает в себя руководящие должности в области управления продуктами и разработки продуктов в NetApp, Micron Technology, Qualcomm и Mentor Graphics.
 Абхинандан Патни является старшим инженером-программистом в Amazon Search. Он занимается созданием систем и инструментов для масштабируемого распределенного обучения глубокому обучению и логических выводов в реальном времени.
Абхинандан Патни является старшим инженером-программистом в Amazon Search. Он занимается созданием систем и инструментов для масштабируемого распределенного обучения глубокому обучению и логических выводов в реальном времени.
 Пьер-Ив Аквиланти является руководителем отдела Frameworks ML Solutions в Amazon Web Services, где он помогает разрабатывать лучшие в отрасли облачные решения ML Frameworks. Его опыт связан с высокопроизводительными вычислениями, и до прихода в AWS Пьер-Ив работал в нефтегазовой отрасли. Пьер-Ив родом из Франции и имеет докторскую степень. в области компьютерных наук Университета Лилля.
Пьер-Ив Аквиланти является руководителем отдела Frameworks ML Solutions в Amazon Web Services, где он помогает разрабатывать лучшие в отрасли облачные решения ML Frameworks. Его опыт связан с высокопроизводительными вычислениями, и до прихода в AWS Пьер-Ив работал в нефтегазовой отрасли. Пьер-Ив родом из Франции и имеет докторскую степень. в области компьютерных наук Университета Лилля.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- ЭВМ Финанс. Единый интерфейс для децентрализованных финансов. Доступ здесь.
- Квантум Медиа Групп. ИК/PR усиление. Доступ здесь.
- ПлатонАйСтрим. Анализ данных Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/accelerate-pytorch-with-deepspeed-to-train-large-language-models-with-intel-habana-gaudi-based-dl1-ec2-instances/