
To je gostujoča objava, ki sta jo skupaj napisala Maik Leuthold in Nick Harmening iz BMW Group.
O BMW Group ima sedež v Münchnu v Nemčiji, kjer nadzoruje 149,000 zaposlenih ter proizvaja avtomobile in motorna kolesa v več kot 30 proizvodnih obratih v 15 državah. Ta multinacionalna proizvodna strategija sledi še bolj mednarodni in razvejani mreži dobaviteljev.
Tako kot mnoga avtomobilska podjetja po vsem svetu se tudi BMW Group sooča z izzivi v svoji dobavni verigi zaradi svetovnega pomanjkanja polprevodnikov. Ustvarjanje preglednosti glede trenutnega in prihodnjega povpraševanja BMW Group po polprevodnikih je eden ključnih strateških vidikov za reševanje pomanjkanja skupaj z dobavitelji in proizvajalci polprevodnikov. Proizvajalci morajo poznati natančne trenutne in prihodnje podatke o količini polprevodnikov BMW Group, ki bodo učinkovito pomagali usmerjati razpoložljivo svetovno ponudbo.
Glavna zahteva je imeti avtomatizirano, pregledno in dolgoročno napoved povpraševanja po polprevodnikih. Poleg tega mora ta sistem napovedovanja zagotoviti korake obogatitve podatkov, vključno s stranskimi produkti, služiti kot glavni podatki za upravljanje polprevodnikov in omogočiti nadaljnje primere uporabe pri BMW Group.
Da bi omogočili ta primer uporabe, smo uporabili podatkovno platformo BMW Group v oblaku, imenovano Cloud Data Hub. Leta 2019 se je BMW Group odločil preoblikovati in premakniti svoje lokalno podatkovno jezero v oblak AWS, da bi omogočil inovacije, ki temeljijo na podatkih, hkrati pa se prilagaja dinamičnim potrebam organizacije. Podatkovno središče v oblaku obdeluje in združuje anonimizirane podatke iz senzorjev vozil in drugih virov v celotnem podjetju, da je lahko dostopen notranjim ekipam, ki ustvarjajo aplikacije, namenjene strankam, in interne aplikacije. Če želite izvedeti več o Cloud Data Hub, glejte BMW Group uporablja podatkovno jezero na osnovi AWS za odklepanje moči podatkov.
V tej objavi delimo, kako BMW Group analizira uporabo povpraševanja po polprevodnikih AWS lepilo.
Logika in sistemi za napovedjo povpraševanja
Prvi korak k napovedi povpraševanja je identifikacija komponent tipa vozila, pomembnih za polprevodnike. Vsaka komponenta je opisana z edinstveno številko dela, ki služi kot ključ v vseh sistemih za identifikacijo te komponente. Sestavni del je lahko na primer žaromet ali volan.
Zaradi zgodovinskih razlogov so zahtevani podatki za ta korak združevanja izolirani in različno predstavljeni v različnih sistemih. Ker imata vsak izvorni sistem in tip podatkov svojo lastno shemo in obliko, je še posebej težko izvajati analitiko na podlagi teh podatkov. Nekateri izvorni sistemi so že na voljo v Cloud Data Hub (na primer delni glavni podatki), zato jih je preprosto uporabljati iz našega računa AWS. Za dostop do preostalih virov podatkov moramo zgraditi posebna opravila za vnos, ki berejo podatke iz zadevnega sistema.
Naslednji diagram ponazarja pristop.
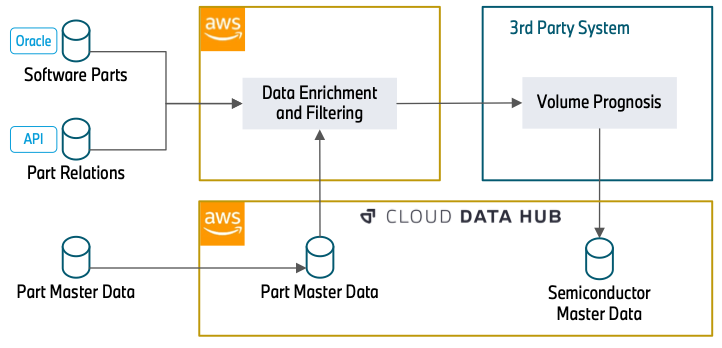
Obogatitev podatkov se začne z zbirko podatkov Oracle (deli programske opreme), ki vsebuje številke delov, ki so povezani s programsko opremo. To je lahko krmilna enota žarometa ali sistem kamer za avtomatizirano vožnjo. Ker so polprevodniki osnova za delovanje programske opreme, ta zbirka podatkov gradi temelj naše obdelave podatkov.
V naslednjem koraku uporabimo API-je REST (Part Relations), da obogatimo podatke z nadaljnjimi atributi. To vključuje, kako so deli povezani (na primer določena krmilna enota, ki bo nameščena v žaromet) in v katerem časovnem obdobju bo številka dela vgrajena v vozilo. Poznavanje razmerij med deli je bistveno za razumevanje, kako je določen polprevodnik, v tem primeru krmilna enota, pomemben za bolj splošen del, žaromet. Časovne informacije o uporabi številk delov nam omogočajo, da filtriramo zastarele številke delov, ki v prihodnosti ne bodo uporabljene in zato nimajo pomena za napoved.
Podatke (glavne podatke dela) je mogoče porabiti neposredno iz središča podatkov v oblaku. Ta zbirka podatkov vključuje atribute o statusu in vrstah materiala številke dela. Te informacije so potrebne za filtriranje številk delov, ki smo jih zbrali v prejšnjih korakih, vendar niso pomembne za polprevodnike. Z informacijami, ki so bile zbrane iz API-jev, se ti podatki poizvedujejo tudi za ekstrahiranje nadaljnjih številk delov, ki niso bile zaužite v prejšnjih korakih.
Po obogatitvi in filtriranju podatkov sistem drugega proizvajalca prebere filtrirane podatke o delih in obogati informacije o polprevodnikih. Nato doda informacije o glasnosti komponent. Nazadnje zagotavlja celotno napoved povpraševanja po polprevodnikih centralno v Cloud Data Hub.
Uporabljene storitve
Naša rešitev uporablja storitve brez strežnika AWS lepilo in Preprosta storitev shranjevanja Amazon (Amazon S3) za zagon delovnih tokov ETL (izvleček, transformacija in nalaganje) brez upravljanja infrastrukture. Prav tako zmanjša stroške s plačilom samo za čas izvajanja opravil. Pristop brez strežnika se zelo dobro ujema z urnikom našega delovnega toka, saj dela izvajamo le enkrat na teden.
Ker uporabljamo različne sisteme virov podatkov ter zapleteno obdelavo in združevanje, je pomembno, da ločimo delovna mesta ETL. To nam omogoča neodvisno obdelavo vsakega vira podatkov. Prav tako smo transformacijo podatkov razdelili na več modulov (Združevanje podatkov, Filtriranje podatkov in Priprava podatkov), da je sistem bolj pregleden in lažji za vzdrževanje. Ta pristop pomaga tudi v primeru podaljšanja ali spreminjanja obstoječih delovnih mest.
Čeprav je vsak modul specifičen za vir podatkov ali določeno transformacijo podatkov, uporabljamo bloke za večkratno uporabo znotraj vsakega opravila. To nam omogoča poenotenje vsake vrste operacij in poenostavi postopek dodajanja novih podatkovnih virov in korakov transformacije v prihodnosti.
Pri naši nastavitvi upoštevamo najboljšo varnostno prakso načela najmanjših privilegijev, da zagotovimo zaščito informacij pred nenamernim ali nepotrebnim dostopom. Zato ima vsak modul AWS upravljanje identitete in dostopa (IAM) vloge s samo potrebnimi dovoljenji, in sicer z dostopom samo do podatkovnih virov in veder, s katerimi se ukvarja delo. Za več informacij o najboljših praksah glede varnosti glejte Najboljše varnostne prakse v IAM.
Pregled rešitev
Naslednji diagram prikazuje celoten potek dela, kjer več opravil AWS Glue zaporedno sodeluje med seboj.

Kot smo že omenili, smo uporabili Cloud Data Hub, Oracle DB in druge vire podatkov, s katerimi komuniciramo prek REST API-ja. Prvi korak rešitve je modul Data Source Ingest, ki črpa podatke iz različnih virov podatkov. V ta namen opravila AWS Glue berejo informacije iz različnih podatkovnih virov in zapisujejo v izvorna vedra S3. Zaužiti podatki so shranjeni v šifriranih vedrih, ključe pa upravlja AWS Service Key Management (AWS KMS).
Po koraku vnosa vira podatkov vmesna opravila združijo in obogatijo tabele z drugimi viri podatkov, kot so različice in kategorije komponent, datumi proizvodnje modelov itd. Nato jih zapišejo v vmesna vedra v modulu za združevanje podatkov, kar ustvari celovito in obilno predstavitev podatkov. Poleg tega v skladu s potekom dela poslovne logike modula za filtriranje podatkov in pripravo podatkov ustvarita končno tabelo z glavnimi podatki samo z dejanskimi in proizvodno pomembnimi informacijami.
Potek dela AWS Glue upravlja vsa ta opravila vnosa in opravila filtriranja od konca do konca. Razpored delovnega toka AWS Glue je konfiguriran tedensko za izvajanje delovnega toka ob sredah. Med izvajanjem delovnega toka vsako opravilo zapiše dnevnike izvajanja (informacije ali napake). Amazon Simple notification Service (Amazon SNS) in amazoncloudwatch za namene spremljanja. Amazon SNS posreduje rezultate izvajanja orodjem za spremljanje, kot so kanali Mail, Teams ali Slack. V primeru kakršne koli napake v opravilih Amazon SNS tudi opozori poslušalce o rezultatu izvajanja opravila, da ukrepajo.
Kot zadnji korak rešitve sistem drugega proizvajalca prebere glavno tabelo iz pripravljenega podatkovnega vedra prek Amazonska Atena. Po nadaljnjih korakih inženiringa podatkov, kot je obogatitev informacij o polprevodnikih in integracija informacij o količini, se končno glavno podatkovno sredstvo zapiše v Cloud Data Hub. S podatki, ki so zdaj na voljo v Cloud Data Hub, lahko drugi primeri uporabe uporabljajo te glavne podatke polprevodnikov, ne da bi zgradili več vmesnikov za različne izvorne sisteme.
Poslovni rezultat
Rezultati projekta zagotavljajo skupini BMW precejšnjo preglednost glede njihovega povpraševanja po polprevodnikih za njihov celoten portfelj vozil v sedanjosti in prihodnosti. Ustvarjanje baze podatkov s to velikostjo omogoča skupini BMW, da vzpostavi še nadaljnje primere uporabe v korist večje preglednosti dobavne verige ter jasnejše in globlje izmenjave z dobavitelji prve stopnje in proizvajalci polprevodnikov. Pomaga ne le pri reševanju trenutnih zahtevnih tržnih razmer, ampak tudi k večji odpornosti v prihodnosti. Zato je to pomemben korak k digitalni, pregledni dobavni verigi.
zaključek
Ta objava opisuje, kako analizirati povpraševanje po polprevodnikih iz številnih virov podatkov z opravili velikih podatkov v delovnem toku AWS Glue. Brezstrežniška arhitektura z minimalno raznolikostjo storitev omogoča enostavno razumevanje in vzdrževanje baze kode in arhitekture. Če želite izvedeti več o uporabi delovnih tokov in opravil AWS Glue za brezstrežniško orkestracijo, obiščite AWS lepilo servisno stran.
O avtorjih
 Maik Leuthold je vodja projekta pri BMW Group za napredno analitiko na poslovnem področju dobavne verige in nabave ter vodi strategijo digitalizacije za upravljanje polprevodnikov.
Maik Leuthold je vodja projekta pri BMW Group za napredno analitiko na poslovnem področju dobavne verige in nabave ter vodi strategijo digitalizacije za upravljanje polprevodnikov.
 Nick Harmening je IT projektni vodja pri BMW Group in AWS certificiran arhitekt rešitev. Gradi in upravlja aplikacije v oblaku s poudarkom na podatkovnem inženiringu in strojnem učenju.
Nick Harmening je IT projektni vodja pri BMW Group in AWS certificiran arhitekt rešitev. Gradi in upravlja aplikacije v oblaku s poudarkom na podatkovnem inženiringu in strojnem učenju.
 Göksel Sarikaya je višji arhitekt aplikacij v oblaku pri AWS Professional Services. Strankam omogoča oblikovanje razširljivih, stroškovno učinkovitih in konkurenčnih aplikacij z inovativno proizvodnjo platforme AWS. Pomaga jim pospešiti poslovne rezultate strank in partnerjev na njihovi poti digitalne transformacije.
Göksel Sarikaya je višji arhitekt aplikacij v oblaku pri AWS Professional Services. Strankam omogoča oblikovanje razširljivih, stroškovno učinkovitih in konkurenčnih aplikacij z inovativno proizvodnjo platforme AWS. Pomaga jim pospešiti poslovne rezultate strank in partnerjev na njihovi poti digitalne transformacije.
 Aleksander Celikov je podatkovni arhitekt pri AWS Professional Services, ki strastno pomaga strankam zgraditi razširljive rešitve za podatke, analitiko in strojno učenje, da bi omogočili pravočasen vpogled in sprejemanje kritičnih poslovnih odločitev.
Aleksander Celikov je podatkovni arhitekt pri AWS Professional Services, ki strastno pomaga strankam zgraditi razširljive rešitve za podatke, analitiko in strojno učenje, da bi omogočili pravočasen vpogled in sprejemanje kritičnih poslovnih odločitev.
 Rahul Shaurya je višji arhitekt za velike podatke pri Amazon Web Services. Pomaga in tesno sodeluje s strankami, ki gradijo podatkovne platforme in analitične aplikacije na AWS. Izven službe Rahul obožuje dolge sprehode s svojim psom Barneyjem.
Rahul Shaurya je višji arhitekt za velike podatke pri Amazon Web Services. Pomaga in tesno sodeluje s strankami, ki gradijo podatkovne platforme in analitične aplikacije na AWS. Izven službe Rahul obožuje dolge sprehode s svojim psom Barneyjem.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoAiStream. Podatkovna inteligenca Web3. Razširjeno znanje. Dostopite tukaj.
- Kovanje prihodnosti z Adryenn Ashley. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/how-the-bmw-group-analyses-semiconductor-demand-with-aws-glue/