
Introduction
Machine Learning (ML) is a field of study that focuses on developing algorithms to learn automatically from data, making predictions and inferring patterns without being explicitly told how to do it. It aims to create systems that automatically improve with experience and data.
This can be achieved through supervised learning, where the model is trained using labeled data to make predictions, or through unsupervised learning, where the model seeks to uncover patterns or correlations within the data without specific target outputs to anticipate.
ML has emerged as an indispensable and widely employed tool across various disciplines, including computer science, biology, finance, and marketing. It has proven its utility in diverse applications such as image classification, natural language processing, and fraud detection.
Machine Learning Tasks
Machine learning can be broadly classified into three main tasks:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Here, we will focus on the first two cases.
Supervised Learning
Supervised learning involves training a model on labeled data, where the input data is paired with the corresponding output or target variable. The goal is to learn a function that can map input data to the correct output. Common supervised learning algorithms include linear regression, logistic regression, decision trees, and support vector machines.
Example of supervised learning code using Python:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
In this simple code example, we train the LinearRegression algorithm from scikit-learn on our training data, and then apply it to get predictions for our test data.
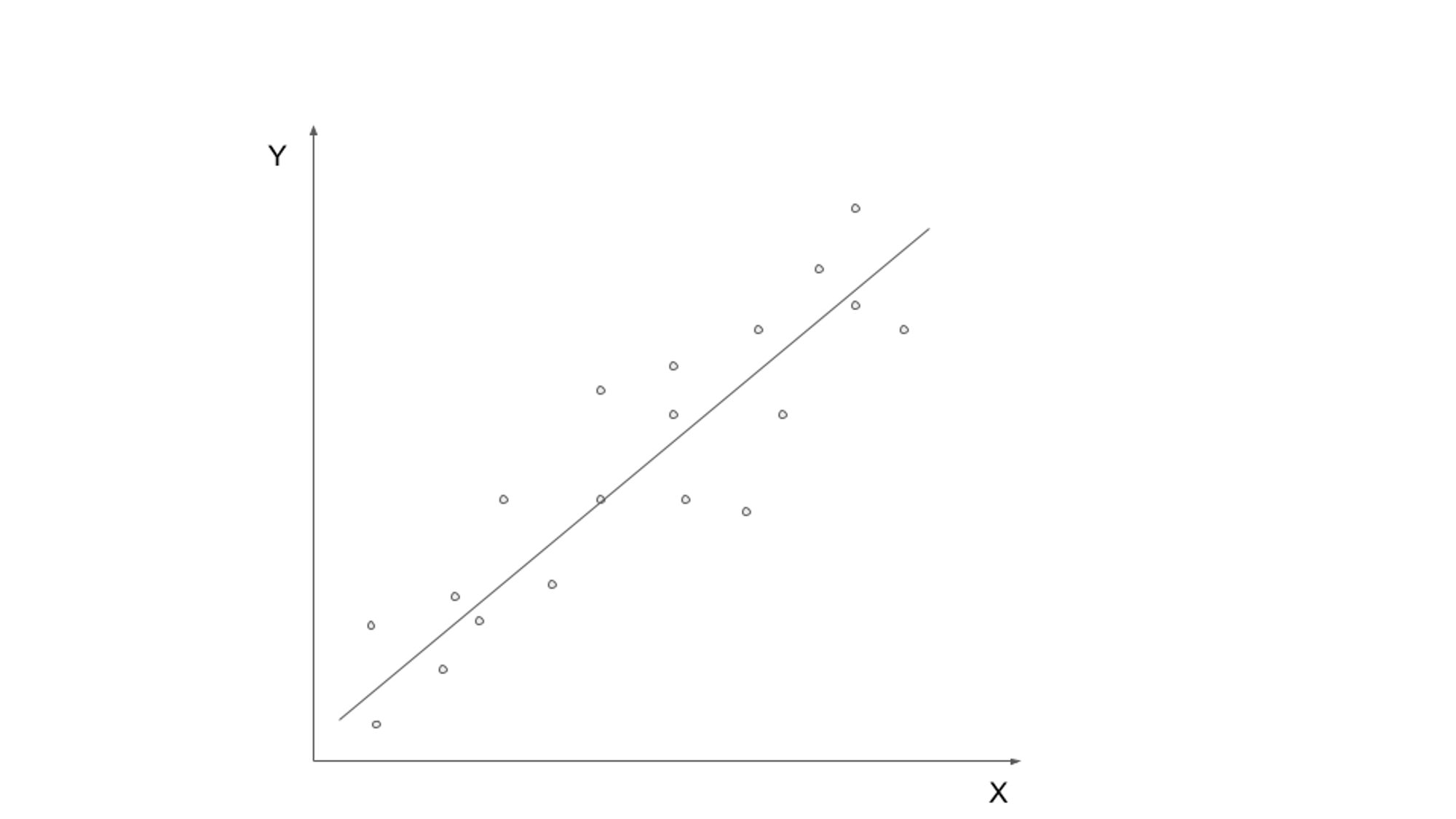
One real-world use case of supervised learning is email spam classification. With the exponential growth of email communication, identifying and filtering spam emails has become crucial. By utilizing supervised learning algorithms, it is possible to train a model to distinguish between legitimate emails and spam based on labeled data.
The supervised learning model can be trained on a dataset containing emails labeled as either “spam” or “not spam.” The model learns patterns and features from the labeled data, such as the presence of certain keywords, email structure, or email sender information. Once the model is trained, it can be used to automatically classify incoming emails as spam or non-spam, efficiently filtering unwanted messages.
Unsupervised Learning
In unsupervised learning, the input data is unlabeled, and the goal is to discover patterns or structures within the data. Unsupervised learning algorithms aim to find meaningful representations or clusters in the data.
Examples of unsupervised learning algorithms include k-means clustering, hierarchical clustering, and principal component analysis (PCA).
Example of unsupervised learning code:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
In this simple code example, we train the KMeans algorithm from scikit-learn to identify three clusters in our data and then fit new data into those clusters.
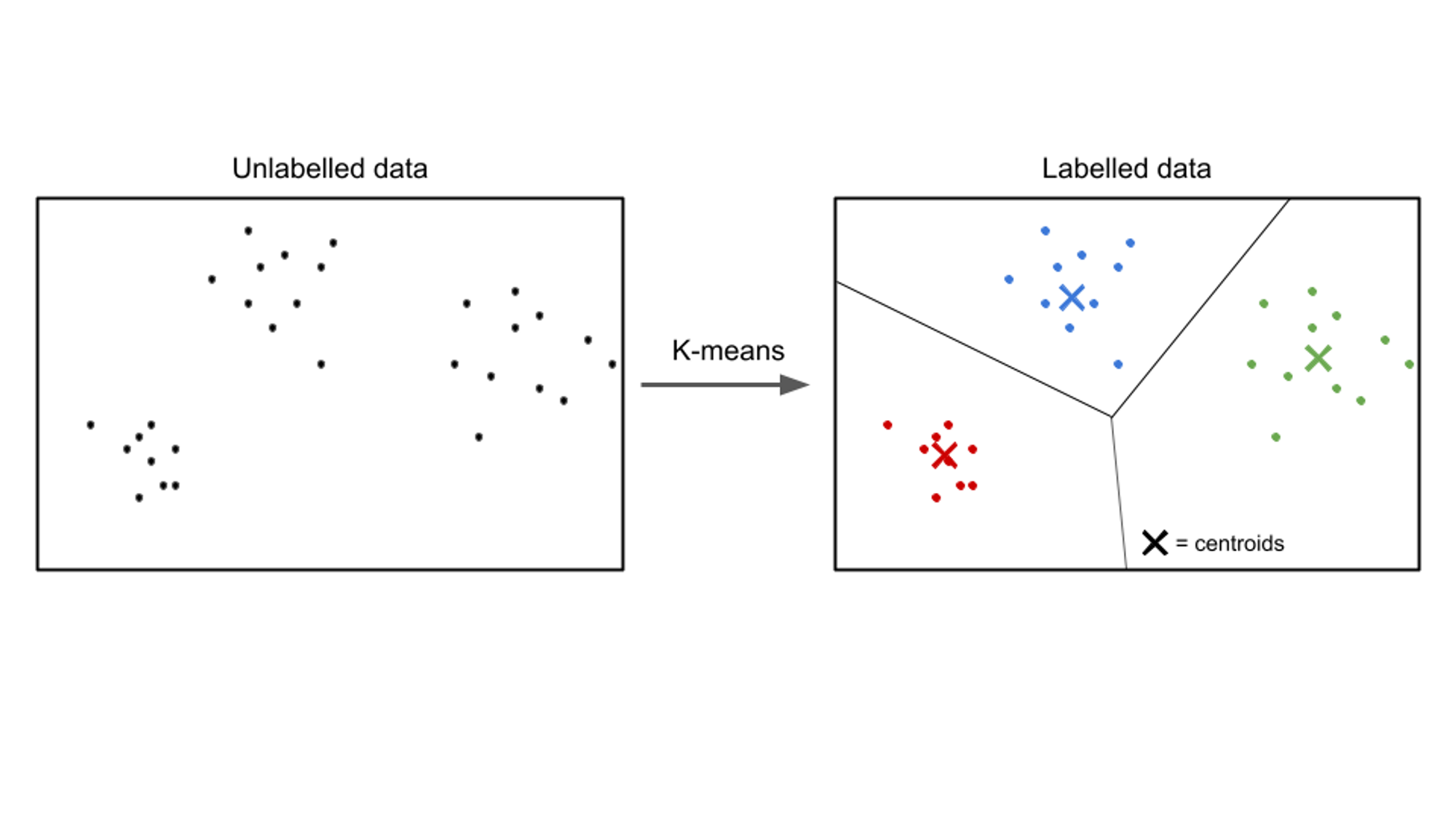
An example of an unsupervised learning use case is customer segmentation. In various industries, businesses aim to understand their customer base better to tailor their marketing strategies, personalize their offerings, and optimize customer experiences. Unsupervised learning algorithms can be employed to segment customers into distinct groups based on their shared characteristics and behaviors.
Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Stop Googling Git commands and actually learn it!
By applying unsupervised learning techniques, such as clustering, businesses can uncover meaningful patterns and groups within their customer data. For instance, clustering algorithms can identify groups of customers with similar purchasing habits, demographics, or preferences. This information can be leveraged to create targeted marketing campaigns, optimize product recommendations, and improve customer satisfaction.
Main Algorithm Classes
Supervised Learning Algorithms
-
Linear models: Used for predicting continuous variables based on linear relationships between features and the target variable.
-
Tree-Based Models: Constructed using a series of binary decisions to make predictions or classifications.
-
Ensemble Models: Method that combines multiple models (tree-based or linear) to make more accurate predictions.
-
Neural Network Models: Methods loosely based on the human brain, where multiple functions work as nodes of a network.
Unsupervised Learning Algorithms
-
Hierarchical Clustering: Builds a hierarchy of clusters by iteratively merging or splitting them.
-
Non-Hierarchical Clustering: Divides data into distinct clusters based on similarity.
-
Dimensionality Reduction: Reduces the dimensionality of data while preserving the most important information.
Model Evaluation
Supervised Learning
To evaluate the performance of supervised learning models, various metrics are used, including accuracy, precision, recall, F1 score, and ROC-AUC. Cross-validation techniques, such as k-fold cross-validation, can help estimate the model’s generalization performance.
Unsupervised Learning
Evaluating unsupervised learning algorithms is often more challenging since there is no ground truth. Metrics such as silhouette score or inertia can be used to assess the quality of clustering results. Visualization techniques can also provide insights into the structure of clusters.
Tips and Tricks
Supervised Learning
- Preprocess and normalize input data to improve model performance.
- Handle missing values appropriately, either by imputation or removal.
- Feature engineering can enhance the model’s ability to capture relevant patterns.
Unsupervised Learning
- Choose the appropriate number of clusters based on domain knowledge or using techniques like the elbow method.
- Consider different distance metrics to measure similarity between data points.
- Regularize the clustering process to avoid overfitting.
In summary, machine learning involves numerous tasks, techniques, algorithms, model evaluation methods, and helpful hints. By comprehending these aspects, practitioners can efficiently apply machine learning to real-world issues and derive significant insights from data. The given code examples showcase the utilization of supervised and unsupervised learning algorithms, highlighting their practical implementation.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- EVM Finance. Unified Interface for Decentralized Finance. Access Here.
- Quantum Media Group. IR/PR Amplified. Access Here.
- PlatoAiStream. Web3 Data Intelligence. Knowledge Amplified. Access Here.
- Source: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/