
Att träna stora språkmodeller (LLM) med miljarder parametrar kan vara utmanande. Förutom att designa modellarkitekturen måste forskare sätta upp toppmoderna träningstekniker för distribuerad träning som blandat precisionsstöd, gradientackumulering och checkpointing. Med stora modeller är träningsupplägget ännu mer utmanande eftersom det tillgängliga minnet i en enstaka acceleratorenhet begränsar storleken på modeller som tränas med endast dataparallellism, och användning av modellparallellträning kräver ytterligare modifieringar av träningskoden. Bibliotek som t.ex DeepSpeed (ett bibliotek för optimering av djupinlärning med öppen källkod för PyTorch) hanterar några av dessa utmaningar och kan hjälpa till att påskynda modellutveckling och utbildning.
I det här inlägget sätter vi upp utbildning på Intel Habana Gaudi-baserad Amazon Elastic Compute Cloud (Amazon EC2) DL1 instanser och kvantifiera fördelarna med att använda ett skalningsramverk som DeepSpeed. Vi presenterar skalningsresultat för en transformatormodell av kodartyp (BERT med 340 miljoner till 1.5 miljarder parametrar). För modellen med 1.5 miljarder parametrar uppnådde vi en skalningseffektivitet på 82.7 % över 128 acceleratorer (16 dl1.24xlarge instanser) med DeepSpeed ZeRO steg 1-optimeringar. Optimeringstillstånden partitionerades av DeepSpeed för att träna stora modeller med hjälp av dataparallellparadigmet. Detta tillvägagångssätt har utvidgats till att träna en modell med 5 miljarder parametrar som använder dataparallellism. Vi använde också Gaudis inbyggda stöd för datatypen BF16 för minskad minnesstorlek och ökad träningsprestanda jämfört med att använda datatypen FP32. Som ett resultat uppnådde vi modellkonvergens före träning (fas 1) inom 16 timmar (vårt mål var att träna en stor modell inom en dag) för BERT-modellen med 1.5 miljarder parametrar med hjälp av wikicorpus-en dataset.
Träningsupplägg
Vi tillhandahållit ett hanterat datorkluster som består av 16 dl1.24xlarge instanser med AWS-batch. Vi utvecklade en AWS Batch-verkstad som illustrerar stegen för att ställa in det distribuerade träningsklustret med AWS Batch. Varje dl1.24xlarge-instans har åtta Habana Gaudi-acceleratorer, var och en med 32 GB minne och ett fullmesh RoCE-nätverk mellan kort med en total dubbelriktad sammankopplingsbandbredd på 700 Gbps vardera (se Amazon EC2 DL1-instanser Deep Dive för mer information). Dl1.24xlarge-klustret använde också fyra AWS elastiska tygadaptrar (EFA), med totalt 400 Gbps sammankoppling mellan noder.
Den distribuerade utbildningsworkshopen illustrerar stegen för att skapa det distribuerade utbildningsklustret. Workshopen visar den distribuerade utbildningsuppsättningen med AWS Batch och i synnerhet funktionen för parallella jobb med flera noder för att lansera storskaliga containeriserade utbildningsjobb på helt hanterade kluster. Mer specifikt skapas en fullt hanterad AWS Batch-beräkningsmiljö med DL1-instanser. Behållarna dras från Amazon Elastic Container Registry (Amazon ECR) och lanseras automatiskt i instanserna i klustret baserat på definitionen av parallella jobb med flera noder. Workshopen avslutas med att köra en multi-nod, multi-HPU data parallell träning av en BERT (340 miljoner till 1.5 miljarder parametrar) modell med PyTorch och DeepSpeed.
BERT 1.5B förträning med DeepSpeed
Habana SynapseAI v1.5 och v1.6 stödja DeepSpeed ZeRO1-optimeringar. De Habana-gaffeln i DeepSpeed GitHub-förvaret innehåller de modifieringar som krävs för att stödja Gaudi-acceleratorerna. Det finns fullt stöd för distribuerad data parallell (multi-card, multi-instans), ZeRO1-optimeringar och BF16-datatyper.
Alla dessa funktioner är aktiverade på BERT 1.5B modellreferensförråd, som introducerar en 48-lagers, 1600-dolda dimension och 25-huvud dubbelriktad kodarmodell, härledd från en BERT-implementering. Förvaret innehåller också baslinjen BERT Large-modellimplementering: en 24-lagers, 1024-dold, 16-head, 340-miljoner-parameter neural nätverksarkitektur. Förträningsmodelleringsskripten är härledda från NVIDIA Deep Learning Exempel förråd för att ladda ner wikicorpus_en-data, förbearbeta rådata till tokens och dela data till mindre h5-datauppsättningar för distribuerad data parallell träning. Du kan använda detta generiska tillvägagångssätt för att träna dina anpassade PyTorch-modellarkitekturer med hjälp av dina datauppsättningar med hjälp av DL1-instanser.
Förträning (fas 1) skalningsresultat
För att förträna stora modeller i stor skala fokuserade vi huvudsakligen på två aspekter av lösningen: träningsprestanda, mätt med tiden det tar att träna, och kostnadseffektiviteten att komma fram till en helt konvergerad lösning. Därefter dyker vi djupare in i dessa två mätvärden med BERT 1.5B förträning som exempel.
Skalning av prestanda och tid att träna
Vi börjar med att mäta prestandan för BERT Large-implementeringen som en baslinje för skalbarhet. Följande tabell listar den uppmätta genomströmningen av sekvenser per sekund från 1-8 dl1.24xlarge instanser (med åtta acceleratorenheter per instans). Genom att använda engångsgenomströmningen som baslinje mätte vi effektiviteten av att skala över flera instanser, vilket är en viktig hävstång för att förstå pris-prestandautbildningsmåttet.
| Antal instanser | Antal acceleratorer | Sekvenser per sekund | Sekvenser per sekund per accelerator | Skalningseffektivitet |
| 1 | 8 | 1,379.76 | 172.47 | 100.0% |
| 2 | 16 | 2,705.57 | 169.10 | 98.04% |
| 4 | 32 | 5,291.58 | 165.36 | 95.88% |
| 8 | 64 | 9,977.54 | 155.90 | 90.39% |
Följande figur illustrerar skalningseffektiviteten.

För BERT 1.5B modifierade vi hyperparametrarna för modellen i referensförvaret för att garantera konvergens. Den effektiva batchstorleken per accelerator sattes till 384 (för maximalt minnesanvändning), med mikrobatcher på 16 per steg och 24 steg av gradientackumulering. Inlärningshastigheter på 0.0015 och 0.003 användes för 8 respektive 16 noder. Med dessa konfigurationer uppnådde vi konvergens av fas 1-förträningen av BERT 1.5B över 8 dl1.24xlarge instanser (64 acceleratorer) på cirka 25 timmar och 15 timmar över 16 dl1.24xlarge instanser (128 acceleratorer). Följande figur visar den genomsnittliga förlusten som en funktion av antalet träningsepoker, när vi skalar upp antalet acceleratorer.

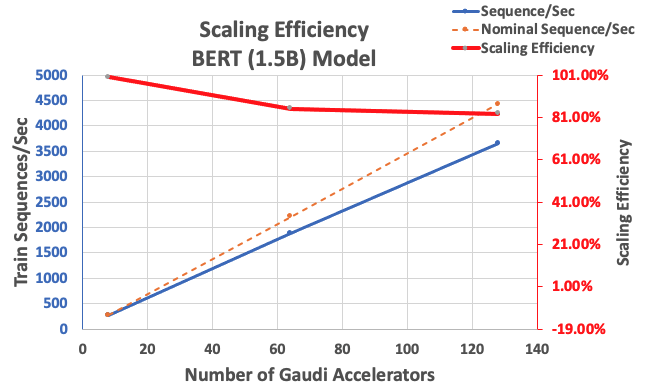
Med den konfiguration som beskrivits tidigare fick vi 85 % stark skalningseffektivitet med 64 acceleratorer och 83 % med 128 acceleratorer, från en baslinje med 8 acceleratorer i ett enda tillfälle. Följande tabell sammanfattar parametrarna.
| Antal instanser | Antal acceleratorer | Sekvenser per sekund | Sekvenser per sekund per accelerator | Skalningseffektivitet |
| 1 | 8 | 276.66 | 34.58 | 100.0% |
| 8 | 64 | 1,883.63 | 29.43 | 85.1% |
| 16 | 128 | 3,659.15 | 28.59 | 82.7% |
Följande figur illustrerar skalningseffektiviteten.
Slutsats
I det här inlägget utvärderade vi stödet för DeepSpeed by Habana SynapseAI v1.5/v1.6 och hur det hjälper till att skala LLM-träning på Habana Gaudi-acceleratorer. Förträning av en BERT-modell med 1.5 miljarder parametrar tog 16 timmar att konvergera på ett kluster av 128 Gaudi-acceleratorer, med 85 % stark skalning. Vi uppmuntrar dig att ta en titt på arkitekturen som visas i AWS verkstad och överväg att använda det för att träna anpassade PyTorch-modellarkitekturer med DL1-instanser.
Om författarna
 Mahadevan Balasubramaniam är en Principal Solutions Architect for Autonomous Computing med nästan 20 års erfarenhet inom området fysikinfunderad djupinlärning, byggande och implementering av digitala tvillingar för industriella system i stor skala. Mahadevan tog sin doktorsexamen i maskinteknik från Massachusetts Institute of Technology och har över 25 patent och publikationer.
Mahadevan Balasubramaniam är en Principal Solutions Architect for Autonomous Computing med nästan 20 års erfarenhet inom området fysikinfunderad djupinlärning, byggande och implementering av digitala tvillingar för industriella system i stor skala. Mahadevan tog sin doktorsexamen i maskinteknik från Massachusetts Institute of Technology och har över 25 patent och publikationer.
 RJ är en ingenjör i Search M5-teamet som leder ansträngningarna för att bygga storskaliga system för djupinlärning för träning och slutledning. Utanför jobbet utforskar han olika maträtter och spelar racketsporter.
RJ är en ingenjör i Search M5-teamet som leder ansträngningarna för att bygga storskaliga system för djupinlärning för träning och slutledning. Utanför jobbet utforskar han olika maträtter och spelar racketsporter.
 Sundar Ranganathan är chef för affärsutveckling, ML Frameworks i Amazon EC2-teamet. Han fokuserar på storskaliga ML-arbetsbelastningar över AWS-tjänster som Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch och Amazon SageMaker. Hans erfarenhet inkluderar ledande roller inom produktledning och produktutveckling på NetApp, Micron Technology, Qualcomm och Mentor Graphics.
Sundar Ranganathan är chef för affärsutveckling, ML Frameworks i Amazon EC2-teamet. Han fokuserar på storskaliga ML-arbetsbelastningar över AWS-tjänster som Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch och Amazon SageMaker. Hans erfarenhet inkluderar ledande roller inom produktledning och produktutveckling på NetApp, Micron Technology, Qualcomm och Mentor Graphics.
 Abhinandan Patni är senior mjukvaruingenjör på Amazon Search. Han fokuserar på att bygga system och verktyg för skalbar distribuerad djupinlärningsträning och realtidsinferens.
Abhinandan Patni är senior mjukvaruingenjör på Amazon Search. Han fokuserar på att bygga system och verktyg för skalbar distribuerad djupinlärningsträning och realtidsinferens.
 Pierre-Yves Aquilanti är Head of Frameworks ML Solutions på Amazon Web Services där han hjälper till att utveckla branschens bästa molnbaserade ML Frameworks-lösningar. Hans bakgrund är inom High Performance Computing och innan han började på AWS arbetade Pierre-Yves i olje- och gasindustrin. Pierre-Yves kommer ursprungligen från Frankrike och har en Ph.D. i datavetenskap från universitetet i Lille.
Pierre-Yves Aquilanti är Head of Frameworks ML Solutions på Amazon Web Services där han hjälper till att utveckla branschens bästa molnbaserade ML Frameworks-lösningar. Hans bakgrund är inom High Performance Computing och innan han började på AWS arbetade Pierre-Yves i olje- och gasindustrin. Pierre-Yves kommer ursprungligen från Frankrike och har en Ph.D. i datavetenskap från universitetet i Lille.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- EVM Finans. Unified Interface for Decentralized Finance. Tillgång här.
- Quantum Media Group. IR/PR förstärkt. Tillgång här.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/accelerate-pytorch-with-deepspeed-to-train-large-language-models-with-intel-habana-gaudi-based-dl1-ec2-instances/