
Beskrivning
Artificiell intelligens (AI) har gjort betydande framsteg i olika branscher, och sjukvården är inget undantag. Ett av de mest lovande områdena inom AI inom sjukvården är Natural Language Processing (NLP), som har potential att revolutionera patientvården genom att underlätta effektivare och mer exakt dataanalys och kommunikation.
NLP har visat sig vara en game changer inom sjukvården. NLP förändrar hur vårdgivare tillhandahåller patientvård. Från folkhälsohantering till sjukdomsdetektering, NLP hjälper vårdpersonal att fatta välgrundade beslut och ge bättre behandlingsresultat.
Inlärningsmål
- Förstå och analysera användningen av NLP och AI i vården
- Att få grepp om grunderna i NLP
- Att lära känna några vanliga NLP-bibliotek inom vården
- Lär dig om användningsfallen av NLP i vården
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
- Motivationen för att använda AI och NLP i vården
- Vad är naturlig språkbehandling?
- Olika tekniker som används i NLP
3.1 Regelbaserade tekniker
3.2 Statistiska tekniker som använder maskininlärningsmodeller
3.3 Överför lärande - Olika NLP-bibliotek och deras ramar
- Vad är stora språkmodeller (LLM)?
- NLP i klinisk text – behovet av ett annat tillvägagångssätt
- Vissa NLP-bibliotek som används inom hälsovårdsindustrin
- Förstå de kliniska datamängderna
- Vilka är olika typer av kliniska data?
- Användningsfall och tillämpningar av NLP i hälso- och sjukvårdsindustrin
- Hur bygger man NLP-pipeline med klinisk text?
11.1 Lösningsdesign
11.2 Steg-för-steg-kod - Slutsats
Motivationen för att använda AI och NLP i vården
Motivationen för att använda AI och NLP inom hälso- och sjukvården har sina rötter i att förbättra patientvård och behandlingsresultat samtidigt som sjukvårdskostnaderna minskar. Sjukvårdsindustrin genererar enorma mängder data, inklusive EMR, kliniska anteckningar och hälsorelaterade inlägg på sociala medier, som kan ge värdefulla insikter om patienternas hälsa och behandlingsresultat. Mycket av denna data är dock ostrukturerad och svår att analysera manuellt.
Dessutom står sjukvårdsindustrin inför flera utmaningar, såsom en åldrande befolkning, ökande frekvens av kroniska sjukdomar och en brist på sjukvårdspersonal.
Dessa utmaningar har lett till ett växande behov av mer effektiv och effektiv sjukvård.
Genom att tillhandahålla värdefulla insikter från ostrukturerade medicinska data kan NLP hjälpa till att förbättra patientvård och behandlingsresultat och stödja vårdpersonal i att fatta mer välgrundade kliniska beslut.
Vad är naturlig språkbehandling?
Natural Language Processing (NLP) är ett underområde av artificiell intelligens (AI) som handlar om interaktionen mellan datorer och mänskliga språk. Den använder beräkningstekniker för att analysera, förstå och generera mänskligt språk. NLP används i många applikationer, inklusive taligenkänning, maskinöversättning, sentimentanalys och textsammanfattning.
Vi kommer nu att utforska de olika NLP-teknikerna, biblioteken och ramarna.
Olika tekniker som används i NLP
Det finns två vanliga tekniker som används i NLP-branschen.
1. Regelbaserade tekniker: lita på fördefinierade grammatikregler och ordböcker
2. Statistiska tekniker: använd maskininlärningsalgoritmer för att analysera och förstå språk
3. Stor språkmodell med hjälp av Överför lärande
Här är en standard NLP Pipeline med olika NLP-uppgifter
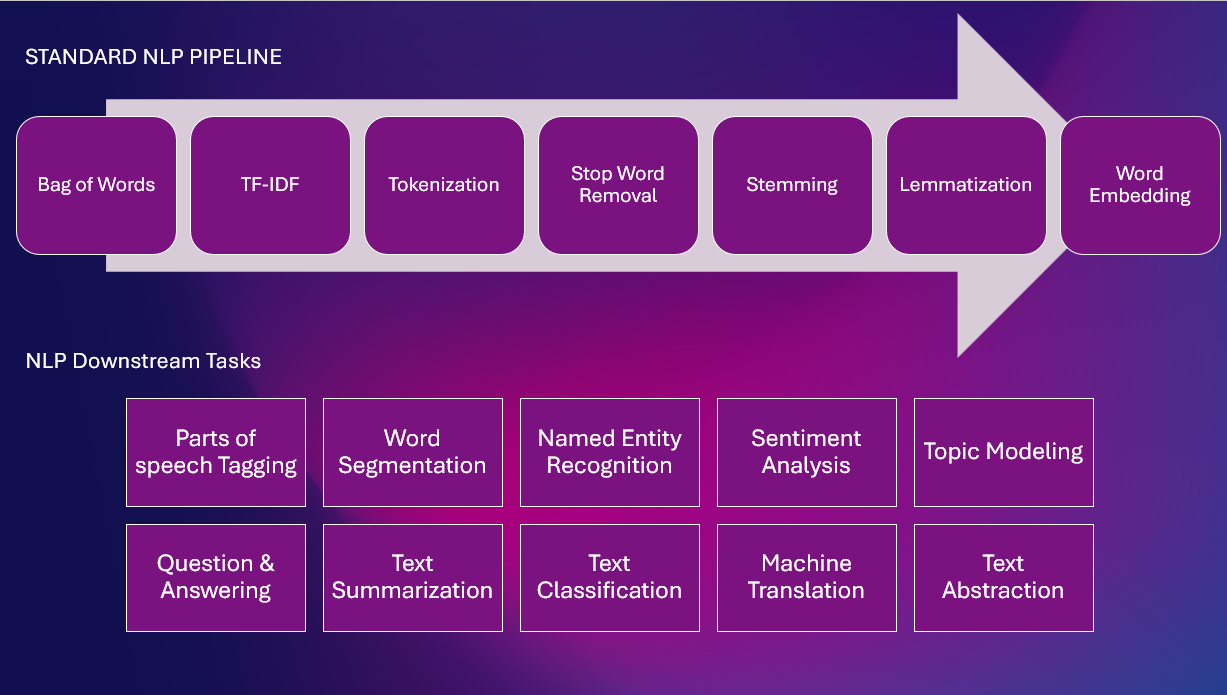
Regelbaserade tekniker
Dessa tekniker innebär att skapa en uppsättning handgjorda regler eller mönster för att extrahera meningsfull information från text. Regelbaserade system fungerar vanligtvis genom att definiera specifika mönster som matchar målinformationen, till exempel namngivna enheter eller specifika nyckelord, och sedan extrahera den informationen baserat på dessa mönster. Regelbaserade system är snabba, pålitliga och enkla, men de begränsas av kvaliteten och antalet regler som definieras, och de kan vara svåra att underhålla och uppdatera.
Till exempel kan ett regelbaserat system för namngivna enhetsigenkänning utformas för att identifiera egennamn i text och kategorisera dem i fördefinierade enhetstyper, såsom en person, plats, organisation, sjukdom, droger, etc. Systemet skulle använda en serie regler för att identifiera mönster i texten som matchar kriterierna för varje enhetstyp, till exempel versaler för personnamn eller specifika nyckelord för organisationer.
Statistiska tekniker som använder maskininlärningsmodeller
Dessa tekniker använder statistiska algoritmer för att lära sig mönster i data och göra förutsägelser baserat på dessa mönster. Maskininlärningsmodeller kan tränas på stora mängder kommenterad data, vilket gör dem mer flexibla och skalbara än regelbaserade system. Flera typer av maskininlärningsmodeller används i NLP, inklusive beslutsträd, slumpmässiga skogar, stödja vektormaskineroch neurala nätverk.
Till exempel kan en maskininlärningsmodell för sentimentanalys tränas på en stor korpus av kommenterad text, där varje text är taggad som positiv, negativ eller neutral. Modellen skulle lära sig de statistiska mönstren i data som skiljer mellan positiv och negativ text och sedan använda dessa mönster för att göra förutsägelser om ny, osynlig text. Fördelen med detta tillvägagångssätt är att modellen kan lära sig att identifiera sentimentmönster som inte är explicit definierade i reglerna.
Överför lärande
Dessa tekniker är en hybrid metod som kombinerar styrkorna hos regelbaserade och maskininlärningsmodeller. Transferinlärning använder en förtränad maskininlärningsmodell, till exempel en språkmodell som tränas på en stor korpus av text, som utgångspunkt för att finjustera en specifik uppgift eller domän. Detta tillvägagångssätt utnyttjar den allmänna kunskapen från den förtränade modellen, vilket minskar mängden märkt data som krävs för utbildning och möjliggör snabbare och mer exakta förutsägelser för en specifik uppgift.
Till exempel kan en överföringsinlärningsmetod för erkännande av namngivna enheter finjustera en förtränad språkmodell på en mindre korpus av kommenterad medicinsk text. Modellen skulle börja med den allmänna kunskap som lärts av den förtränade modellen och sedan anpassa dess vikter för att bättre matcha den medicinska textens mönster. Detta tillvägagångssätt skulle minska mängden märkt data som krävs för utbildning och resultera i en mer exakt modell för erkännande av namngivna enheter inom den medicinska domänen.
Olika NLP-bibliotek och deras ramar
Olika bibliotek tillhandahåller ett brett utbud av NLP-funktioner. Till exempel :

Natural Language Processing (NLP) bibliotek och ramverk är programvaruverktyg som hjälper till att utveckla och distribuera NLP-applikationer. Flera NLP-bibliotek och ramverk finns tillgängliga, alla med styrkor, svagheter och fokusområden.
Dessa verktyg varierar i termer av komplexiteten hos de algoritmer de stöder, storleken på modellerna de kan hantera, användarvänligheten och graden av anpassning de tillåter.
Vad är stora språkmodeller (LLM)?
Stora språkmodeller tränas på enorma mängder data. Kan generera människoliknande text och utföra ett brett utbud av NLP-uppgifter med hög noggrannhet.
Här är några exempel på stora språkmodeller och en kort beskrivning av var och en:
GPT-3 (Generative Pretrained Transformer 3): Utvecklad av OpenAI, GPT-3 är en stor transformatorbaserad språkmodell som använder algoritmer för djupinlärning för att generera människoliknande text. Den har tränats på en massiv korpus av textdata, vilket gör att den kan generera sammanhängande och kontextuellt lämpliga textsvar baserat på en prompt.
BERTI (Dubbelriktade kodarrepresentationer från Transformers): Utvecklad av Google, BERT är en transformatorbaserad språkmodell som har förutbildats på en stor korpus av textdata. Den är utformad för att fungera bra på ett brett spektrum av NLP-uppgifter, såsom namngiven enhetsigenkänning, frågesvar och textklassificering, genom att koda sammanhanget och relationerna mellan ord i en mening.
ROBERTA (Robust optimerad BERT-metod): Utvecklad av Facebook AI, RoBERTa är en variant av BERT som har finjusterats och optimerats för NLP-uppgifter. Den har tränats på en större korpus av textdata och använder en annan träningsstrategi än BERT, vilket leder till förbättrad prestanda på NLP-riktmärken.
ELMo (Inbäddningar från språkmodeller): Utvecklad av Allen Institute for AI, ELMo är en djup kontextualiserad ordrepresentationsmodell som använder ett dubbelriktat LSTM-nätverk (Long Short-Term Memory) för att lära sig språkrepresentationer från en stor korpus av textdata. ELMo kan finjusteras för specifika NLP-uppgifter eller användas som funktionsextraktor för andra maskininlärningsmodeller.
ULMFiT (Universal Language Model Fine-Tuning): Utvecklad av FastAI, ULMFiT är en överföringsinlärningsmetod som finjusterar en förtränad språkmodell på en specifik NLP-uppgift med hjälp av en liten mängd uppgiftsspecifik kommenterad data. ULMFiT har uppnått toppmodern prestanda på ett brett spektrum av NLP-riktmärken och anses vara ett ledande exempel på överföringsinlärning inom NLP.
NLP i klinisk text: The Need for Different Approach
Klinisk text är ofta ostrukturerad och innehåller mycket medicinsk jargong och akronymer, vilket gör det svårt för traditionella NLP-modeller att förstå och bearbeta. Dessutom innehåller klinisk text ofta viktig information som sjukdom, läkemedel, patientinformation, diagnoser och behandlingsplaner, som kräver specialiserade NLP-modeller som exakt kan extrahera och förstå denna medicinska information.
En annan anledning till att klinisk text behöver olika NLP-modeller är att den innehåller en stor mängd data spridda över olika källor, såsom EPJ, kliniska anteckningar och röntgenrapporter, som måste integreras. Detta kräver modeller som kan bearbeta och förstå texten och länka och integrera data över olika källor och etablera kliniskt acceptabla relationer.
Slutligen innehåller klinisk text ofta känslig patientinformation och måste skyddas av strikta regler som HIPAA. NLP-modeller som används för att bearbeta klinisk text måste kunna identifiera och skydda känslig patientinformation samtidigt som de ger användbara insikter.
Vissa NLP-bibliotek som används inom hälsovårdsindustrin
Textdata inom medicin kräver ett specialiserat Natural Language Processing (NLP) system som kan extrahera medicinsk information från olika källor såsom kliniska texter och andra medicinska dokument.
Här är en lista över NLP-bibliotek och modeller som är specifika för den medicinska domänen:
rymd: Det är ett NLP-bibliotek med öppen källkod som tillhandahåller färdiga modeller för olika domäner, inklusive den medicinska domänen.
ScispaCy: En specialiserad version av spaCy som är utbildad specifikt på vetenskaplig och biomedicinsk text, vilket gör den idealisk för bearbetning av medicinsk text.
BioBERT: En förtränad transformatorbaserad modell speciellt designad för den biomedicinska domänen. Den är förtränad med Wiki + Books + PubMed + PMC.
ClinicalBERT: En annan förtränad modell utformad för att behandla kliniska anteckningar och sammanfattningar av utskrivningar från MIMIC-III-databasen.
Med7: En transformatorbaserad modell som tränades i elektroniska hälsojournaler (EHR) för att extrahera sju viktiga kliniska koncept, inklusive diagnos, medicinering och laboratorietester.
DisMod-ML: Ett probabilistiskt modelleringsramverk för sjukdomsmodellering som använder NLP-tekniker för att bearbeta medicinsk text.
LÄKARE: Ett regelbaserat NLP-system för att extrahera medicinsk information från text.
Det här är några av de populära NLP-biblioteken och modellerna som är speciellt utformade för den medicinska domänen. De erbjuder en rad funktioner, från förutbildade modeller till regelbaserade system, och kan hjälpa vårdorganisationer att bearbeta medicinsk text effektivt.
I vår NER-modell kommer vi att använda spaCy och Scispacy. Dessa bibliotek är förhållandevis enkla att köra på Google colab eller lokal infrastruktur.
De resurskrävande stora språkmodellerna BioBERT och ClinicalBERT behöver GPU:er och högre infrastruktur.
Förstå de kliniska datamängderna
Medicinsk textdata kan erhållas från olika källor, såsom elektroniska journaler (EPJ), medicinska tidskrifter, kliniska anteckningar, medicinska webbplatser och databaser. Vissa av dessa källor tillhandahåller allmänt tillgängliga datauppsättningar som kan användas för utbildning av NLP-modeller, medan andra kan kräva godkännande och etiska överväganden innan de får tillgång till data. Källorna till medicinsk textdata inkluderar:
1. Medicinska korpora med öppen källkod som t.ex MIMIC-III databas är en stor, öppet tillgänglig elektronisk journaldatabas (EHR) från patienter som fick vård vid Beth Israel Deaconess Medical Center mellan 2001 och 2012. Databasen innehåller information som patientdemografi, vitala tecken, laboratorietester, mediciner, procedurer och anteckningar från sjukvårdspersonal, såsom sjuksköterskor och läkare. Dessutom innehåller databasen information om patienters intensivvårdsvistelser, inklusive typ av intensivvård, vistelsetid och resultat. Uppgifterna i MIMIC-III är avidentifierade och kan användas för forskningsändamål för att stödja utvecklingen av prediktiva modeller och kliniska beslutsstödssystem.
2. Nationalbiblioteket för medicin ClinicalTrials.gov webbplatsen har data från kliniska prövningar och sjukdomsövervakningsdata.
3. National Institutes of Healths National Library of Medicine, National Centers for Biotechnology Information (NCBI), och Världshälsoorganisationen (VEM)
4. Sjukvårdsinstitutioner och organisationer som sjukhus, kliniker och läkemedelsföretag genererar stora mängder medicinsk textdata genom elektroniska journaler, kliniska anteckningar, medicinsk transkription och medicinska rapporter.
5. Medicinska forskningstidskrifter och databaser, såsom PubMed och CINAHL, innehåller stora mängder publicerade medicinska forskningsartiklar och sammanfattningar.
6. Sociala medieplattformar som Twitter kan ge realtidsinsikter om patientperspektiv, läkemedelsrecensioner och upplevelser.
För att träna NLP-modeller med hjälp av medicinsk textdata är det viktigt att ta hänsyn till datas kvalitet och relevans och se till att den är korrekt förbehandlad och formaterad. Dessutom är det viktigt att följa etiska och juridiska överväganden när man arbetar med känslig medicinsk information.
Vilka är olika typer av kliniska data?
Flera typer av kliniska data används ofta inom vården:

Kliniska data avser information om individers hälsovård, inklusive patientens medicinska historia, diagnoser, behandlingar, labbresultat, bildstudier och annan relevant hälsoinformation.
EHR/EMR-data är länkade till demografisk data (detta inkluderar personlig information som ålder, kön, etnicitet och kontaktinformation.), Patientgenererad data (denna typ av data genereras av patienterna själva, inklusive information som samlats in genom patientrapporterade resultatmått och patient -genererade hälsodata.)
Andra uppsättningar data är:
Genomisk data: Denna typ avser en individs genetiska information, inklusive DNA-sekvenser och markörer.
Data för bärbara enheter: Dessa data inkluderar information som samlats in från bärbara enheter som träningsspårare och hjärtmonitorer.
Varje typ av klinisk data spelar en unik roll för att ge en heltäckande bild av en patients hälsa och används på olika sätt av vårdgivare och forskare för att förbättra patientvården och informera behandlingsbeslut.
Användningsfall och tillämpningar av NLP i hälso- och sjukvårdsindustrin
Natural Language Processing (NLP) har antagits allmänt inom sjukvårdsindustrin och har flera användningsfall. Några av de framstående inkluderar:
Befolknings hälsa: NLP kan användas för att bearbeta stora mängder ostrukturerad medicinsk data såsom medicinska journaler, undersökningar och anspråksdata för att identifiera mönster, korrelationer och insikter. Detta hjälper till att övervaka befolkningens hälsa och tidig upptäckt av sjukdomar.
Patientvård: NLP kan användas för att behandla patienters elektroniska hälsojournaler (EHR) för att extrahera viktig information som diagnos, mediciner och symtom. Denna information kan användas för att förbättra patientvården och ge personlig behandling.
Sjukdomsdetektering: NLP kan användas för att bearbeta stora mängder textdata, såsom vetenskapliga artiklar, nyhetsartiklar och inlägg på sociala medier, för att upptäcka utbrott av infektionssjukdomar.
Clinical Decision Support System (CDSS): NLP kan användas för att analysera patienters elektroniska journaler för att ge beslutsstöd i realtid till vårdgivare. Detta hjälper till att tillhandahålla bästa möjliga behandlingsalternativ och förbättra den övergripande kvaliteten på vården.
Klinisk prövning: NLP kan bearbeta data från kliniska prövningar för att identifiera samband och potentiella nya behandlingar.
Narkotikabiverkningar: NLP kan användas för att bearbeta stora mängder läkemedelssäkerhetsdata för att identifiera biverkningar och läkemedelsinteraktioner.
Precision Health: NLP kan användas för att behandla genomiska data och medicinska journaler för att identifiera personliga behandlingsalternativ för enskilda patienter.
Läkarens effektivitetsförbättring: NLP kan automatisera rutinuppgifter som medicinsk kodning, datainmatning och anspråksbearbetning, vilket gör att läkare kan fokusera på att ge bättre patientvård.
Det här är bara några exempel på hur NLP revolutionerar sjukvårdsbranschen. När NLP-tekniken fortsätter att utvecklas kan vi förvänta oss att se fler innovativa användningar av NLP inom vården i framtiden.
Hur bygger man NLP-pipeline med klinisk text?
Vi kommer att utveckla en steg-för-steg-pipeline för Spacy med hjälp av SciSpacy NER Model for Clinical Text.
Mål: Detta projekt syftar till att konstruera en NLP-pipeline som använder SciSpacy för att utföra anpassad Named Entity Recognition på kliniska texter.
Resultat: Resultatet kommer att extrahera information om sjukdomar, läkemedel och läkemedelsdoser från klinisk text, som sedan kan användas i olika NLP nedströms applikationer.
Lösningsdesign:
Här är lösningen på hög nivå för att extrahera enhetsinformation från Clinical Text. NER-extraktion är en viktig NLP-uppgift som används i de flesta NLP-pipelines.
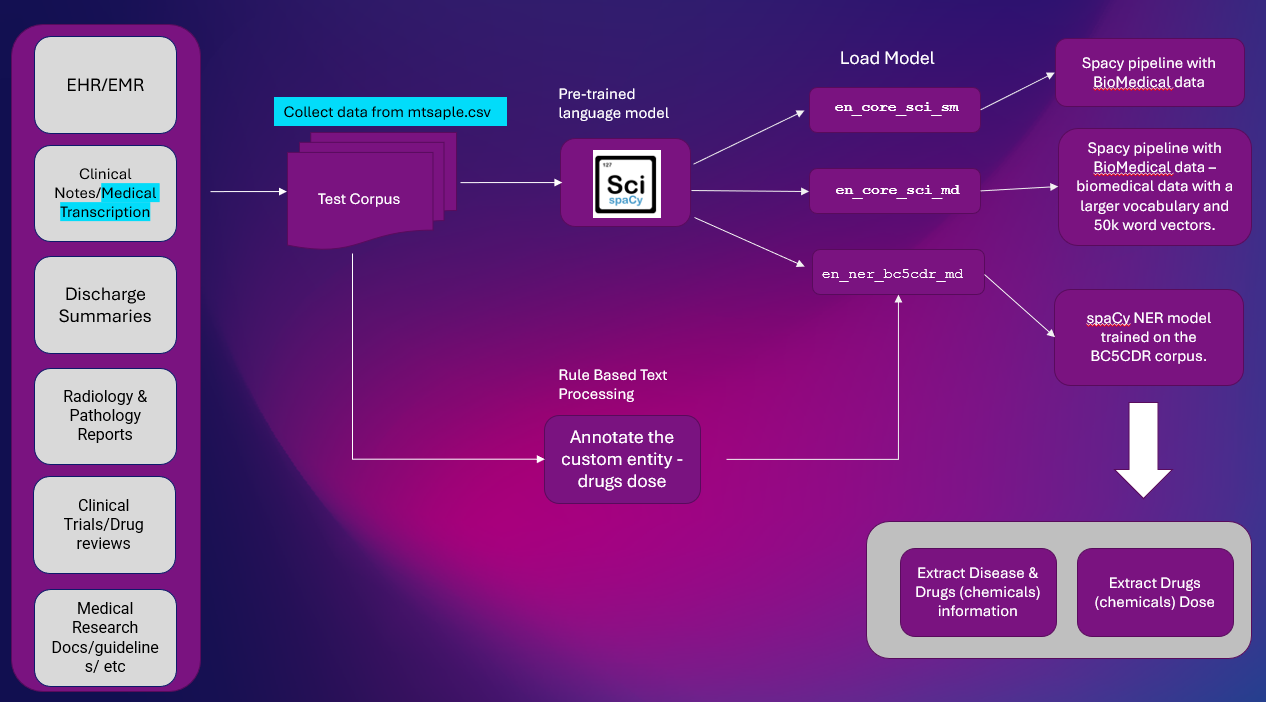
Plattform: Google Colab
NLP-bibliotek: spaCy & SciSpacy
dataset: mtsample.csv (skrotade data från mtsample).
Vi har använt ScispaCy förtränad NER-modell en_ner_bc5cdr_md-0.5.1 att utvinna sjukdomar och droger. Läkemedel utvinns som kemikalier.
en_ner_bc5cdr_md-0.5.1 är en spaCy-modell för namngiven enhetsigenkänning (NER) i den biomedicinska domänen.
"bc5cdr" hänvisar till BC5CDR corpus, en biomedicinsk textkorpus som används för att träna modellen. "md" i namnet hänvisar till den biomedicinska domänen. "0.5.1" i namnet hänvisar till modellens version.
Vi kommer att använda provet "transkriptions"-text från mtsample.csv och kommentera med hjälp av ett regelbaserat mönster för att extrahera läkemedelsdoser.
Steg-för-steg-kod:
Installera spacy & scispacy-paket. spaCy-modeller är designade för att utföra specifika NLP-uppgifter, såsom tokenisering, ordordstaggning och namngiven enhetsigenkänning.
!pip installation -U spacy !pip installation scispacy
Installera scispacy-basmodeller och NER-modeller
Modellen en_ner_bc5cdr_md-0.5.1 är speciellt utformad för att känna igen namngivna enheter i biomedicinsk text, såsom sjukdomar, gener och läkemedel, som kemikalier.
Denna modell kan vara användbar för NLP-uppgifter inom den biomedicinska domänen, såsom informationsextraktion, textklassificering och frågesvar.
!pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_sm-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_md-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_ner_bc5cdr_md-0.5.1.tar.gz
Installera andra paket
pip installera render
Importera paket
import scispacy import spacy #Core models import en_core_sci_sm import en_core_sci_md
#NER specifika modeller import en_ner_bc5cdr_md #Verktyg för att extrahera och visa data från rymliga importförskjutningar importera pandor som pd
Python-kod:
Testa modellerna med exempeldata
# Välj specifik transkription att använda (rad 3, kolumn "transcription") och testa scispacy NER-modellens text = mtsample_df.loc[10, "transcription"]

Ladda specifik modell: en_core_sci_sm och skicka text igenom
nlp_sm = en_core_sci_sm.load() doc = nlp_sm(text)
#Visa resultat
enhetsextraktion displacy_image = displacy.render(doc, jupyter=True,style='ent')

Observera att enheten är taggad här. Mest medicinska termer. Dessa är dock generiska enheter.
Ladda nu den specifika modellen: en_core_sci_md och skicka text igenom
nlp_md = en_core_sci_md.load() doc = nlp_md(text)
#Visa resulterande enhetsextraktion
displacy_image = displacy.render(doc, jupyter=True,style='ent')

Den här gången är numren också taggade som entiteter av en_core_sci_md.
Ladda nu specifik modell: importera en_ner_bc5cdr_md och skicka igenom text
nlp_bc = en_ner_bc5cdr_md.load() doc = nlp_bc(text) #Display resulterande enhetsextraktion displacy_image = displacy.render(doc, jupyter=True,style='ent')

Nu är två medicinska enheter taggade: sjukdom och kemikalie(droger).
Visa enheten
print("TEXT", "START", "END", "ENTITY TYPE") för ent i doc.ents: print(ent.text, ent.start_char, ent.end_char, ent.label_)
TEXT START SLUT ENHETSTYP
Sjuklig fetma 26 40 SJUKDOM
Sjuklig fetma 70 84 SJUKDOM
viktminskning 400 411 SJUKDOM
Marcaine 1256 1264 KEMISKA
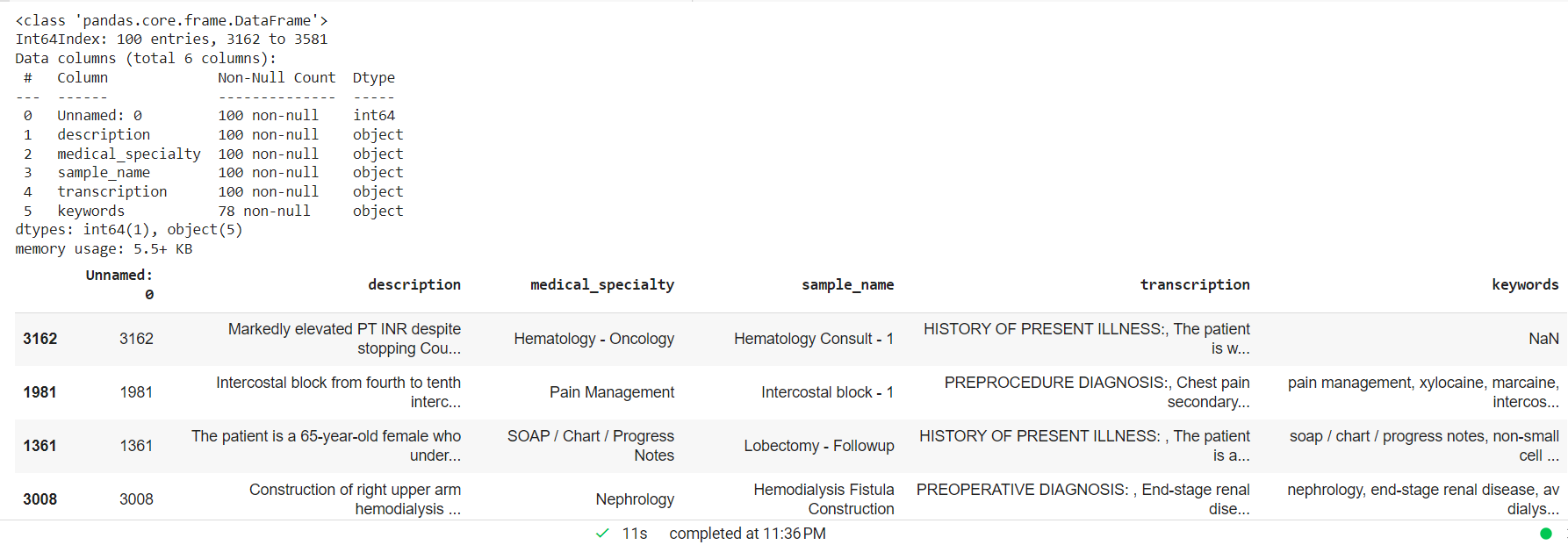
Bearbeta den kliniska texten genom att ta bort NAN-värden och skapa ett slumpmässigt mindre urval för den anpassade enhetsmodellen.
mtsample_df.dropna(subset=['transcription'], inplace=True) mtsample_df_subset = mtsample_df.sample(n=100, replace=False, random_state=42) mtsample_df_subset.info() mtsample.head()_subset
spaCy matcher – Den regelbaserade matchningen liknar användningen av reguljära uttryck, men spaCy ger ytterligare möjligheter. Genom att använda tokens och relationerna i ett dokument kan du identifiera mönster som inkluderar entiteter med hjälp av NER-modeller. Målet är att hitta läkemedelsnamn och deras doseringar från texten, vilket kan hjälpa till att upptäcka medicineringsfel genom att jämföra dem med standarder och riktlinjer.
Målet är att hitta läkemedelsnamn och deras doseringar från texten, vilket kan hjälpa till att upptäcka medicineringsfel genom att jämföra dem med standarder och riktlinjer.
från spacy.matcher import Matcher
mönster = [{'ENT_TYPE':'CHEMICAL'}, {'LIKE_NUM': True}, {'IS_ASCII': True}] matcher = Matcher(nlp_bc.vocab) matcher.add("DRUG_DOSE", [pattern])
för transkription i mtsample_df_subset['transcription']: doc = nlp_bc(transcription) matches = matcher(doc) för match_id, start, end in matches: string_id = nlp_bc.vocab.strings[match_id] # get string representation span = doc[start :end] # det matchade intervallet lägg till läkemedelsdoser print(span.text, start, end, string_id,) #Lägg till sjukdom och läkemedel för ent in doc.ents: print(ent.text, ent.start_char, ent.end_char, ent .märka_)
Utdata kommer att visa enheterna som extraherats från det kliniska textprovet.
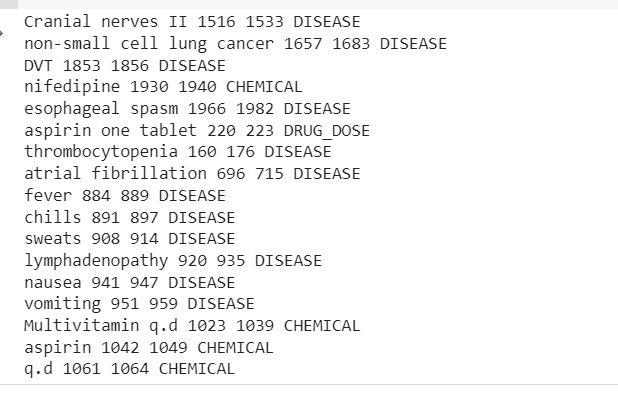
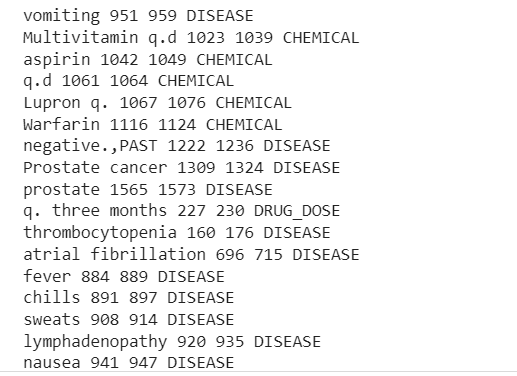
Nu kan vi se rörledningen extraherad Sjukdomar, droger (kemikalier) och läkemedelsdoser information från den kliniska texten.
Det finns en viss felklassificering, men vi kan öka modellens prestanda med mer data.
Vi kan nu använda dessa medicinska enheter i olika uppgifter som sjukdomsdetektering, prediktiv analys, kliniskt beslutsstödssystem, medicinsk textklassificering, sammanfattning, svar på frågor och många fler.
Slutsats
1. I den här artikeln har vi utforskat några av nyckelfunktionerna i NLP i hälso- och sjukvården, som kommer att hjälpa dig att förstå de komplexa vårdtextdata.
Vi implementerade också scispaCy och spaCy och konstruerade en enkel anpassad NER-modell genom en förtränad NER-modell och regelbaserad matchning. Även om vi bara har täckt en NER-modell, finns många andra tillgängliga och en stor mängd ytterligare funktioner att upptäcka.
2. Inom ramen för scispaCy finns det många ytterligare tekniker att utforska, inklusive metoder för att upptäcka förkortningar, utföra beroendeanalys och identifiera enskilda meningar.
3. De senaste trenderna inom NLP för sjukvård inkluderar utvecklingen av domänspecifika modeller som BioBERT och ClinicalBert och användning av stora språkmodeller som GPT-3. Dessa modeller erbjuder en hög nivå av noggrannhet och effektivitet, men deras användning väcker också oro för partiskhet, integritet och kontroll över data.
ChatGPT (en avancerad konversations-AI-modell utvecklad av OpenAI) gör redan en enorm inverkan i NLP-världen. Modellen är tränad på en enorm mängd textdata från internet och har förmågan att generera människoliknande textsvar baserat på den input den får. Den kan användas för olika uppgifter som att svara på frågor, sammanfatta, översätta och mer. Modellen är också finjusterad för specifika användningsfall, som att generera kod eller skriva artiklar, för att förbättra dess prestanda inom de specifika områdena.
5. Men trots dess många fördelar är NLP inom sjukvården inte utan sina utmaningar. Att säkerställa noggrannheten och rättvisan hos NLP-modeller och att övervinna problem med datasekretess är några av de utmaningar som måste lösas för att fullt ut förverkliga potentialen för NLP inom hälso- och sjukvården.
6. Med sina många fördelar är det viktigt för vårdpersonal att ta till sig och införliva NLP i sina arbetsflöden. Även om det finns många utmaningar att övervinna, är NLP inom sjukvården verkligen en trend värd att titta på och investera i.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/02/extracting-medical-information-from-clinical-text-with-nlp/