
Konversationsassistenter för artificiell intelligens (AI) är konstruerade för att ge exakta svar i realtid genom intelligent dirigering av frågor till de mest lämpliga AI-funktionerna. Med AWS generativa AI-tjänster som Amazonas berggrund, kan utvecklare skapa system som sakkunnigt hanterar och svarar på användarförfrågningar. Amazon Bedrock är en helt hanterad tjänst som erbjuder ett urval av högpresterande grundmodeller (FM) från ledande AI-företag som AI21 Labs, Anthropic, Cohere, Meta, Stability AI och Amazon med ett enda API, tillsammans med en bred uppsättning av funktioner du behöver för att bygga generativa AI-applikationer med säkerhet, integritet och ansvarsfull AI.
Det här inlägget bedömer två primära tillvägagångssätt för att utveckla AI-assistenter: att använda hanterade tjänster som t.ex Agenter för Amazon Bedrock, och använder öppen källkodsteknik som Langkedja. Vi utforskar fördelarna och utmaningarna med var och en, så att du kan välja den mest lämpliga vägen för dina behov.
Vad är en AI-assistent?
En AI-assistent är ett intelligent system som förstår naturliga språkfrågor och interagerar med olika verktyg, datakällor och API:er för att utföra uppgifter eller hämta information för användarens räkning. Effektiva AI-assistenter har följande nyckelfunktioner:
- Naturlig språkbehandling (NLP) och samtalsflöde
- Kunskapsbasintegration och semantiska sökningar för att förstå och hämta relevant information baserat på nyanserna i konversationskontext
- Körande uppgifter, såsom databasfrågor och anpassade AWS Lambda funktioner
- Hantera specialiserade samtal och användarförfrågningar
Vi visar fördelarna med AI-assistenter som använder Internet of Things (IoT) enhetshantering som exempel. I det här fallet kan AI hjälpa tekniker att hantera maskiner effektivt med kommandon som hämtar data eller automatiserar uppgifter, vilket effektiviserar tillverkningen.
Agenter för Amazon Bedrock-metoden
Agenter för Amazon Bedrock låter dig bygga generativa AI-applikationer som kan köra flerstegsuppgifter över ett företags system och datakällor. Den erbjuder följande nyckelfunktioner:
- Skapa automatiskt prompt från instruktioner, API-detaljer och information från datakällan, vilket sparar veckors snabba tekniska ansträngningar
- Retrieval Augmented Generation (RAG) för att säkert ansluta agenter till ett företags datakällor och ge relevanta svar
- Orkesterering och körning av flerstegsuppgifter genom att dela upp förfrågningar i logiska sekvenser och anropa nödvändiga API:er
- Synlighet i agentens resonemang genom en tankekedja (CoT), vilket möjliggör felsökning och styrning av modellbeteende
- Fråga tekniska förmågor för att modifiera den automatiskt genererade promptmallen för förbättrad kontroll över agenter
Du kan använda Agenter för Amazon Bedrock och Kunskapsbaser för Amazon Bedrock att bygga och distribuera AI-assistenter för komplexa routinganvändningsfall. De ger en strategisk fördel för utvecklare och organisationer genom att förenkla infrastrukturhanteringen, förbättra skalbarheten, förbättra säkerheten och minska odifferentierade tunga lyft. De möjliggör också enklare applikationslagerkod eftersom routningslogiken, vektoriseringen och minnet är helt hanterat.
Lösningsöversikt
Den här lösningen introducerar en AI-assistent för samtal som är skräddarsydd för IoT-enhetshantering och drift när man använder Anthropics Claude v2.1 på Amazon Bedrock. AI-assistentens kärnfunktioner styrs av en omfattande uppsättning instruktioner, känd som en systemuppmaning, som beskriver dess förmågor och expertområden. Denna vägledning ser till att AI-assistenten kan hantera ett brett utbud av uppgifter, från att hantera enhetsinformation till att köra operativa kommandon.
Utrustad med dessa funktioner, som beskrivs i systemuppmaningen, följer AI-assistenten ett strukturerat arbetsflöde för att hantera användarfrågor. Följande figur ger en visuell representation av detta arbetsflöde, som illustrerar varje steg från första användarinteraktion till det slutliga svaret.
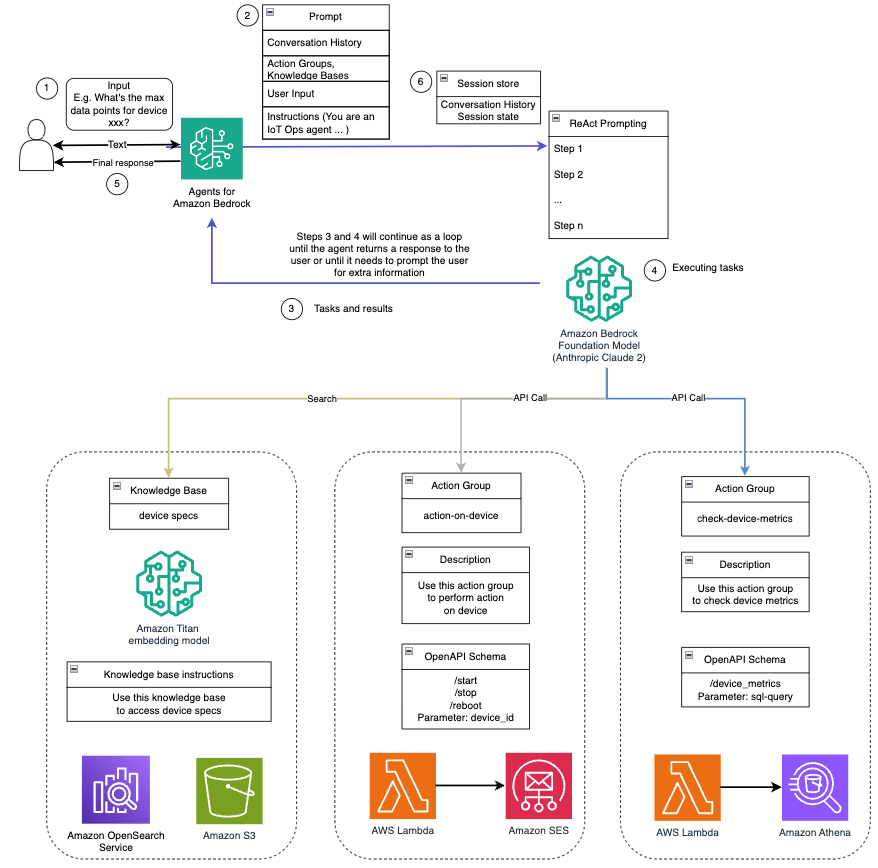
Arbetsflödet består av följande steg:
- Processen börjar när en användare ber assistenten att utföra en uppgift; till exempel att be om maximala datapunkter för en specifik IoT-enhet
device_xxx. Denna textinmatning fångas och skickas till AI-assistenten. - AI-assistenten tolkar användarens textinmatning. Den använder den tillhandahållna konversationshistoriken, åtgärdsgrupperna och kunskapsbaserna för att förstå sammanhanget och bestämma de nödvändiga uppgifterna.
- Efter att användarens avsikt har analyserats och förstått, definierar AI-assistenten uppgifter. Detta är baserat på instruktionerna som tolkas av assistenten enligt systemuppmaningen och användarens input.
- Uppgifterna körs sedan genom en serie API-anrop. Detta görs med hjälp av Reagera uppmaning, som delar upp uppgiften i en serie steg som bearbetas sekventiellt:
- För kontroll av enhetsstatistik använder vi
check-device-metricsaction group, som involverar ett API-anrop till Lambda-funktioner som sedan frågar Amazonas Athena för de begärda uppgifterna. - För direkta enhetsåtgärder som start, stopp eller omstart använder vi
action-on-deviceaktionsgrupp, som åberopar en lambdafunktion. Denna funktion initierar en process som skickar kommandon till IoT-enheten. För det här inlägget skickar Lambda-funktionen aviseringar med hjälp av Amazons enkla e -posttjänst (Amazon SES). - Vi använder kunskapsbaser för Amazon Bedrock för att hämta från historiska data lagrade som inbäddningar i Amazon OpenSearch Service vektor databas.
- För kontroll av enhetsstatistik använder vi
- När uppgifterna är klara genereras det slutliga svaret av Amazon Bedrock FM och skickas tillbaka till användaren.
- Agenter för Amazon Bedrock lagrar automatiskt information med hjälp av en tillståndsgivande session för att upprätthålla samma konversation. Tillståndet raderas efter att en konfigurerbar inaktiv timeout har förflutit.
Teknisk översikt
Följande diagram illustrerar arkitekturen för att distribuera en AI-assistent med Agents for Amazon Bedrock.
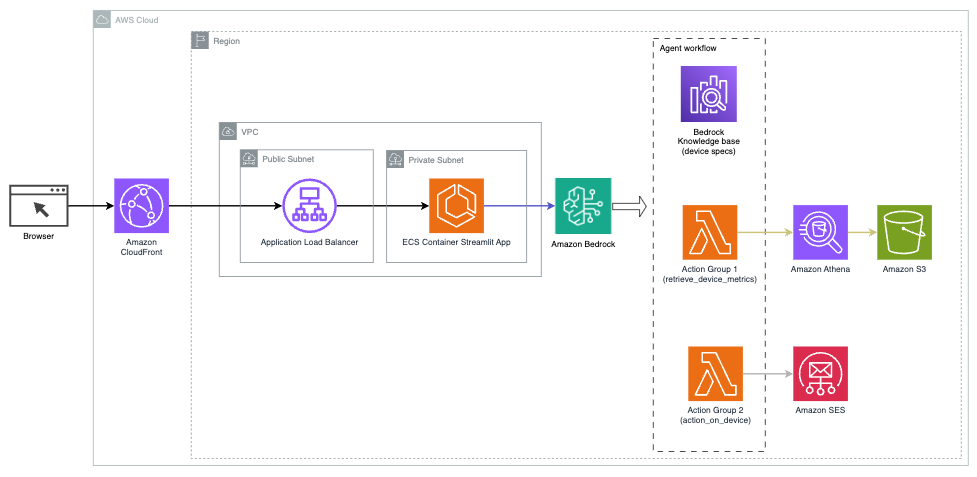
Den består av följande nyckelkomponenter:
- Konversationsgränssnitt – Konversationsgränssnittet använder Streamlit, ett Python-bibliotek med öppen källkod som förenklar skapandet av anpassade, visuellt tilltalande webbappar för maskininlärning (ML) och datavetenskap. Den är värd på Amazon Elastic Container Service (Amazon ECS) med AWS Fargate, och den nås med en Application Load Balancer. Du kan använda Fargate med Amazon ECS för att köra behållare utan att behöva hantera servrar, kluster eller virtuella maskiner.
- Agenter för Amazon Bedrock – Agenter för Amazon Bedrock slutför användarfrågorna genom en serie resonemangssteg och motsvarande åtgärder baserat på Reagera uppmaning:
- Kunskapsbaser för Amazon Bedrock – Kunskapsbaser för Amazon Bedrock tillhandahåller helt hanterade RAG för att ge AI-assistenten åtkomst till dina data. I vårt användningsfall laddade vi upp enhetsspecifikationer till en Amazon enkel lagringstjänst (Amazon S3) hink. Den fungerar som datakällan till kunskapsbasen.
- Aktionsgrupper – Dessa är definierade API-scheman som anropar specifika Lambda-funktioner för att interagera med IoT-enheter och andra AWS-tjänster.
- Antropisk Claude v2.1 på Amazon Bedrock – Den här modellen tolkar användarfrågor och orkestrerar flödet av uppgifter.
- Amazon Titan-inbäddningar – Den här modellen fungerar som en textinbäddningsmodell som omvandlar text på naturligt språk – från enstaka ord till komplexa dokument – till numeriska vektorer. Detta möjliggör vektorsökningsmöjligheter, vilket gör det möjligt för systemet att semantiskt matcha användarfrågor med de mest relevanta kunskapsbasposterna för effektiv sökning.
Lösningen är integrerad med AWS-tjänster som Lambda för att köra kod som svar på API-anrop, Athena för att fråga datauppsättningar, OpenSearch Service för att söka igenom kunskapsbaser och Amazon S3 för lagring. Dessa tjänster samarbetar för att ge en sömlös upplevelse för IoT-enhetshantering genom naturliga språkkommandon.
Fördelar
Denna lösning erbjuder följande fördelar:
- Implementeringskomplexitet:
- Färre rader kod krävs, eftersom Agents for Amazon Bedrock abstraherar bort mycket av den underliggande komplexiteten, vilket minskar utvecklingsarbetet
- Hantera vektordatabaser som OpenSearch Service är förenklat, eftersom kunskapsbaser för Amazon Bedrock hanterar vektorisering och lagring
- Integration med olika AWS-tjänster är mer strömlinjeformad genom fördefinierade åtgärdsgrupper
- Utvecklarerfarenhet:
- Amazon Bedrock-konsolen ger ett användarvänligt gränssnitt för snabb utveckling, testning och rotorsaksanalys (RCA), vilket förbättrar den övergripande utvecklarupplevelsen
- Smidighet och flexibilitet:
- Agenter för Amazon Bedrock möjliggör sömlösa uppgraderingar till nyare FM:er (som Claude 3.0) när de blir tillgängliga, så att din lösning håller sig uppdaterad med de senaste framstegen
- Tjänstekvoter och begränsningar hanteras av AWS, vilket minskar kostnaderna för övervakning och skalning av infrastruktur
- Säkerhet:
- Amazon Bedrock är en fullständigt hanterad tjänst som följer AWS:s stränga säkerhets- och efterlevnadsstandarder, vilket potentiellt förenklar organisatoriska säkerhetsgranskningar
Även om Agents for Amazon Bedrock erbjuder en strömlinjeformad och hanterad lösning för att bygga konversationsbaserade AI-applikationer, kanske vissa organisationer föredrar ett tillvägagångssätt med öppen källkod. I sådana fall kan du använda ramverk som LangChain, som vi diskuterar i nästa avsnitt.
LangChain dynamisk routing tillvägagångssätt
LangChain är ett ramverk med öppen källkod som förenklar byggandet av konversations-AI genom att tillåta integration av stora språkmodeller (LLM) och dynamiska routingfunktioner. Med LangChain Expression Language (LCEL) kan utvecklare definiera routing, som låter dig skapa icke-deterministiska kedjor där resultatet från ett tidigare steg definierar nästa steg. Routing hjälper till att ge struktur och konsekvens i interaktioner med LLM:er.
För det här inlägget använder vi samma exempel som AI-assistenten för IoT-enhetshantering. Den största skillnaden är dock att vi måste hantera systemuppmaningarna separat och behandla varje kedja som en separat enhet. Routingkedjan bestämmer destinationskedjan baserat på användarens input. Beslutet fattas med stöd av en LLM genom att skicka systemprompten, chatthistoriken och användarens fråga.
Lösningsöversikt
Följande diagram illustrerar arbetsflödet för dynamisk routinglösning.
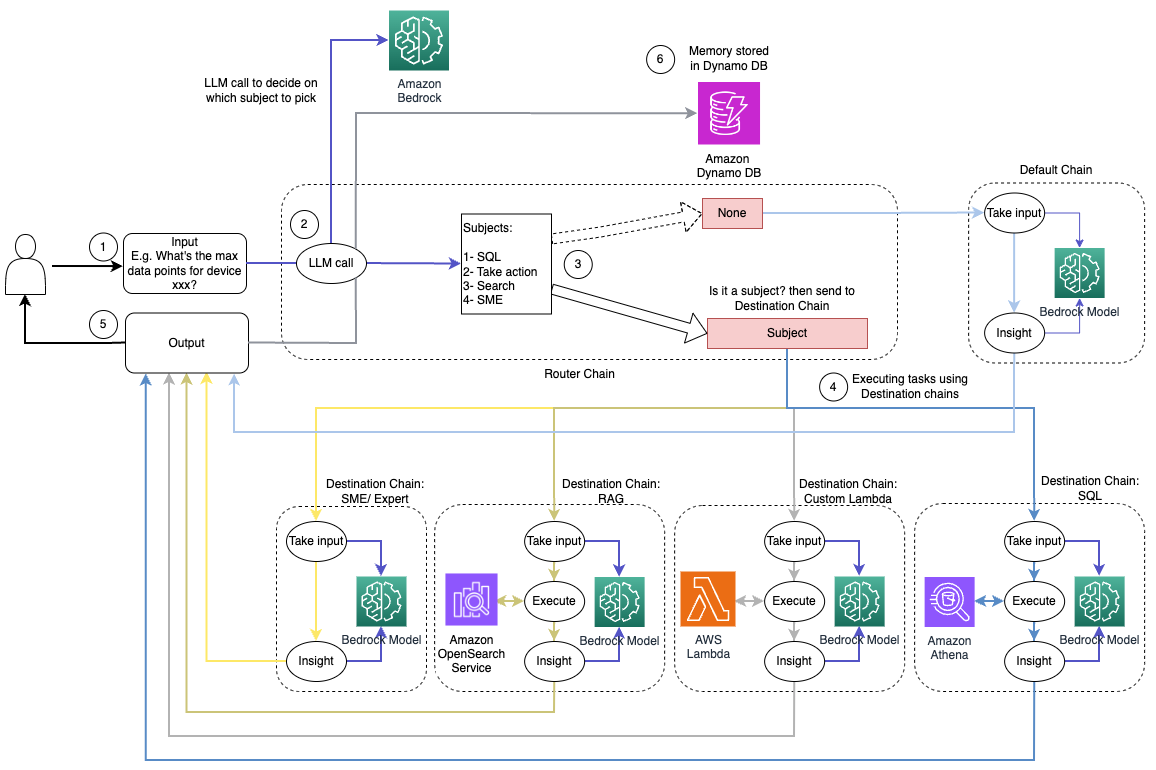
Arbetsflödet består av följande steg:
- Användaren ställer en fråga till AI-assistenten. Till exempel, "Vilka är maxvärdena för enhet 1009?"
- En LLM utvärderar varje fråga tillsammans med chatthistoriken från samma session för att bestämma dess karaktär och vilket ämnesområde den faller under (som SQL, action, sökning eller SME). LLM klassificerar ingången och LCEL-dirigeringskedjan tar den ingången.
- Routerkedjan väljer destinationskedjan baserat på indata, och LLM är försedd med följande systemprompt:
LLM utvärderar användarens fråga tillsammans med chatthistoriken för att bestämma frågans karaktär och vilket ämnesområde den faller under. LLM klassificerar sedan ingången och matar ut ett JSON-svar i följande format:
Routerkedjan använder detta JSON-svar för att anropa motsvarande destinationskedja. Det finns fyra ämnesspecifika destinationskedjor, var och en med sin egen systemprompt:
- SQL-relaterade frågor skickas till SQL-destinationskedjan för databasinteraktioner. Du kan använda LCEL för att bygga SQL-kedja.
- Handlingsorienterade frågor åberopar den anpassade Lambda-destinationskedjan för att köra operationer. Med LCEL kan du definiera din egen anpassad funktion; i vårt fall är det en funktion att köra en fördefinierad Lambda-funktion för att skicka ett e-postmeddelande med ett enhets-ID tolkat. Exempel på användarinmatning kan vara "Stäng av enhet 1009."
- Sökfokuserade förfrågningar fortsätter till RAG destinationskedja för informationssökning.
- SME-relaterade frågor går till SME/expertdestinationskedjan för specialiserade insikter.
- Varje destinationskedja tar input och kör de nödvändiga modellerna eller funktionerna:
- SQL-kedjan använder Athena för att köra frågor.
- RAG-kedjan använder OpenSearch Service för semantisk sökning.
- Den anpassade Lambdakedjan kör Lambdafunktioner för åtgärder.
- SME/expertkedjan ger insikter med hjälp av Amazon Bedrock-modellen.
- Svar från varje destinationskedja formuleras till sammanhängande insikter av LLM. Dessa insikter levereras sedan till användaren och slutför frågecykeln.
- Användarinput och svar lagras i Amazon DynamoDB för att ge sammanhang till LLM för den aktuella sessionen och från tidigare interaktioner. Varaktigheten av bevarad information i DynamoDB styrs av applikationen.
Teknisk översikt
Följande diagram illustrerar arkitekturen för LangChains dynamiska routinglösning.

Webbapplikationen är byggd på Streamlit värd på Amazon ECS med Fargate, och den nås med en Application Load Balancer. Vi använder Anthropics Claude v2.1 på Amazon Bedrock som vår LLM. Webbapplikationen interagerar med modellen med hjälp av LangChain-bibliotek. Den interagerar också med en mängd andra AWS-tjänster, såsom OpenSearch Service, Athena och DynamoDB för att uppfylla slutanvändarnas behov.
Fördelar
Denna lösning erbjuder följande fördelar:
- Implementeringskomplexitet:
- Även om det kräver mer kod och anpassad utveckling, ger LangChain större flexibilitet och kontroll över routinglogiken och integration med olika komponenter.
- Att hantera vektordatabaser som OpenSearch Service kräver ytterligare installations- och konfigurationsinsatser. Vektoriseringsprocessen implementeras i kod.
- Integrering med AWS-tjänster kan innebära mer anpassad kod och konfiguration.
- Utvecklarerfarenhet:
- LangChains Python-baserade tillvägagångssätt och omfattande dokumentation kan vara tilltalande för utvecklare som redan är bekanta med Python och verktyg med öppen källkod.
- Snabb utveckling och felsökning kan kräva mer manuell ansträngning jämfört med att använda Amazon Bedrock-konsolen.
- Smidighet och flexibilitet:
- LangChain stöder ett brett utbud av LLM, så att du kan växla mellan olika modeller eller leverantörer, vilket främjar flexibilitet.
- Den öppna källkoden hos LangChain möjliggör community-drivna förbättringar och anpassningar.
- Säkerhet:
- Som ett ramverk med öppen källkod kan LangChain kräva mer rigorösa säkerhetsgranskningar och granskning inom organisationer, vilket eventuellt kan lägga till overhead.
Slutsats
Conversational AI-assistenter är transformativa verktyg för att effektivisera verksamheten och förbättra användarupplevelsen. Det här inlägget utforskade två kraftfulla tillvägagångssätt med hjälp av AWS-tjänster: de hanterade agenterna för Amazon Bedrock och den flexibla, öppen källkod LangChain dynamisk routing. Valet mellan dessa tillvägagångssätt beror på din organisations krav, utvecklingspreferenser och önskad nivå av anpassning. Oavsett vilken väg du tar, ger AWS dig möjlighet att skapa intelligenta AI-assistenter som revolutionerar affärs- och kundinteraktioner
Hitta lösningskoden och distributionstillgångarna i vår GitHub repository, där du kan följa de detaljerade stegen för varje AI-konversationsmetod.
Om författarna
 Ameer Hakme är en AWS Solutions Architect baserad i Pennsylvania. Han samarbetar med Independent Software Vendors (ISVs) i nordöstra regionen, och hjälper dem att designa och bygga skalbara och moderna plattformar på AWS Cloud. Ameer är expert på AI/ML och generativ AI och hjälper kunder att frigöra potentialen hos dessa banbrytande teknologier. På fritiden tycker han om att köra motorcykel och tillbringa kvalitetstid med familjen.
Ameer Hakme är en AWS Solutions Architect baserad i Pennsylvania. Han samarbetar med Independent Software Vendors (ISVs) i nordöstra regionen, och hjälper dem att designa och bygga skalbara och moderna plattformar på AWS Cloud. Ameer är expert på AI/ML och generativ AI och hjälper kunder att frigöra potentialen hos dessa banbrytande teknologier. På fritiden tycker han om att köra motorcykel och tillbringa kvalitetstid med familjen.
 Sharon Lic är en AI/ML Solutions Architect på Amazon Web Services baserad i Boston, med en passion för att designa och bygga generativa AI-applikationer på AWS. Hon samarbetar med kunder för att utnyttja AWS AI/ML-tjänster för innovativa lösningar.
Sharon Lic är en AI/ML Solutions Architect på Amazon Web Services baserad i Boston, med en passion för att designa och bygga generativa AI-applikationer på AWS. Hon samarbetar med kunder för att utnyttja AWS AI/ML-tjänster för innovativa lösningar.
 Kawsar Kamal är en senior lösningsarkitekt på Amazon Web Services med över 15 års erfarenhet av infrastrukturautomation och säkerhetsområdet. Han hjälper kunder att designa och bygga skalbara DevSecOps och AI/ML-lösningar i molnet.
Kawsar Kamal är en senior lösningsarkitekt på Amazon Web Services med över 15 års erfarenhet av infrastrukturautomation och säkerhetsområdet. Han hjälper kunder att designa och bygga skalbara DevSecOps och AI/ML-lösningar i molnet.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/