
Från och med version 6.14, Amazon EMR Studio stöder interaktiv analys på Amazon EMR-serverlös. Du kan nu använda EMR-serverlösa applikationer som beräkning, förutom Amazon EMR på EC2-kluster och Amazon EMR på EKS virtuella kluster för att köra JupyterLab-anteckningsböcker från EMR Studio Workspaces.
EMR Studio är en integrerad utvecklingsmiljö (IDE) som gör det enkelt för datavetare och dataingenjörer att utveckla, visualisera och felsöka analysapplikationer skrivna i PySpark, Python och Scala. EMR Serverless är ett serverlöst alternativ för Amazon EMR som gör det enkelt att köra ramverk för stordataanalys med öppen källkod som Apache Spark utan att konfigurera, hantera och skala kluster eller servrar.
I inlägget visar vi hur man gör följande:
- Skapa en EMR-serverlös slutpunkt för interaktiva applikationer
- Koppla slutpunkten till en befintlig EMR Studio-miljö
- Skapa en anteckningsbok och kör en interaktiv applikation
- Sömlöst diagnostisera interaktiva applikationer från EMR Studio
Förutsättningar
I en typisk organisation kommer en AWS-kontoadministratör att ställa in AWS-resurser som t.ex AWS identitets- och åtkomsthantering (IAM) roller, Amazon enkel lagringstjänst (Amazon S3) hinkar, och Amazon Virtual Private Cloud (Amazon VPC) resurser för internetåtkomst och åtkomst till andra resurser i VPC. De tilldelar EMR Studio-administratörer som hanterar installationen av EMR Studios och tilldelar användare till en specifik EMR Studio. När de är tilldelade kan EMR Studio-utvecklare använda EMR Studio för att utveckla och övervaka arbetsbelastningar.
Se till att du ställer in resurser som din S3-bucket, VPC-undernät och EMR Studio i samma AWS-region.
Utför följande steg för att distribuera dessa förutsättningar:
- Starta följande AWS molnformation stack.

- Ange värden för Admin lösenord och DevPassword och anteckna lösenorden du skapar.
- Välja Nästa.
- Behåll inställningarna som standard och välj Nästa igen.
- Välja Jag erkänner att AWS CloudFormation kan skapa IAM-resurser med anpassade namn.
- Välj Skicka.
Vi har också tillhandahållit instruktioner för att distribuera dessa resurser manuellt med exempel på IAM-policyer i GitHub repo.
Konfigurera EMR Studio och en serverlös interaktiv applikation
Efter att AWS-kontoadministratören har slutfört förutsättningarna kan EMR Studio-administratören logga in på AWS Management Console för att skapa en EMR Studio, Workspace och EMR Serverless-applikation.
Skapa en EMR-studio och arbetsyta
EMR Studio-administratören bör logga in på konsolen med hjälp av emrs-interactive-app-admin-user användaruppgifter. Om du distribuerade de nödvändiga resurserna med hjälp av den medföljande CloudFormation-mallen, använd lösenordet som du angav som indataparameter.
- Välj på Amazon EMR -konsol EMR-serverlös i navigeringsfönstret.

- Välja KOM IGÅNG.
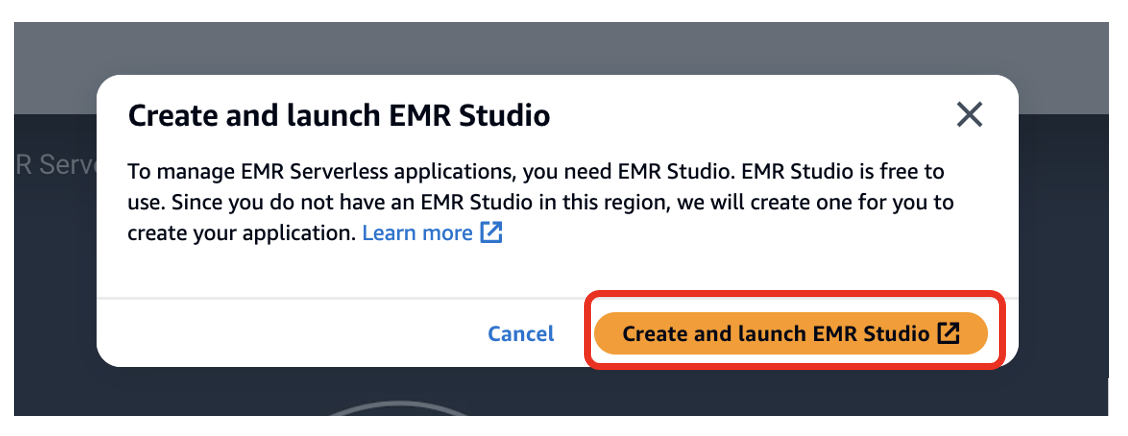
- Välja Skapa och starta EMR Studio.
Detta skapar en Studio med standardnamnet studio_1 och en arbetsyta med standardnamnet My_First_Workspace. En ny webbläsarflik öppnas för Studio_1 användargränssnitt.
Skapa en EMR-serverlös applikation
Utför följande steg för att skapa en EMR-serverlös applikation:
- Välj på EMR Studio-konsolen Applikationer i navigeringsfönstret.
- Skapa en ny applikation.
- För Namn , ange ett namn (t.ex.
my-serverless-interactive-application). - För Alternativ för programinställningar, Välj Använd anpassade inställningar för interaktiva arbetsbelastningar.
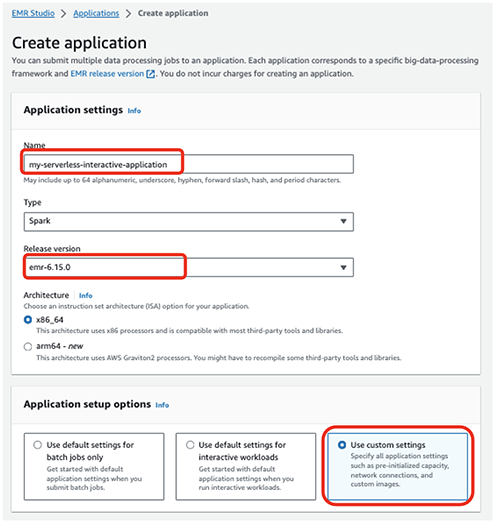
För interaktiva applikationer rekommenderar vi som en bästa praxis att hålla föraren och arbetarna förinitierade genom att konfigurera förinitierad kapacitet vid tidpunkten för skapandet av ansökan. Detta skapar effektivt en varm pool av arbetare för en applikation och håller resurserna redo att förbrukas, vilket gör att applikationen kan svara på några sekunder. För ytterligare bästa praxis för att skapa EMR-serverlösa applikationer, se Definiera resursgränser per team för big data-arbetsbelastningar med Amazon EMR Serverless.
- I Interaktiv slutpunkt avsnitt, välj Aktivera interaktiv slutpunkt.
- I Nätverkskopplingar väljer du VPC, privata undernät och säkerhetsgrupp som du skapade tidigare.
Om du distribuerade CloudFormation-stacken som tillhandahålls i det här inlägget, välj emr-serverless-sg som säkerhetsgrupp.
En VPC behövs för att arbetsbelastningen ska kunna komma åt internet från EMR Serverless-applikationen för att ladda ner externa Python-paket. VPC:n låter dig också komma åt resurser som t.ex Amazon Relational Databas Service (Amazon RDS) och Amazon RedShift som finns i VPC från denna applikation. Att koppla en serverlös applikation till en VPC kan leda till IP-utmattning i subnätet, så se till att det finns tillräckligt med IP-adresser i ditt subnät.
- Välja Skapa och starta applikation.

På applikationssidan kan du verifiera att statusen för din serverlösa applikation ändras till Satte igång.
- Välj din applikation och välj Hur det fungerar.
- Välja Visa och starta arbetsytor.
- Välja Konfigurera studio.

- För Serviceroll¸ tillhandahåll den EMR Studio-tjänstroll du skapade som en förutsättning (
emr-studio-service-role). - För Arbetsyta förvaring, ange sökvägen för S3-skopan du skapade som en förutsättning (
emrserverless-interactive-blog-<account-id>-<region-name>). - Välja Spara ändringar.
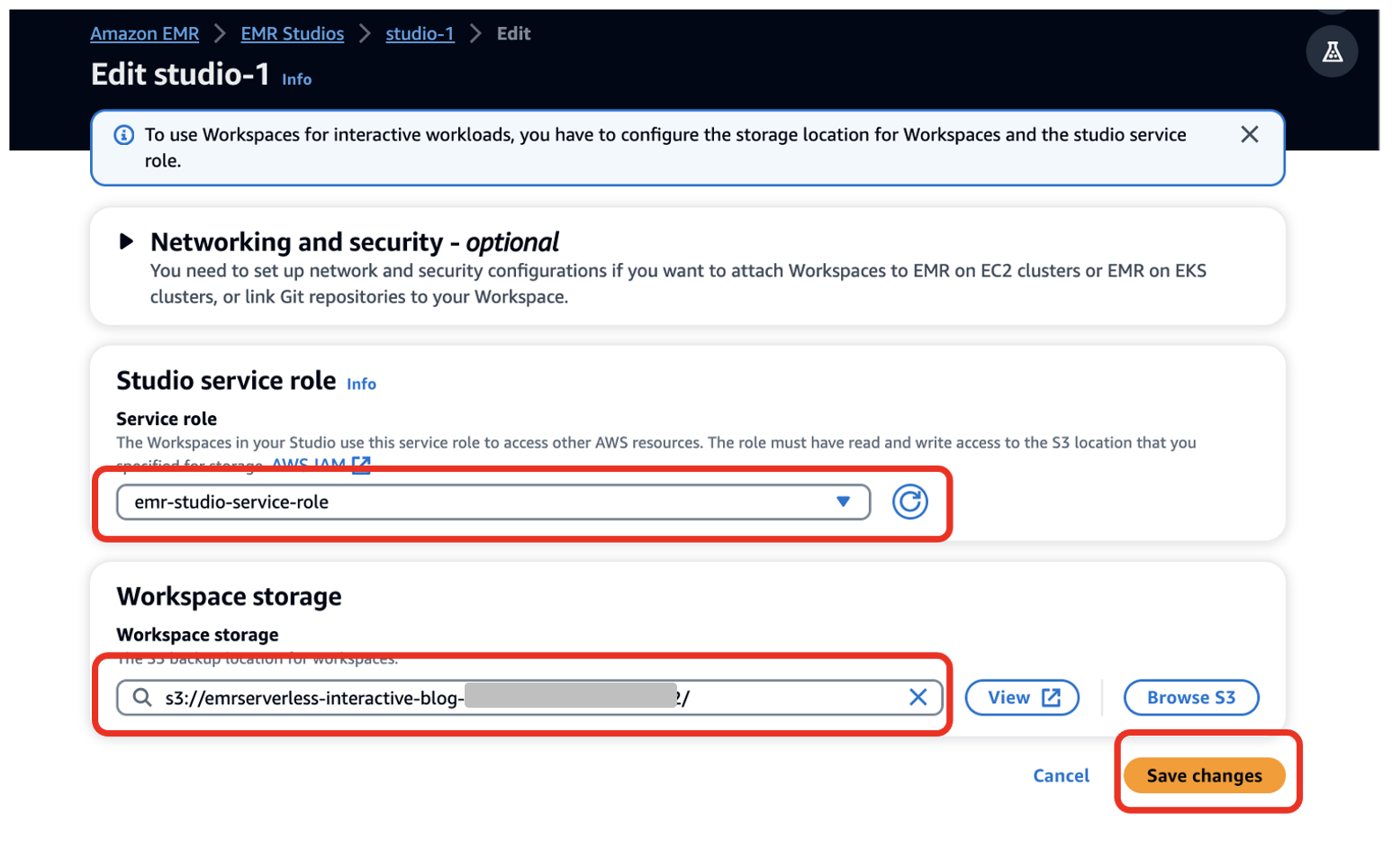
14. Navigera till Studios-konsolen genom att välja Studios i den vänstra navigeringsmenyn i EMR Studio sektion. Notera Studio-åtkomst-URL från Studios-konsolen och ge den till dina utvecklare för att köra deras Spark-applikationer.
Kör din första Spark-applikation
Efter att EMR Studio-administratören har skapat Studio-, Workspace- och serverlösa applikationer kan Studio-användaren använda Workspace och applikationen för att utveckla och övervaka Spark-arbetsbelastningar.
Starta arbetsytan och anslut den serverlösa applikationen
Följ följande steg:
- Använd Studio-URL som tillhandahålls av EMR Studio-administratören och logga in med hjälp av
emrs-interactive-app-dev-useranvändaruppgifter som delas av AWS-kontoadministratören.
Om du distribuerade de nödvändiga resurserna med hjälp av den medföljande CloudFormation-mallen, använd lösenordet som du angav som en indataparameter.
På arbetsytor sida kan du kontrollera statusen för din arbetsyta. När arbetsytan startas kommer du att se statusändringen till Redo.
- Starta arbetsytan genom att välja arbetsytans namn (
My_First_Workspace).
Detta öppnar en ny flik. Se till att din webbläsare tillåter popup-fönster.
- Välj i arbetsytan Compute (klusterikon) i navigeringsfönstret.
- För EMR Serverlös applikation, välj din ansökan (
my-serverless-interactive-application). - För Interaktiv körtidsroll, välj en interaktiv körtidsroll (för det här inlägget använder vi
emr-serverless-runtime-role). - Välja Bifoga för att bifoga det serverlösa programmet som beräkningstyp för alla anteckningsböcker i denna arbetsyta.

Kör din Spark-applikation interaktivt
Följ följande steg:
- Välj Exempel på anteckningsbok (ikon med tre punkter) i navigeringsfönstret och öppna
Getting-started-with-emr-serverlessanteckningsbok. - Välja Spara i Workspace.
Det finns tre val av kärnor för vår anteckningsbok: Python 3, PySpark och Spark (för Scala).
- När du uppmanas väljer du PySpark som kärnan.
- Välja Välja.

Nu kan du köra din Spark-applikation. För att göra det, använd %%configure Sparkmagic kommando, som konfigurerar parametrarna för skapande av sessioner. Interaktiva applikationer stöder virtuella Python-miljöer. Vi använder en anpassad miljö i arbetarnoderna genom att ange en sökväg för en annan Python-körtid för exekveringsmiljön med spark.executorEnv.PYSPARK_PYTHON. Se följande kod:
Installera externa paket
Nu när du har en oberoende virtuell miljö för arbetarna, låter EMR Studios bärbara datorer dig installera externa paket från den serverlösa applikationen genom att använda Spark install_pypi_package fungera genom Spark-kontexten. Genom att använda den här funktionen blir paketet tillgängligt för alla EMR-serverlösa arbetare.
Installera först matplotlib, ett Python-paket, från PyPi:
Om det föregående steget inte svarar, kontrollera din VPC-installation och se till att den är korrekt konfigurerad för internetåtkomst.
Nu kan du använda en datauppsättning och visualisera dina data.
Skapa visualiseringar
För att skapa visualiseringar använder vi en offentlig datauppsättning på NYC gula taxibilar:
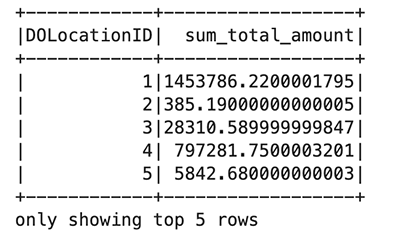
I föregående kodblock läser du Parkettfilen från en offentlig hink i Amazon S3. Filen har rubriker och vi vill att Spark ska härleda schemat. Du använder sedan en Spark-dataram för att gruppera och räkna specifika kolumner från taxi_df:
Använda %%display magiskt att se resultatet i tabellformat:

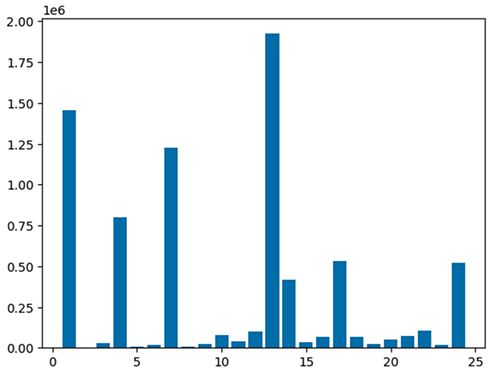
Du kan också snabbt visualisera dina data med fem typer av diagram. Du kan välja visningstyp och diagrammet ändras därefter. I följande skärmdump använder vi ett stapeldiagram för att visualisera våra data.

Interagera med EMR Serverless med Spark SQL
Du kan interagera med tabeller i AWS limdatakatalog använder Spark SQL på EMR Serverless. I exempelanteckningsboken visar vi hur du kan transformera data med en Spark-dataram.
Skapa först en ny tillfällig vy som kallas taxis. Detta gör att du kan använda Spark SQL för att välja data från den här vyn. Skapa sedan en taxidataram för vidare bearbetning:
I varje cell i din EMR Studio-anteckningsbok kan du expandera Spark Job Framsteg för att se de olika stadierna av jobbet som skickats till EMR Serverless medan du kör den här specifika cellen. Du kan se hur lång tid det tar att slutföra varje steg. I följande exempel har steg 14 av jobbet 12 slutförda uppgifter. Dessutom, om det finns något fel, kan du se loggarna, vilket gör felsökningen till en sömlös upplevelse. Vi diskuterar detta mer i nästa avsnitt.
![Job[14]: showString på NativeMethodAccessorImpl.java:0 och Job[15]: showString på NativeMethodAccessorImpl.java:0](https://xlera8.com/wp-content/uploads/2024/04/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio-amazon-web-services-11.png)
Använd följande kod för att visualisera den bearbetade dataramen med matplotlib-paketet. Du använder maptplotlib-biblioteket för att plotta avlämningsplatsen och den totala mängden som ett stapeldiagram.
Diagnostisera interaktiva applikationer
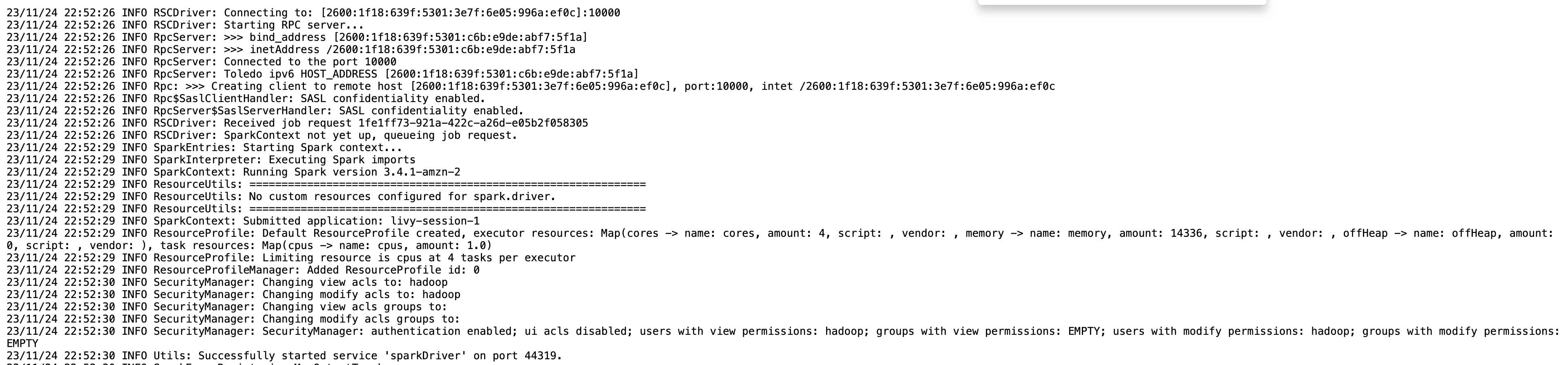
Du kan få sessionsinformationen för din Livy-ändpunkt med hjälp av %%info Sparkmagic. Detta ger dig länkar för att komma åt Spark UI samt drivrutinsloggen direkt i din bärbara dator.

Följande skärmdump är ett utdrag för drivrutinslogg för vår applikation, som vi öppnade via länken i vår anteckningsbok.
På samma sätt kan du välja länken nedan Spark UI för att öppna användargränssnittet. Följande skärmdump visar testamentsexekutorer fliken, som ger åtkomst till drivrutins- och exekveringsloggarna.

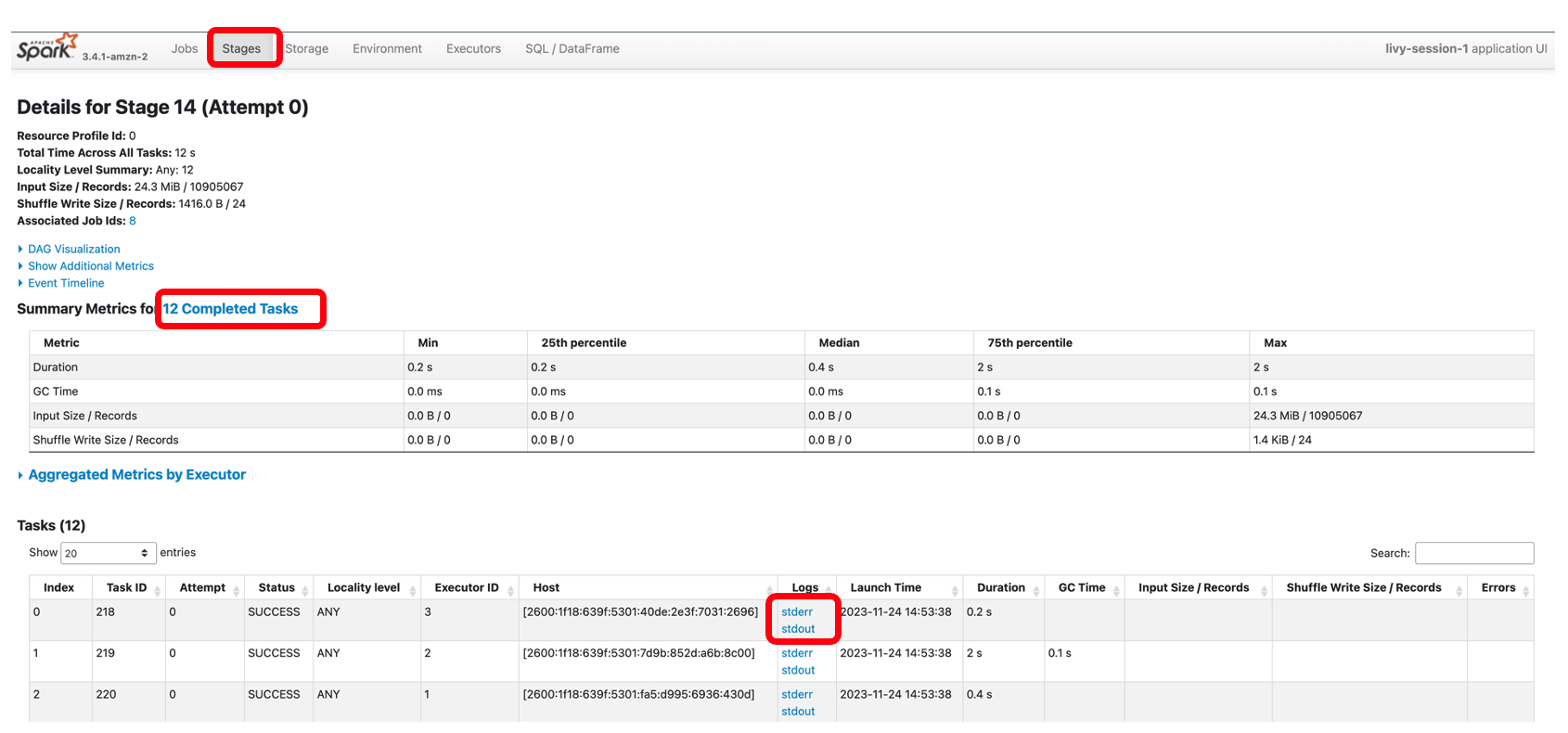
Följande skärmdump visar steg 14, vilket motsvarar Spark SQL-steget vi såg tidigare där vi beräknade den platsmässiga summan av totala taxiinsamlingar, som hade delats upp i 12 uppgifter. Genom Spark-gränssnittet ger den interaktiva applikationen finkornig status på uppgiftsnivå, I/O och blandningsdetaljer, samt länkar till motsvarande loggar för varje uppgift för detta steg direkt från din bärbara dator, vilket möjliggör en sömlös felsökningsupplevelse.
Städa upp
Om du inte längre vill behålla resurserna som skapats i det här inlägget, slutför du följande rensningssteg:
- Ta bort programmet EMR Serverless.
- Ta bort EMR Studio och tillhörande arbetsytor och anteckningsböcker.
- För att ta bort resten av resurserna, navigera till CloudFormation-konsolen, välj stacken och välj Radera.
Alla resurser kommer att raderas utom S3-bucket, som har sin borttagningspolicy inställd på att behålla.
Slutsats
Inlägget visade hur man kör interaktiva PySpark-arbetsbelastningar i EMR Studio med EMR Serverless som dator. Du kan också bygga och övervaka Spark-applikationer i en interaktiv JupyterLab Workspace.
I ett kommande inlägg kommer vi att diskutera ytterligare funktioner hos EMR Serverless Interactive-applikationer, som:
- Arbeta med resurser som Amazon RDS och Amazon Redshift i din VPC (till exempel för JDBC/ODBC-anslutning)
- Kör transaktionella arbetsbelastningar med serverlösa slutpunkter
Om det här är första gången du utforskar EMR Studio rekommenderar vi att du kollar in Amazon EMR workshops och hänvisar till Skapa en EMR-studio.
Om författarna
 Sekar Srinivasan är en Principal Specialist Solutions Architect på AWS med fokus på Data Analytics och AI. Sekar har över 20 års erfarenhet av att arbeta med data. Han brinner för att hjälpa kunder att bygga skalbara lösningar som moderniserar sin arkitektur och genererar insikter från deras data. På fritiden gillar han att arbeta med ideella projekt, inriktade på underprivilegierade barns utbildning.
Sekar Srinivasan är en Principal Specialist Solutions Architect på AWS med fokus på Data Analytics och AI. Sekar har över 20 års erfarenhet av att arbeta med data. Han brinner för att hjälpa kunder att bygga skalbara lösningar som moderniserar sin arkitektur och genererar insikter från deras data. På fritiden gillar han att arbeta med ideella projekt, inriktade på underprivilegierade barns utbildning.
 Disha Umarwani är en Sr. Data Architect med Amazon Professional Services inom Global Health Care och LifeSciences. Hon har arbetat med kunder för att designa, designa och implementera Data Strategy i stor skala. Hon är specialiserad på arkitektur av Data Mesh-arkitekturer för Enterprise-plattformar.
Disha Umarwani är en Sr. Data Architect med Amazon Professional Services inom Global Health Care och LifeSciences. Hon har arbetat med kunder för att designa, designa och implementera Data Strategy i stor skala. Hon är specialiserad på arkitektur av Data Mesh-arkitekturer för Enterprise-plattformar.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio/