
Du kan nu träna om maskininlärningsmodeller (ML) och automatisera batchförutsägelsearbetsflöden med uppdaterade datauppsättningar i Amazon SageMaker Canvas, vilket gör det lättare att ständigt lära sig och förbättra modellens prestanda och köreffektivitet. En ML-modells effektivitet beror på kvaliteten och relevansen av den data som den tränas på. Allt eftersom tiden går kan de underliggande mönstren, trenderna och fördelningarna i data ändras. Genom att uppdatera datasetet säkerställer du att modellen lär sig av de senaste och representativa data, och förbättrar därmed dess förmåga att göra korrekta förutsägelser. Canvas stöder nu uppdatering av datamängder automatiskt och manuellt, vilket gör att du kan använda den senaste versionen av tabell-, bild- och dokumentdatauppsättningen för att träna ML-modeller.
Efter att modellen har tränats kanske du vill köra förutsägelser på den. Att köra batchförutsägelser på en ML-modell gör det möjligt att bearbeta flera datapunkter samtidigt istället för att göra förutsägelser en efter en. Att automatisera denna process ger effektivitet, skalbarhet och beslutsfattande i rätt tid. Efter att förutsägelserna har genererats kan de analyseras, aggregeras eller visualiseras ytterligare för att få insikter, identifiera mönster eller fatta välgrundade beslut baserat på de förutspådda utfallen. Canvas stöder nu att konfigurera en automatisk batchförutsägelsekonfiguration och associera en datauppsättning till den. När den associerade datamängden uppdateras, antingen manuellt eller enligt ett schema, kommer ett batchförutsägande arbetsflöde att utlösas automatiskt på motsvarande modell. Resultaten av förutsägelserna kan ses direkt eller laddas ner för senare granskning.
I det här inlägget visar vi hur man tränar om ML-modeller och automatiserar batchförutsägelser med hjälp av uppdaterade datauppsättningar i Canvas.
Översikt över lösningen
För vårt användningsfall spelar vi rollen som affärsanalytiker för ett e-handelsföretag. Vårt produktteam vill att vi ska fastställa de mest kritiska mätvärdena som påverkar en shoppers köpbeslut. För detta tränar vi en ML-modell i Canvas med en kundwebbplats online sessionsdataset från företaget. Vi utvärderar modellens prestanda och vid behov tränar vi om modellen med ytterligare data för att se om den förbättrar prestandan för den befintliga modellen eller inte. För att göra det använder vi funktionen för automatisk uppdatering av dataset i Canvas och tränar om vår befintliga ML-modell med den senaste versionen av träningsdatauppsättningen. Sedan konfigurerar vi automatiska batchförutsägelsearbetsflöden – när motsvarande förutsägelsedatauppsättning uppdateras utlöser den automatiskt batchförutsägelsejobbet på modellen och gör resultaten tillgängliga för oss att granska.
Arbetsflödesstegen är följande:
- Ladda upp den nedladdade kundwebbplatsens online sessionsdata till Amazon enkel lagringstjänst (Amazon S3) och skapa ett nytt träningsdataset Canvas. För den fullständiga listan över datakällor som stöds, se Importera data i Amazon SageMaker Canvas.
- Bygg ML-modeller och analysera deras prestationsmått. Se stegen för hur du gör bygga en anpassad ML-modell i Canvas och utvärdera en modells prestanda.
- Ställ in automatisk uppdatering av den befintliga träningsdatauppsättningen och ladda upp ny data till Amazon S3-platsen som stödjer denna datauppsättning. När den är klar bör den skapa en ny datauppsättningsversion.
- Använd den senaste versionen av datamängden för att träna om ML-modellen och analysera dess prestanda.
- Montera myggnät för luckor automatiska batch-förutsägelser på den bättre presterande modellversionen och se förutsägelseresultaten.
Du kan utföra dessa steg i Canvas utan att skriva en enda rad kod.
Översikt över data
Datauppsättningen består av funktionsvektorer som tillhör 12,330 1 sessioner. Datauppsättningen utformades så att varje session skulle tillhöra en annan användare under en XNUMX-årsperiod för att undvika alla tendenser till en specifik kampanj, speciell dag, användarprofil eller period. Följande tabell beskriver dataschemat.
| Kolumnnamn | Data typ | Beskrivning |
Administrative |
Numerisk | Antal sidor som användaren besökt för hantering av användarkonton. |
Administrative_Duration |
Numerisk | Mängden tid som spenderas i denna kategori av sidor. |
Informational |
Numerisk | Antal sidor av denna typ (information) som användaren besökte. |
Informational_Duration |
Numerisk | Mängden tid som spenderas i denna kategori av sidor. |
ProductRelated |
Numerisk | Antal sidor av denna typ (produktrelaterade) som användaren besökte. |
ProductRelated_Duration |
Numerisk | Mängden tid som spenderas i denna kategori av sidor. |
BounceRates |
Numerisk | Andel av besökare som går in på webbplatsen via den sidan och avslutar utan att utlösa några ytterligare uppgifter. |
ExitRates |
Numerisk | Genomsnittlig utgångsfrekvens för de sidor som användaren besöker. Det här är andelen personer som lämnade din webbplats från den sidan. |
Page Values |
Numerisk | Genomsnittligt sidvärde för de sidor som användaren besöker. Detta är det genomsnittliga värdet för en sida som en användare besökte innan han landade på målsidan eller slutförde en e-handelstransaktion (eller båda). |
SpecialDay |
Binary | Funktionen "Special Day" indikerar hur nära webbplatsens besökstid en specifik speciell dag (som Mors dag eller Alla hjärtans dag) då sessionerna är mer sannolikt att avslutas med en transaktion. |
Month |
Kategorisk | Månaden för besöket. |
OperatingSystems |
Kategorisk | Besökarens operativsystem. |
Browser |
Kategorisk | Webbläsare som används av användaren. |
Region |
Kategorisk | Geografisk region från vilken sessionen har startat av besökaren. |
TrafficType |
Kategorisk | Trafikkälla genom vilken användare har kommit in på webbplatsen. |
VisitorType |
Kategorisk | Oavsett om kunden är en ny användare, återkommande användare eller annan. |
Weekend |
Binary | Om kunden besökte hemsidan på helgen. |
Revenue |
Binary | Om ett köp gjordes. |
Intäkter är målkolumnen, som hjälper oss att förutsäga om en shoppare kommer att köpa en produkt eller inte.
Det första steget är att ladda ner datamängden som vi kommer att använda. Observera att denna datamängd är med tillstånd från UCI Machine Learning Repository.
Förutsättningar
För den här genomgången, slutför följande nödvändiga steg:
- Dela upp den nedladdade CSV-filen som innehåller 20,000 XNUMX rader i flera mindre bitfiler.
Detta för att vi ska kunna visa upp datauppsättningsuppdateringsfunktionen. Se till att alla CSV-filer har samma rubriker, annars kan du stöta på schemafel när du skapar en träningsdatauppsättning i Canvas.

- Skapa en S3-bucket och ladda upp
online_shoppers_intentions1-3.csvtill S3-skopan.

- Avsätt 1,500 XNUMX rader från den nedladdade CSV-filen för att köra batchförutsägelser efter att ML-modellen har tränats.
- Ta bort
Revenuekolumnen från dessa filer så att när du kör batchförutsägelse på ML-modellen är det värdet som din modell kommer att förutsäga.
Se till att alla predict*.csv filer har samma rubriker, annars kan du stöta på schemafel när du skapar en förutsägelsedatauppsättning (inferens) i Canvas.

- Utför de nödvändiga stegen för att konfigurera en SageMaker-domän och Canvas-app.
Skapa en datauppsättning
För att skapa en datauppsättning i Canvas, slutför följande steg:
- Välj i Canvas dataset i navigeringsfönstret.
- Välja Skapa Och välj Tabellformat.

- Ge din datauppsättning ett namn. För det här inlägget kallar vi vår träningsdatauppsättning
OnlineShoppersIntentions. - Välja Skapa.

- Välj din datakälla (för det här inlägget är vår datakälla Amazon S3).
Observera att när detta skrivs stöds datauppsättningsuppdateringsfunktionen endast för Amazon S3 och lokalt uppladdade datakällor.
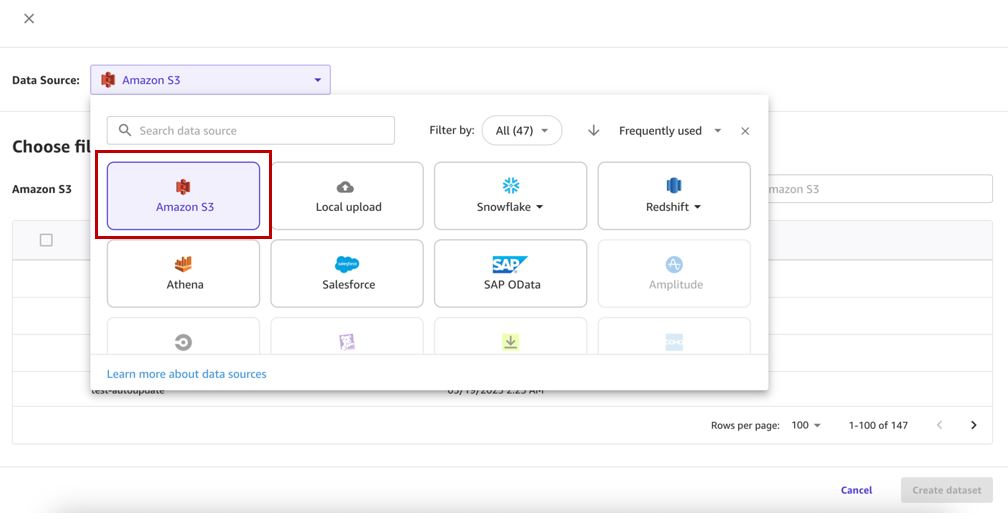
- Välj motsvarande hink och ladda upp CSV-filerna för datamängden.
Du kan nu skapa en datauppsättning med flera filer.

- Förhandsgranska alla filer i datamängden och välj Skapa datasätt.

Vi har nu version 1 av OnlineShoppersIntentions dataset med tre filer skapade.
- Välj datauppsättningen för att se detaljerna.

Smakämnen Data fliken visar en förhandsvisning av datamängden.
- Välja Dataset detaljer för att visa filerna som datasetet innehåller.
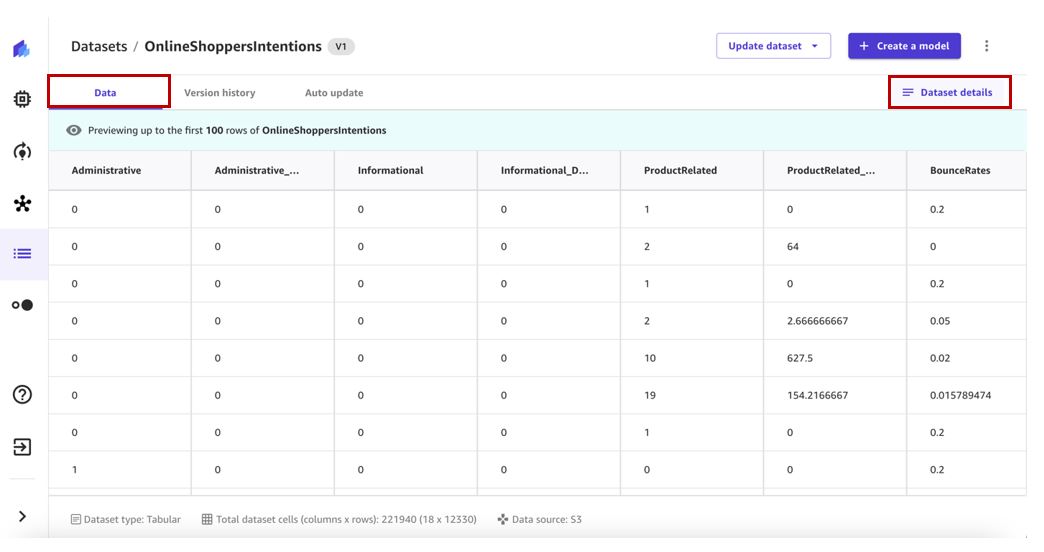
Smakämnen Datauppsättningsfiler rutan listar tillgängliga filer.

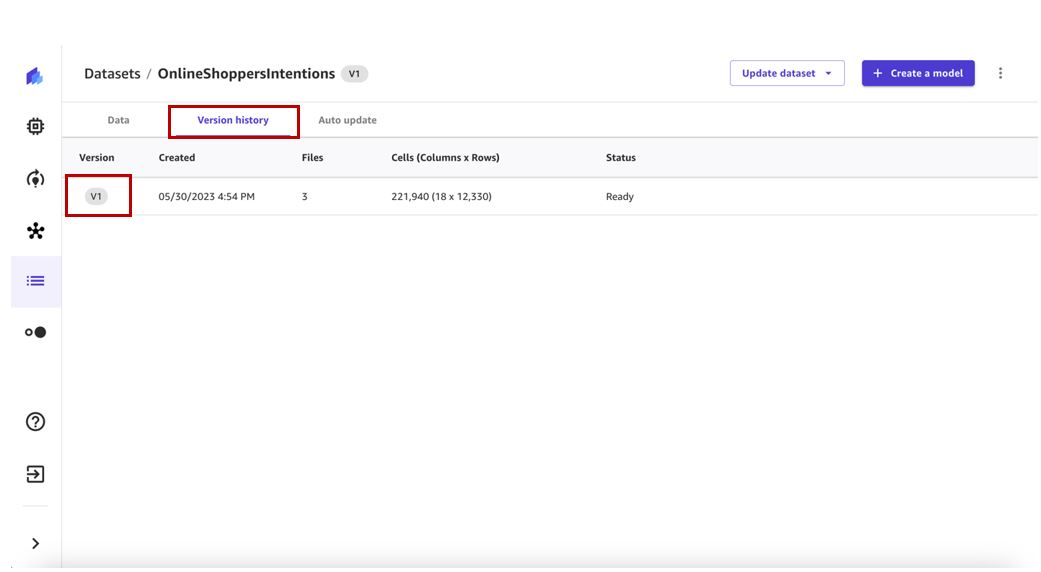
- Välj version History fliken för att se alla versioner för denna datauppsättning.
Vi kan se att vår första datauppsättningsversion har tre filer. Varje efterföljande version kommer att inkludera alla filer från tidigare versioner och kommer att ge en kumulativ bild av data.
Träna en ML-modell med version 1 av datamängden
Låt oss träna en ML-modell med version 1 av vår datauppsättning.
- Välj i Canvas Mina modeller i navigeringsfönstret.
- Välja Ny modell.
- Ange ett modellnamn (t.ex.
OnlineShoppersIntentionsModel), välj problemtyp och välj Skapa.
- Välj datamängden. För det här inlägget väljer vi
OnlineShoppersIntentionsdatasätt.
Som standard hämtar Canvas den senaste datauppsättningsversionen för träning.

- På Bygga fliken väljer du målkolumnen att förutsäga. För det här inlägget väljer vi kolumnen Intäkt.
- Välja Snabbbyggnad.

Modellutbildningen tar 2–5 minuter att genomföra. I vårt fall ger den tränade modellen oss ett betyg på 89 %.

Ställ in automatiska datauppsättningsuppdateringar
Låt oss uppdatera på vår datauppsättning med hjälp av funktionen för automatisk uppdatering och ta in mer data och se om modellens prestanda förbättras med den nya versionen av datauppsättningen. Datauppsättningar kan också uppdateras manuellt.
- På dataset sida, välj
OnlineShoppersIntentionsdataset och välj Uppdatera dataset. - Du kan antingen välja Manuell uppdatering, som är ett engångsuppdateringsalternativ, eller Automatisk uppdatering, som låter dig uppdatera din datauppsättning automatiskt enligt ett schema. För det här inlägget visar vi upp den automatiska uppdateringsfunktionen.

Du omdirigeras till Automatisk uppdatering fliken för motsvarande datauppsättning. Vi kan se det Aktivera automatisk uppdatering är för närvarande inaktiverad.

- Växla Aktivera automatisk uppdatering på och ange datakällan (när detta skrivs stöds Amazon S3-datakällor för automatiska uppdateringar).
- Välj en frekvens och ange en starttid.
- Spara konfigurationsinställningarna.

En datauppsättningskonfiguration för automatisk uppdatering har skapats. Den kan redigeras när som helst. När ett motsvarande uppdateringsjobb för dataset utlöses enligt det angivna schemat, kommer jobbet att visas i Jobbhistoria sektion.

- Låt oss sedan ladda upp
online_shoppers_intentions4.csv,online_shoppers_intentions5.csvochonline_shoppers_intentions6.csvfiler till vår S3-hink.

Vi kan se våra filer i dataset-update-demo S3 hink.

Uppdateringsjobbet för datasetet kommer att triggas vid det angivna schemat och skapa en ny version av datamängden.

När jobbet är klart kommer datauppsättningsversion 2 att ha alla filer från version 1 och de ytterligare filerna bearbetade av datauppsättningsuppdateringsjobbet. I vårt fall har version 1 tre filer och uppdateringsjobbet hämtade ytterligare tre filer, så den slutliga datauppsättningsversionen har sex filer.
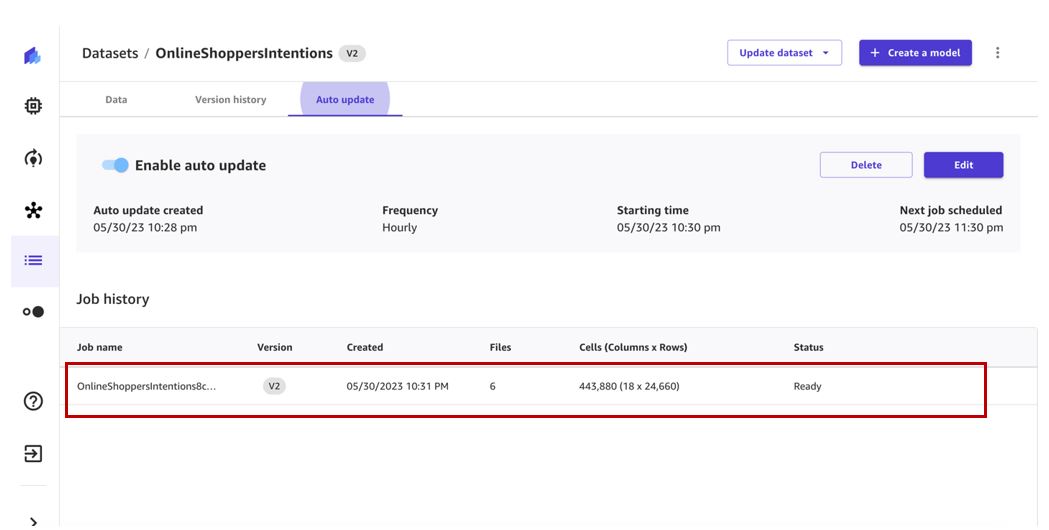
Vi kan se den nya versionen som skapades på Versionshistorik fliken.

Smakämnen Data fliken innehåller en förhandsvisning av datamängden och ger en lista över alla filer i den senaste versionen av datamängden.

Träna om ML-modellen med en uppdaterad datauppsättning
Låt oss omskola vår ML-modell med den senaste versionen av datamängden.
- På Mina modeller sida, välj din modell.
- Välja Lägg till version.
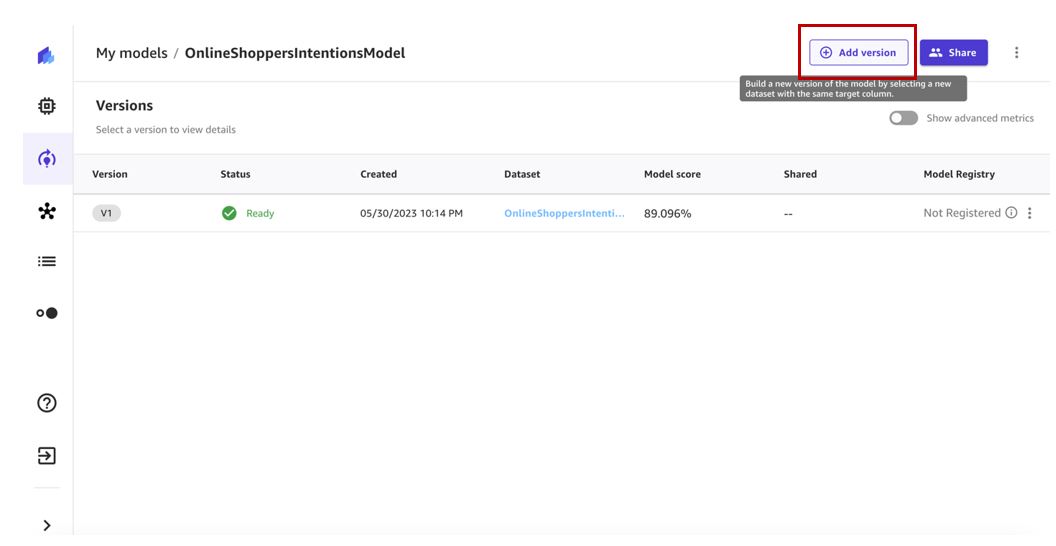
- Välj den senaste datauppsättningsversionen (v2 i vårt fall) och välj Välj dataset.
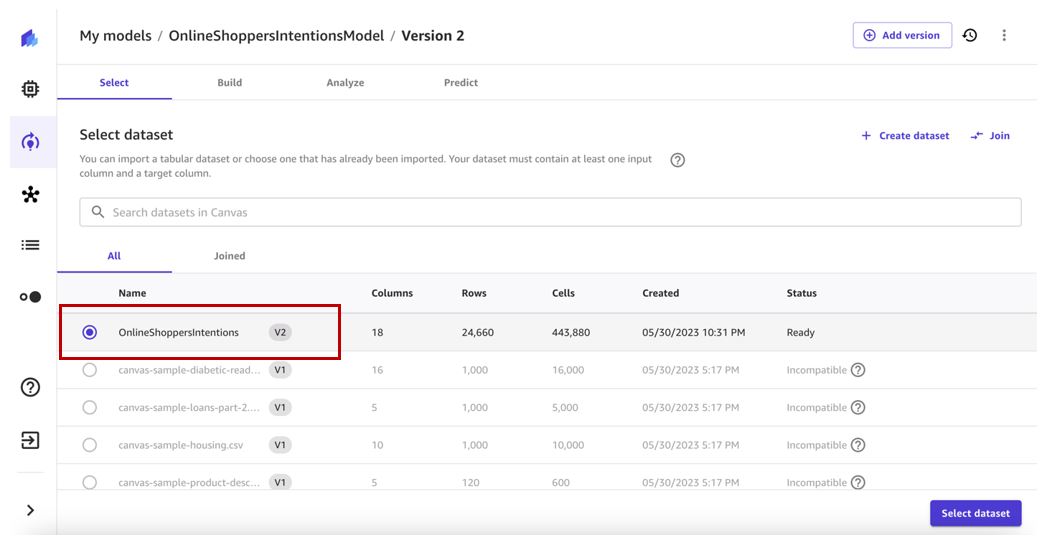
- Behåll målkolumnen och byggkonfigurationen som liknar den tidigare modellversionen.

När utbildningen är klar, låt oss utvärdera modellens prestanda. Följande skärmdump visar att lägga till ytterligare data och omskola vår ML-modell har hjälpt till att förbättra vår modellprestanda.

Skapa en förutsägelsedatauppsättning
Med en ML-modell tränad, låt oss skapa en datauppsättning för förutsägelser och köra batchförutsägelser på den.
- På dataset sida, skapa en tabelluppsättning.
- Ange ett namn och välj Skapa.

- I vår S3-bucket laddar du upp en fil med 500 rader att förutsäga.

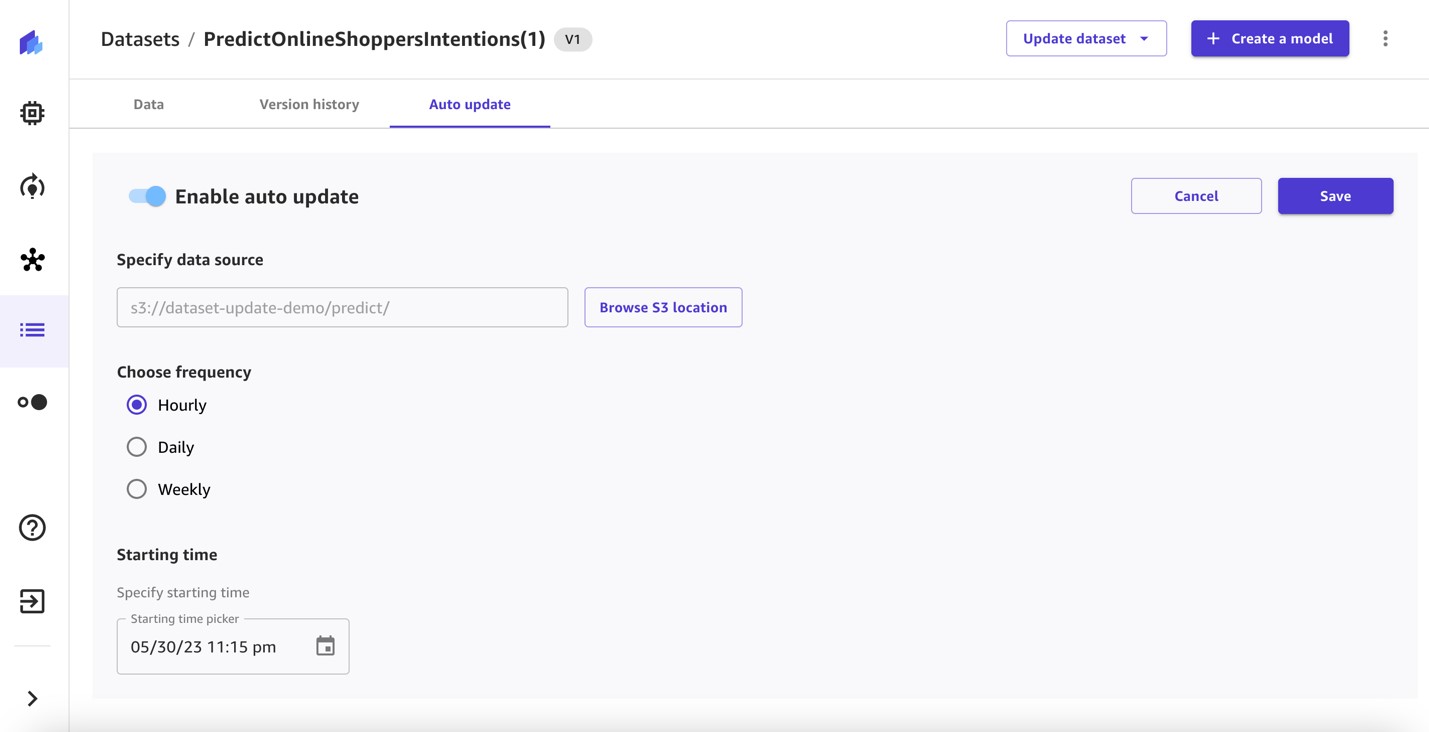
Därefter ställer vi in automatiska uppdateringar på förutsägelsedatauppsättningen.
- Växla Aktivera automatisk uppdatering på och ange datakällan.
- Välj frekvens och ange en starttid.
- Spara konfigurationen.
Automatisera batchförutsägelsearbetsflödet på en automatiskt uppdaterad förutsägelsedatauppsättning
I det här steget konfigurerar vi våra automatiska batch-förutsägelsearbetsflöden.
- På Mina modeller sida, navigera till version 2 av din modell.
- På förutsäga fliken, välj Batch-förutsägelse och Automat.
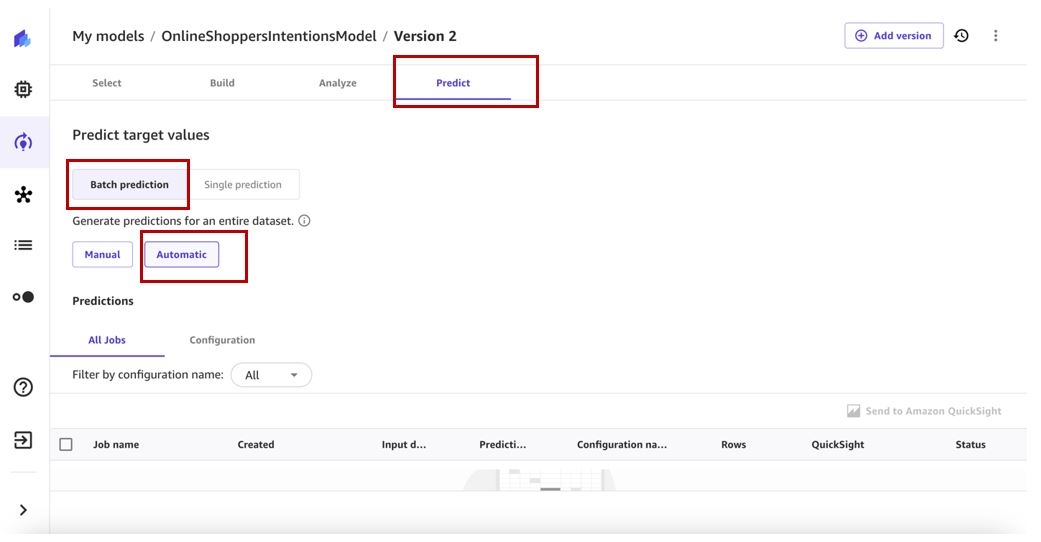
- Välja Välj dataset för att ange datauppsättningen att generera förutsägelser på.

- Välj
predictdataset som vi skapade tidigare och väljer Välj dataset.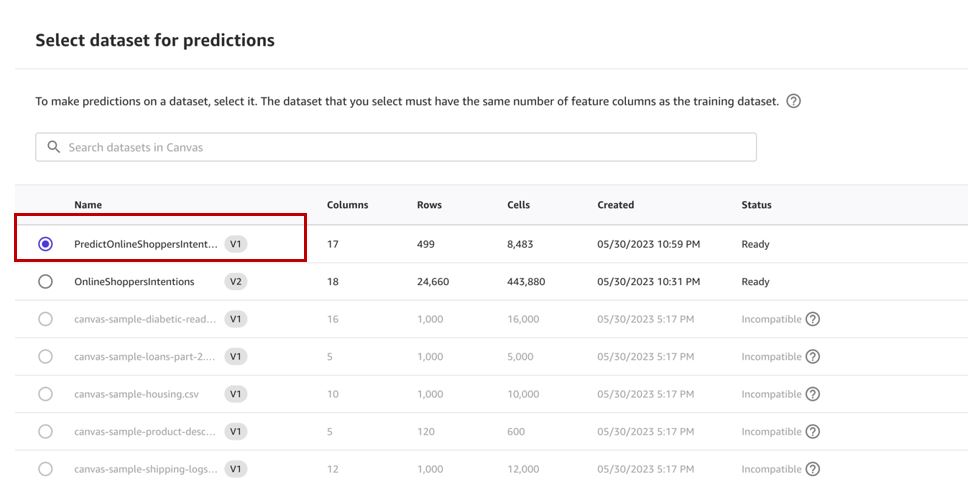
- Välja Montera myggnät för luckor.

Vi har nu ett automatiskt arbetsflöde för batchprediktion. Detta kommer att utlösas när Predict datasetet uppdateras automatiskt.

Låt oss nu ladda upp fler CSV-filer till predict S3 mapp.
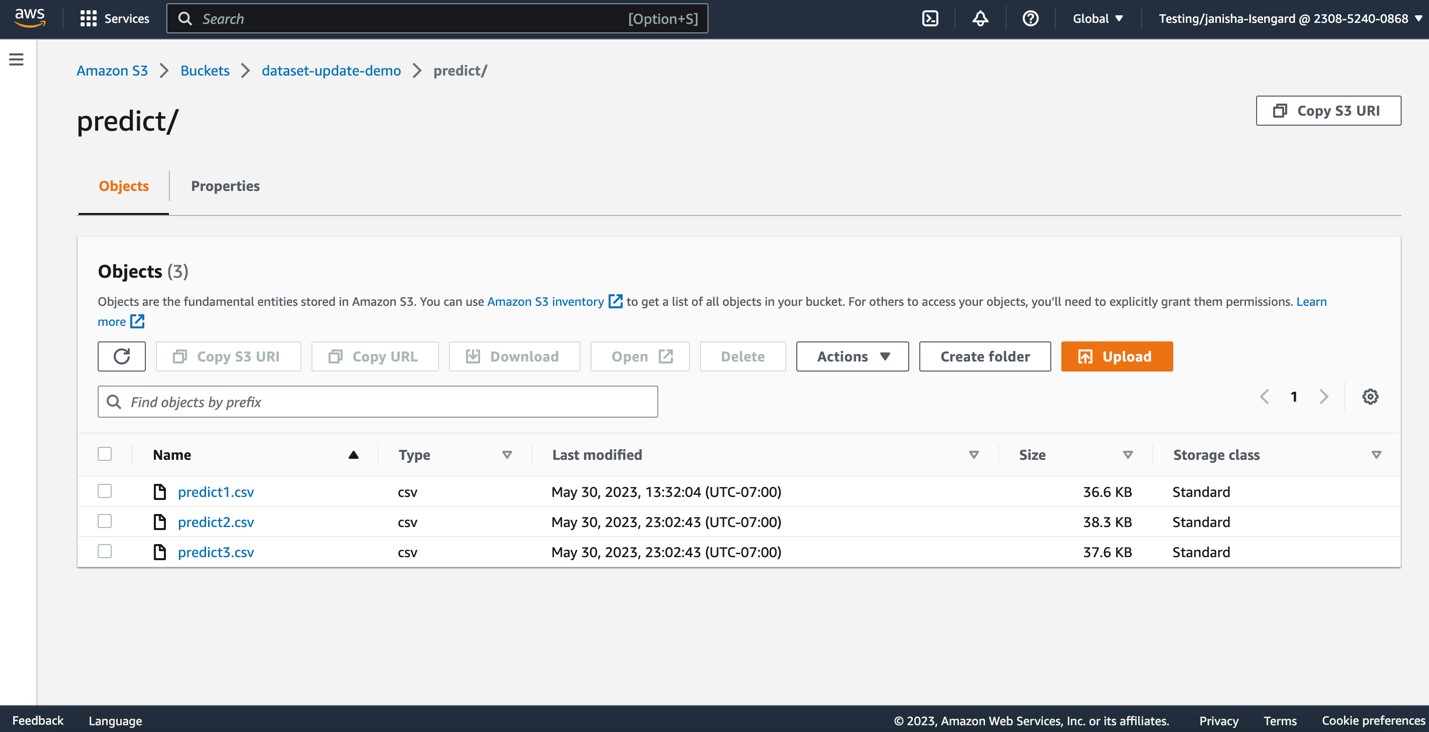
Denna operation kommer att utlösa en automatisk uppdatering av predict datasätt.
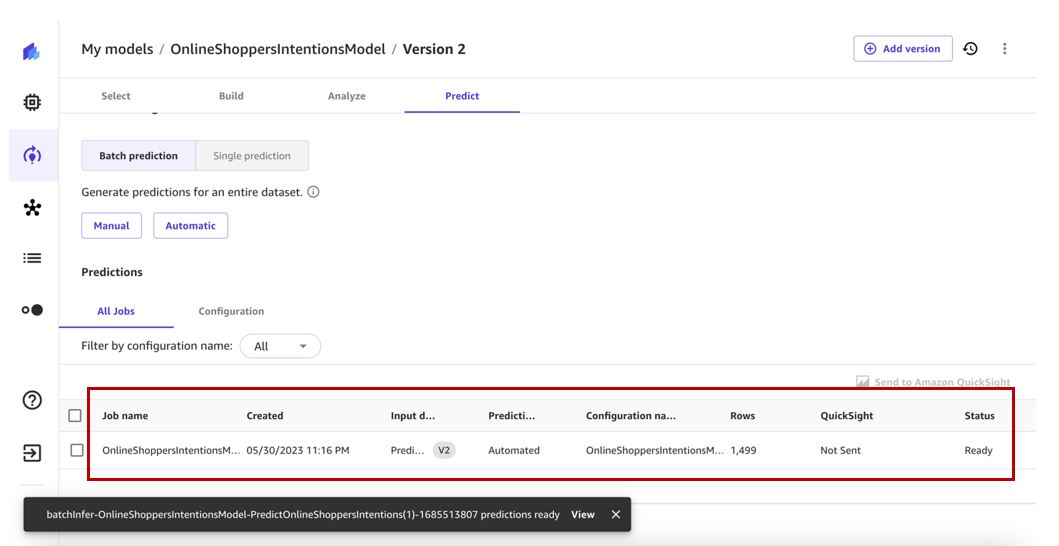
Detta kommer i sin tur att utlösa det automatiska batchförutsägelsearbetsflödet och generera förutsägelser som vi kan se.

Vi kan se alla automatiseringar på Automationer sida.

Tack vare den automatiska datauppsättningsuppdateringen och automatiska batchförutsägelsearbetsflödena kan vi använda den senaste versionen av tabell-, bild- och dokumentdatauppsättningen för att träna ML-modeller och bygga batchförutsägelsearbetsflöden som utlöses automatiskt vid varje datauppsättningsuppdatering.
Städa upp
Logga ut från Canvas för att undvika framtida avgifter. Canvas fakturerar dig för hela sessionen, och vi rekommenderar att du loggar ut från Canvas när du inte använder den. Hänvisa till Logga ut från Amazon SageMaker Canvas för mer detaljer.
Slutsats
I det här inlägget diskuterade vi hur vi kan använda den nya datauppdateringsförmågan för att bygga nya datauppsättningsversioner och träna våra ML-modeller med den senaste datan i Canvas. Vi visade också hur vi effektivt kan automatisera processen att köra batchförutsägelser på uppdaterad data.
För att starta din ML-resa med låg kod/no-kod, se Amazon SageMaker Canvas Developer Guide.
Ett särskilt tack till alla som bidragit till lanseringen.
Om författarna
 Janisha Anand är Senior Product Manager på SageMaker No/Low-Code ML-teamet, som inkluderar SageMaker Canvas och SageMaker Autopilot. Hon tycker om kaffe, att vara aktiv och umgås med sin familj.
Janisha Anand är Senior Product Manager på SageMaker No/Low-Code ML-teamet, som inkluderar SageMaker Canvas och SageMaker Autopilot. Hon tycker om kaffe, att vara aktiv och umgås med sin familj.
 Prashanth är mjukvaruutvecklingsingenjör på Amazon SageMaker och arbetar huvudsakligen med SageMaker lågkods- och no-code-produkter.
Prashanth är mjukvaruutvecklingsingenjör på Amazon SageMaker och arbetar huvudsakligen med SageMaker lågkods- och no-code-produkter.
 Esha Dutta är en mjukvaruutvecklingsingenjör på Amazon SageMaker. Hon fokuserar på att bygga ML-verktyg och produkter för kunder. Utanför jobbet tycker hon om att vara utomhus, yoga och vandra.
Esha Dutta är en mjukvaruutvecklingsingenjör på Amazon SageMaker. Hon fokuserar på att bygga ML-verktyg och produkter för kunder. Utanför jobbet tycker hon om att vara utomhus, yoga och vandra.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- EVM Finans. Unified Interface for Decentralized Finance. Tillgång här.
- Quantum Media Group. IR/PR förstärkt. Tillgång här.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/retrain-ml-models-and-automate-batch-predictions-in-amazon-sagemaker-canvas-using-updated-datasets/