
โพสต์นี้ร่วมเขียนโดย Goktug Cinar, Michael Binder และ Adrian Horvath จาก Bosch Center for Artificial Intelligence (BCAI)
การคาดการณ์รายได้เป็นงานที่ท้าทายแต่มีความสำคัญสำหรับการตัดสินใจทางธุรกิจเชิงกลยุทธ์และการวางแผนทางการเงินในองค์กรส่วนใหญ่ บ่อยครั้ง การคาดการณ์รายได้จะดำเนินการด้วยตนเองโดยนักวิเคราะห์ทางการเงิน ซึ่งใช้เวลานานและเป็นส่วนตัว ความพยายามด้วยตนเองดังกล่าวมีความท้าทายเป็นพิเศษสำหรับองค์กรธุรกิจข้ามชาติขนาดใหญ่ที่ต้องการการคาดการณ์รายได้ในกลุ่มผลิตภัณฑ์ที่หลากหลายและพื้นที่ทางภูมิศาสตร์ที่ความละเอียดหลายระดับ สิ่งนี้ไม่เพียงต้องการความแม่นยำเท่านั้น แต่ยังต้องมีการเชื่อมโยงกันของการคาดการณ์ตามลำดับชั้นด้วย
บ๊อช เป็นบริษัทข้ามชาติที่มีหน่วยงานที่ดำเนินงานในหลายภาคส่วน รวมถึงยานยนต์ โซลูชั่นอุตสาหกรรม และสินค้าอุปโภคบริโภค ด้วยผลกระทบของการคาดการณ์รายได้ที่ถูกต้องและสอดคล้องกันในการดำเนินธุรกิจที่ดี บ๊อช ศูนย์ปัญญาประดิษฐ์ (BCAI) ลงทุนอย่างมากในการใช้การเรียนรู้ของเครื่อง (ML) เพื่อปรับปรุงประสิทธิภาพและความถูกต้องของกระบวนการวางแผนทางการเงิน เป้าหมายคือการบรรเทากระบวนการที่ต้องทำด้วยตนเองโดยการให้การคาดการณ์รายได้พื้นฐานที่สมเหตุสมผลผ่าน ML โดยมีการปรับเปลี่ยนเป็นครั้งคราวเท่านั้นที่นักวิเคราะห์ทางการเงินต้องการโดยใช้ความรู้ด้านอุตสาหกรรมและโดเมนของตน
เพื่อให้บรรลุเป้าหมายนี้ BCAI ได้พัฒนากรอบการคาดการณ์ภายในที่สามารถให้การคาดการณ์แบบลำดับชั้นขนาดใหญ่ผ่านชุดปรับแต่งของแบบจำลองพื้นฐานที่หลากหลาย meta-learner จะเลือกโมเดลที่มีประสิทธิภาพดีที่สุดโดยพิจารณาจากคุณลักษณะที่ดึงมาจากแต่ละอนุกรมเวลา การคาดการณ์จากแบบจำลองที่เลือกจะถูกหาค่าเฉลี่ยเพื่อรับการคาดการณ์แบบรวม การออกแบบสถาปัตยกรรมเป็นแบบแยกส่วนและขยายได้โดยใช้อินเทอร์เฟซแบบ REST ซึ่งช่วยให้สามารถปรับปรุงประสิทธิภาพอย่างต่อเนื่องผ่านการรวมโมเดลเพิ่มเติม
BCAI ร่วมมือกับ ห้องปฏิบัติการโซลูชัน Amazon ML (MLSL) เพื่อรวมความก้าวหน้าล่าสุดในโมเดล Deep Neural Network (DNN) สำหรับการคาดการณ์รายได้ ความก้าวหน้าล่าสุดในการคาดการณ์ทางประสาทได้แสดงให้เห็นประสิทธิภาพที่ล้ำสมัยสำหรับปัญหาการคาดการณ์ในทางปฏิบัติมากมาย เมื่อเทียบกับแบบจำลองการคาดการณ์แบบดั้งเดิม นักพยากรณ์ประสาทจำนวนมากสามารถรวม covariates หรือข้อมูลเมตาเพิ่มเติมของอนุกรมเวลาได้ เรารวม CNN-QR และ DeepAR+ ซึ่งเป็นรุ่นที่วางจำหน่ายแล้วใน พยากรณ์อเมซอน, ตลอดจนโมเดล Transformer แบบกำหนดเองที่ได้รับการฝึกฝนโดยใช้ อเมซอน SageMaker. ทั้งสามรุ่นครอบคลุมชุดตัวแทนของแกนหลักของตัวเข้ารหัสที่มักใช้ในเครื่องพยากรณ์ประสาท: โครงข่ายประสาทเทียม (CNN), โครงข่ายประสาทเทียมแบบต่อเนื่องตามลำดับ (RNN) และตัวเข้ารหัสแบบใช้หม้อแปลงไฟฟ้า
หนึ่งในความท้าทายหลักที่พันธมิตร BCAI-MLSL ต้องเผชิญคือการจัดทำการคาดการณ์ที่แข็งแกร่งและสมเหตุสมผลภายใต้ผลกระทบของ COVID-19 ซึ่งเป็นเหตุการณ์ระดับโลกที่ไม่เคยเกิดขึ้นมาก่อนซึ่งทำให้เกิดความผันผวนอย่างมากต่อผลประกอบการทางการเงินขององค์กรทั่วโลก เนื่องจากนักพยากรณ์ประสาทได้รับการฝึกอบรมเกี่ยวกับข้อมูลในอดีต การคาดการณ์ที่สร้างขึ้นจากข้อมูลที่ไม่อยู่ในการกระจายจากช่วงเวลาที่ผันผวนมากขึ้นจึงอาจไม่ถูกต้องและไม่น่าเชื่อถือ ดังนั้นเราจึงเสนอให้เพิ่มกลไกการปกปิดความสนใจในสถาปัตยกรรม Transformer เพื่อแก้ไขปัญหานี้
ตัวพยากรณ์ประสาทสามารถรวมเป็นแบบจำลองวงดนตรีเดี่ยว หรือรวมเป็นเอกเทศในจักรวาลแบบจำลองของ Bosch และเข้าถึงได้ง่ายผ่านจุดปลาย REST API เราเสนอแนวทางในการรวมตัวพยากรณ์ทางประสาทผ่านผลการทดสอบย้อนหลัง ซึ่งให้ประสิทธิภาพการแข่งขันและแข็งแกร่งเมื่อเวลาผ่านไป นอกจากนี้ เรายังตรวจสอบและประเมินเทคนิคการกระทบยอดแบบลำดับชั้นแบบคลาสสิกจำนวนหนึ่งเพื่อให้แน่ใจว่าการคาดการณ์จะรวมกันอย่างสอดคล้องกันในกลุ่มผลิตภัณฑ์ ภูมิศาสตร์ และองค์กรธุรกิจ
ในโพสต์นี้ เราสาธิตสิ่งต่อไปนี้:
- วิธีการใช้แบบจำลองที่กำหนดเองของ Forecast และ SageMaker สำหรับปัญหาการพยากรณ์อนุกรมเวลาขนาดใหญ่ที่มีลำดับชั้น
- วิธีประกอบโมเดลแบบกำหนดเองด้วยโมเดลนอกชั้นวางจาก Forecast
- วิธีลดผลกระทบของเหตุการณ์ก่อกวนเช่น COVID-19 ต่อปัญหาการคาดการณ์
- วิธีสร้างเวิร์กโฟลว์การคาดการณ์แบบ end-to-end บน AWS
ความท้าทาย
เราจัดการกับความท้าทายสองประการ: การสร้างการคาดการณ์รายได้ขนาดใหญ่แบบลำดับชั้น และผลกระทบของการระบาดใหญ่ของโควิด-19 ต่อการคาดการณ์ในระยะยาว
การคาดการณ์รายได้ขนาดใหญ่แบบลำดับชั้น
นักวิเคราะห์ทางการเงินมีหน้าที่ในการคาดการณ์ตัวเลขทางการเงินที่สำคัญ รวมถึงรายได้ ค่าใช้จ่ายในการดำเนินงาน และค่าใช้จ่ายด้านการวิจัยและพัฒนา ตัวชี้วัดเหล่านี้ให้ข้อมูลเชิงลึกเกี่ยวกับการวางแผนธุรกิจในระดับต่างๆ ของการรวมกลุ่ม และเปิดใช้งานการตัดสินใจที่ขับเคลื่อนด้วยข้อมูล โซลูชันการคาดการณ์อัตโนมัติใดๆ จำเป็นต้องจัดเตรียมการคาดการณ์ที่ระดับใดๆ ของการรวมสายธุรกิจตามอำเภอใจ ที่ Bosch สามารถจินตนาการถึงการรวมเป็นอนุกรมเวลาที่จัดกลุ่มเป็นรูปแบบทั่วไปของโครงสร้างแบบลำดับชั้น รูปภาพต่อไปนี้แสดงตัวอย่างแบบง่ายที่มีโครงสร้างสองระดับ ซึ่งเลียนแบบโครงสร้างการคาดการณ์รายได้แบบลำดับชั้นที่ Bosch รายได้รวมแบ่งออกเป็นหลายระดับของการรวมตามผลิตภัณฑ์และภูมิภาค
จำนวนอนุกรมเวลาทั้งหมดที่ต้องคาดการณ์ที่ Bosch อยู่ที่ระดับล้าน โปรดสังเกตว่าอนุกรมเวลาระดับบนสุดสามารถแบ่งตามผลิตภัณฑ์หรือภูมิภาคได้ สร้างเส้นทางหลายเส้นทางไปยังการคาดการณ์ระดับล่างสุด รายได้จะต้องได้รับการคาดการณ์ที่ทุกโหนดในลำดับชั้นโดยมีขอบเขตการคาดการณ์เป็นเวลา 12 เดือนในอนาคต มีข้อมูลประวัติรายเดือน
โครงสร้างลำดับชั้นสามารถแสดงได้โดยใช้รูปแบบต่อไปนี้พร้อมสัญกรณ์ของเมทริกซ์ผลรวม S (Hyndman และ Athanasopoulos):
![]()
ในสมการนี้ Y เท่ากับต่อไปนี้:

ที่นี่ b แสดงถึงลำดับเวลาระดับล่างสุด ณ เวลานั้น t.
ผลกระทบจากการระบาดของไวรัสโควิด-19
การระบาดใหญ่ของ COVID-19 ทำให้เกิดความท้าทายที่สำคัญสำหรับการคาดการณ์ เนื่องจากผลกระทบที่ก่อกวนและไม่เคยเกิดขึ้นมาก่อนในแทบทุกด้านของการทำงานและชีวิตทางสังคม สำหรับการคาดการณ์รายได้ในระยะยาว การหยุดชะงักยังทำให้เกิดผลกระทบต่อท้ายน้ำที่ไม่คาดคิดอีกด้วย เพื่อแสดงปัญหานี้ รูปภาพต่อไปนี้แสดงอนุกรมเวลาตัวอย่างซึ่งรายได้จากผลิตภัณฑ์ลดลงอย่างมากในช่วงเริ่มต้นของการระบาดใหญ่และค่อยๆ ฟื้นตัวในภายหลัง โมเดลการคาดการณ์ทางประสาททั่วไปจะใช้ข้อมูลรายได้ซึ่งรวมถึงช่วง COVID ที่ไม่อยู่ในการกระจาย (OOD) เป็นข้อมูลบริบททางประวัติศาสตร์ รวมถึงความจริงพื้นฐานสำหรับการฝึกแบบจำลอง เป็นผลให้การคาดการณ์ที่เกิดขึ้นไม่น่าเชื่อถืออีกต่อไป

แนวทางการสร้างแบบจำลอง
ในส่วนนี้ เราจะพูดถึงแนวทางการสร้างแบบจำลองต่างๆ ของเรา
พยากรณ์อเมซอน
การพยากรณ์เป็นบริการ AI/ML ที่มีการจัดการเต็มรูปแบบจาก AWS ซึ่งมีรูปแบบการคาดการณ์อนุกรมเวลาที่ทันสมัยและกำหนดค่าไว้ล่วงหน้า มันรวมข้อเสนอเหล่านี้เข้ากับความสามารถภายในสำหรับการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์อัตโนมัติ การสร้างแบบจำลองทั้งมวล (สำหรับแบบจำลองที่จัดทำโดย Forecast) และการสร้างการคาดการณ์ความน่าจะเป็น วิธีนี้ช่วยให้คุณนำเข้าชุดข้อมูลที่กำหนดเอง ประมวลผลข้อมูลล่วงหน้า ฝึกโมเดลการคาดการณ์ และสร้างการคาดการณ์ที่มีประสิทธิภาพได้อย่างง่ายดาย การออกแบบโมดูลาร์ของบริการเพิ่มเติมช่วยให้เราสามารถสืบค้นและรวมการคาดการณ์จากโมเดลที่กำหนดเองเพิ่มเติมที่พัฒนาควบคู่กันไปได้อย่างง่ายดาย
เรารวมตัวพยากรณ์ประสาทสองตัวจากการคาดการณ์: CNN-QR และ DeepAR+ ทั้งสองวิธีนี้เป็นวิธีการเรียนรู้เชิงลึกภายใต้การดูแลที่ฝึกแบบจำลองส่วนกลางสำหรับชุดข้อมูลอนุกรมเวลาทั้งหมด ทั้งรุ่น CNNQR และ DeepAR+ สามารถรับข้อมูลเมตาดาต้าแบบคงที่เกี่ยวกับอนุกรมเวลาแต่ละชุด ซึ่งเป็นผลิตภัณฑ์ ภูมิภาค และองค์กรธุรกิจที่เกี่ยวข้องในกรณีของเรา พวกเขายังเพิ่มคุณสมบัติชั่วคราวโดยอัตโนมัติ เช่น เดือนของปี โดยเป็นส่วนหนึ่งของข้อมูลป้อนเข้าสู่โมเดล
Transformer พร้อมหน้ากากป้องกันโควิด
สถาปัตยกรรม Transformer (Vaswani และคณะ) ซึ่งเดิมออกแบบสำหรับการประมวลผลภาษาธรรมชาติ (NLP) เมื่อเร็ว ๆ นี้ได้กลายเป็นตัวเลือกทางสถาปัตยกรรมยอดนิยมสำหรับการพยากรณ์อนุกรมเวลา ที่นี่ เราใช้สถาปัตยกรรม Transformer ที่อธิบายไว้ใน โจวและคณะ โดยไม่มีการบันทึกความน่าจะเป็น โมเดลนี้ใช้การออกแบบสถาปัตยกรรมทั่วไปโดยรวมตัวเข้ารหัสและตัวถอดรหัส สำหรับการคาดการณ์รายได้ เรากำหนดค่าตัวถอดรหัสเพื่อส่งออกการคาดการณ์ของขอบฟ้า 12 เดือนโดยตรง แทนที่จะสร้างการคาดการณ์แบบรายเดือนในลักษณะถดถอยอัตโนมัติ ตามความถี่ของอนุกรมเวลา คุณลักษณะเพิ่มเติมที่เกี่ยวข้องกับเวลา เช่น เดือนของปี จะถูกเพิ่มเป็นตัวแปรอินพุต ตัวแปรตามหมวดหมู่เพิ่มเติมที่อธิบายข้อมูลเมตา (ผลิตภัณฑ์ ภูมิภาค องค์กรธุรกิจ) จะถูกป้อนเข้าสู่เครือข่ายผ่านเลเยอร์การฝังที่ฝึกได้
ไดอะแกรมต่อไปนี้แสดงสถาปัตยกรรม Transformer และกลไกการปิดบังความสนใจ การมาสก์การเตือนจะใช้ตลอดทั้งเลเยอร์ตัวเข้ารหัสและตัวถอดรหัสตามที่ไฮไลต์เป็นสีส้ม เพื่อป้องกันไม่ให้ข้อมูล OOD ส่งผลกระทบต่อการคาดการณ์

เราลดผลกระทบของหน้าต่างบริบท OOD โดยการเพิ่มมาสก์ความสนใจ โมเดลนี้ได้รับการฝึกฝนให้ให้ความสนใจเพียงเล็กน้อยกับช่วงโควิดที่มีค่าผิดปกติผ่านการมาสก์ และทำการคาดการณ์ด้วยข้อมูลที่ปกปิด มาสก์ความสนใจถูกนำไปใช้ในทุกชั้นของสถาปัตยกรรมตัวถอดรหัสและตัวเข้ารหัส หน้าต่างที่ปิดบังสามารถระบุได้ด้วยตนเองหรือผ่านอัลกอริธึมการตรวจจับค่าผิดปกติ นอกจากนี้ เมื่อใช้กรอบเวลาที่มีค่าผิดปกติเป็นป้ายกำกับการฝึก ความสูญเสียจะไม่ถูกส่งต่อกลับ วิธีการที่ใช้การปิดบังความสนใจนี้สามารถนำไปใช้เพื่อจัดการกับการหยุดชะงักและกรณี OOD ที่เกิดจากเหตุการณ์หายากอื่นๆ และปรับปรุงความแข็งแกร่งของการคาดการณ์
วงดนตรีรุ่น
วงดนตรีรุ่นมักจะทำงานได้ดีกว่าแบบจำลองเดี่ยวสำหรับการคาดการณ์—จะปรับปรุงความสามารถในการสรุปทั่วไปของแบบจำลองและดีกว่าในการจัดการข้อมูลอนุกรมเวลาที่มีคุณสมบัติที่แตกต่างกันในช่วงระยะเวลาและช่วงไม่ต่อเนื่อง เรารวมชุดกลยุทธ์ชุดโมเดลเพื่อปรับปรุงประสิทธิภาพของแบบจำลองและความแข็งแกร่งของการคาดการณ์ รูปแบบทั่วไปอย่างหนึ่งของชุดโมเดลการเรียนรู้เชิงลึกคือการรวมผลลัพธ์จากการรันแบบจำลองด้วยการเริ่มต้นน้ำหนักแบบสุ่มที่แตกต่างกัน หรือจากยุคการฝึกที่แตกต่างกัน เราใช้กลยุทธ์นี้เพื่อรับการคาดการณ์สำหรับรุ่น Transformer
เพื่อสร้างวงดนตรีเพิ่มเติมบนสถาปัตยกรรมแบบจำลองต่างๆ เช่น Transformer, CNNQR และ DeepAR+ เราใช้กลยุทธ์ชุดรวมโมเดลแบบแพนซึ่งเลือกโมเดลที่ทำงานได้ดีที่สุดสำหรับแต่ละอนุกรมเวลาโดยพิจารณาจากผลการทดสอบย้อนหลังและได้ ค่าเฉลี่ย เนื่องจากผลการทดสอบย้อนหลังสามารถส่งออกได้โดยตรงจากแบบจำลองการพยากรณ์ที่ได้รับการฝึกอบรม กลยุทธ์นี้ช่วยให้เราสามารถใช้ประโยชน์จากบริการแบบเบ็ดเสร็จ เช่น การพยากรณ์ ด้วยการปรับปรุงที่ได้รับจากแบบจำลองแบบกำหนดเอง เช่น Transformer แนวทางการรวมโมเดลแบบ end-to-end ดังกล่าวไม่จำเป็นต้องมีการฝึกอบรม meta-learner หรือการคำนวณคุณสมบัติของอนุกรมเวลาสำหรับการเลือกแบบจำลอง
การกระทบยอดแบบลำดับชั้น
กรอบนี้สามารถปรับได้เพื่อรวมเทคนิคที่หลากหลายเป็นขั้นตอนหลังการประมวลผลสำหรับการกระทบยอดการคาดการณ์ตามลำดับชั้น ซึ่งรวมถึงจากล่างขึ้นบน (BU) การกระทบยอดจากบนลงล่างด้วยสัดส่วนการคาดการณ์ (TDFP) สี่เหลี่ยมจัตุรัสน้อยที่สุดธรรมดา (OLS) และกำลังสองน้อยที่สุดที่ถ่วงน้ำหนัก ( วสท.) ผลการทดลองทั้งหมดในโพสต์นี้รายงานโดยใช้การกระทบยอดจากบนลงล่างด้วยสัดส่วนการคาดการณ์
ภาพรวมสถาปัตยกรรม
เราพัฒนาเวิร์กโฟลว์แบบ end-to-end แบบอัตโนมัติบน AWS เพื่อสร้างการคาดการณ์รายได้โดยใช้บริการต่างๆ ซึ่งรวมถึง Forecast, SageMaker, บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (อเมซอน เอส3) AWS แลมบ์ดา, ฟังก์ชันขั้นตอนของ AWSและ ชุดพัฒนา AWS Cloud (AWS CDK). โซลูชันที่ปรับใช้ให้การคาดการณ์อนุกรมเวลาแต่ละรายการผ่าน REST API โดยใช้ Amazon API Gateway Amazonโดยส่งคืนผลลัพธ์ในรูปแบบ JSON ที่กำหนดไว้ล่วงหน้า
ไดอะแกรมต่อไปนี้แสดงเวิร์กโฟลว์การคาดการณ์ตั้งแต่ต้นจนจบ

การพิจารณาการออกแบบที่สำคัญสำหรับสถาปัตยกรรมคือความเก่งกาจ ประสิทธิภาพ และความเป็นมิตรต่อผู้ใช้ ระบบควรมีความอเนกประสงค์เพียงพอที่จะรวมชุดอัลกอริธึมที่หลากหลายในระหว่างการพัฒนาและการปรับใช้ โดยมีการเปลี่ยนแปลงที่จำเป็นน้อยที่สุด และสามารถขยายได้อย่างง่ายดายเมื่อเพิ่มอัลกอริธึมใหม่ในอนาคต ระบบควรเพิ่มค่าใช้จ่ายขั้นต่ำและสนับสนุนการฝึกอบรมแบบขนานสำหรับทั้ง Forecast และ SageMaker เพื่อลดเวลาในการฝึกอบรมและรับการคาดการณ์ล่าสุดได้เร็วขึ้น สุดท้าย ระบบควรใช้งานง่ายเพื่อการทดลอง
เวิร์กโฟลว์ end-to-end ทำงานตามลำดับผ่านโมดูลต่อไปนี้:
- โมดูลการประมวลผลล่วงหน้าสำหรับการจัดรูปแบบและการแปลงข้อมูลใหม่
- โมดูลการฝึกโมเดลที่รวมทั้งโมเดลการพยากรณ์และโมเดลแบบกำหนดเองบน SageMaker (ทั้งสองทำงานพร้อมกัน)
- โมดูลหลังการประมวลผลที่สนับสนุนชุดโมเดล การกระทบยอดตามลำดับชั้น เมทริก และการสร้างรายงาน
Step Functions จัดระเบียบและจัดการเวิร์กโฟลว์ตั้งแต่ต้นจนจบเป็นเครื่องสถานะ การรันเครื่องในสถานะได้รับการกำหนดค่าด้วยไฟล์ JSON ที่มีข้อมูลที่จำเป็นทั้งหมด รวมถึงตำแหน่งของไฟล์ CSV รายได้ที่ผ่านมาใน Amazon S3 เวลาเริ่มต้นการคาดการณ์ และการตั้งค่าไฮเปอร์พารามิเตอร์ของโมเดลเพื่อเรียกใช้เวิร์กโฟลว์ตั้งแต่ต้นจนจบ การเรียกแบบอะซิงโครนัสถูกสร้างขึ้นเพื่อขนานการฝึกแบบจำลองในเครื่องสถานะโดยใช้ฟังก์ชัน Lambda ข้อมูลประวัติ ไฟล์กำหนดค่า ผลการคาดการณ์ และผลลัพธ์ขั้นกลาง เช่น ผลการทดสอบย้อนหลังทั้งหมดจะถูกเก็บไว้ใน Amazon S3 REST API สร้างขึ้นบน Amazon S3 เพื่อจัดเตรียมอินเทอร์เฟซที่สามารถสืบค้นได้สำหรับการสืบค้นผลการคาดการณ์ สามารถขยายระบบเพื่อรวมแบบจำลองการคาดการณ์ใหม่และฟังก์ชันสนับสนุน เช่น การสร้างรายงานการแสดงภาพการคาดการณ์
การประเมินผล
ในส่วนนี้ เราจะให้รายละเอียดเกี่ยวกับการตั้งค่าการทดสอบ องค์ประกอบหลัก ได้แก่ ชุดข้อมูล เมทริกการประเมิน หน้าต่างการทดสอบย้อนหลัง การตั้งค่าโมเดลและการฝึกอบรม
ชุด
เพื่อปกป้องความเป็นส่วนตัวทางการเงินของ Bosch ในขณะที่ใช้ชุดข้อมูลที่มีความหมาย เราใช้ชุดข้อมูลสังเคราะห์ที่มีลักษณะทางสถิติที่คล้ายคลึงกันกับชุดข้อมูลรายได้จริงจากหน่วยธุรกิจหนึ่งหน่วยที่ Bosch ชุดข้อมูลประกอบด้วยอนุกรมเวลาทั้งหมด 1,216 รายการ โดยมีรายได้ที่บันทึกเป็นความถี่รายเดือน ครอบคลุมตั้งแต่มกราคม 2016 ถึงเมษายน 2022 ชุดข้อมูลนี้จัดส่งพร้อมอนุกรมเวลา 877 รายการในระดับที่ละเอียดที่สุด (อนุกรมเวลาด้านล่าง) โดยมีการแสดงโครงสร้างอนุกรมเวลาที่จัดกลุ่มที่สอดคล้องกัน เป็นเมทริกซ์ผลรวม S แต่ละอนุกรมเวลาเชื่อมโยงกับแอตทริบิวต์การจัดหมวดหมู่แบบคงที่สามรายการ ซึ่งสอดคล้องกับหมวดหมู่ผลิตภัณฑ์ ภูมิภาค และหน่วยขององค์กรในชุดข้อมูลจริง (ไม่ระบุชื่อในข้อมูลสังเคราะห์)
ตัวชี้วัดการประเมิน
เราใช้ค่ามัธยฐาน-Mean Arctangent Absolute Percentage Error (ค่ามัธยฐาน-MAAPE) และ Weighted-MAAPE เพื่อประเมินประสิทธิภาพของแบบจำลองและทำการวิเคราะห์เปรียบเทียบ ซึ่งเป็นตัวชี้วัดมาตรฐานที่ใช้ใน Bosch MAAPE กล่าวถึงข้อบกพร่องของตัวชี้วัด Mean Absolute Percentage Error (MAPE) ที่ใช้กันทั่วไปในบริบททางธุรกิจ ค่ามัธยฐาน-MAAPE ให้ภาพรวมของประสิทธิภาพของแบบจำลองโดยการคำนวณค่ามัธยฐานของ MAAPE ที่คำนวณแยกกันในแต่ละอนุกรมเวลา Weighted-MAAPE รายงานการรวมน้ำหนักของ MAAPE แต่ละรายการ น้ำหนักคือสัดส่วนของรายได้สำหรับแต่ละอนุกรมเวลาเทียบกับรายได้รวมของชุดข้อมูลทั้งหมด Weighted-MAAPE สะท้อนผลกระทบทางธุรกิจปลายน้ำของความแม่นยำในการคาดการณ์ได้ดีขึ้น เมตริกทั้งสองได้รับการรายงานในชุดข้อมูลทั้งหมดของอนุกรมเวลา 1,216 รายการ
ทดสอบย้อนหลัง windows
เราใช้หน้าต่างทดสอบย้อนหลัง 12 เดือนเพื่อเปรียบเทียบประสิทธิภาพของแบบจำลอง รูปต่อไปนี้แสดงหน้าต่างทดสอบย้อนหลังที่ใช้ในการทดลองและเน้นข้อมูลที่เกี่ยวข้องซึ่งใช้สำหรับการฝึกอบรมและการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์ (HPO) สำหรับช่วงทดสอบย้อนหลังหลังจากเริ่มโควิด-19 ผลลัพธ์จะได้รับผลกระทบจากอินพุต OOD ตั้งแต่เดือนเมษายนถึงพฤษภาคม 2020 โดยอิงจากสิ่งที่เราสังเกตเห็นจากอนุกรมเวลาของรายได้

การติดตั้งโมเดลและการฝึก
สำหรับการฝึกอบรม Transformer เราใช้การสูญเสียเชิงปริมาณและปรับขนาดในแต่ละอนุกรมเวลาโดยใช้ค่าเฉลี่ยในอดีตก่อนที่จะป้อนลงใน Transformer และคำนวณการสูญเสียการฝึก การคาดการณ์ขั้นสุดท้ายจะถูกปรับขนาดกลับเพื่อคำนวณเมตริกความถูกต้อง โดยใช้ MeanScaler ที่นำมาใช้ใน กลูออนทีเอส. เราใช้หน้าต่างบริบทที่มีข้อมูลรายได้รายเดือนในช่วง 18 เดือนที่ผ่านมา ซึ่งเลือกผ่าน HPO ในกรอบเวลาการทดสอบย้อนหลังตั้งแต่เดือนกรกฎาคม 2018 ถึงมิถุนายน 2019 ข้อมูลเมตาเพิ่มเติมเกี่ยวกับแต่ละอนุกรมเวลาในรูปแบบของตัวแปรหมวดหมู่คงที่จะถูกป้อนเข้าสู่โมเดลผ่านการฝัง ก่อนป้อนเข้าชั้นหม้อแปลง เราฝึก Transformer ด้วยการเริ่มต้นน้ำหนักแบบสุ่มที่แตกต่างกันห้าแบบ และค่าเฉลี่ยผลการคาดการณ์จากสามยุคสุดท้ายสำหรับการรันแต่ละครั้ง รวมทั้งหมด 15 รุ่นโดยเฉลี่ย การฝึกวิ่งแบบจำลองทั้งห้าแบบสามารถขนานกันเพื่อลดเวลาการฝึก สำหรับ Transformer ที่สวมหน้ากาก เราระบุเดือนตั้งแต่เดือนเมษายนถึงพฤษภาคม 2020 เป็นค่าผิดปกติ
สำหรับการฝึกแบบจำลองการคาดการณ์ทั้งหมด เราเปิดใช้งาน HPO อัตโนมัติ ซึ่งสามารถเลือกแบบจำลองและพารามิเตอร์การฝึกตามระยะเวลาการทดสอบย้อนหลังที่ผู้ใช้กำหนด ซึ่งตั้งค่าเป็น 12 เดือนที่ผ่านมาในหน้าต่างข้อมูลที่ใช้สำหรับการฝึกและ HPO
ผลการทดลอง
เราฝึก Transformers ที่สวมหน้ากากและเปิดโปงโดยใช้ไฮเปอร์พารามิเตอร์ชุดเดียวกัน และเปรียบเทียบประสิทธิภาพสำหรับหน้าต่างทดสอบย้อนหลังทันทีหลังจากเกิดภาวะช็อกจากโควิด-19 ใน Transformer ที่สวมหน้ากาก สองเดือนที่สวมหน้ากากคือเดือนเมษายนและพฤษภาคม 2020 ตารางต่อไปนี้แสดงผลจากช่วงการทดสอบย้อนหลังที่มีหน้าต่างพยากรณ์ 12 เดือนเริ่มตั้งแต่เดือนมิถุนายน 2020 เราสามารถสังเกตได้ว่า Transformer ที่สวมหน้ากากนั้นมีประสิทธิภาพเหนือกว่าเวอร์ชันที่ไม่ได้ปิดบังอย่างสม่ำเสมอ .

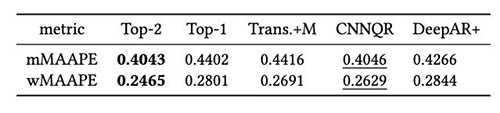
เราทำการประเมินเพิ่มเติมเกี่ยวกับกลยุทธ์ชุดโมเดลตามผลการทดสอบย้อนหลัง โดยเฉพาะอย่างยิ่ง เราเปรียบเทียบทั้งสองกรณีเมื่อเลือกเฉพาะแบบจำลองที่มีประสิทธิภาพสูงสุด เทียบกับเมื่อเลือกแบบจำลองที่มีประสิทธิภาพสูงสุด XNUMX อันดับแรก และการหาค่าเฉลี่ยแบบจำลองจะดำเนินการโดยการคำนวณค่าเฉลี่ยของการคาดการณ์ เราเปรียบเทียบประสิทธิภาพของรุ่นพื้นฐานและรุ่นทั้งมวลในรูปต่อไปนี้ สังเกตว่าไม่มีนักพยากรณ์ประสาทรายใดทำงานได้ดีกว่าคนอื่น ๆ อย่างสม่ำเสมอสำหรับหน้าต่างการทดสอบย้อนกลับ


ตารางต่อไปนี้แสดงให้เห็นว่าโดยเฉลี่ยแล้ว การสร้างแบบจำลองทั้งมวลของสองรุ่นยอดนิยมนั้นให้ประสิทธิภาพที่ดีที่สุด CNNQR ให้ผลลัพธ์ที่ดีที่สุดเป็นอันดับสอง
สรุป
โพสต์นี้สาธิตวิธีสร้างโซลูชัน ML แบบ end-to-end สำหรับปัญหาการคาดการณ์ขนาดใหญ่ที่รวมการพยากรณ์และโมเดลแบบกำหนดเองที่ได้รับการฝึกฝนบน SageMaker ขึ้นอยู่กับความต้องการทางธุรกิจและความรู้ ML ของคุณ คุณสามารถใช้บริการที่มีการจัดการเต็มรูปแบบ เช่น การคาดการณ์ เพื่อออฟโหลดกระบวนการสร้าง ฝึกฝน และปรับใช้โมเดลการคาดการณ์ สร้างโมเดลแบบกำหนดเองของคุณด้วยกลไกการปรับแต่งเฉพาะด้วย SageMaker หรือประกอบโมเดลโดยการรวมสองบริการเข้าด้วยกัน
หากคุณต้องการความช่วยเหลือในการเร่งการใช้ ML ในผลิตภัณฑ์และบริการของคุณ โปรดติดต่อ ห้องปฏิบัติการโซลูชัน Amazon ML โครงการ
อ้างอิง
Hyndman RJ, Athanasopoulos G. การพยากรณ์: หลักการและการปฏิบัติ OTข้อความ; 2018 8 พฤษภาคม
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. ความสนใจคือสิ่งที่คุณต้องการ ความก้าวหน้าในระบบประมวลผลข้อมูลประสาท 2017;30.
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Informer: นอกเหนือจากหม้อแปลงที่มีประสิทธิภาพสำหรับการพยากรณ์อนุกรมเวลาแบบยาว InProceedings ของ AAAI 2021 2 ก.พ.
เกี่ยวกับผู้เขียน
 ก็อกตุก ซินาร์ เป็นนักวิทยาศาสตร์ ML ชั้นนำและหัวหน้าด้านเทคนิคของ ML และการคาดการณ์ตามสถิติที่ Robert Bosch LLC และ Bosch Center for Artificial Intelligence เขาเป็นผู้นำในการวิจัยแบบจำลองการคาดการณ์ การรวมลำดับชั้น และเทคนิคการผสมผสานแบบจำลอง ตลอดจนทีมพัฒนาซอฟต์แวร์ที่ปรับขนาดแบบจำลองเหล่านี้และให้บริการโดยเป็นส่วนหนึ่งของซอฟต์แวร์การคาดการณ์ทางการเงินแบบ end-to-end ภายใน
ก็อกตุก ซินาร์ เป็นนักวิทยาศาสตร์ ML ชั้นนำและหัวหน้าด้านเทคนิคของ ML และการคาดการณ์ตามสถิติที่ Robert Bosch LLC และ Bosch Center for Artificial Intelligence เขาเป็นผู้นำในการวิจัยแบบจำลองการคาดการณ์ การรวมลำดับชั้น และเทคนิคการผสมผสานแบบจำลอง ตลอดจนทีมพัฒนาซอฟต์แวร์ที่ปรับขนาดแบบจำลองเหล่านี้และให้บริการโดยเป็นส่วนหนึ่งของซอฟต์แวร์การคาดการณ์ทางการเงินแบบ end-to-end ภายใน
 ไมเคิล บินเดอร์ เป็นเจ้าของผลิตภัณฑ์ที่ Bosch Global Services ซึ่งเขาประสานงานด้านการพัฒนา การปรับใช้ และการปรับใช้แอปพลิเคชันการวิเคราะห์เชิงคาดการณ์ทั่วทั้งบริษัทสำหรับข้อมูลอัตโนมัติขนาดใหญ่ที่ขับเคลื่อนการคาดการณ์ตัวเลขสำคัญทางการเงิน
ไมเคิล บินเดอร์ เป็นเจ้าของผลิตภัณฑ์ที่ Bosch Global Services ซึ่งเขาประสานงานด้านการพัฒนา การปรับใช้ และการปรับใช้แอปพลิเคชันการวิเคราะห์เชิงคาดการณ์ทั่วทั้งบริษัทสำหรับข้อมูลอัตโนมัติขนาดใหญ่ที่ขับเคลื่อนการคาดการณ์ตัวเลขสำคัญทางการเงิน
 เอเดรียน ฮอร์วาธ เป็นนักพัฒนาซอฟต์แวร์ที่ศูนย์ปัญญาประดิษฐ์ของ Bosch ซึ่งเขาพัฒนาและดูแลระบบเพื่อสร้างการคาดการณ์ตามแบบจำลองการคาดการณ์ต่างๆ
เอเดรียน ฮอร์วาธ เป็นนักพัฒนาซอฟต์แวร์ที่ศูนย์ปัญญาประดิษฐ์ของ Bosch ซึ่งเขาพัฒนาและดูแลระบบเพื่อสร้างการคาดการณ์ตามแบบจำลองการคาดการณ์ต่างๆ
 ปันปันซู เป็นนักวิทยาศาสตร์ประยุกต์อาวุโสและผู้จัดการของ Amazon ML Solutions Lab ที่ AWS เธอกำลังทำงานเกี่ยวกับการวิจัยและพัฒนาอัลกอริธึมการเรียนรู้ของเครื่องสำหรับแอปพลิเคชันของลูกค้าที่มีผลกระทบสูงในแนวดิ่งทางอุตสาหกรรมที่หลากหลายเพื่อเร่งการนำ AI และระบบคลาวด์ไปใช้ ความสนใจในงานวิจัยของเธอรวมถึงความสามารถในการตีความแบบจำลอง การวิเคราะห์เชิงสาเหตุ AI แบบมนุษย์ในวง และการแสดงภาพข้อมูลเชิงโต้ตอบ
ปันปันซู เป็นนักวิทยาศาสตร์ประยุกต์อาวุโสและผู้จัดการของ Amazon ML Solutions Lab ที่ AWS เธอกำลังทำงานเกี่ยวกับการวิจัยและพัฒนาอัลกอริธึมการเรียนรู้ของเครื่องสำหรับแอปพลิเคชันของลูกค้าที่มีผลกระทบสูงในแนวดิ่งทางอุตสาหกรรมที่หลากหลายเพื่อเร่งการนำ AI และระบบคลาวด์ไปใช้ ความสนใจในงานวิจัยของเธอรวมถึงความสามารถในการตีความแบบจำลอง การวิเคราะห์เชิงสาเหตุ AI แบบมนุษย์ในวง และการแสดงภาพข้อมูลเชิงโต้ตอบ
 จัสลีน กรีวาล เป็นนักวิทยาศาสตร์ประยุกต์ที่ Amazon Web Services ซึ่งเธอทำงานร่วมกับลูกค้าของ AWS เพื่อแก้ปัญหาในโลกแห่งความเป็นจริงโดยใช้การเรียนรู้ของเครื่อง โดยมุ่งเน้นที่ยาที่แม่นยำและจีโนมเป็นพิเศษ เธอมีพื้นฐานที่แข็งแกร่งในด้านชีวสารสนเทศ เนื้องอก และจีโนมทางคลินิก เธอหลงใหลในการใช้บริการ AI/ML และบริการคลาวด์เพื่อปรับปรุงการดูแลผู้ป่วย
จัสลีน กรีวาล เป็นนักวิทยาศาสตร์ประยุกต์ที่ Amazon Web Services ซึ่งเธอทำงานร่วมกับลูกค้าของ AWS เพื่อแก้ปัญหาในโลกแห่งความเป็นจริงโดยใช้การเรียนรู้ของเครื่อง โดยมุ่งเน้นที่ยาที่แม่นยำและจีโนมเป็นพิเศษ เธอมีพื้นฐานที่แข็งแกร่งในด้านชีวสารสนเทศ เนื้องอก และจีโนมทางคลินิก เธอหลงใหลในการใช้บริการ AI/ML และบริการคลาวด์เพื่อปรับปรุงการดูแลผู้ป่วย
 เซลวาน เซนธิเวล เป็นวิศวกร ML อาวุโสของ Amazon ML Solutions Lab ที่ AWS โดยมุ่งเน้นที่การช่วยเหลือลูกค้าเกี่ยวกับแมชชีนเลิร์นนิง ปัญหาการเรียนรู้เชิงลึก และโซลูชัน ML แบบครบวงจร เขาเป็นหัวหน้าฝ่ายวิศวกรรมผู้ก่อตั้งของ Amazon Comprehend Medical และมีส่วนในการออกแบบและสถาปัตยกรรมของบริการ AWS AI ที่หลากหลาย
เซลวาน เซนธิเวล เป็นวิศวกร ML อาวุโสของ Amazon ML Solutions Lab ที่ AWS โดยมุ่งเน้นที่การช่วยเหลือลูกค้าเกี่ยวกับแมชชีนเลิร์นนิง ปัญหาการเรียนรู้เชิงลึก และโซลูชัน ML แบบครบวงจร เขาเป็นหัวหน้าฝ่ายวิศวกรรมผู้ก่อตั้งของ Amazon Comprehend Medical และมีส่วนในการออกแบบและสถาปัตยกรรมของบริการ AWS AI ที่หลากหลาย
 รุ่ยหลิน จาง เป็น SDE กับ Amazon ML Solutions Lab ที่ AWS เขาช่วยลูกค้านำบริการ AWS AI มาใช้โดยการสร้างโซลูชันเพื่อแก้ไขปัญหาทางธุรกิจทั่วไป
รุ่ยหลิน จาง เป็น SDE กับ Amazon ML Solutions Lab ที่ AWS เขาช่วยลูกค้านำบริการ AWS AI มาใช้โดยการสร้างโซลูชันเพื่อแก้ไขปัญหาทางธุรกิจทั่วไป
 เชน ราย เป็น Sr. ML Strategist กับ Amazon ML Solutions Lab ที่ AWS เขาทำงานร่วมกับลูกค้าในอุตสาหกรรมที่หลากหลายเพื่อแก้ไขความต้องการทางธุรกิจที่เร่งด่วนและเป็นนวัตกรรมใหม่โดยใช้บริการ AI/ML บนคลาวด์ของ AWS
เชน ราย เป็น Sr. ML Strategist กับ Amazon ML Solutions Lab ที่ AWS เขาทำงานร่วมกับลูกค้าในอุตสาหกรรมที่หลากหลายเพื่อแก้ไขความต้องการทางธุรกิจที่เร่งด่วนและเป็นนวัตกรรมใหม่โดยใช้บริการ AI/ML บนคลาวด์ของ AWS
 หลิน ลี ชอง เป็นผู้จัดการวิทยาศาสตร์ประยุกต์กับทีม Amazon ML Solutions Lab ที่ AWS เธอทำงานร่วมกับลูกค้า AWS เชิงกลยุทธ์เพื่อสำรวจและใช้ปัญญาประดิษฐ์และแมชชีนเลิร์นนิงเพื่อค้นหาข้อมูลเชิงลึกใหม่ๆ และแก้ปัญหาที่ซับซ้อน
หลิน ลี ชอง เป็นผู้จัดการวิทยาศาสตร์ประยุกต์กับทีม Amazon ML Solutions Lab ที่ AWS เธอทำงานร่วมกับลูกค้า AWS เชิงกลยุทธ์เพื่อสำรวจและใช้ปัญญาประดิษฐ์และแมชชีนเลิร์นนิงเพื่อค้นหาข้อมูลเชิงลึกใหม่ๆ และแก้ปัญหาที่ซับซ้อน