
บทนำ
ปัญญาประดิษฐ์ (AI) มีความก้าวหน้าอย่างมากในอุตสาหกรรมต่างๆ และการดูแลสุขภาพก็ไม่มีข้อยกเว้น หนึ่งในพื้นที่ที่มีแนวโน้มมากที่สุดใน AI ในการดูแลสุขภาพคือการประมวลผลภาษาธรรมชาติ (NLP) ซึ่งมีศักยภาพในการปฏิวัติการดูแลผู้ป่วยโดยอำนวยความสะดวกในการวิเคราะห์ข้อมูลและการสื่อสารที่มีประสิทธิภาพและแม่นยำยิ่งขึ้น
NLP ได้รับการพิสูจน์แล้วว่าเป็นตัวเปลี่ยนเกมในด้านการดูแลสุขภาพ NLP กำลังเปลี่ยนวิธีที่ผู้ให้บริการด้านการแพทย์ให้การดูแลผู้ป่วย ตั้งแต่การจัดการด้านสุขภาพของประชากรไปจนถึงการตรวจหาโรค NLP ช่วยให้บุคลากรทางการแพทย์ตัดสินใจอย่างมีข้อมูลและให้ผลการรักษาที่ดีขึ้น
วัตถุประสงค์การเรียนรู้
- ทำความเข้าใจและวิเคราะห์การใช้ NLP และ AI ในการดูแลสุขภาพ
- เข้าใจพื้นฐานของ NLP
- ทำความรู้จักกับไลบรารี NLP ที่ใช้กันทั่วไปในการดูแลสุขภาพ
- เรียนรู้เกี่ยวกับกรณีการใช้ NLP ในการดูแลสุขภาพ
บทความนี้เผยแพร่โดยเป็นส่วนหนึ่งของไฟล์ Blogathon วิทยาศาสตร์ข้อมูล.
สารบัญ
- แรงจูงใจในการใช้ AI & NLP ในการดูแลสุขภาพ
- การประมวลผลภาษาธรรมชาติคืออะไร?
- เทคนิคต่างๆ ที่ใช้ใน NLP
3.1 เทคนิคตามกฎ
3.2 เทคนิคทางสถิติโดยใช้โมเดลการเรียนรู้ของเครื่อง
3.3 โอนการเรียนรู้ - ไลบรารี NLP ต่างๆ และกรอบการทำงาน
- โมเดลภาษาขนาดใหญ่ (LLM) คืออะไร
- NLP ในข้อความทางคลินิก - ความต้องการแนวทางที่แตกต่างกัน
- ไลบรารี NLP บางส่วนที่ใช้ในอุตสาหกรรมการดูแลสุขภาพ
- ทำความเข้าใจกับชุดข้อมูลทางคลินิก
- ข้อมูลทางคลินิกประเภทต่างๆ มีอะไรบ้าง
- กรณีการใช้งานและการประยุกต์ใช้ NLP ในอุตสาหกรรมการดูแลสุขภาพ
- จะสร้าง NLP Pipeline ด้วย Clinical Text ได้อย่างไร?
11.1 การออกแบบโซลูชัน
11.2 รหัสทีละขั้นตอน - สรุป
แรงจูงใจในการใช้ AI & NLP ในการดูแลสุขภาพ
แรงจูงใจในการใช้ AI และ NLP ในการดูแลสุขภาพมีรากฐานมาจากการปรับปรุงการดูแลผู้ป่วยและผลการรักษาในขณะที่ลดค่าใช้จ่ายด้านการรักษาพยาบาล อุตสาหกรรมการดูแลสุขภาพสร้างข้อมูลจำนวนมหาศาล รวมถึง EMR บันทึกทางคลินิก และโพสต์บนโซเชียลมีเดียที่เกี่ยวข้องกับสุขภาพ ซึ่งสามารถให้ข้อมูลเชิงลึกที่มีคุณค่าเกี่ยวกับสุขภาพของผู้ป่วยและผลการรักษา อย่างไรก็ตาม ข้อมูลเหล่านี้ส่วนใหญ่ไม่มีโครงสร้างและยากต่อการวิเคราะห์ด้วยตนเอง
นอกจากนี้ อุตสาหกรรมการดูแลสุขภาพยังเผชิญกับความท้าทายหลายประการ เช่น ประชากรสูงอายุ อัตราการเกิดโรคเรื้อรังที่เพิ่มขึ้น และการขาดแคลนบุคลากรทางการแพทย์
ความท้าทายเหล่านี้นำไปสู่ความต้องการที่เพิ่มขึ้นสำหรับการให้บริการด้านสุขภาพที่มีประสิทธิภาพและประสิทธิผลมากขึ้น
ด้วยการให้ข้อมูลเชิงลึกที่มีค่าจากข้อมูลทางการแพทย์ที่ไม่มีโครงสร้าง NLP สามารถช่วยปรับปรุงการดูแลผู้ป่วยและผลการรักษา และสนับสนุนบุคลากรทางการแพทย์ในการตัดสินใจทางคลินิกที่มีข้อมูลมากขึ้น
การประมวลผลภาษาธรรมชาติคืออะไร?
การประมวลผลภาษาธรรมชาติ (NLP) เป็นสาขาย่อยของปัญญาประดิษฐ์ (AI) ที่เกี่ยวข้องกับการโต้ตอบระหว่างคอมพิวเตอร์และภาษามนุษย์ ใช้เทคนิคการคำนวณเพื่อวิเคราะห์ ทำความเข้าใจ และสร้างภาษามนุษย์ NLP ถูกนำไปใช้ในหลายๆ แอปพลิเคชัน รวมถึงการรู้จำเสียง การแปลด้วยคอมพิวเตอร์ การวิเคราะห์ความรู้สึก และการสรุปข้อความ
ตอนนี้เราจะสำรวจเทคนิค NLP ไลบรารีและเฟรมเวิร์กต่างๆ
เทคนิคต่างๆ ที่ใช้ใน NLP
มีสองเทคนิคที่ใช้กันทั่วไปในอุตสาหกรรม NLP
1. เทคนิคตามกฎ: ใช้กฎไวยากรณ์และพจนานุกรมที่กำหนดไว้ล่วงหน้า
2. เทคนิคทางสถิติ: ใช้อัลกอริธึมการเรียนรู้ของเครื่องเพื่อวิเคราะห์และทำความเข้าใจภาษา
3. ใช้โมเดลภาษาขนาดใหญ่ ถ่ายทอดการเรียนรู้
นี่คือ NLP Pipeline มาตรฐานที่มีงาน NLP ต่างๆ
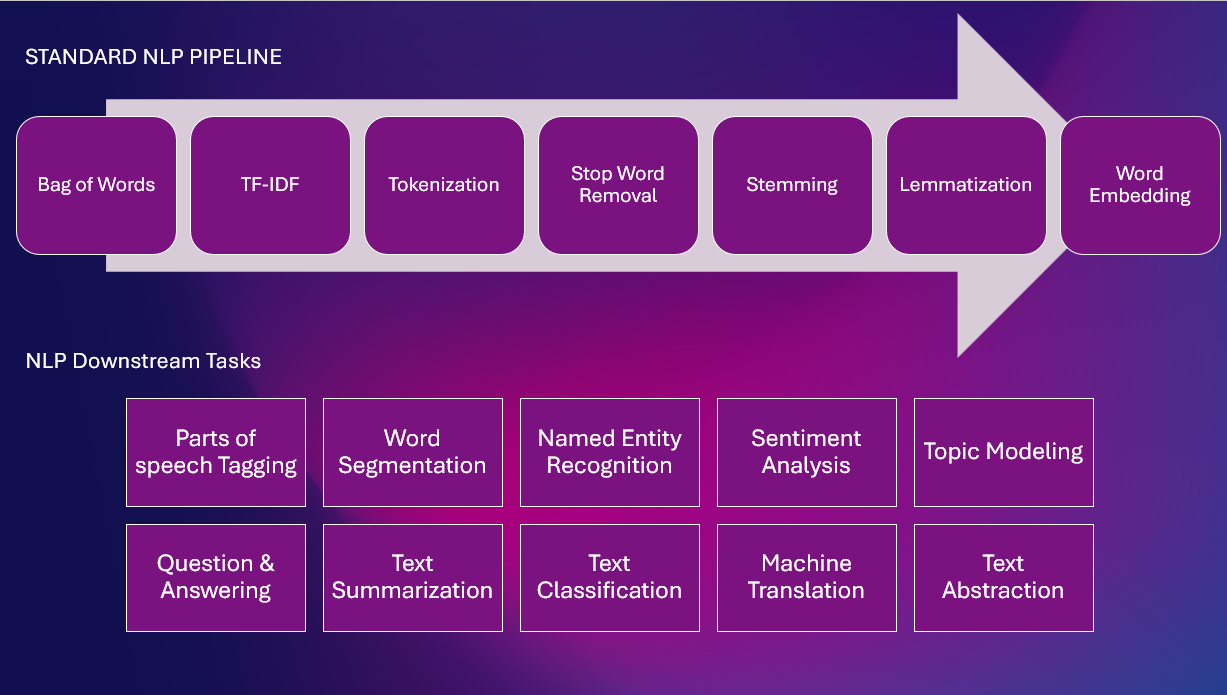
เทคนิคตามกฎ
เทคนิคเหล่านี้เกี่ยวข้องกับการสร้างชุดกฎหรือรูปแบบที่สร้างขึ้นด้วยมือเพื่อดึงข้อมูลที่มีความหมายจากข้อความ โดยทั่วไปแล้ว ระบบตามกฎจะทำงานโดยกำหนดรูปแบบเฉพาะที่ตรงกับข้อมูลเป้าหมาย เช่น เอนทิตีที่มีชื่อหรือคำหลักเฉพาะ แล้วแยกข้อมูลนั้นตามรูปแบบเหล่านั้น ระบบตามกฎ มีความรวดเร็ว เชื่อถือได้ และตรงไปตรงมา แต่จะถูกจำกัดด้วยคุณภาพและจำนวนของกฎที่กำหนดไว้ และอาจเป็นเรื่องยากที่จะรักษาและอัปเดต
ตัวอย่างเช่น ระบบตามกฎสำหรับการรับรู้เอนทิตีที่มีชื่อสามารถออกแบบมาเพื่อระบุคำนามที่เหมาะสมในข้อความและจัดหมวดหมู่เป็นประเภทเอนทิตีที่กำหนดไว้ล่วงหน้า เช่น บุคคล สถานที่ องค์กร โรคภัยไข้เจ็บ ยา ฯลฯ ระบบจะใช้ชุด ของกฎเพื่อระบุรูปแบบในข้อความที่ตรงกับเกณฑ์สำหรับเอนทิตีแต่ละประเภท เช่น การใช้อักษรตัวพิมพ์ใหญ่สำหรับชื่อบุคคลหรือคำหลักเฉพาะสำหรับองค์กร
เทคนิคทางสถิติโดยใช้โมเดลการเรียนรู้ของเครื่อง
เทคนิคเหล่านี้ใช้อัลกอริธึมทางสถิติเพื่อเรียนรู้รูปแบบในข้อมูลและคาดการณ์ตามรูปแบบเหล่านั้น โมเดลแมชชีนเลิร์นนิงสามารถฝึกฝนกับข้อมูลที่มีคำอธิบายประกอบจำนวนมากได้ ทำให้มีความยืดหยุ่นและปรับขนาดได้มากกว่าระบบตามกฎ โมเดลแมชชีนเลิร์นนิงหลายประเภทใช้ใน NLP รวมถึง ต้นไม้ตัดสินใจ, ป่าสุ่ม, สนับสนุนเครื่องเวกเตอร์และ เครือข่ายประสาทเทียม.
ตัวอย่างเช่น โมเดลแมชชีนเลิร์นนิงสำหรับการวิเคราะห์ความรู้สึกอาจได้รับการฝึกฝนในคลังข้อมูลขนาดใหญ่ของข้อความที่มีคำอธิบายประกอบ โดยที่แต่ละข้อความจะถูกแท็กเป็นบวก ลบ หรือเป็นกลาง แบบจำลองจะเรียนรู้รูปแบบทางสถิติในข้อมูลที่แยกความแตกต่างระหว่างข้อความเชิงบวกและเชิงลบ จากนั้นใช้รูปแบบเหล่านั้นเพื่อคาดการณ์ข้อความใหม่ที่มองไม่เห็น ข้อดีของแนวทางนี้คือ โมเดลสามารถเรียนรู้ที่จะระบุรูปแบบความรู้สึกที่ไม่ได้กำหนดไว้อย่างชัดเจนในกฎ
ถ่ายทอดการเรียนรู้
เทคนิคเหล่านี้เป็นวิธีการแบบผสมผสานที่รวมจุดแข็งของโมเดลตามกฎและการเรียนรู้ของเครื่อง การเรียนรู้การถ่ายโอนใช้โมเดลแมชชีนเลิร์นนิงที่ฝึกไว้ล่วงหน้า เช่น โมเดลภาษาที่ฝึกในคลังข้อความขนาดใหญ่ เป็นจุดเริ่มต้นสำหรับการปรับแต่งงานหรือโดเมนเฉพาะอย่างละเอียด แนวทางนี้ใช้ประโยชน์จากความรู้ทั่วไปที่ได้เรียนรู้จากโมเดลที่ได้รับการฝึกอบรมล่วงหน้า ลดปริมาณข้อมูลฉลากที่จำเป็นสำหรับการฝึกอบรม และช่วยให้สามารถคาดการณ์งานที่เฉพาะเจาะจงได้รวดเร็วและแม่นยำยิ่งขึ้น
ตัวอย่างเช่น วิธีการโอนการเรียนรู้ไปยังการจดจำเอนทิตีที่มีชื่อสามารถปรับแต่งรูปแบบภาษาที่ได้รับการฝึกอบรมล่วงหน้าในคลังข้อมูลขนาดเล็กของข้อความทางการแพทย์ที่มีคำอธิบายประกอบ แบบจำลองจะเริ่มต้นด้วยความรู้ทั่วไปที่ได้เรียนรู้จากแบบจำลองที่ผ่านการฝึกอบรมมาแล้ว จากนั้นจึงปรับน้ำหนักให้ตรงกับรูปแบบข้อความทางการแพทย์มากขึ้น วิธีนี้จะลดปริมาณข้อมูลที่ติดฉลากซึ่งจำเป็นสำหรับการฝึกอบรมและส่งผลให้มีแบบจำลองที่แม่นยำยิ่งขึ้นสำหรับการจดจำเอนทิตีที่มีชื่อในโดเมนทางการแพทย์
ไลบรารี NLP ต่างๆ และกรอบการทำงาน
ห้องสมุดต่างๆ มีฟังก์ชัน NLP ที่หลากหลาย เช่น :

ไลบรารีและเฟรมเวิร์กการประมวลผลภาษาธรรมชาติ (NLP) เป็นเครื่องมือซอฟต์แวร์ที่ช่วยพัฒนาและปรับใช้แอปพลิเคชัน NLP มีไลบรารีและเฟรมเวิร์กของ NLP มากมาย แต่ละอันมีจุดแข็ง จุดอ่อน และจุดเน้น
เครื่องมือเหล่านี้แตกต่างกันไปในแง่ของความซับซ้อนของอัลกอริทึมที่รองรับ ขนาดของโมเดลที่สามารถจัดการได้ ความสะดวกในการใช้งาน และระดับการปรับแต่งที่อนุญาต
โมเดลภาษาขนาดใหญ่ (LLM) คืออะไร
โมเดลภาษาขนาดใหญ่ได้รับการฝึกฝนบนข้อมูลจำนวนมหาศาล สามารถสร้างข้อความเหมือนมนุษย์และทำงาน NLP ได้หลากหลายด้วยความแม่นยำสูง
ต่อไปนี้คือตัวอย่างบางส่วนของโมเดลภาษาขนาดใหญ่และคำอธิบายโดยย่อของแต่ละโมเดล:
จีพีที-3 (หม้อแปลงสำเร็จรูปเจเนอเรทีฟ 3): พัฒนาโดย OpenAI, GPT-3 เป็นโมเดลภาษาแบบทรานส์ฟอร์มเมอร์ขนาดใหญ่ที่ใช้อัลกอริทึมการเรียนรู้เชิงลึกเพื่อสร้างข้อความที่เหมือนมนุษย์ ได้รับการฝึกอบรมเกี่ยวกับคลังข้อมูลข้อความจำนวนมหาศาล ทำให้สามารถสร้างการตอบกลับข้อความที่เหมาะสมตามบริบทโดยอิงจากข้อความแจ้ง
BERT (การแทนตัวเข้ารหัสแบบสองทิศทางจาก Transformers): BERT พัฒนาโดย Google เป็นโมเดลภาษาที่ใช้การแปลงข้อมูลซึ่งได้รับการฝึกอบรมล่วงหน้าจากคลังข้อมูลข้อความขนาดใหญ่ ได้รับการออกแบบมาให้ทำงานได้ดีกับงาน NLP ที่หลากหลาย เช่น การจดจำเอนทิตีที่มีชื่อ การตอบคำถาม และการจัดประเภทข้อความ โดยการเข้ารหัสบริบทและความสัมพันธ์ระหว่างคำในประโยค
โรเบอร์ต้า (แนวทาง BERT ที่ปรับให้เหมาะสมอย่างแข็งแกร่ง): พัฒนาโดย Facebook AI, RoBERTa เป็นรูปแบบหนึ่งของ BERT ที่ได้รับการปรับแต่งและปรับให้เหมาะสมสำหรับงาน NLP ได้รับการฝึกอบรมเกี่ยวกับคลังข้อมูลข้อความขนาดใหญ่และใช้กลยุทธ์การฝึกอบรมที่แตกต่างจาก BERT ซึ่งนำไปสู่การปรับปรุงประสิทธิภาพในเกณฑ์มาตรฐาน NLP
ELMo (การฝังตัวจากโมเดลภาษา): พัฒนาโดย Allen Institute for AI ELMo เป็นโมเดลการแสดงคำตามบริบทเชิงลึกที่ใช้เครือข่าย LSTM (Long Short-Term Memory) แบบสองทิศทางเพื่อเรียนรู้การแสดงภาษาจากคลังข้อมูลข้อความขนาดใหญ่ ELMo สามารถปรับอย่างละเอียดสำหรับงาน NLP เฉพาะ หรือใช้เป็นตัวแยกฟีเจอร์สำหรับโมเดลการเรียนรู้ของเครื่องอื่นๆ
ULMFiT (การปรับแต่งโมเดลภาษาสากล): ULMFiT พัฒนาโดย FastAI เป็นวิธีการเรียนรู้การถ่ายโอนที่ปรับแต่งโมเดลภาษาที่ได้รับการฝึกฝนล่วงหน้าอย่างละเอียดในงาน NLP เฉพาะโดยใช้ข้อมูลที่มีคำอธิบายประกอบเฉพาะงานจำนวนเล็กน้อย ULMFiT ประสบความสำเร็จในประสิทธิภาพอันล้ำสมัยจากการวัดประสิทธิภาพ NLP ที่หลากหลาย และถือเป็นตัวอย่างชั้นนำของการเรียนรู้การถ่ายโอนใน NLP
NLP ในข้อความทางคลินิก: ความต้องการแนวทางที่แตกต่างกัน
ข้อความทางคลินิกมักไม่มีโครงสร้างและมีศัพท์แสงทางการแพทย์และคำย่อจำนวนมาก ทำให้โมเดล NLP แบบดั้งเดิมเข้าใจและประมวลผลได้ยาก นอกจากนี้ ข้อความทางคลินิกมักประกอบด้วยข้อมูลสำคัญ เช่น โรค ยา ข้อมูลผู้ป่วย การวินิจฉัย และแผนการรักษา ซึ่งต้องใช้แบบจำลองเฉพาะของ NLP ที่สามารถแยกและทำความเข้าใจข้อมูลทางการแพทย์นี้ได้อย่างถูกต้อง
อีกเหตุผลหนึ่งข้อความทางคลินิกต้องการแบบจำลอง NLP ที่แตกต่างกัน คือมีข้อมูลจำนวนมากกระจายไปตามแหล่งต่างๆ เช่น EHR บันทึกทางคลินิก และรายงานรังสีวิทยา ซึ่งจำเป็นต้องรวมเข้าด้วยกัน สิ่งนี้ต้องการแบบจำลองที่สามารถประมวลผลและเข้าใจข้อความและเชื่อมโยงและรวมข้อมูลในแหล่งต่าง ๆ และสร้างความสัมพันธ์ที่ยอมรับได้ทางคลินิก
ประการสุดท้าย ข้อความทางคลินิกมักประกอบด้วยข้อมูลผู้ป่วยที่ละเอียดอ่อนและจำเป็นต้องได้รับการคุ้มครองตามกฎระเบียบที่เข้มงวด เช่น HIPAA แบบจำลอง NLP ที่ใช้ในการประมวลผลข้อความทางคลินิกต้องสามารถระบุและปกป้องข้อมูลที่สำคัญของผู้ป่วยได้ ในขณะที่ยังคงให้ข้อมูลเชิงลึกที่เป็นประโยชน์
ไลบรารี NLP บางส่วนที่ใช้ในอุตสาหกรรมการดูแลสุขภาพ
ข้อมูลที่เป็นข้อความภายในยาต้องการระบบการประมวลผลภาษาธรรมชาติ (NLP) เฉพาะที่สามารถดึงข้อมูลทางการแพทย์จากแหล่งต่างๆ เช่น ข้อความทางคลินิกและเอกสารทางการแพทย์อื่นๆ
นี่คือรายการไลบรารีและโมเดล NLP เฉพาะสำหรับโดเมนทางการแพทย์:
สปาซี: เป็นไลบรารี NLP แบบโอเพ่นซอร์สที่ให้บริการโมเดลนอกกรอบสำหรับโดเมนต่างๆ รวมถึงโดเมนทางการแพทย์
ซิสป้าซี: SpaCy เวอร์ชันพิเศษที่ได้รับการฝึกอบรมโดยเฉพาะเกี่ยวกับข้อความทางวิทยาศาสตร์และชีวการแพทย์ ซึ่งทำให้เหมาะสำหรับการประมวลผลข้อความทางการแพทย์
ไบโอเบิร์ต: แบบจำลองที่ใช้หม้อแปลงที่ผ่านการฝึกอบรมล่วงหน้าซึ่งออกแบบมาโดยเฉพาะสำหรับโดเมนชีวการแพทย์ ได้รับการฝึกฝนล่วงหน้าด้วย Wiki + Books + PubMed + PMC
คลินิกBERT: อีกรูปแบบที่ผ่านการฝึกอบรมล่วงหน้าซึ่งออกแบบมาเพื่อประมวลผลบันทึกทางคลินิกและสรุปการจำหน่ายจากฐานข้อมูล MIMIC-III
เมด7: แบบจำลองที่ใช้หม้อแปลงไฟฟ้าที่ได้รับการฝึกอบรมเกี่ยวกับบันทึกสุขภาพอิเล็กทรอนิกส์ (EHR) เพื่อแยกแนวคิดทางคลินิกที่สำคัญ XNUMX ประการ รวมถึงการวินิจฉัย การใช้ยา และการทดสอบในห้องปฏิบัติการ
DisMod-ML: กรอบแบบจำลองความน่าจะเป็นสำหรับแบบจำลองโรคที่ใช้เทคนิค NLP เพื่อประมวลผลข้อความทางการแพทย์
แพทย์: ระบบ NLP ตามกฎสำหรับการดึงข้อมูลทางการแพทย์จากข้อความ
นี่คือไลบรารีและโมเดล NLP ยอดนิยมบางส่วนที่ออกแบบมาโดยเฉพาะสำหรับโดเมนทางการแพทย์ พวกเขาเสนอคุณสมบัติที่หลากหลายตั้งแต่แบบจำลองที่ได้รับการฝึกอบรมล่วงหน้าไปจนถึงระบบตามกฎ และสามารถช่วยองค์กรด้านการดูแลสุขภาพประมวลผลข้อความทางการแพทย์ได้อย่างมีประสิทธิภาพ
ในโมเดล NER ของเรา เราจะใช้ spaCy และ Scispacy ไลบรารีเหล่านี้ทำงานได้ค่อนข้างง่ายบน Google colab หรือโครงสร้างพื้นฐานในเครื่อง
โมเดลภาษาขนาดใหญ่ที่ใช้ทรัพยากรจำนวนมากของ BioBERT และ ClinicalBERT ต้องการ GPU และโครงสร้างพื้นฐานที่สูงขึ้น
ทำความเข้าใจกับชุดข้อมูลทางคลินิก
ข้อมูลทางการแพทย์สามารถหาได้จากแหล่งต่างๆ เช่น บันทึกสุขภาพอิเล็กทรอนิกส์ (EHR) วารสารทางการแพทย์ บันทึกทางคลินิก เว็บไซต์ทางการแพทย์ และฐานข้อมูล แหล่งที่มาเหล่านี้บางส่วนมีชุดข้อมูลที่เปิดเผยต่อสาธารณะซึ่งสามารถใช้สำหรับการฝึกอบรมโมเดล NLP ในขณะที่แหล่งข้อมูลอื่นอาจต้องได้รับการอนุมัติและการพิจารณาด้านจริยธรรมก่อนที่จะเข้าถึงข้อมูล แหล่งที่มาของข้อมูลข้อความทางการแพทย์ ได้แก่ :
1. องค์กรทางการแพทย์แบบโอเพ่นซอร์สเช่น ฐานข้อมูล MIMIC-III เป็นฐานข้อมูลบันทึกสุขภาพอิเล็กทรอนิกส์ (EHR) ขนาดใหญ่ที่สามารถเข้าถึงได้อย่างเปิดเผยจากผู้ป่วยที่ได้รับการดูแลที่ศูนย์การแพทย์เบธ อิสราเอล ดีคอนเนส ระหว่างปี 2001 ถึง 2012 ฐานข้อมูลประกอบด้วยข้อมูลต่างๆ เช่น ข้อมูลประชากรของผู้ป่วย สัญญาณชีพ การทดสอบในห้องปฏิบัติการ ยา วิธีการทำหัตถการ และ บันทึกจากบุคลากรทางการแพทย์ เช่น พยาบาลและแพทย์ นอกจากนี้ ฐานข้อมูลยังมีข้อมูลเกี่ยวกับการเข้าพักในห้องไอซียูของผู้ป่วย รวมถึงประเภทของห้องไอซียู ระยะเวลาการเข้าพัก และผลลัพธ์ ข้อมูลใน MIMIC-III นั้นไม่ระบุตัวตนและสามารถใช้เพื่อวัตถุประสงค์ในการวิจัยเพื่อสนับสนุนการพัฒนาแบบจำลองการคาดการณ์และระบบสนับสนุนการตัดสินใจทางคลินิก
2. หอสมุดแพทยศาสตร์แห่งชาติ ClinicalTrials.gov เว็บไซต์มีข้อมูลการทดลองทางคลินิกและข้อมูลการเฝ้าระวังโรค
3. หอสมุดแพทยศาสตร์แห่งชาติของสถาบันสุขภาพแห่งชาติ ศูนย์ข้อมูลเทคโนโลยีชีวภาพแห่งชาติ (NCBI) และองค์การอนามัยโลก (WHO)
4. สถาบันและองค์กรด้านการดูแลสุขภาพ เช่น โรงพยาบาล คลินิก และบริษัทยาสร้างข้อมูลทางการแพทย์จำนวนมากผ่านบันทึกสุขภาพอิเล็กทรอนิกส์ บันทึกทางคลินิก การถอดความทางการแพทย์ และรายงานทางการแพทย์
5. วารสารและฐานข้อมูลการวิจัยทางการแพทย์ เช่น PubMed และ CINAHL มีบทความและบทคัดย่อการวิจัยทางการแพทย์ที่ตีพิมพ์จำนวนมาก
6. แพลตฟอร์มโซเชียลมีเดียเช่น Twitter สามารถให้ข้อมูลเชิงลึกแบบเรียลไทม์เกี่ยวกับมุมมองของผู้ป่วย การทบทวนยา และประสบการณ์
ในการฝึกโมเดล NLP โดยใช้ข้อมูลข้อความทางการแพทย์ สิ่งสำคัญคือต้องพิจารณาคุณภาพและความเกี่ยวข้องของข้อมูล และตรวจสอบให้แน่ใจว่าข้อมูลได้รับการประมวลผลล่วงหน้าและจัดรูปแบบอย่างเหมาะสม นอกจากนี้ สิ่งสำคัญคือต้องปฏิบัติตามข้อพิจารณาด้านจริยธรรมและกฎหมายเมื่อทำงานกับข้อมูลทางการแพทย์ที่ละเอียดอ่อน
ข้อมูลทางคลินิกประเภทต่างๆ มีอะไรบ้าง
ข้อมูลทางคลินิกหลายประเภทมักใช้ในการดูแลสุขภาพ:

ข้อมูลทางคลินิกหมายถึงข้อมูลเกี่ยวกับการรักษาพยาบาลของแต่ละบุคคล รวมถึงประวัติทางการแพทย์ของผู้ป่วย การวินิจฉัย การรักษา ผลการตรวจทางห้องปฏิบัติการ การศึกษาเกี่ยวกับภาพ และข้อมูลด้านสุขภาพอื่นๆ ที่เกี่ยวข้อง
ข้อมูล EHR/EMR เชื่อมโยงกับข้อมูลประชากร (ซึ่งรวมถึงข้อมูลส่วนบุคคล เช่น อายุ เพศ เชื้อชาติ และข้อมูลติดต่อ) ข้อมูลที่ผู้ป่วยสร้างขึ้น (ข้อมูลประเภทนี้สร้างขึ้นโดยผู้ป่วยเอง รวมถึงข้อมูลที่รวบรวมผ่านมาตรการผลลัพธ์ที่ผู้ป่วยรายงานและผู้ป่วย ข้อมูลสุขภาพ -generated.)
ข้อมูลชุดอื่นๆ ได้แก่
ข้อมูลจีโนม: ประเภทนี้เกี่ยวข้องกับข้อมูลทางพันธุกรรมของแต่ละบุคคล รวมถึงลำดับดีเอ็นเอและเครื่องหมาย
ข้อมูลอุปกรณ์สวมใส่: ข้อมูลนี้รวมถึงข้อมูลที่รวบรวมจากอุปกรณ์ที่สวมใส่ได้ เช่น ตัวติดตามฟิตเนสและเครื่องวัดอัตราการเต้นของหัวใจ
ข้อมูลทางคลินิกแต่ละประเภทมีบทบาทเฉพาะในการให้มุมมองที่ครอบคลุมเกี่ยวกับสุขภาพของผู้ป่วย และถูกใช้ในรูปแบบต่างๆ โดยผู้ให้บริการด้านการดูแลสุขภาพและนักวิจัยเพื่อปรับปรุงการดูแลผู้ป่วยและแจ้งการตัดสินใจในการรักษา
กรณีการใช้งานและการประยุกต์ใช้ NLP ในอุตสาหกรรมการดูแลสุขภาพ
การประมวลผลภาษาธรรมชาติ (NLP) ถูกนำมาใช้กันอย่างแพร่หลายในอุตสาหกรรมการดูแลสุขภาพและมีกรณีการใช้งานหลายกรณี บางส่วนของคนที่โดดเด่น ได้แก่ :
สุขภาพประชากร: NLP สามารถใช้ในการประมวลผลข้อมูลทางการแพทย์ที่ไม่มีโครงสร้างจำนวนมาก เช่น เวชระเบียน การสำรวจ และข้อมูลการเรียกร้องเพื่อระบุรูปแบบ ความสัมพันธ์ และข้อมูลเชิงลึก ซึ่งจะช่วยในการติดตามสุขภาพของประชากรและการตรวจหาโรคในระยะเริ่มต้น
ดูแลผู้ป่วย: สามารถใช้ NLP เพื่อประมวลผลบันทึกสุขภาพอิเล็กทรอนิกส์ (EHR) ของผู้ป่วยเพื่อดึงข้อมูลที่สำคัญ เช่น การวินิจฉัย ยา และอาการต่างๆ ข้อมูลนี้สามารถใช้เพื่อปรับปรุงการดูแลผู้ป่วยและให้การรักษาเฉพาะบุคคล
การตรวจหาโรค: NLP สามารถใช้ในการประมวลผลข้อมูลข้อความจำนวนมาก เช่น บทความทางวิทยาศาสตร์ บทความข่าว และโพสต์บนโซเชียลมีเดีย เพื่อตรวจหาการระบาดของโรคติดเชื้อ
ระบบสนับสนุนการตัดสินใจทางคลินิก (CDSS): สามารถใช้ NLP เพื่อวิเคราะห์บันทึกสุขภาพอิเล็กทรอนิกส์ของผู้ป่วยเพื่อให้การสนับสนุนการตัดสินใจแบบเรียลไทม์แก่ผู้ให้บริการด้านสุขภาพ สิ่งนี้ช่วยในการเสนอทางเลือกการรักษาที่ดีที่สุดและปรับปรุงคุณภาพการดูแลโดยรวม
การทดลองทางคลินิก: NLP สามารถประมวลผลข้อมูลการทดลองทางคลินิกเพื่อระบุความสัมพันธ์และการรักษาใหม่ที่เป็นไปได้
เหตุการณ์ไม่พึงประสงค์จากยา: NLP สามารถใช้ในการประมวลผลข้อมูลความปลอดภัยของยาจำนวนมากเพื่อระบุเหตุการณ์ไม่พึงประสงค์และปฏิกิริยาระหว่างยา
สุขภาพที่แม่นยำ: สามารถใช้ NLP เพื่อประมวลผลข้อมูลจีโนมและเวชระเบียนเพื่อระบุตัวเลือกการรักษาเฉพาะบุคคลสำหรับผู้ป่วยแต่ละราย
การปรับปรุงประสิทธิภาพของแพทย์ผู้เชี่ยวชาญ: NLP สามารถทำงานประจำโดยอัตโนมัติ เช่น การเข้ารหัสทางการแพทย์ การป้อนข้อมูล และการประมวลผลข้อเรียกร้อง ทำให้ผู้เชี่ยวชาญทางการแพทย์มีอิสระในการให้ความสำคัญกับการดูแลผู้ป่วยที่ดีขึ้น
นี่เป็นเพียงตัวอย่างเล็กๆ น้อยๆ ของวิธีที่ NLP ปฏิวัติอุตสาหกรรมการดูแลสุขภาพ ในขณะที่เทคโนโลยี NLP ก้าวหน้าอย่างต่อเนื่อง เราคาดหวังได้ว่าจะได้เห็นการใช้ NLP ในเชิงนวัตกรรมมากขึ้นในการดูแลสุขภาพในอนาคต
จะสร้าง NLP Pipeline ด้วย Clinical Text ได้อย่างไร?
เราจะพัฒนา Spacy ไปป์ไลน์ทีละขั้นตอนโดยใช้ SciSpacy NER Model สำหรับ Clinical Text
วัตถุประสงค์: โครงการนี้มีเป้าหมายเพื่อสร้าง NLP ไปป์ไลน์โดยใช้ SciSpacy เพื่อดำเนินการ Named Entity Recognition แบบกำหนดเองบนข้อความทางคลินิก
ผล: ผลลัพธ์จะดึงข้อมูลเกี่ยวกับโรค ยา และขนาดยาจากข้อความทางคลินิก ซึ่งสามารถนำไปใช้กับแอปพลิเคชันดาวน์สตรีม NLP ต่างๆ ได้
การออกแบบโซลูชัน:
นี่คือโซลูชันระดับสูงในการดึงข้อมูลเอนทิตีจาก Clinical Text การแยก NER เป็นงาน NLP ที่สำคัญที่ใช้ในไปป์ไลน์ NLP ส่วนใหญ่
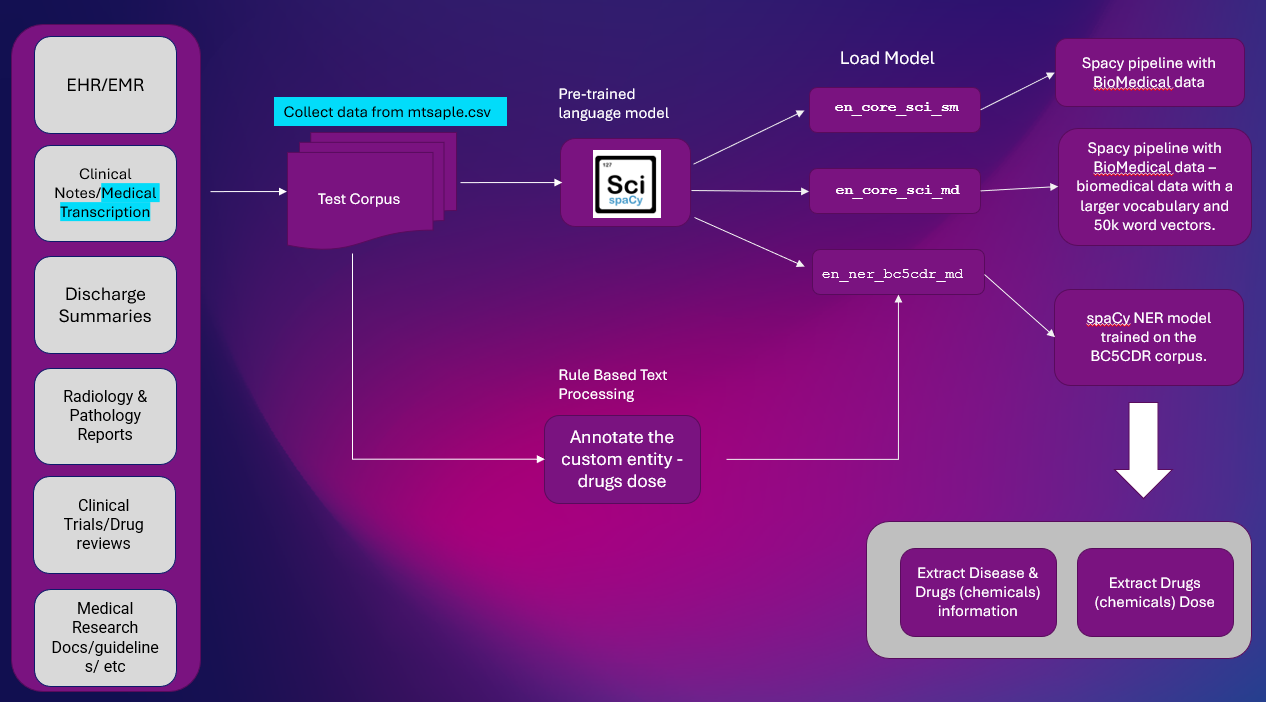
แพลตฟอร์ม: Google Colab
ห้องสมุด NLP: สปาซี & ไซสปาซี
ชุดข้อมูล: mtsample.csv (ข้อมูลที่คัดลอกมาจาก mtsample)
เราได้ใช้ สซิสป้าซี แบบจำลอง NER ที่ผ่านการฝึกอบรมล่วงหน้า เอ็น_เนอร์_bc5cdr_md-0.5.1 เพื่อสกัดโรคและตัวยา ยาถูกสกัดเป็นสารเคมี
en_ner_bc5cdr_md-0.5.1 เป็นแบบจำลอง spaCy สำหรับการจดจำเอนทิตีที่มีชื่อ (NER) ในโดเมนชีวการแพทย์
“bc5cdr” หมายถึง BC5CDR คลังข้อมูล คลังข้อความทางชีวการแพทย์ที่ใช้ในการฝึกโมเดล “md” ในชื่อหมายถึงโดเมนชีวการแพทย์ “0.5.1” ในชื่อหมายถึงรุ่นของรุ่น
เราจะใช้ตัวอย่างข้อความ "ถอดความ" จาก mtsample.csv และใส่คำอธิบายประกอบโดยใช้รูปแบบตามกฎเพื่อแยกขนาดยา
รหัสทีละขั้นตอน:
ติดตั้งแพ็คเกจ spacy & scispacy โมเดล spaCy ได้รับการออกแบบมาเพื่อทำงาน NLP เฉพาะ เช่น โทเค็น การติดแท็กส่วนหนึ่งของคำพูด และการจดจำชื่อเอนทิตี
!pip install -U spacy !pip ติดตั้ง scispacy
ติดตั้งโมเดลพื้นฐาน scispacy และโมเดล NER
แบบจำลอง en_ner_bc5cdr_md-0.5.1 ได้รับการออกแบบมาโดยเฉพาะเพื่อจดจำสิ่งที่มีชื่อในข้อความทางชีวการแพทย์ เช่น โรค ยีน และยา ว่าเป็นสารเคมี
โมเดลนี้มีประโยชน์สำหรับงาน NLP ในโดเมนชีวการแพทย์ เช่น การดึงข้อมูล การจำแนกข้อความ และการตอบคำถาม
!pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_sm-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_md-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_ner_bc5cdr_md-0.5.1.tar.gz
ติดตั้งแพ็คเกจอื่นๆ
pip ติดตั้งเรนเดอร์
นำเข้าแพ็คเกจ
นำเข้า scispacy นำเข้า spacy #Core โมเดล นำเข้า en_core_sci_sm นำเข้า en_core_sci_md
#NER รุ่นเฉพาะนำเข้า en_ner_bc5cdr_md #เครื่องมือสำหรับการแยกและแสดงข้อมูลจากแพนด้านำเข้า displacey นำเข้า displacey เป็น pd
รหัสหลาม:
ทดสอบโมเดลด้วยข้อมูลตัวอย่าง
# เลือกการถอดความเฉพาะเพื่อใช้ (แถว 3 คอลัมน์ "การถอดความ") และทดสอบข้อความโมเดล NER scispacy = mtsample_df.loc[10, "transcription"]

โหลดโมเดลเฉพาะ: en_core_sci_sm และส่งข้อความผ่าน
nlp_sm = en_core_sci_sm.load() doc = nlp_sm(ข้อความ)
#การแสดงผล
การแยกเอนทิตี displacey_image = displacey.render(doc, jupyter=True,style='ent')

โปรดทราบว่ามีการแท็กเอนทิตีที่นี่ ส่วนใหญ่เป็นศัพท์ทางการแพทย์ อย่างไรก็ตาม สิ่งเหล่านี้เป็นเอนทิตีทั่วไป
ตอนนี้โหลดโมเดลเฉพาะ: en_core_sci_md และส่งข้อความผ่าน
nlp_md = en_core_sci_md.load() doc = nlp_md(ข้อความ)
#Display การสกัดเอนทิตีที่เป็นผลลัพธ์
displacey_image = displacey.render(doc, jupyter=True,style='ent')

เวลานี้ตัวเลขจะถูกแท็กเป็นเอนทิตีด้วย en_core_sci_md
ตอนนี้โหลดโมเดลเฉพาะ: นำเข้า en_ner_bc5cdr_md และส่งข้อความผ่าน
nlp_bc = en_ner_bc5cdr_md.load() doc = nlp_bc(text) #แสดงผลการแยกเอนทิตีที่เป็นผลลัพธ์ displacey_image = displacey.render(doc, jupyter=True,style='ent')

ตอนนี้มีการติดแท็กหน่วยงานทางการแพทย์สองแห่ง: โรคและสารเคมี (ยา)
แสดงเอนทิตี
พิมพ์ ("TEXT", "START", "END", "ENTITY TYPE") สำหรับ ent ใน doc.ents: พิมพ์ (ent.text, ent.start_char, ent.end_char, ent.label_)
ข้อความเริ่มต้นสิ้นสุดประเภทเอนทิตี
โรคอ้วน 26 40 โรค
โรคอ้วน 70 84 โรค
ลดน้ำหนัก 400 411 โรค
มาร์เคน 1256 1264 เคมีภัณฑ์
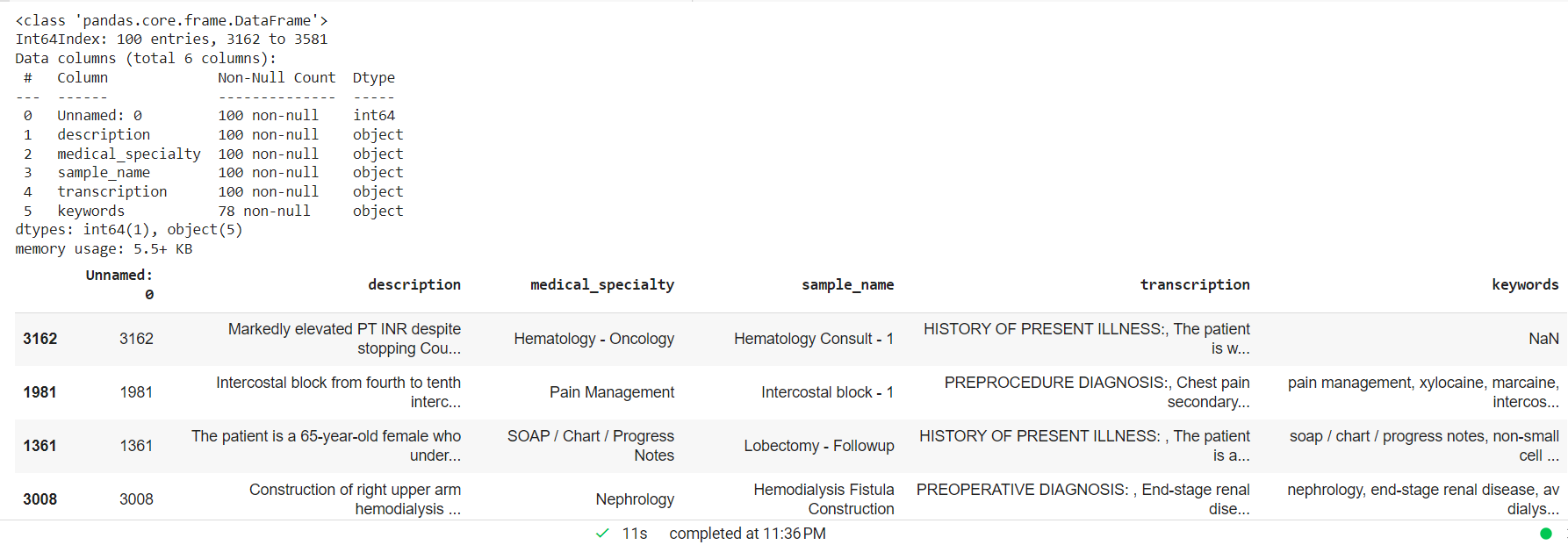
ประมวลผลข้อความทางคลินิกที่ปล่อยค่า NAN และสร้างตัวอย่างขนาดเล็กแบบสุ่มสำหรับโมเดลเอนทิตีแบบกำหนดเอง
mtsample_df.dropna(subset=['transcription'], inplace=True) mtsample_df_subset = mtsample_df.sample(n=100, แทนที่=False, Random_state=42) mtsample_df_subset.info() mtsample_df_subset.head()
โปรแกรมจับคู่ spaCy – การจับคู่ตามกฎคล้ายกับการใช้นิพจน์ทั่วไป แต่ spaCy มีความสามารถเพิ่มเติม การใช้โทเค็นและความสัมพันธ์ภายในเอกสารทำให้คุณสามารถระบุรูปแบบที่รวมเอนทิตีด้วยความช่วยเหลือของแบบจำลอง NER เป้าหมายคือค้นหาชื่อยาและขนาดยาจากข้อความ ซึ่งอาจช่วยตรวจหาข้อผิดพลาดในการใช้ยาโดยเปรียบเทียบกับมาตรฐานและแนวทางปฏิบัติ
เป้าหมายคือค้นหาชื่อยาและขนาดยาจากข้อความ ซึ่งอาจช่วยตรวจหาข้อผิดพลาดในการใช้ยาโดยเปรียบเทียบกับมาตรฐานและแนวทางปฏิบัติ
จาก spacy.matcher นำเข้า Matcher
รูปแบบ = [{'ENT_TYPE':'CHEMICAL'}, {'LIKE_NUM': True}, {'IS_ASCII': True}] matcher = Matcher(nlp_bc.vocab) matcher.add("DRUG_DOSE", [pattern])
สำหรับการถอดความใน mtsample_df_subset['transcription']: doc = nlp_bc(transcription) จับคู่ = matcher(doc) สำหรับ match_id เริ่มต้น สิ้นสุดในการจับคู่: string_id = nlp_bc.vocab.strings[match_id] # รับการเป็นตัวแทนสตริง span = doc[start :end] # the Matching span added drug doses print(span.text, start, end, string_id,) #Add โรคและยาสำหรับ ent ใน doc.ents: print(ent.text, ent.start_char, ent.end_char, ent .ฉลาก_)
ผลลัพธ์จะแสดงเอนทิตีที่ดึงมาจากตัวอย่างข้อความทางคลินิก
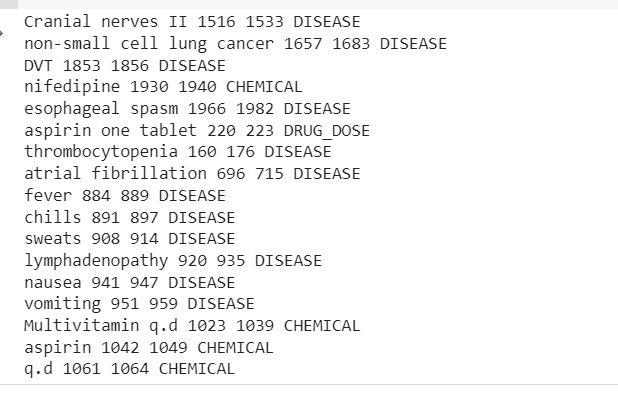
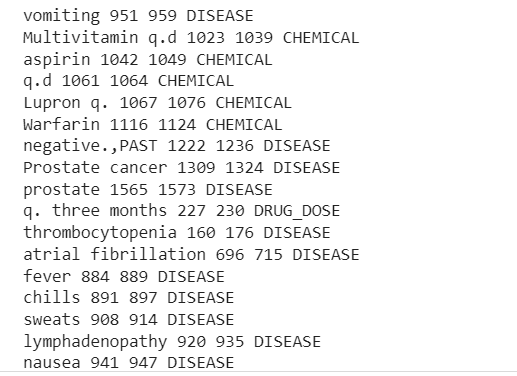
ตอนนี้เราสามารถเห็นท่อแตกออก โรค ยา (สารเคมี) และปริมาณยา ข้อมูลจากข้อความทางคลินิก
มีการแบ่งประเภทที่ไม่ถูกต้อง แต่เราสามารถเพิ่มประสิทธิภาพของโมเดลได้โดยใช้ข้อมูลเพิ่มเติม
ขณะนี้เราสามารถใช้หน่วยงานทางการแพทย์เหล่านี้ในงานต่างๆ เช่น การตรวจหาโรค การวิเคราะห์เชิงคาดการณ์ ระบบสนับสนุนการตัดสินใจทางคลินิก การจำแนกข้อความทางการแพทย์ การสรุป คำถาม-คำตอบ และอื่นๆ อีกมากมาย
สรุป
1. ในบทความนี้ เราได้สำรวจคุณลักษณะหลักบางประการของ NLP ในการดูแลสุขภาพ ซึ่งจะช่วยให้เข้าใจข้อมูลข้อความด้านการดูแลสุขภาพที่ซับซ้อน
เรายังใช้ scispaCy และ spaCy และสร้างโมเดล NER แบบกำหนดเองอย่างง่ายผ่านโมเดล NER ที่ผ่านการฝึกอบรมล่วงหน้าและตัวจับคู่ตามกฎ แม้ว่าเราจะพูดถึง NER เพียงรุ่นเดียว แต่ก็มีรุ่นอื่นๆ อีกมากมายที่พร้อมให้ใช้งาน และฟังก์ชันเพิ่มเติมอีกมากมายให้ค้นพบ
2. ภายในเฟรมเวิร์ก scispaCy มีเทคนิคเพิ่มเติมมากมายในการสำรวจ รวมถึงวิธีการตรวจหาคำย่อ การแยกวิเคราะห์การอ้างอิง และการระบุประโยคแต่ละประโยค
3. แนวโน้มล่าสุดใน NLP สำหรับการดูแลสุขภาพ ได้แก่ การพัฒนาโมเดลเฉพาะโดเมน เช่น BioBERT และ ClinicalBert และการใช้โมเดลภาษาขนาดใหญ่ เช่น GPT-3 โมเดลเหล่านี้มีความแม่นยำและประสิทธิภาพระดับสูง แต่การใช้งานยังทำให้เกิดความกังวลเกี่ยวกับอคติ ความเป็นส่วนตัว และการควบคุมข้อมูลอีกด้วย
ChatGPT (โมเดล AI การสนทนาขั้นสูงที่พัฒนาโดย OpenAI) กำลังสร้างผลกระทบอย่างมากในโลกของ NLP โมเดลนี้ได้รับการฝึกฝนเกี่ยวกับข้อมูลข้อความจำนวนมหาศาลจากอินเทอร์เน็ต และมีความสามารถในการสร้างข้อความตอบกลับที่เหมือนมนุษย์ตามอินพุตที่ได้รับ สามารถใช้กับงานต่างๆ เช่น การตอบคำถาม การสรุป การแปล และอื่นๆ นอกจากนี้ โมเดลยังได้รับการปรับแต่งอย่างละเอียดสำหรับกรณีการใช้งานเฉพาะ เช่น การสร้างโค้ดหรือการเขียนบทความ เพื่อปรับปรุงประสิทธิภาพในพื้นที่เฉพาะเหล่านั้น
5. อย่างไรก็ตาม แม้จะมีประโยชน์มากมาย แต่ NLP ในการดูแลสุขภาพก็ใช่ว่าจะปราศจากความท้าทาย การรับรองความถูกต้องและยุติธรรมของแบบจำลอง NLP และการเอาชนะข้อกังวลด้านความเป็นส่วนตัวของข้อมูลเป็นความท้าทายบางประการที่ต้องได้รับการแก้ไขเพื่อให้ตระหนักถึงศักยภาพของ NLP ในการดูแลสุขภาพอย่างเต็มที่
6. ด้วยข้อดีหลายประการ บุคลากรทางการแพทย์จำเป็นต้องยอมรับและนำ NLP ไปใช้ในกระบวนการทำงานของตน แม้ว่าจะมีความท้าทายมากมายที่ต้องเอาชนะ แต่ NLP ในการดูแลสุขภาพก็เป็นเทรนด์ที่น่าจับตามองและลงทุนอย่างแน่นอน
สื่อที่แสดงในบทความนี้ไม่ได้เป็นของ Analytics Vidhya และถูกใช้ตามดุลยพินิจของผู้เขียน
ที่เกี่ยวข้อง
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://www.analyticsvidhya.com/blog/2023/02/extracting-medical-information-from-clinical-text-with-nlp/