
บทนำ
แมชชีนเลิร์นนิง (ML) เป็นสาขาวิชาที่มุ่งเน้นการพัฒนาอัลกอริทึมเพื่อเรียนรู้โดยอัตโนมัติจากข้อมูล คาดการณ์และอนุมานรูปแบบโดยไม่ต้องบอกอย่างชัดเจนว่าต้องทำอย่างไร มีจุดมุ่งหมายเพื่อสร้างระบบที่ปรับปรุงโดยอัตโนมัติด้วยประสบการณ์และข้อมูล
ซึ่งสามารถทำได้ผ่านการเรียนรู้แบบมีผู้สอน โดยที่ตัวแบบได้รับการฝึกอบรมโดยใช้ข้อมูลที่ติดป้ายเพื่อคาดการณ์ หรือผ่านการเรียนรู้แบบไม่มีผู้ดูแล โดยที่ตัวแบบจะพยายามเปิดเผยรูปแบบหรือความสัมพันธ์ภายในข้อมูลโดยไม่ต้องมีผลลัพธ์เป้าหมายที่เจาะจงให้คาดหวัง
ML ได้กลายเป็นเครื่องมือที่จำเป็นและใช้งานกันอย่างแพร่หลายในสาขาวิชาต่างๆ รวมถึงวิทยาการคอมพิวเตอร์ ชีววิทยา การเงิน และการตลาด ได้รับการพิสูจน์แล้วว่ามีประโยชน์ในการใช้งานที่หลากหลาย เช่น การจำแนกภาพ การประมวลผลภาษาธรรมชาติ และการตรวจจับการฉ้อโกง
งานการเรียนรู้ของเครื่อง
แมชชีนเลิร์นนิงแบ่งกว้างๆ ได้เป็นสามงานหลัก:
- การเรียนรู้ภายใต้การดูแล
- การเรียนรู้ที่ไม่มีผู้ดูแล
- เสริมการเรียนรู้
ที่นี่เราจะมุ่งเน้นไปที่สองกรณีแรก
การเรียนรู้ภายใต้การดูแล
การเรียนรู้ภายใต้การดูแลเกี่ยวข้องกับการฝึกอบรมแบบจำลองเกี่ยวกับข้อมูลที่มีป้ายกำกับ โดยที่ข้อมูลอินพุตจะจับคู่กับเอาต์พุตหรือตัวแปรเป้าหมายที่สอดคล้องกัน เป้าหมายคือการเรียนรู้ฟังก์ชันที่สามารถจับคู่ข้อมูลอินพุตกับเอาต์พุตที่ถูกต้อง อัลกอริทึมการเรียนรู้ภายใต้การดูแลทั่วไป ได้แก่ การถดถอยเชิงเส้น การถดถอยโลจิสติก ต้นไม้การตัดสินใจ และเครื่องเวกเตอร์สนับสนุน
ตัวอย่างรหัสการเรียนรู้ภายใต้การดูแลโดยใช้ Python:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
ในตัวอย่างโค้ดง่ายๆ นี้ เราฝึกการ LinearRegression อัลกอริทึมจาก scikit-learn จากข้อมูลการฝึกอบรมของเรา แล้วนำไปใช้เพื่อรับการคาดการณ์สำหรับข้อมูลการทดสอบของเรา
กรณีการใช้งานจริงอย่างหนึ่งของการเรียนรู้แบบมีผู้สอนคือการจัดประเภทสแปมอีเมล ด้วยการเติบโตแบบทวีคูณของการสื่อสารทางอีเมล การระบุและกรองอีเมลขยะจึงกลายเป็นสิ่งสำคัญ การใช้อัลกอริทึมการเรียนรู้ภายใต้การดูแล เป็นไปได้ที่จะฝึกแบบจำลองเพื่อแยกความแตกต่างระหว่างอีเมลที่ถูกต้องและสแปมตามข้อมูลที่มีป้ายกำกับ
โมเดลการเรียนรู้ภายใต้การดูแลสามารถฝึกฝนได้ในชุดข้อมูลที่มีอีเมลที่ติดป้ายว่า "สแปม" หรือ "ไม่ใช่สแปม" โมเดลจะเรียนรู้รูปแบบและคุณสมบัติจากข้อมูลที่มีป้ายกำกับ เช่น การมีอยู่ของคำหลัก โครงสร้างอีเมล หรือข้อมูลผู้ส่งอีเมล เมื่อโมเดลได้รับการฝึกฝนแล้ว จะสามารถใช้จัดประเภทอีเมลขาเข้าโดยอัตโนมัติว่าเป็นสแปมหรือไม่ใช่สแปม กรองข้อความที่ไม่ต้องการได้อย่างมีประสิทธิภาพ
การเรียนรู้ที่ไม่มีผู้ดูแล
ในการเรียนรู้แบบไม่มีผู้ดูแล ข้อมูลอินพุตจะไม่มีป้ายกำกับ และเป้าหมายคือการค้นหารูปแบบหรือโครงสร้างภายในข้อมูล อัลกอริทึมการเรียนรู้แบบไม่มีผู้ดูแลมีเป้าหมายเพื่อค้นหาการเป็นตัวแทนหรือกลุ่มที่มีความหมายในข้อมูล
ตัวอย่างของอัลกอริทึมการเรียนรู้แบบไม่มีผู้ดูแล ได้แก่ k-หมายถึงการจัดกลุ่ม, การจัดกลุ่มแบบลำดับชั้นและ การวิเคราะห์องค์ประกอบหลัก (PCA).
ตัวอย่างรหัสการเรียนรู้ที่ไม่มีผู้ดูแล:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
ในตัวอย่างโค้ดง่ายๆ นี้ เราฝึกการ KMeans อัลกอริทึมจาก scikit-learn เพื่อระบุสามกลุ่มในข้อมูลของเรา แล้วใส่ข้อมูลใหม่ลงในกลุ่มเหล่านั้น
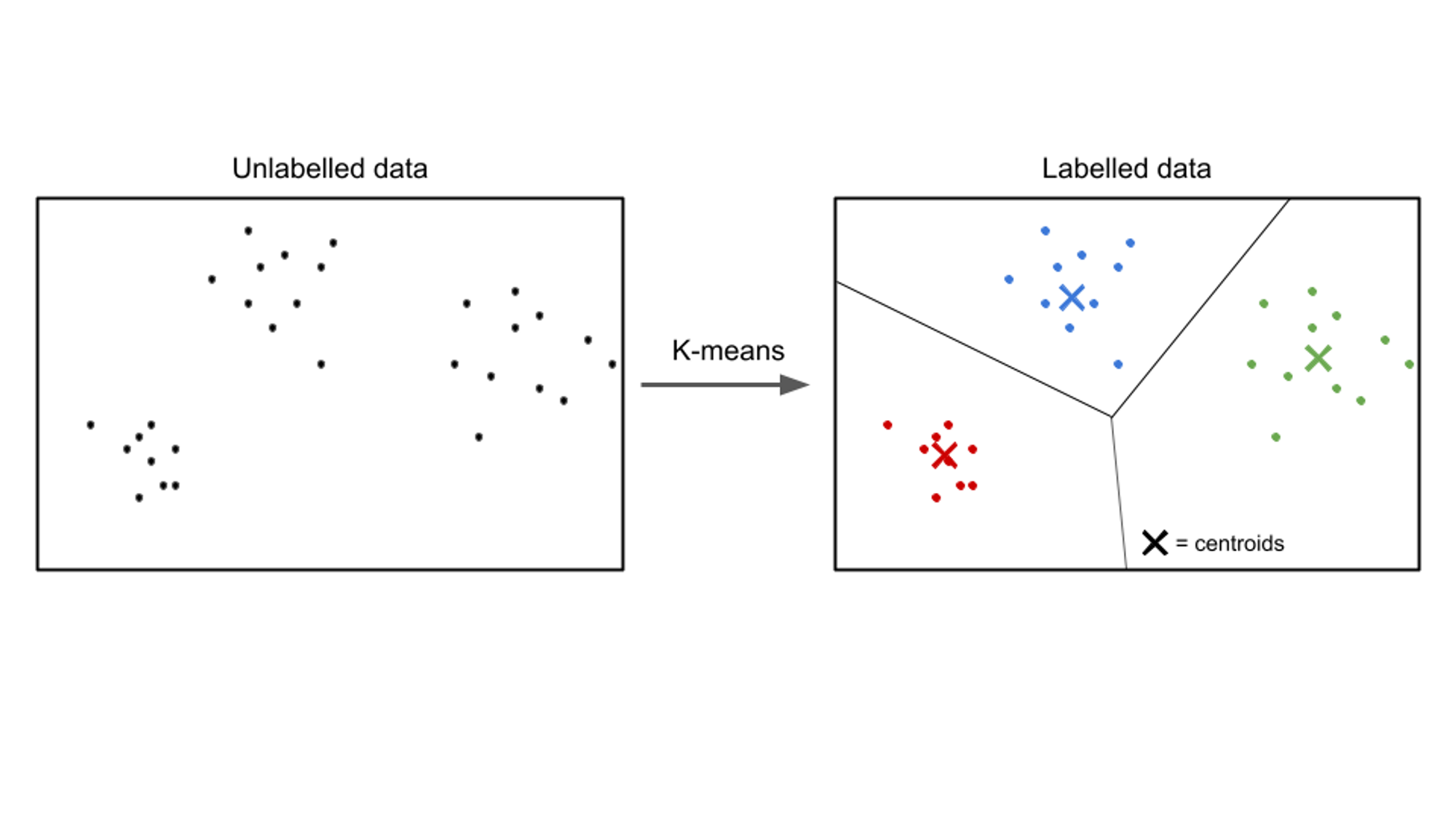
ตัวอย่างของกรณีการใช้งานการเรียนรู้ที่ไม่มีผู้ดูแลคือการแบ่งกลุ่มลูกค้า ในอุตสาหกรรมต่างๆ ธุรกิจต่างๆ มีเป้าหมายที่จะเข้าใจฐานลูกค้าของตนให้ดียิ่งขึ้นเพื่อปรับกลยุทธ์ทางการตลาด ปรับแต่งข้อเสนอให้เหมาะกับแต่ละบุคคล และเพิ่มประสิทธิภาพประสบการณ์ของลูกค้า สามารถใช้อัลกอริธึมการเรียนรู้แบบไม่มีผู้ดูแลเพื่อแบ่งลูกค้าออกเป็นกลุ่มต่างๆ ตามลักษณะและพฤติกรรมที่ใช้ร่วมกัน
ดูคู่มือเชิงปฏิบัติสำหรับการเรียนรู้ Git ที่มีแนวทางปฏิบัติที่ดีที่สุด มาตรฐานที่ยอมรับในอุตสาหกรรม และเอกสารสรุปรวม หยุดคำสั่ง Googling Git และจริงๆ แล้ว เรียน มัน!
ด้วยการใช้เทคนิคการเรียนรู้แบบไม่มีผู้ดูแล เช่น การจัดกลุ่ม ธุรกิจสามารถค้นพบรูปแบบและกลุ่มที่มีความหมายภายในข้อมูลลูกค้าของตนได้ ตัวอย่างเช่น อัลกอริทึมการจัดกลุ่มสามารถระบุกลุ่มลูกค้าที่มีพฤติกรรมการซื้อ ข้อมูลประชากร หรือความชอบที่คล้ายคลึงกัน ข้อมูลนี้สามารถใช้ประโยชน์เพื่อสร้างแคมเปญการตลาดที่ตรงเป้าหมาย เพิ่มประสิทธิภาพคำแนะนำผลิตภัณฑ์ และเพิ่มความพึงพอใจของลูกค้า
คลาสอัลกอริทึมหลัก
อัลกอริทึมการเรียนรู้ภายใต้การดูแล
-
แบบจำลองเชิงเส้น: ใช้สำหรับทำนายตัวแปรต่อเนื่องตามความสัมพันธ์เชิงเส้นระหว่างคุณสมบัติและตัวแปรเป้าหมาย
-
Tree-Based Models: สร้างขึ้นโดยใช้ชุดของการตัดสินใจแบบไบนารีเพื่อทำการทำนายหรือการจำแนกประเภท
-
Ensemble Models: วิธีการที่รวมโมเดลหลายๆ แบบ (ตามต้นไม้หรือเชิงเส้น) เพื่อทำการทำนายที่แม่นยำยิ่งขึ้น
-
แบบจำลองโครงข่ายประสาทเทียม: วิธีการที่อาศัยสมองมนุษย์อย่างหลวมๆ โดยที่ฟังก์ชันต่างๆ ทำงานเป็นโหนดของเครือข่าย
อัลกอริทึมการเรียนรู้ที่ไม่มีผู้ดูแล
-
การทำคลัสเตอร์แบบลำดับชั้น: สร้างลำดับชั้นของคลัสเตอร์โดยการรวมหรือแยกกลุ่มซ้ำๆ
-
การทำคลัสเตอร์แบบไม่มีลำดับชั้น: แบ่งข้อมูลออกเป็นคลัสเตอร์ที่แตกต่างกันตามความคล้ายคลึงกัน
-
การลดขนาด: ลดขนาดของข้อมูลในขณะที่รักษาข้อมูลที่สำคัญที่สุดไว้
การประเมินแบบจำลอง
การเรียนรู้ภายใต้การดูแล
ในการประเมินประสิทธิภาพของโมเดลการเรียนรู้แบบมีผู้สอน จะมีการใช้เมตริกต่างๆ รวมถึงความแม่นยำ ความแม่นยำ การเรียกคืน คะแนน F1 และ ROC-AUC เทคนิคการตรวจสอบความถูกต้องข้าม เช่น การตรวจสอบความถูกต้องข้าม k-fold สามารถช่วยประเมินประสิทธิภาพการทำงานทั่วไปของแบบจำลองได้
การเรียนรู้ที่ไม่มีผู้ดูแล
การประเมินอัลกอริทึมการเรียนรู้แบบไม่มีผู้ดูแลมักมีความท้าทายมากกว่าเนื่องจากไม่มีความจริงพื้นฐาน เมตริกต่างๆ เช่น คะแนนภาพเงาหรือความเฉื่อยสามารถใช้เพื่อประเมินคุณภาพของผลลัพธ์การจัดกลุ่มได้ เทคนิคการสร้างภาพยังสามารถให้ข้อมูลเชิงลึกเกี่ยวกับโครงสร้างของคลัสเตอร์
เคล็ดลับและ
การเรียนรู้ภายใต้การดูแล
- ประมวลผลล่วงหน้าและทำให้ข้อมูลอินพุตเป็นมาตรฐานเพื่อปรับปรุงประสิทธิภาพของโมเดล
- จัดการค่าที่ขาดหายไปอย่างเหมาะสม ไม่ว่าจะโดยการใส่ค่าหรือลบออก
- วิศวกรรมคุณลักษณะสามารถเพิ่มความสามารถของแบบจำลองในการจับภาพรูปแบบที่เกี่ยวข้อง
การเรียนรู้ที่ไม่มีผู้ดูแล
- เลือกจำนวนคลัสเตอร์ที่เหมาะสมตามความรู้โดเมนหรือใช้เทคนิคต่างๆ เช่น วิธีหักศอก
- พิจารณาการวัดระยะทางที่แตกต่างกันเพื่อวัดความคล้ายคลึงกันระหว่างจุดข้อมูล
- ปรับกระบวนการคลัสเตอร์ให้เป็นมาตรฐานเพื่อหลีกเลี่ยงการโอเวอร์ฟิต
โดยสรุป แมชชีนเลิร์นนิงเกี่ยวข้องกับงาน เทคนิค อัลกอริทึม วิธีการประเมินโมเดล และคำแนะนำที่เป็นประโยชน์มากมาย เมื่อเข้าใจประเด็นเหล่านี้ ผู้ปฏิบัติงานสามารถใช้การเรียนรู้ของเครื่องกับปัญหาในโลกแห่งความเป็นจริงได้อย่างมีประสิทธิภาพ และได้รับข้อมูลเชิงลึกที่สำคัญจากข้อมูล ตัวอย่างรหัสที่ให้มาแสดงการใช้อัลกอริทึมการเรียนรู้แบบมีผู้สอนและแบบไม่มีผู้ดูแล โดยเน้นการนำไปปฏิบัติจริง
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- การเงิน EVM ส่วนต่อประสานแบบครบวงจรสำหรับการเงินแบบกระจายอำนาจ เข้าถึงได้ที่นี่.
- กลุ่มสื่อควอนตัม IR/PR ขยาย เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. ข้อมูลอัจฉริยะ Web3 ขยายความรู้ เข้าถึงได้ที่นี่.
- ที่มา: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/