
Giriş
Yapay Zeka (AI) çeşitli endüstrilerde önemli ilerlemeler kaydediyor ve sağlık hizmetleri de bir istisna değil. Sağlık hizmetlerinde yapay zekanın en umut verici alanlarından biri, daha verimli ve doğru veri analizi ve iletişimini kolaylaştırarak hasta bakımında devrim yaratma potansiyeline sahip olan Doğal Dil İşleme'dir (NLP).
NLP'nin sağlık alanında ezber bozan bir ilaç olduğu kanıtlandı. NLP, sağlık hizmeti sağlayıcılarının hasta bakımı sağlama şeklini değiştiriyor. NLP, nüfus sağlığı yönetiminden hastalık tespitine kadar sağlık profesyonellerinin bilinçli kararlar almasına ve daha iyi tedavi sonuçları sağlamasına yardımcı oluyor.
Öğrenme hedefleri
- Sağlık hizmetlerinde NLP ve yapay zekanın kullanımını anlama ve analiz etme
- NLP'nin temellerini kavramak
- Sağlık hizmetlerinde yaygın olarak kullanılan bazı NLP kütüphaneleri hakkında bilgi edinmek
- NLP'nin sağlık hizmetlerinde kullanım örneklerini öğrenmek
Bu makale, Veri Bilimi Blogathon.
İçindekiler
- Sağlık Hizmetinde Yapay Zeka ve NLP Kullanma Motivasyonu
- Doğal Dil İşleme nedir?
- NLP'de Kullanılan Farklı Teknikler
3.1 Kurala Dayalı Teknikler
3.2 Makine Öğrenimi Modellerini Kullanan İstatistiksel Teknikler
3.3 Öğrenimin Transferi - Çeşitli NLP Kütüphaneleri ve Çerçeveleri
- Büyük Dil Modelleri (LLM) Nedir?
- Klinik Metinde NLP – Farklı Yaklaşım İhtiyacı
- Sağlık Sektöründe Kullanılan Bazı NLP Kütüphaneleri
- Klinik Veri Kümelerini Anlamak
- Farklı Klinik Veri Türleri Nelerdir?
- Sağlık Sektöründe NLP'nin Kullanım Örnekleri ve Uygulamaları
- Klinik Metinle NLP Boru Hattı Nasıl Oluşturulur?
11.1 Çözüm Tasarımı
11.2 Adım Adım Kod - Sonuç
Sağlık Hizmetinde Yapay Zeka ve NLP Kullanma Motivasyonu
Kullanma motivasyonu AI Sağlık hizmetlerinde NLP'nin temeli, sağlık bakım maliyetlerini düşürürken hasta bakımını ve tedavi sonuçlarını iyileştirmeye dayanmaktadır. Sağlık sektörü, EMR'ler, klinik notlar ve sağlıkla ilgili sosyal medya gönderileri dahil olmak üzere, hasta sağlığı ve tedavi sonuçları hakkında değerli bilgiler sağlayabilecek çok büyük miktarda veri üretiyor. Ancak bu verilerin çoğu yapısal değildir ve manuel olarak analiz edilmesi zordur.
Ayrıca sağlık sektörü, yaşlanan nüfus, artan kronik hastalık oranları ve sağlık personeli eksikliği gibi çeşitli zorluklarla karşı karşıyadır.
Bu zorluklar, daha verimli ve etkili sağlık hizmeti sunumuna olan ihtiyacın artmasına yol açmıştır.
NLP, yapılandırılmamış tıbbi verilerden değerli bilgiler sağlayarak hasta bakımı ve tedavi sonuçlarının iyileştirilmesine yardımcı olabilir ve sağlık profesyonellerinin daha bilinçli klinik kararlar almasına destek olabilir.
Doğal Dil İşleme nedir?
Doğal Dil İşleme (NLP), bilgisayarlar ve insan dilleri arasındaki etkileşimle ilgilenen Yapay Zekanın (AI) bir alt alanıdır. İnsan dilini analiz etmek, anlamak ve oluşturmak için hesaplama tekniklerini kullanır. NLP, konuşma tanıma, makine çevirisi, duygu analizi ve metin özetleme dahil olmak üzere birçok uygulamada kullanılır.
Şimdi çeşitli NLP Tekniklerini, kütüphanelerini ve çerçevelerini inceleyeceğiz.
NLP'de Kullanılan Farklı Teknikler
NLP endüstrisinde yaygın olarak kullanılan iki teknik vardır.
1. Kurala Dayalı Teknikler: önceden tanımlanmış dilbilgisi kurallarına ve sözlüklere güvenin
2. İstatistiksel Teknikler: dili analiz etmek ve anlamak için makine öğrenimi algoritmalarını kullanın
3. Büyük Dil Modeli Kullanımı Transfer Öğrenimi
İşte çeşitli NLP görevlerine sahip standart bir NLP İşlem Hattı
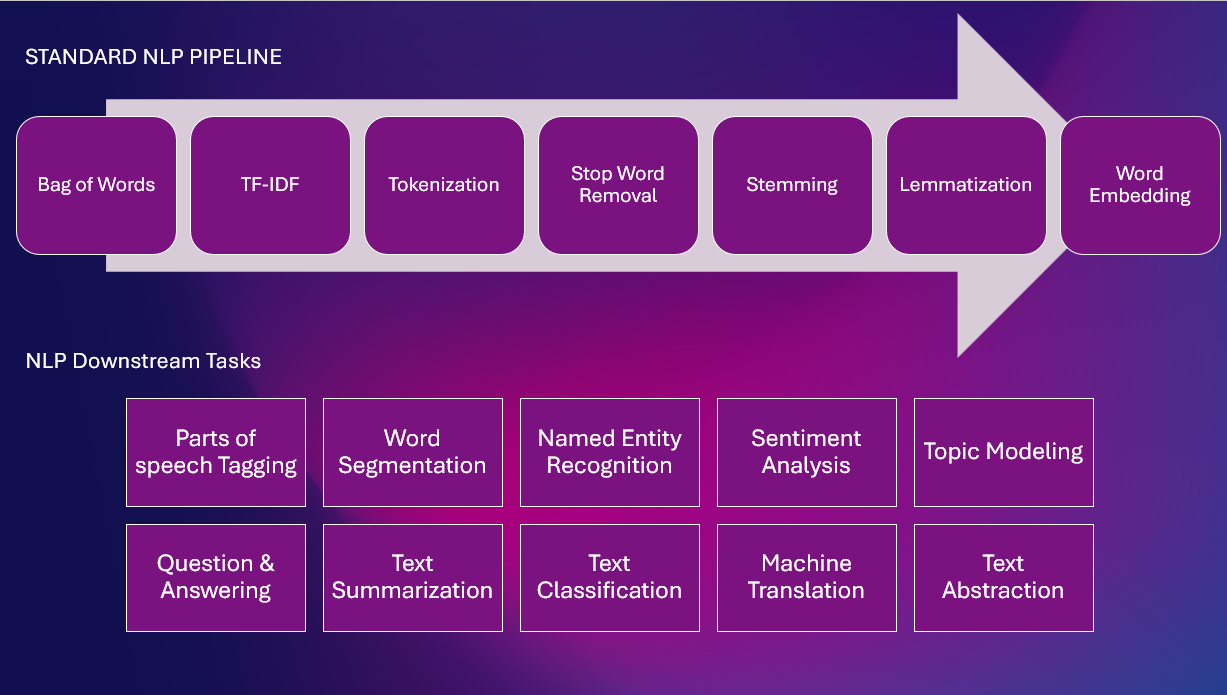
Kural Tabanlı Teknikler
Bu teknikler, metinden anlamlı bilgiler çıkarmak için bir dizi el yapımı kural veya desen oluşturmayı içerir. Kural tabanlı sistemler genellikle, adlandırılmış varlıklar veya belirli anahtar sözcükler gibi hedef bilgilerle eşleşen belirli kalıpları tanımlayarak ve ardından bu kalıplara dayalı olarak bu bilgiyi çıkararak çalışır. Kural tabanlı sistemler hızlı, güvenilir ve basittir ancak tanımlanan kuralların kalitesi ve sayısı nedeniyle sınırlıdırlar ve bakımları ve güncellemeleri zor olabilir.
Örneğin, adlandırılmış varlık tanımaya yönelik kural tabanlı bir sistem, metindeki özel isimleri tanımlamak ve bunları kişi, konum, organizasyon, hastalık, ilaçlar vb. gibi önceden tanımlanmış varlık türlerine göre kategorize etmek için tasarlanabilir. Sistem bir dizi kullanacaktır. Kişi adları için büyük harf kullanımı veya kuruluşlar için belirli anahtar kelimeler gibi, her varlık türü için kriterlerle eşleşen metindeki kalıpları belirlemeye yönelik kurallar.
Makine Öğrenimi Modellerini Kullanan İstatistiksel Teknikler
Bu teknikler, verilerdeki kalıpları öğrenmek ve bu kalıplara dayalı tahminler yapmak için istatistiksel algoritmalar kullanır. Makine öğrenimi modelleri büyük miktarlarda açıklamalı veriler üzerinde eğitilebilir ve bu da onları kural tabanlı sistemlerden daha esnek ve ölçeklenebilir hale getirir. NLP'de çeşitli makine öğrenimi modelleri kullanılır: Karar ağaçları, rastgele ormanlar, Vektör makineleri desteklemek, ve nöral ağlar.
Örneğin, duygu analizine yönelik bir makine öğrenimi modeli, her metnin olumlu, olumsuz veya nötr olarak etiketlendiği geniş bir açıklamalı metin kümesi üzerinde eğitilebilir. Model, verilerdeki olumlu ve olumsuz metinleri ayırt eden istatistiksel kalıpları öğrenecek ve daha sonra bu kalıpları yeni, görünmeyen metinler hakkında tahminlerde bulunmak için kullanacak. Bu yaklaşımın avantajı, modelin, kurallarda açıkça tanımlanmayan duygu kalıplarını tanımlamayı öğrenebilmesidir.
Transfer Öğrenimi
Bu teknikler, kural tabanlı ve makine öğrenimi modellerinin güçlü yönlerini birleştiren hibrit bir yaklaşımdır. Transfer öğrenimi, belirli bir göreve veya alana ince ayar yapmak için başlangıç noktası olarak geniş bir metin kümesi üzerinde eğitilmiş dil modeli gibi önceden eğitilmiş bir makine öğrenimi modelini kullanır. Bu yaklaşım, önceden eğitilmiş modelden öğrenilen genel bilgiden yararlanır, eğitim için gereken etiketli veri miktarını azaltır ve belirli bir görev üzerinde daha hızlı ve daha doğru tahminler yapılmasını sağlar.
Örneğin, adlandırılmış varlık tanımaya yönelik bir transfer öğrenme yaklaşımı, daha küçük bir açıklamalı tıbbi metin külliyatı üzerinde önceden eğitilmiş bir dil modeline ince ayar yapabilir. Model, önceden eğitilmiş modelden öğrenilen genel bilgilerle başlayacak ve daha sonra ağırlıklarını tıbbi metnin kalıplarına daha iyi uyacak şekilde ayarlayacaktır. Bu yaklaşım, eğitim için gereken etiketli veri miktarını azaltacak ve tıbbi alanda adlandırılmış varlık tanıma için daha doğru bir modelle sonuçlanacaktır.
Çeşitli NLP Kütüphaneleri ve Çerçeveleri
Çeşitli kütüphaneler çok çeşitli NLP işlevleri sağlar. Örneğin :

Doğal Dil İşleme (NLP) kitaplıkları ve çerçeveleri, NLP uygulamalarının geliştirilmesine ve dağıtılmasına yardımcı olan yazılım araçlarıdır. Her birinin güçlü, zayıf yönleri ve odak alanları olan çeşitli NLP kütüphaneleri ve çerçeveleri mevcuttur.
Bu araçlar, destekledikleri algoritmaların karmaşıklığına, işleyebilecekleri modellerin boyutuna, kullanım kolaylığına ve izin verdikleri özelleştirme derecesine göre farklılık gösterir.
Büyük Dil Modelleri (LLM) Nedir?
Büyük dil modelleri büyük miktarda veri üzerinde eğitilir. İnsan benzeri metinler oluşturabilir ve çok çeşitli NLP görevlerini yüksek doğrulukla gerçekleştirebilir.
Büyük dil modellerinin bazı örneklerini ve her birinin kısa açıklamasını burada bulabilirsiniz:
GPT 3 (Jeneratif Önceden Eğitimli Transformatör 3): OpenAI tarafından geliştirilen GPT-3, insan benzeri metinler oluşturmak için derin öğrenme algoritmalarını kullanan büyük, dönüştürücü tabanlı bir dil modelidir. Büyük bir metin verisi külliyatı üzerinde eğitilmiş olup, bir istemi temel alarak tutarlı ve bağlamsal olarak uygun metin yanıtları oluşturmasına olanak tanımaktadır.
Bert (Transformatörlerden Çift Yönlü Kodlayıcı Gösterimleri): Google tarafından geliştirilen BERT, geniş bir metin verisi külliyatı üzerinde önceden eğitilmiş, dönüştürücü tabanlı bir dil modelidir. Bir cümledeki kelimeler arasındaki bağlamı ve ilişkileri kodlayarak adlandırılmış varlık tanıma, soru yanıtlama ve metin sınıflandırma gibi çok çeşitli NLP görevlerinde iyi performans gösterecek şekilde tasarlanmıştır.
roBERTa (Güçlü Optimize Edilmiş BERT Yaklaşımı): Facebook AI tarafından geliştirilen RoBERTa, BERT'in NLP görevleri için ince ayar yapılmış ve optimize edilmiş bir çeşididir. Daha geniş bir metin verisi külliyatı üzerinde eğitilmiştir ve BERT'ten farklı bir eğitim stratejisi kullanır, bu da NLP kıyaslamalarında performansın artmasına yol açar.
ELMo (Dil Modellerinden Yerleştirmeler): Allen Yapay Zeka Enstitüsü tarafından geliştirilen ELMo, geniş bir metin verisi kümesinden dil temsillerini öğrenmek için çift yönlü bir LSTM (Uzun Kısa Süreli Bellek) ağı kullanan, derin bağlamsallaştırılmış bir kelime temsil modelidir. ELMo, belirli NLP görevleri için ince ayar yapılabilir veya diğer makine öğrenimi modelleri için özellik çıkarıcı olarak kullanılabilir.
ULMFiT (Evrensel Dil Modeli İnce Ayarı): FastAI tarafından geliştirilen ULMFiT, az miktarda göreve özgü açıklamalı veri kullanarak belirli bir NLP görevinde önceden eğitilmiş bir dil modeline ince ayar yapan bir transfer öğrenme yöntemidir. ULMFiT, çok çeşitli NLP kriterlerinde en gelişmiş performansı elde etmiştir ve NLP'de transfer öğreniminin önde gelen bir örneği olarak kabul edilmektedir.
Klinik Metinde NLP: Farklı Yaklaşım İhtiyacı
Klinik metinler genellikle yapılandırılmamıştır ve çok sayıda tıbbi jargon ve kısaltma içermektedir; bu da geleneksel NLP modellerinin anlaşılmasını ve işlenmesini zorlaştırmaktadır. Ek olarak, klinik metinler genellikle hastalık, ilaçlar, hasta bilgileri, teşhisler ve tedavi planları gibi önemli bilgileri içerir ve bu tıbbi bilgileri doğru bir şekilde çıkarabilen ve anlayabilen özel NLP modelleri gerektirir.
Klinik metinlerin farklı NLP modellerine ihtiyaç duymasının bir diğer nedeni de, EHR'ler, klinik notlar ve radyoloji raporları gibi entegre edilmesi gereken farklı kaynaklara yayılmış büyük miktarda veri içermesidir. Bu, metni işleyip anlayabilen, verileri farklı kaynaklara bağlayıp entegre edebilen ve klinik olarak kabul edilebilir ilişkiler kurabilen modeller gerektirir.
Son olarak, klinik metinler sıklıkla hassas hasta bilgileri içerir ve HIPAA gibi katı düzenlemelerle korunması gerekir. Klinik metni işlemek için kullanılan NLP modelleri, bir yandan yararlı bilgiler sağlarken bir yandan da hassas hasta bilgilerini tanımlayıp koruyabilmelidir.
Sağlık Sektöründe Kullanılan Bazı NLP Kütüphaneleri
Tıp alanındaki metinsel veriler, klinik metinler ve diğer tıbbi belgeler gibi çeşitli kaynaklardan tıbbi bilgileri çıkarabilen özel bir Doğal Dil İşleme (NLP) sistemi gerektirir.
Tıbbi alana özgü NLP kitaplıklarının ve modellerinin bir listesi:
SpaCy: Tıbbi alan da dahil olmak üzere çeşitli alanlar için kullanıma hazır modeller sağlayan açık kaynaklı bir NLP kütüphanesidir.
ScispaCy: spaCy'nin bilimsel ve biyomedikal metinler üzerine özel olarak eğitilmiş özel bir versiyonudur ve bu da onu tıbbi metinlerin işlenmesi için ideal kılar.
BioBERT: Biyomedikal alan için özel olarak tasarlanmış, önceden eğitilmiş transformatör tabanlı bir model. Wiki + Books + PubMed + PMC ile önceden eğitilmiştir.
KlinikBERT: MIMIC-III veri tabanından klinik notları ve taburcu özetlerini işlemek için tasarlanmış, önceden eğitilmiş başka bir model.
Med7: Teşhis, ilaç tedavisi ve laboratuvar testleri de dahil olmak üzere yedi temel klinik kavramı ortaya çıkarmak için elektronik sağlık kayıtları (EHR) üzerine eğitilmiş transformatör tabanlı bir model.
DisMod-ML: Tıbbi metni işlemek için NLP tekniklerini kullanan, hastalık modellemeye yönelik olasılıksal bir modelleme çerçevesi.
Doktor: Metinden tıbbi bilgi çıkarmaya yönelik kural tabanlı bir NLP sistemi.
Bunlar özellikle tıbbi alan için tasarlanmış popüler NLP kitaplıklarından ve modellerinden bazılarıdır. Önceden eğitilmiş modellerden kural tabanlı sistemlere kadar çeşitli özellikler sunarlar ve sağlık kuruluşlarının tıbbi metinleri etkili bir şekilde işlemesine yardımcı olabilirler.
NER modelimizde spaCy ve Scisspacy kullanacağız. Bu kitaplıkların Google ortak laboratuvarında veya yerel altyapıda çalıştırılması nispeten kolaydır.
BioBERT ve ClinicalBERT kaynak yoğun büyük dil modelleri GPU'lara ve daha yüksek altyapıya ihtiyaç duyar.
Klinik Veri Kümelerini Anlamak
Tıbbi metin verileri, elektronik sağlık kayıtları (EHR'ler), tıbbi dergiler, klinik notlar, tıbbi web siteleri ve veritabanları gibi çeşitli kaynaklardan elde edilebilir. Bu kaynaklardan bazıları, NLP modellerini eğitmek için kullanılabilecek kamuya açık veri kümeleri sağlarken, diğerleri verilere erişmeden önce onay ve etik değerlendirmeler gerektirebilir. Tıbbi metin verilerinin kaynakları şunları içerir:
1. Açık kaynaklı tıbbi derlemler, örneğin MIMIC-III veritabanı 2001 ve 2012 yılları arasında Beth Israel Deaconess Tıp Merkezi'nde bakım gören hastalara ait geniş, açık erişilebilir bir elektronik sağlık kayıtları (EHR) veritabanıdır. Veritabanı, hasta demografik bilgileri, yaşamsal belirtiler, laboratuvar testleri, ilaçlar, prosedürler ve tedaviler gibi bilgileri içerir. Hemşireler ve doktorlar gibi sağlık çalışanlarının notları. Ek olarak veri tabanı, yoğun bakım tipi, kalış süresi ve sonuçlar da dahil olmak üzere hastaların yoğun bakımda kalışlarına ilişkin bilgileri içerir. MIMIC-III'deki veriler kimliksizleştirilmiştir ve tahmine dayalı modellerin ve klinik karar destek sistemlerinin geliştirilmesini desteklemek amacıyla araştırma amacıyla kullanılabilir.
2. Ulusal Tıp Kütüphanesi ClinicalTrials.gov web sitesinde klinik deneme verileri ve hastalık gözetim verileri bulunmaktadır.
3. Ulusal Sağlık Enstitüleri Ulusal Tıp Kütüphanesi, Ulusal Biyoteknoloji Bilgi Merkezleri (NCBI) ve Dünya Sağlık Örgütü (DSÖ)
4. Hastane, klinik, ilaç firmaları gibi sağlık kurum ve kuruluşları, elektronik sağlık kayıtları, klinik notlar, tıbbi transkripsiyon ve tıbbi raporlar aracılığıyla büyük miktarda tıbbi metin verisi üretmektedir.
5. PubMed ve CINAHL gibi tıbbi araştırma dergileri ve veritabanları, çok sayıda yayınlanmış tıbbi araştırma makalesi ve özeti içerir.
6. Twitter gibi sosyal medya platformları hastaların bakış açıları, ilaç incelemeleri ve deneyimlerine ilişkin gerçek zamanlı bilgiler sağlayabilir.
NLP modellerini tıbbi metin verilerini kullanarak eğitmek için verilerin kalitesini ve alaka düzeyini dikkate almak ve bunların uygun şekilde önceden işlendiğinden ve biçimlendirildiğinden emin olmak önemlidir. Ayrıca hassas tıbbi bilgilerle çalışırken etik ve yasal hususlara uymak önemlidir.
Farklı Klinik Veri Türleri Nelerdir?
Sağlık hizmetlerinde yaygın olarak çeşitli klinik veri türleri kullanılır:

Klinik veriler; hastanın tıbbi geçmişi, teşhisler, tedaviler, laboratuvar sonuçları, görüntüleme çalışmaları ve diğer ilgili sağlık bilgileri dahil olmak üzere bireylerin sağlık hizmetlerine ilişkin bilgileri ifade eder.
EHR/EMR verileri Demografik verilerle bağlantılıdır (Buna yaş, cinsiyet, etnik köken ve iletişim bilgileri gibi kişisel bilgiler dahildir.), Hasta tarafından oluşturulan veriler (Hasta tarafından bildirilen sonuç ölçümleri ve hasta tarafından bildirilen sonuç ölçütleri aracılığıyla toplanan bilgiler de dahil olmak üzere, hastaların kendileri tarafından oluşturulan veriler) -oluşturulan sağlık verileri.)
Diğer veri kümeleri şunlardır:
Genomik Veri: Bu tür, bireyin DNA dizileri ve belirteçleri de dahil olmak üzere genetik bilgisiyle ilgilidir.
Giyilebilir Cihaz Verileri: Bu veriler, kondisyon takip cihazları ve kalp monitörleri gibi giyilebilir cihazlardan toplanan bilgileri içerir.
Her tür klinik veri, hastanın sağlığına ilişkin kapsamlı bir görünüm sağlamada benzersiz bir rol oynar ve sağlık hizmeti sağlayıcıları ve araştırmacılar tarafından hasta bakımını iyileştirmek ve tedavi kararlarını bilgilendirmek için farklı şekillerde kullanılır.
Sağlık Sektöründe NLP'nin Kullanım Örnekleri ve Uygulamaları
Doğal Dil İşleme (NLP), sağlık sektöründe geniş çapta benimsenmiştir ve çeşitli kullanım durumları vardır. Öne çıkanlardan bazıları şunlardır:
Nüfus Sağlığı: NLP, kalıpları, korelasyonları ve içgörüleri belirlemek amacıyla tıbbi kayıtlar, anketler ve talep verileri gibi büyük miktarlarda yapılandırılmamış tıbbi verileri işlemek için kullanılabilir. Bu, toplum sağlığının izlenmesine ve hastalıkların erken teşhisine yardımcı olur.
Hasta bakımı: NLP, teşhis, ilaçlar ve semptomlar gibi hayati bilgileri çıkarmak için hastaların elektronik sağlık kayıtlarını (EHR'ler) işlemek için kullanılabilir. Bu bilgiler hasta bakımını iyileştirmek ve kişiselleştirilmiş tedavi sağlamak için kullanılabilir.
Hastalık Tespiti: NLP, bulaşıcı hastalık salgınlarını tespit etmek amacıyla bilimsel makaleler, haber makaleleri ve sosyal medya gönderileri gibi büyük miktarda metin verisini işlemek için kullanılabilir.
Klinik Karar Destek Sistemi (CDSS): NLP, sağlık hizmeti sağlayıcılarına gerçek zamanlı karar desteği sağlamak amacıyla hastaların elektronik sağlık kayıtlarını analiz etmek için kullanılabilir. Bu, mümkün olan en iyi tedavi seçeneklerinin sağlanmasına ve genel bakım kalitesinin iyileştirilmesine yardımcı olur.
Klinik çalışma: NLP, korelasyonları ve potansiyel yeni tedavileri belirlemek için klinik deney verilerini işleyebilir.
Uyuşturucu Yan Etkileri: NLP, advers olayları ve ilaç etkileşimlerini belirlemek amacıyla büyük miktarda ilaç güvenliği verisini işlemek için kullanılabilir.
Hassas Sağlık: NLP, bireysel hastalar için kişiselleştirilmiş tedavi seçeneklerini belirlemek amacıyla genomik verileri ve tıbbi kayıtları işlemek için kullanılabilir.
Tıp Uzmanının Verimliliğinin Artırılması: NLP, tıbbi kodlama, veri girişi ve talep işleme gibi rutin görevleri otomatikleştirerek tıp profesyonellerinin daha iyi hasta bakımı sağlamaya odaklanmasını sağlar.
Bunlar NLP'nin sağlık sektöründe nasıl devrim yarattığının sadece birkaç örneğidir. NLP teknolojisi ilerlemeye devam ettikçe, gelecekte NLP'nin sağlık hizmetlerinde daha yenilikçi kullanımlarını görmeyi bekleyebiliriz.
Klinik Metinle NLP Boru Hattı Nasıl Oluşturulur?
Klinik Metin için SciSpacy NER Modelini kullanarak adım adım bir Spacy işlem hattı geliştireceğiz.
Nesnel: Bu proje, klinik metinlerde özel Adlandırılmış Varlık Tanıma işlemini gerçekleştirmek için SciSpacy'yi kullanan bir NLP hattı oluşturmayı amaçlamaktadır.
Sonuç: Sonuç, klinik metinlerden hastalıklar, ilaçlar ve ilaç dozlarına ilişkin bilgilerin çıkarılması olacak ve bunlar daha sonra çeşitli NLP alt uygulamalarında kullanılabilecek.
Çözüm tasarımı:
İşte Klinik Metinden varlık bilgilerini çıkarmaya yönelik üst düzey çözüm. NER çıkarma, NLP işlem hatlarının çoğunda kullanılan önemli bir NLP görevidir.
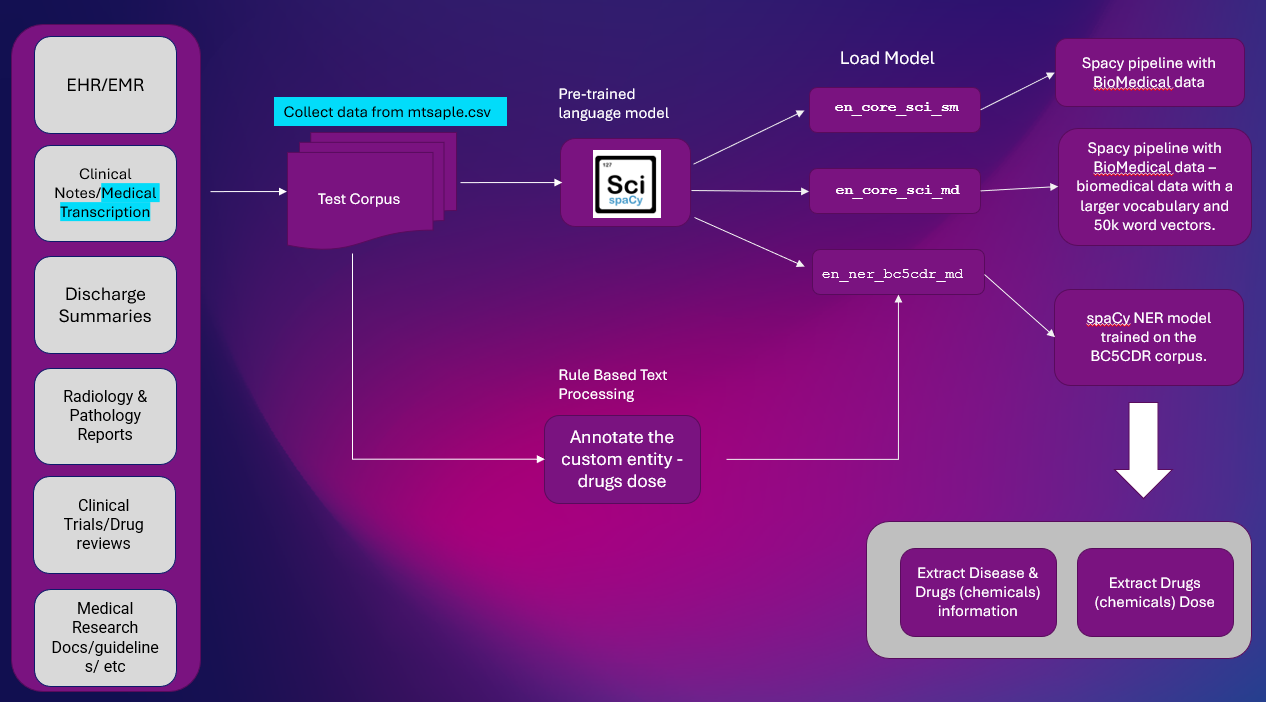
Platform: Google İşbirliği
NLP Kütüphaneleri: spaCy ve BilimSpacy
Veri kümesi: mtsample.csv (mtsample'dan alınan veriler).
Kullandık ScispaCy önceden eğitilmiş NER modeli tr_ner_bc5cdr_md-0.5.1 hastalıkları ve ilaçları çıkarmak için. İlaçlar Kimyasal olarak çıkarılır.
en_ner_bc5cdr_md-0.5.1, biyomedikal alanda adlandırılmış varlık tanıma (NER) için bir spaCy modelidir.
“bc5cdr” şunu ifade eder: BC5CDR modeli eğitmek için kullanılan bir biyomedikal metin külliyatı. Adındaki “md” biyomedikal alanı ifade etmektedir. Adındaki “0.5.1” modelin versiyonunu ifade ediyor.
İlaç dozlarını çıkarmak için mtsample.csv'deki örnek "transkripsiyon" metnini kullanacağız ve kural tabanlı bir model kullanarak açıklama ekleyeceğiz.
Adım Adım Kod:
Spacy ve scistacy Paketlerini yükleyin. spaCy modelleri, tokenizasyon, konuşma bölümü etiketleme ve adlandırılmış varlık tanıma gibi belirli NLP görevlerini gerçekleştirmek üzere tasarlanmıştır.
!pip kurulum -U spacy !pip kurulum scispacy
Scistacy temel modellerini ve NER modellerini yükleyin
en_ner_bc5cdr_md-0.5.1 modeli, biyomedikal metinlerde hastalıklar, genler ve ilaçlar gibi adlandırılmış varlıkları kimyasal olarak tanımak için özel olarak tasarlanmıştır.
Bu model, biyomedikal alandaki bilgi çıkarma, metin sınıflandırma ve soru cevaplama gibi NLP görevleri için yararlı olabilir.
!pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_sm-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_md-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_ner_bc5cdr_md-0.5.1.tar.gz
Diğer Paketleri Kur
pip yükleme oluşturma
Paketleri İçe Aktar
import scispacy import spacy #Core modelleri import en_core_sci_sm import en_core_sci_md
#NER'e özgü modeller import en_ner_bc5cdr_md #Spacy import displacy'den verileri çıkarmak ve görüntülemek için araçlar pandaları pd olarak içe aktarın
Python Kodu:
Modelleri örnek verilerle test edin
# Kullanılacak spesifik transkripsiyonu seçin (satır 3, sütun "transkripsiyon") ve scispacy NER modelini test edin text = mtsample_df.loc[10, "transcription"]

Belirli bir modeli yükleyin: en_core_sci_sm ve metni iletin
nlp_sm = en_core_sci_sm.load() doc = nlp_sm(metin)
#Sonucu görüntüle
varlık çıkarma displacy_image = displacy.render(doc, jupyter=True,style='ent')

Varlığın burada etiketlendiğini unutmayın. Çoğunlukla tıbbi terimler. Ancak bunlar genel varlıklardır.
Şimdi belirli modeli yükleyin: en_core_sci_md ve metni iletin
nlp_md = en_core_sci_md.load() doc = nlp_md(metin)
#Sonuçta ortaya çıkan varlık çıkarımını görüntüle
displacy_image = displacy.render(belge, jupyter=Doğru, stil='ent')

Bu kez sayılar en_core_sci_md tarafından varlıklar olarak da etiketlendi.
Şimdi belirli bir modeli yükleyin: en_ner_bc5cdr_md dosyasını içe aktarın ve metni iletin
nlp_bc = en_ner_bc5cdr_md.load() doc = nlp_bc(text) #Sonuçta varlık çıkartmayı görüntüle displacy_image = displacy.render(doc, jupyter=True,style='ent')

Artık iki tıbbi varlık etiketlendi: hastalık ve kimyasal (ilaçlar).
Varlığı görüntüle
doc.ents'te ent için print("TEXT", "START", "END", "ENTITY TYPE"): print(ent.text, ent.start_char, ent.end_char, ent.label_)
METİN BAŞLANGIÇ BİTİŞ VARLIK TÜRÜ
Morbid obezite 26 40 HASTALIK
Morbid obezite 70 84 HASTALIK
kilo kaybı 400 411 HASTALIK
Marcaine 1256 1264 KİMYASAL
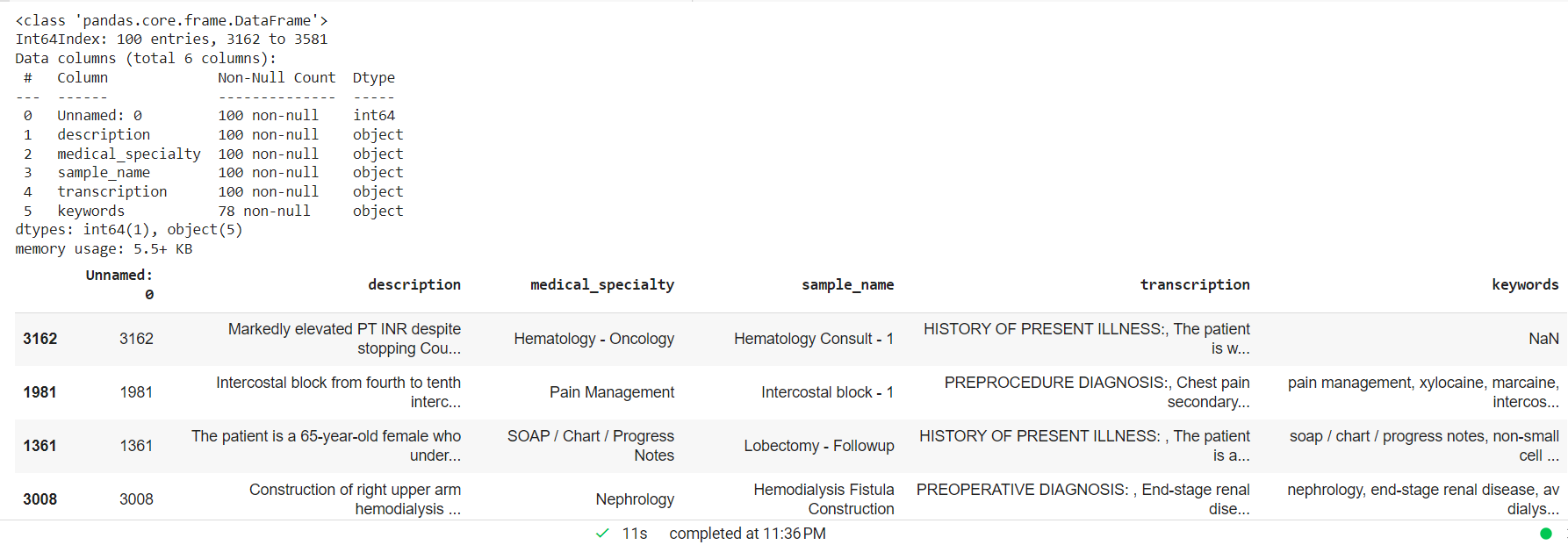
NAN değerlerini bırakarak klinik metni işleyin ve özel varlık modeli için rastgele daha küçük bir örnek oluşturun.
mtsample_df.dropna(subset=['transcription'], inplace=True) mtsample_df_subset = mtsample_df.sample(n=100, replacement=False, random_state=42) mtsample_df_subset.info() mtsample_df_subset.head()
spaCy eşleştirici – Kural tabanlı eşleştirme, normal ifadelerin kullanımına benzer, ancak spaCy ek yetenekler sağlar. Bir belgedeki belirteçleri ve ilişkileri kullanmak, NER modellerinin yardımıyla varlıkları içeren kalıpları tanımlamanıza olanak tanır. Amaç, ilaç adlarını ve dozajlarını metinden bulmaktır; bu, ilaç hatalarını standartlar ve kılavuzlarla karşılaştırarak tespit etmeye yardımcı olabilir.
Amaç, ilaç adlarını ve dozajlarını metinden bulmaktır; bu, ilaç hatalarını standartlar ve kılavuzlarla karşılaştırarak tespit etmeye yardımcı olabilir.
spacy.matcher ithalat Eşleştiricisi'nden
model = [{'ENT_TYPE':'CHEMICAL'}, {'LIKE_NUM': True}, {'IS_ASCII': True}] matcher = Matcher(nlp_bc.vocab) matcher.add("DRUG_DOSE", [pattern])
mtsample_df_subset['transkripsiyon'] içindeki transkripsiyon için: doc = nlp_bc(transkripsiyon) eşleşmeler = match_id, start, end için eşleştirici(doc) eşleşmelerde: string_id = nlp_bc.vocab.strings[match_id] # dize gösterimini al span = doc[start :end] # eşleşen aralık ilaç dozları ekleniyor print(span.text, start, end, string_id,) #Belgelerdeki ent için hastalık ve ilaçları ekleyin: print(ent.text, ent.start_char, ent.end_char, ent .etiket_)
Çıktı, klinik metin örneğinden çıkarılan varlıkları görüntüleyecektir.
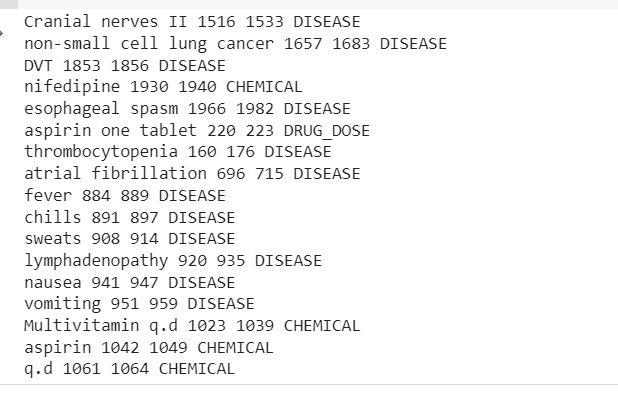
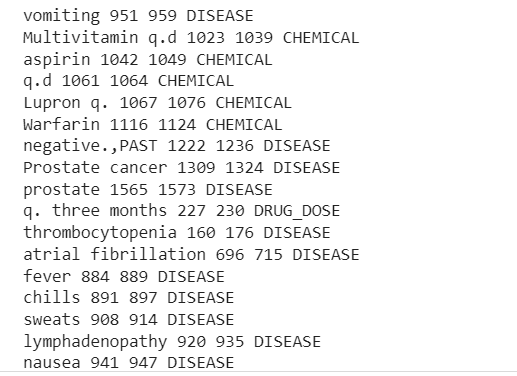
Artık boru hattının çıkarıldığını görebiliriz Hastalık, İlaçlar (Kimyasallar) ve İlaçlar-Dozlar klinik metinden bilgi.
Bazı yanlış sınıflandırmalar var ama daha fazla veri kullanarak modelin performansını arttırabiliriz.
Artık bu tıbbi varlıkları hastalık tespiti, öngörücü analiz, klinik karar destek sistemi, tıbbi metin sınıflandırma, özetleme, soru cevaplama ve daha pek çok görevde kullanabiliriz.
Sonuç
1. Bu makalede, Sağlık Hizmetlerinde NLP'nin karmaşık sağlık hizmetleri metin verilerinin anlaşılmasına yardımcı olacak bazı temel özelliklerini araştırdık.
Ayrıca scispaCy ve spaCy'yi uyguladık ve önceden eğitilmiş bir NER modeli ve kural tabanlı eşleştirici aracılığıyla basit bir özel NER modeli oluşturduk. Yalnızca bir NER modelini ele almış olsak da, çok sayıda başka model ve keşfedilecek çok sayıda ek işlevsellik mevcuttur.
2. Bilim çerçevesinde, kısaltmaları tespit etme, bağımlılık ayrıştırma gerçekleştirme ve tek tek cümleleri tanımlama yöntemleri de dahil olmak üzere keşfedilecek çok sayıda ek teknik vardır.
3. Sağlık hizmetleri için NLP'deki en son trendler arasında BioBERT ve ClinicalBert gibi alana özgü modellerin geliştirilmesi ve GPT-3 gibi büyük dil modellerinin kullanılması yer almaktadır. Bu modeller yüksek düzeyde doğruluk ve verimlilik sunar, ancak bunların kullanımı aynı zamanda önyargı, gizlilik ve veriler üzerindeki kontrol konusundaki endişeleri de artırmaktadır.
ChatGPT (OpenAI tarafından geliştirilen gelişmiş bir konuşma yapay zeka modeli) NLP dünyasında şimdiden büyük bir etki yaratıyor. Model, internetten gelen çok miktarda metin verisi üzerinde eğitiliyor ve aldığı girdiye dayalı olarak insan benzeri metin yanıtları üretme yeteneğine sahip. Soru cevaplama, özetleme, çeviri ve daha fazlası gibi çeşitli görevler için kullanılabilir. Model aynı zamanda kod oluşturma veya makale yazma gibi belirli kullanım durumları için de ince ayar yaparak bu belirli alanlardaki performansını artırıyor.
5. Ancak sayısız faydasına rağmen sağlık hizmetlerinde NLP'nin zorlukları da vardır. NLP modellerinin doğruluğunu ve adilliğini sağlamak ve veri gizliliği endişelerinin üstesinden gelmek, NLP'nin sağlık hizmetlerindeki potansiyelini tam olarak gerçekleştirmek için ele alınması gereken zorluklardan bazılarıdır.
6. Pek çok avantajıyla birlikte sağlık çalışanlarının NLP'yi benimsemesi ve iş akışlarına dahil etmesi önemlidir. Üstesinden gelinmesi gereken pek çok zorluk olsa da sağlık hizmetlerinde NLP kesinlikle izlemeye ve yatırım yapmaya değer bir trend.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/02/extracting-medical-information-from-clinical-text-with-nlp/