Amazon Açık Arama Hizmeti yakın zamanda, dahili karşılaştırmalarda mevcut bellek için optimize edilmiş örneklere göre %1'a kadar fiyat-performans artışı sağlayan OpenSearch Optimize Edilmiş Örnek ailesini (OR30) tanıttı ve Amazon Basit Depolama Hizmeti (Amazon S3) 11 9s dayanıklılık sağlamak için. Bu yeni bulut sunucusu ailesiyle OpenSearch Service, verilerin bulutta nasıl dizine eklendiğini ve depolandığını yeniden tasarlamak için OpenSearch yeniliğini ve AWS teknolojilerini kullanıyor.
Bugün müşteriler, yüksek hacimli verileri alma ve aynı zamanda zengin ve etkileşimli analiz sağlama yeteneği nedeniyle operasyonel analiz için OpenSearch Hizmetini yaygın olarak kullanıyor. Bu faydaları sağlamak için OpenSearch, verileri indeksleyen ve istekleri işleyen birden fazla bağımsız örneğe sahip, yüksek ölçekli bir dağıtılmış sistem olarak tasarlanmıştır. Operasyonel analitik veri hızınız ve veri hacminiz arttıkça darboğazlar ortaya çıkabilir. Yüksek indeksleme hacmini sürdürülebilir bir şekilde desteklemek ve dayanıklılık sağlamak için OR1 bulut sunucusu ailesini oluşturduk.
Bu yazıda, yeniden tasarlanan veri akışının OR1 bulut sunucularıyla nasıl çalıştığını ve yeni bir fiziksel çoğaltma protokolü kullanarak nasıl yüksek dizin oluşturma verimi ve dayanıklılık sağlayabileceğini tartışıyoruz. Ayrıca doğruluğu ve veri bütünlüğünü korumak için çözdüğümüz bazı zorlukları da derinlemesine inceliyoruz.
11 9s dayanıklılıkla yüksek verim için tasarım
OpenSearch Hizmeti on binlerce OpenSearch kümesini yönetir. Müşterilerin yüksek verim ve dayanıklılık hedeflerini karşılamak için kullandığı tipik küme yapılandırmalarına ilişkin bilgiler edindik. Daha yüksek verim elde etmek için müşteriler genellikle çoğaltma gecikmesinden tasarruf etmek amacıyla kopya kopyaları bırakmayı tercih eder; ancak bu yapılandırma kullanılabilirlik ve dayanıklılıktan ödün verilmesine neden olur. Diğer müşteriler ise yüksek dayanıklılığa ihtiyaç duyuyor ve bunun sonucunda da birden fazla kopya bulundurmak zorunda kalıyor, bu da onlar için daha yüksek işletme maliyetlerine neden oluyor.
OpenSearch Optimize Edilmiş Bulut Sunucusu ailesi, verilerin bir kopyasını Amazon S3'te depolayarak maliyetleri düşürmenin yanı sıra ek dayanıklılık da sağlar. OR1 örnekleriyle, dizin oluşturma hızını korurken yüksek okuma kullanılabilirliği için birden fazla replika kopya yapılandırabilirsiniz.
Aşağıdaki diyagramda OR1'deki meta veri güncellemesini içeren bir indeksleme akışı gösterilmektedir
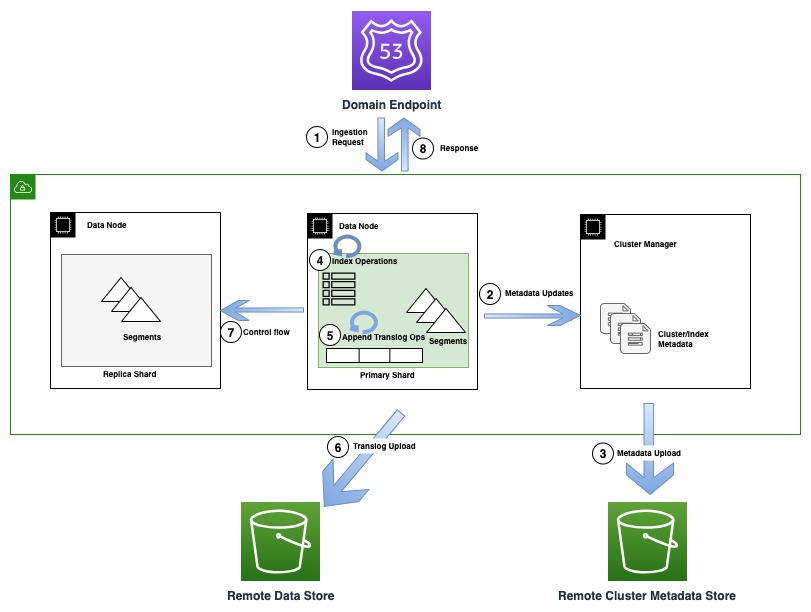
İndeksleme işlemleri sırasında, tek tek belgeler Lucene'ye indekslenir ve aynı zamanda translog olarak da bilinen bir yazma öncesi günlüğüne eklenir. İstemciye bir onay gönderilmeden önce tüm translog işlemleri Amazon S3 tarafından desteklenen uzak veri deposunda kalıcı hale getirilir. Herhangi bir kopya kopyası yapılandırılmışsa, birincil kopya, doğruluk nedeniyle tüm kopya kopyalarında birden fazla yazıcı (kontrol akışı) olasılığını tespit etmek için kontroller gerçekleştirir.
Aşağıdaki şemada OR1 örneklerinde segment oluşturma ve çoğaltma akışı gösterilmektedir
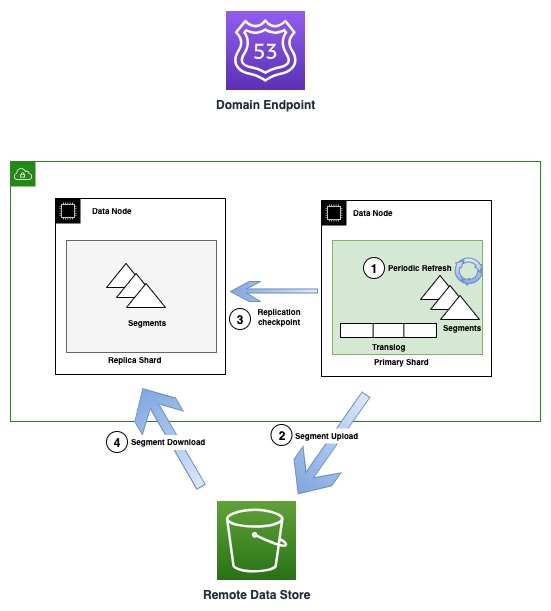
Düzenli olarak yeni segment dosyaları oluşturuldukça OR1 bu segmentleri Amazon S3'e kopyalar. Aktarım tamamlandığında, birincil, tüm kopya kopyalara yeni kontrol noktaları yayınlayarak yeni bir bölümün indirilmeye hazır olduğunu bildirir. Çoğaltma kopyaları daha sonra daha yeni segmentleri indirir ve bunları aranabilir hale getirir. Bu model, Amazon S3 kullanılarak gerçekleşen veri akışı ile düğümler arası aktarım iletişimi üzerinden gerçekleşen kontrol akışını (kontrol noktası yayını ve terim doğrulaması) birbirinden ayırır.
Aşağıdaki şema OR1 bulut sunucularındaki kurtarma akışını göstermektedir

OR1 bulut sunucuları yalnızca verileri değil, Amazon S3'teki dizin eşlemeleri, şablonlar ve ayarlar gibi küme meta verilerini de korur. Bu, özel olmayan küme yöneticisi kurulumlarında yaygın bir hata modu olan küme yöneticisi çekirdek kaybı durumunda OpenSearch'ün en son onaylanan meta verileri güvenilir bir şekilde kurtarabilmesini sağlar.
Altyapı arızası durumunda OpenSearch etki alanı bir veya daha fazla düğümü kaybedebilir. Böyle bir durumda, yeni bulut sunucusu ailesi hem küme meta verilerinin hem de dizin verilerinin en son onaylanan işleme kadar kurtarılmasını garanti eder. Yeni yedek düğümler kümeye katıldıkça, dahili küme kurtarma mekanizması yeni düğüm kümesini önyükler ve ardından uzak küme meta veri deposundan en son küme meta verilerini kurtarır. Küme meta verileri kurtarıldıktan sonra kurtarma mekanizması, eksik segment verilerini ve Amazon S3'teki translogu kurtarmaya başlar. Daha sonra, son onaylanan işleme kadar kaydedilmemiş tüm translog işlemleri, kayıp kopyayı eski haline getirmek için yeniden oynatılır.
Yeni tasarım, aramaların çalışma şeklini değiştirmez. Sorgular, dizindeki her parça için birincil veya kopya parça tarafından normal şekilde işlenir. Veri çoğaltma Amazon S10 kullandığından, tüm kopyaların belirli bir zaman noktasıyla tutarlı hale gelmesinden önce daha uzun gecikmeler (3 saniye aralığında) görebilirsiniz.
Bu mimarinin önemli bir avantajı, okuyucu ve yazarların ayrılması gibi gelecekteki yenilikler için temel bir yapı taşı olarak hizmet vermesi ve bilgi işlem ve depolama katmanlarının ayrılmasına yardımcı olmasıdır.
Çoğaltma stratejisinin yeniden tanımlanması indeksleme verimini nasıl artırır?
OpenSearch iki çoğaltma stratejisini destekler: mantıksal (belge) ve fiziksel (bölüm) çoğaltma. Mantıksal çoğaltma durumunda, veriler tüm kopyalarda bağımsız olarak indekslenir ve bu da kümede gereksiz hesaplama yapılmasına yol açar. OR1 örnekleri yeniyi kullanır fiziksel çoğaltma Verilerin yalnızca birincil kopyada indekslendiği ve birincil kopyadan veri kopyalanarak ek kopyaların oluşturulduğu model. Çok sayıda kopya kopyasıyla, birincil kopyayı barındıran düğüm, segmenti tüm kopyalara çoğaltarak önemli miktarda ağ bant genişliği gerektirir. Yeni OR1 bulut sunucuları, segmenti kalıcı olarak yapılandırılmış olan Amazon S3'te kalıcı hale getirerek bu sorunu çözmektedir. uzak depolama seçenek. Ayrıca birincilde darboğaz olmadan kopyaların ölçeklendirilmesine de yardımcı olurlar.
Segmentler Amazon S3'e yüklendikten sonra birincil, bir kontrol noktası isteği göndererek tüm replikalara yeni segmentleri indirmeleri gerektiğini bildirir. Daha sonra çoğaltma kopyalarının artımlı segmentleri indirmesi gerekir. Bu işlem, verileri çoğaltmak için birincil öğelerde oluşan ağ ek yükünü ve verileri yedekli olarak indekslemek için gerekli olan kopyalardaki bilgi işlem kaynaklarını serbest bıraktığından, küme daha fazla aktarım hızı sağlayabilir. Aşırı yük veya yavaş ağ yolları nedeniyle replikaların yeni oluşturulan segmentleri işleyememesi durumunda, bir noktanın ötesindeki replikalar, eski sonuçlar döndürmelerini önlemek için başarısız olarak işaretlenir.
Yüksek dayanıklılık neden iyi bir fikirdir, ancak bunu başarmak zordur?
Taahhüt edilen tüm segmentler, oluşturuldukları anda Amazon S3'te kalıcı bir şekilde kalıcı hale getirilse de, yüksek dayanıklılığa ulaşmadaki en önemli zorluklardan biri, taahhüt edilmemiş tüm işlemleri, isteği müşteriye geri bildirmeden önce, kaliteden ödün vermeden Amazon S3'teki bir yazma öncesi günlüğüne eş zamanlı olarak yazmaktır. verim. Yeni anlambilim, bireysel istekler için ek ağ gecikmesi sağlar, ancak aktarım hızının hiçbir etkisi olmadığından emin olmamızın yolu, diğer iş parçacıklarının dizine eklemeye devam etmesini sağlarken, belirli bir aralığa kadar tek bir iş parçacığı üzerindeki istekleri toplu olarak toplamak ve boşaltmaktır. istekler. Sonuç olarak, toplu yüklerinizi en iyi şekilde gruplandırarak daha fazla eş zamanlı istemci bağlantısıyla daha yüksek verim elde edebilirsiniz.
Son derece dayanıklı bir sistem tasarlamanın diğer zorlukları arasında veri bütünlüğünün ve doğruluğunun her zaman sağlanması yer alır. Ağ bölümleri gibi bazı olaylar nadir olmasına rağmen sistemin doğruluğunu bozabilir ve bu nedenle sistemin bu arıza modlarıyla baş etmeye hazır olması gerekir. Bu nedenle, yeni segment çoğaltma protokolüne geçerken, her kopyada birden fazla yazıcının algılanması gibi birkaç başka protokol değişikliğini de uygulamaya koyduk. Protokol, yalıtılmış bir yazarın bir yazma isteğini kabul edememesini sağlarken, küme yöneticisi yeter sayısına dayalı olarak yeni tanıtılan başka bir birincil eş zamanlı olarak daha yeni yazma işlemlerini kabul eder.
Yeni bulut sunucusu ailesi, verileri kurtarırken birincil parçanın kaybını otomatik olarak algılıyor ve veriler Amazon S3'ten yeniden oluşturulup küme sağlıklı bir duruma getirilmeden önce ağ erişilebilirliği üzerinde kapsamlı kontroller gerçekleştiriyor.
Veri bütünlüğü açısından, verilerin okunamaz hale gelmesine neden olabilecek ağ veya dosya sistemi bozulmalarını tespit edebildiğimizden ve önleyebildiğimizden emin olmak için tüm dosyalara kapsamlı bir sağlama toplamı uygulanır. Ayrıca, meta veriler de dahil olmak üzere tüm dosyalar, bozulmalara karşı ek güvenlik sağlayacak şekilde değiştirilemez şekilde tasarlanmış ve değişikliklerin kazara değişmesini önleyecek şekilde sürümlendirilmiştir.
Veri akışının nasıl yeniden tasarlanması
OR1 bulut sunucuları, bir altyapı arızası sırasında kaybolan parçaların kurtarılmasını gerçekleştirmek için kopyaları doğrudan Amazon S3'ten hidratlar. Amazon S3'ü kullanarak birincil düğümün ağ bant genişliğini, disk verimini ve bilgi işlem miktarını serbest bırakabiliyoruz ve bu nedenle tüm süreci minimum düzeyde birincil düğüm koordinasyonuyla düzenleyerek daha kusursuz bir yerinde ölçeklendirme ve mavi/yeşil dağıtım deneyimi sağlıyoruz.
OpenSearch Hizmeti, çağrılan otomatik veri yedeklemelerini sağlar anlık saatlik aralıklarla, yani verilerde kazara değişiklik yapılması durumunda, zaman durumunda önceki bir noktaya geri dönme seçeneğiniz vardır. Ancak yeni OpenSearch bulut sunucusu ailesiyle birlikte verilerin Amazon S3'te zaten kalıcı bir şekilde saklandığını tartıştık. Peki veriler Amazon S3'te zaten mevcutken anlık görüntüler nasıl çalışır?
Yeni bulut sunucusu ailesinde anlık görüntüler, belirli bir zamanda mevcut olan mevcut segment verilerine referans vererek kontrol noktaları görevi görür. Bu, anlık görüntülerin daha hafif ve daha hızlı olmasını sağlar çünkü herhangi bir ek veriyi yeniden yüklemelerine gerek kalmaz. Bunun yerine, segmentlerin o andaki görünümünü yakalayan meta veri dosyalarını yüklerler. sığ anlık görüntüler. Sığ anlık görüntülerin faydası, anlık görüntülerin oluşturulması, silinmesi ve klonlanması gibi tüm işlemleri kapsar. Hala bağımsız bir kopyanın anlık görüntüsünü alma seçeneğiniz var. manuel anlık görüntüler diğer idari işlemler için.
Özet
OpenSearch açık kaynaklı, topluluk odaklı bir yazılımdır. Çoğaltma modeli, uzak destekli depolama ve uzak küme meta verileri dahil olmak üzere temel değişikliklerin çoğu açık kaynağa katkıda bulunmuştur; aslında açık kaynaklı bir ilk geliştirme modelini takip ediyoruz.
Verimi ve güvenilirliği artırma çabaları, öğrenmeye ve gelişmeye devam ettikçe hiç bitmeyen bir döngüdür. Yeni OpenSearch için optimize edilmiş örnekler, temel bir yapı taşı görevi görerek gelecekteki yeniliklerin önünü açıyor. Güvenilirliği ve performansı artırma çabalarımıza devam etmekten ve OpenSearch Hizmetini kullanarak hangi yeni ve mevcut çözüm oluşturucuların yaratabileceğini görmekten heyecan duyuyoruz. Bunun, yeni OpenSearch bulut sunucusu ailesinin, bu teklifin nasıl yüksek dayanıklılık ve daha iyi verim elde ettiğinin ve kümeleri işletmenizin ihtiyaçlarına göre yapılandırmanıza nasıl yardımcı olabileceğinin daha derinlemesine anlaşılmasına yol açacağını umuyoruz.
OpenSearch'e katkıda bulunmaktan heyecan duyuyorsanız, bir GitHub sorunu ve düşüncelerinizi bize bildirin. Ayrıca OpenSearch Hizmetinde yüksek verim ve dayanıklılık elde eden başarı öykülerinizi de duymak isteriz. Başka sorularınız varsa lütfen yorum bırakın.
Yazarlar Hakkında
 Buktaver Han Amazon OpenSearch Hizmeti üzerinde çalışan bir Baş Mühendistir. Dağıtılmış ve otonom sistemler oluşturmakla ilgileniyor. OpenSearch'ün bakımını yapan ve aktif bir katılımcısıdır.
Buktaver Han Amazon OpenSearch Hizmeti üzerinde çalışan bir Baş Mühendistir. Dağıtılmış ve otonom sistemler oluşturmakla ilgileniyor. OpenSearch'ün bakımını yapan ve aktif bir katılımcısıdır.
 Gaurav Bafna Amazon Web Services'ta OpenSearch üzerinde çalışan Kıdemli Yazılım Mühendisidir. Dağıtılmış sistemlerde problem çözme konusunda büyülenmiştir. OpenSearch'ün bakımını yapan ve aktif bir katılımcısıdır.
Gaurav Bafna Amazon Web Services'ta OpenSearch üzerinde çalışan Kıdemli Yazılım Mühendisidir. Dağıtılmış sistemlerde problem çözme konusunda büyülenmiştir. OpenSearch'ün bakımını yapan ve aktif bir katılımcısıdır.
 Saçin Kale AWS'de OpenSearch üzerinde çalışan kıdemli bir yazılım geliştirme mühendisidir.
Saçin Kale AWS'de OpenSearch üzerinde çalışan kıdemli bir yazılım geliştirme mühendisidir.
 Rohin Bhargava Amazon OpenSearch Service ekibinde Kıdemli Ürün Yöneticisidir. AWS'deki tutkusu, müşterilerin iş hedefleri için başarıya ulaşmaları için doğru AWS hizmetleri karışımını bulmalarına yardımcı olmaktır.
Rohin Bhargava Amazon OpenSearch Service ekibinde Kıdemli Ürün Yöneticisidir. AWS'deki tutkusu, müşterilerin iş hedefleri için başarıya ulaşmaları için doğru AWS hizmetleri karışımını bulmalarına yardımcı olmaktır.
 Ranjith Ramachandra Amazon OpenSearch Hizmeti üzerinde çalışan bir Kıdemli Mühendislik Yöneticisidir. Yüksek oranda ölçeklenebilir dağıtılmış sistemler, yüksek performans ve esnek sistemler konusunda tutkulu.
Ranjith Ramachandra Amazon OpenSearch Hizmeti üzerinde çalışan bir Kıdemli Mühendislik Yöneticisidir. Yüksek oranda ölçeklenebilir dağıtılmış sistemler, yüksek performans ve esnek sistemler konusunda tutkulu.
Amazon OpenSearch Hizmeti Genel Bakış : OpenSearch Optimize Edilmiş Örnekler(OR1) | Amazon Web Hizmetleri
Plato tarafından yeniden yayınlandı
Amazon Açık Arama Hizmeti yakın zamanda, dahili karşılaştırmalarda mevcut bellek için optimize edilmiş örneklere göre %1'a kadar fiyat-performans artışı sağlayan OpenSearch Optimize Edilmiş Örnek ailesini (OR30) tanıttı ve Amazon Basit Depolama Hizmeti (Amazon S3) 11 9s dayanıklılık sağlamak için. Bu yeni bulut sunucusu ailesiyle OpenSearch Service, verilerin bulutta nasıl dizine eklendiğini ve depolandığını yeniden tasarlamak için OpenSearch yeniliğini ve AWS teknolojilerini kullanıyor.
Bugün müşteriler, yüksek hacimli verileri alma ve aynı zamanda zengin ve etkileşimli analiz sağlama yeteneği nedeniyle operasyonel analiz için OpenSearch Hizmetini yaygın olarak kullanıyor. Bu faydaları sağlamak için OpenSearch, verileri indeksleyen ve istekleri işleyen birden fazla bağımsız örneğe sahip, yüksek ölçekli bir dağıtılmış sistem olarak tasarlanmıştır. Operasyonel analitik veri hızınız ve veri hacminiz arttıkça darboğazlar ortaya çıkabilir. Yüksek indeksleme hacmini sürdürülebilir bir şekilde desteklemek ve dayanıklılık sağlamak için OR1 bulut sunucusu ailesini oluşturduk.
Bu yazıda, yeniden tasarlanan veri akışının OR1 bulut sunucularıyla nasıl çalıştığını ve yeni bir fiziksel çoğaltma protokolü kullanarak nasıl yüksek dizin oluşturma verimi ve dayanıklılık sağlayabileceğini tartışıyoruz. Ayrıca doğruluğu ve veri bütünlüğünü korumak için çözdüğümüz bazı zorlukları da derinlemesine inceliyoruz.
11 9s dayanıklılıkla yüksek verim için tasarım
OpenSearch Hizmeti on binlerce OpenSearch kümesini yönetir. Müşterilerin yüksek verim ve dayanıklılık hedeflerini karşılamak için kullandığı tipik küme yapılandırmalarına ilişkin bilgiler edindik. Daha yüksek verim elde etmek için müşteriler genellikle çoğaltma gecikmesinden tasarruf etmek amacıyla kopya kopyaları bırakmayı tercih eder; ancak bu yapılandırma kullanılabilirlik ve dayanıklılıktan ödün verilmesine neden olur. Diğer müşteriler ise yüksek dayanıklılığa ihtiyaç duyuyor ve bunun sonucunda da birden fazla kopya bulundurmak zorunda kalıyor, bu da onlar için daha yüksek işletme maliyetlerine neden oluyor.
OpenSearch Optimize Edilmiş Bulut Sunucusu ailesi, verilerin bir kopyasını Amazon S3'te depolayarak maliyetleri düşürmenin yanı sıra ek dayanıklılık da sağlar. OR1 örnekleriyle, dizin oluşturma hızını korurken yüksek okuma kullanılabilirliği için birden fazla replika kopya yapılandırabilirsiniz.
Aşağıdaki diyagramda OR1'deki meta veri güncellemesini içeren bir indeksleme akışı gösterilmektedir
İndeksleme işlemleri sırasında, tek tek belgeler Lucene'ye indekslenir ve aynı zamanda translog olarak da bilinen bir yazma öncesi günlüğüne eklenir. İstemciye bir onay gönderilmeden önce tüm translog işlemleri Amazon S3 tarafından desteklenen uzak veri deposunda kalıcı hale getirilir. Herhangi bir kopya kopyası yapılandırılmışsa, birincil kopya, doğruluk nedeniyle tüm kopya kopyalarında birden fazla yazıcı (kontrol akışı) olasılığını tespit etmek için kontroller gerçekleştirir.
Aşağıdaki şemada OR1 örneklerinde segment oluşturma ve çoğaltma akışı gösterilmektedir
Düzenli olarak yeni segment dosyaları oluşturuldukça OR1 bu segmentleri Amazon S3'e kopyalar. Aktarım tamamlandığında, birincil, tüm kopya kopyalara yeni kontrol noktaları yayınlayarak yeni bir bölümün indirilmeye hazır olduğunu bildirir. Çoğaltma kopyaları daha sonra daha yeni segmentleri indirir ve bunları aranabilir hale getirir. Bu model, Amazon S3 kullanılarak gerçekleşen veri akışı ile düğümler arası aktarım iletişimi üzerinden gerçekleşen kontrol akışını (kontrol noktası yayını ve terim doğrulaması) birbirinden ayırır.
Aşağıdaki şema OR1 bulut sunucularındaki kurtarma akışını göstermektedir
OR1 bulut sunucuları yalnızca verileri değil, Amazon S3'teki dizin eşlemeleri, şablonlar ve ayarlar gibi küme meta verilerini de korur. Bu, özel olmayan küme yöneticisi kurulumlarında yaygın bir hata modu olan küme yöneticisi çekirdek kaybı durumunda OpenSearch'ün en son onaylanan meta verileri güvenilir bir şekilde kurtarabilmesini sağlar.
Altyapı arızası durumunda OpenSearch etki alanı bir veya daha fazla düğümü kaybedebilir. Böyle bir durumda, yeni bulut sunucusu ailesi hem küme meta verilerinin hem de dizin verilerinin en son onaylanan işleme kadar kurtarılmasını garanti eder. Yeni yedek düğümler kümeye katıldıkça, dahili küme kurtarma mekanizması yeni düğüm kümesini önyükler ve ardından uzak küme meta veri deposundan en son küme meta verilerini kurtarır. Küme meta verileri kurtarıldıktan sonra kurtarma mekanizması, eksik segment verilerini ve Amazon S3'teki translogu kurtarmaya başlar. Daha sonra, son onaylanan işleme kadar kaydedilmemiş tüm translog işlemleri, kayıp kopyayı eski haline getirmek için yeniden oynatılır.
Yeni tasarım, aramaların çalışma şeklini değiştirmez. Sorgular, dizindeki her parça için birincil veya kopya parça tarafından normal şekilde işlenir. Veri çoğaltma Amazon S10 kullandığından, tüm kopyaların belirli bir zaman noktasıyla tutarlı hale gelmesinden önce daha uzun gecikmeler (3 saniye aralığında) görebilirsiniz.
Bu mimarinin önemli bir avantajı, okuyucu ve yazarların ayrılması gibi gelecekteki yenilikler için temel bir yapı taşı olarak hizmet vermesi ve bilgi işlem ve depolama katmanlarının ayrılmasına yardımcı olmasıdır.
Çoğaltma stratejisinin yeniden tanımlanması indeksleme verimini nasıl artırır?
OpenSearch iki çoğaltma stratejisini destekler: mantıksal (belge) ve fiziksel (bölüm) çoğaltma. Mantıksal çoğaltma durumunda, veriler tüm kopyalarda bağımsız olarak indekslenir ve bu da kümede gereksiz hesaplama yapılmasına yol açar. OR1 örnekleri yeniyi kullanır fiziksel çoğaltma Verilerin yalnızca birincil kopyada indekslendiği ve birincil kopyadan veri kopyalanarak ek kopyaların oluşturulduğu model. Çok sayıda kopya kopyasıyla, birincil kopyayı barındıran düğüm, segmenti tüm kopyalara çoğaltarak önemli miktarda ağ bant genişliği gerektirir. Yeni OR1 bulut sunucuları, segmenti kalıcı olarak yapılandırılmış olan Amazon S3'te kalıcı hale getirerek bu sorunu çözmektedir. uzak depolama seçenek. Ayrıca birincilde darboğaz olmadan kopyaların ölçeklendirilmesine de yardımcı olurlar.
Segmentler Amazon S3'e yüklendikten sonra birincil, bir kontrol noktası isteği göndererek tüm replikalara yeni segmentleri indirmeleri gerektiğini bildirir. Daha sonra çoğaltma kopyalarının artımlı segmentleri indirmesi gerekir. Bu işlem, verileri çoğaltmak için birincil öğelerde oluşan ağ ek yükünü ve verileri yedekli olarak indekslemek için gerekli olan kopyalardaki bilgi işlem kaynaklarını serbest bıraktığından, küme daha fazla aktarım hızı sağlayabilir. Aşırı yük veya yavaş ağ yolları nedeniyle replikaların yeni oluşturulan segmentleri işleyememesi durumunda, bir noktanın ötesindeki replikalar, eski sonuçlar döndürmelerini önlemek için başarısız olarak işaretlenir.
Yüksek dayanıklılık neden iyi bir fikirdir, ancak bunu başarmak zordur?
Taahhüt edilen tüm segmentler, oluşturuldukları anda Amazon S3'te kalıcı bir şekilde kalıcı hale getirilse de, yüksek dayanıklılığa ulaşmadaki en önemli zorluklardan biri, taahhüt edilmemiş tüm işlemleri, isteği müşteriye geri bildirmeden önce, kaliteden ödün vermeden Amazon S3'teki bir yazma öncesi günlüğüne eş zamanlı olarak yazmaktır. verim. Yeni anlambilim, bireysel istekler için ek ağ gecikmesi sağlar, ancak aktarım hızının hiçbir etkisi olmadığından emin olmamızın yolu, diğer iş parçacıklarının dizine eklemeye devam etmesini sağlarken, belirli bir aralığa kadar tek bir iş parçacığı üzerindeki istekleri toplu olarak toplamak ve boşaltmaktır. istekler. Sonuç olarak, toplu yüklerinizi en iyi şekilde gruplandırarak daha fazla eş zamanlı istemci bağlantısıyla daha yüksek verim elde edebilirsiniz.
Son derece dayanıklı bir sistem tasarlamanın diğer zorlukları arasında veri bütünlüğünün ve doğruluğunun her zaman sağlanması yer alır. Ağ bölümleri gibi bazı olaylar nadir olmasına rağmen sistemin doğruluğunu bozabilir ve bu nedenle sistemin bu arıza modlarıyla baş etmeye hazır olması gerekir. Bu nedenle, yeni segment çoğaltma protokolüne geçerken, her kopyada birden fazla yazıcının algılanması gibi birkaç başka protokol değişikliğini de uygulamaya koyduk. Protokol, yalıtılmış bir yazarın bir yazma isteğini kabul edememesini sağlarken, küme yöneticisi yeter sayısına dayalı olarak yeni tanıtılan başka bir birincil eş zamanlı olarak daha yeni yazma işlemlerini kabul eder.
Yeni bulut sunucusu ailesi, verileri kurtarırken birincil parçanın kaybını otomatik olarak algılıyor ve veriler Amazon S3'ten yeniden oluşturulup küme sağlıklı bir duruma getirilmeden önce ağ erişilebilirliği üzerinde kapsamlı kontroller gerçekleştiriyor.
Veri bütünlüğü açısından, verilerin okunamaz hale gelmesine neden olabilecek ağ veya dosya sistemi bozulmalarını tespit edebildiğimizden ve önleyebildiğimizden emin olmak için tüm dosyalara kapsamlı bir sağlama toplamı uygulanır. Ayrıca, meta veriler de dahil olmak üzere tüm dosyalar, bozulmalara karşı ek güvenlik sağlayacak şekilde değiştirilemez şekilde tasarlanmış ve değişikliklerin kazara değişmesini önleyecek şekilde sürümlendirilmiştir.
Veri akışının nasıl yeniden tasarlanması
OR1 bulut sunucuları, bir altyapı arızası sırasında kaybolan parçaların kurtarılmasını gerçekleştirmek için kopyaları doğrudan Amazon S3'ten hidratlar. Amazon S3'ü kullanarak birincil düğümün ağ bant genişliğini, disk verimini ve bilgi işlem miktarını serbest bırakabiliyoruz ve bu nedenle tüm süreci minimum düzeyde birincil düğüm koordinasyonuyla düzenleyerek daha kusursuz bir yerinde ölçeklendirme ve mavi/yeşil dağıtım deneyimi sağlıyoruz.
OpenSearch Hizmeti, çağrılan otomatik veri yedeklemelerini sağlar anlık saatlik aralıklarla, yani verilerde kazara değişiklik yapılması durumunda, zaman durumunda önceki bir noktaya geri dönme seçeneğiniz vardır. Ancak yeni OpenSearch bulut sunucusu ailesiyle birlikte verilerin Amazon S3'te zaten kalıcı bir şekilde saklandığını tartıştık. Peki veriler Amazon S3'te zaten mevcutken anlık görüntüler nasıl çalışır?
Yeni bulut sunucusu ailesinde anlık görüntüler, belirli bir zamanda mevcut olan mevcut segment verilerine referans vererek kontrol noktaları görevi görür. Bu, anlık görüntülerin daha hafif ve daha hızlı olmasını sağlar çünkü herhangi bir ek veriyi yeniden yüklemelerine gerek kalmaz. Bunun yerine, segmentlerin o andaki görünümünü yakalayan meta veri dosyalarını yüklerler. sığ anlık görüntüler. Sığ anlık görüntülerin faydası, anlık görüntülerin oluşturulması, silinmesi ve klonlanması gibi tüm işlemleri kapsar. Hala bağımsız bir kopyanın anlık görüntüsünü alma seçeneğiniz var. manuel anlık görüntüler diğer idari işlemler için.
Özet
OpenSearch açık kaynaklı, topluluk odaklı bir yazılımdır. Çoğaltma modeli, uzak destekli depolama ve uzak küme meta verileri dahil olmak üzere temel değişikliklerin çoğu açık kaynağa katkıda bulunmuştur; aslında açık kaynaklı bir ilk geliştirme modelini takip ediyoruz.
Verimi ve güvenilirliği artırma çabaları, öğrenmeye ve gelişmeye devam ettikçe hiç bitmeyen bir döngüdür. Yeni OpenSearch için optimize edilmiş örnekler, temel bir yapı taşı görevi görerek gelecekteki yeniliklerin önünü açıyor. Güvenilirliği ve performansı artırma çabalarımıza devam etmekten ve OpenSearch Hizmetini kullanarak hangi yeni ve mevcut çözüm oluşturucuların yaratabileceğini görmekten heyecan duyuyoruz. Bunun, yeni OpenSearch bulut sunucusu ailesinin, bu teklifin nasıl yüksek dayanıklılık ve daha iyi verim elde ettiğinin ve kümeleri işletmenizin ihtiyaçlarına göre yapılandırmanıza nasıl yardımcı olabileceğinin daha derinlemesine anlaşılmasına yol açacağını umuyoruz.
OpenSearch'e katkıda bulunmaktan heyecan duyuyorsanız, bir GitHub sorunu ve düşüncelerinizi bize bildirin. Ayrıca OpenSearch Hizmetinde yüksek verim ve dayanıklılık elde eden başarı öykülerinizi de duymak isteriz. Başka sorularınız varsa lütfen yorum bırakın.
Yazarlar Hakkında
Kripto İçin Zorlu Haftada Polkadot ve Cosmos Kazanç Kazandı: CoinDesk Endeks Piyasası Güncellemesi
‘There’s Not Much More Downside Left To Go’: Trader Says Bitcoin Close to Bottom After Deepest Retrace of Cycle – The Daily Hodl
Dünya Çapındaki Hükümetleri DeFi Konusunda Endişelendiren Nedir? – CryptoInfoNet
Portföyünüze Ekleyebileceğiniz En İyi 4 Kripto: BlockDAG, APT, MNTL ve BDJ'de Zirvede
Bitbot'un Ön Satışı Yapay Zeka Geliştirme Güncellemesinin Ardından 3 Milyon Dolarlık Dönüm Noktasına Ulaştı
Bitcoin Milyarderi Arthur Hayes, Piyasanın Dibinin 'Yavaş Yavaş Yükseleceğini' Tahmin Ediyor - Decrypt
Analist: Bu Kripto Boğa Koşusu Neden Geçmişe Kadar Yaşayamayabilir?
BDAG'ın Yeni Ödeme Seçenekleri Arbitrum Sahiplerini Mantle'ın Mücadelesinin Ortasına Çekiyor
NFTBank, NFT Portföyünü ve Web2 Oyun Hazinesi Yönetimini Geliştirmek İçin NFTBank V3'yi Piyasaya Sürüyor
Yapay Zekadan Kentucky Derby Kazananlarını Tahmin Etmesini İstedik - İşte Seçtikleri - Decrypt