
Giriş
Makine Öğrenimi (ML), verilerden otomatik olarak öğrenmek için algoritmalar geliştirmeye, nasıl yapılacağı açıkça söylenmeden tahminlerde bulunmaya ve kalıplar çıkarmaya odaklanan bir çalışma alanıdır. Tecrübe ve verilerle otomatik olarak gelişen sistemler oluşturmayı amaçlar.
Bu, modelin tahminler yapmak için etiketli veriler kullanılarak eğitildiği denetimli öğrenme yoluyla veya modelin tahmin edilecek belirli hedef çıktıları olmadan veriler içindeki kalıpları veya korelasyonları ortaya çıkarmaya çalıştığı denetimsiz öğrenme yoluyla elde edilebilir.
Makine öğrenimi, bilgisayar bilimi, biyoloji, finans ve pazarlama dahil olmak üzere çeşitli disiplinlerde vazgeçilmez ve yaygın olarak kullanılan bir araç olarak ortaya çıkmıştır. Görüntü sınıflandırma, doğal dil işleme ve dolandırıcılık tespiti gibi çeşitli uygulamalarda kullanışlılığını kanıtlamıştır.
Makine Öğrenimi Görevleri
Makine öğrenimi genel olarak üç ana göreve ayrılabilir:
- Denetimli öğrenme
- Denetimsiz öğrenme
- Takviye öğrenimi
Burada ilk iki duruma odaklanacağız.
Denetimli Öğrenme
Denetimli öğrenme, girdi verilerinin karşılık gelen çıktı veya hedef değişkenle eşleştirildiği etiketli veriler üzerinde bir modelin eğitilmesini içerir. Amaç, girdi verilerini doğru çıktıya eşleyebilen bir işlevi öğrenmektir. Yaygın denetimli öğrenme algoritmaları, doğrusal regresyon, lojistik regresyon, karar ağaçları ve destek vektör makinelerini içerir.
Python kullanan denetimli öğrenme kodu örneği:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
Bu basit kod örneğinde, LinearRegression eğitim verilerimiz üzerinde scikit-learn algoritmasını kullanın ve ardından test verilerimiz için tahminler almak üzere uygulayın.
Denetimli öğrenmenin gerçek dünyadaki kullanım durumlarından biri, e-posta spam sınıflandırmasıdır. E-posta iletişiminin katlanarak büyümesiyle birlikte, istenmeyen e-postaları belirlemek ve filtrelemek çok önemli hale geldi. Denetimli öğrenme algoritmalarını kullanarak, etiketlenmiş verilere dayalı olarak meşru e-postalar ile istenmeyen postaları ayırt edecek bir model eğitmek mümkündür.
Denetimli öğrenme modeli, "spam" veya "spam değil" olarak etiketlenmiş e-postaları içeren bir veri kümesi üzerinde eğitilebilir. Model, belirli anahtar kelimelerin varlığı, e-posta yapısı veya e-posta gönderen bilgileri gibi etiketli verilerden kalıpları ve özellikleri öğrenir. Model bir kez eğitildikten sonra, istenmeyen iletileri verimli bir şekilde filtreleyerek gelen e-postaları otomatik olarak istenmeyen posta veya istenmeyen posta olmayan olarak sınıflandırmak için kullanılabilir.
Denetimsiz Öğrenme
Denetimsiz öğrenmede, girdi verileri etiketlenmez ve amaç, veriler içindeki kalıpları veya yapıları keşfetmektir. Denetimsiz öğrenme algoritmaları, verilerde anlamlı temsiller veya kümeler bulmayı amaçlar.
Denetimsiz öğrenme algoritmalarının örnekleri şunları içerir: k-kümeleme anlamına gelir, hiyerarşik kümeleme, ve temel bileşen analizi (PCA).
Denetimsiz öğrenme kodu örneği:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
Bu basit kod örneğinde, KMeans scikit-learn algoritması, verilerimizdeki üç kümeyi tanımlıyor ve ardından yeni verileri bu kümelere sığdırıyor.
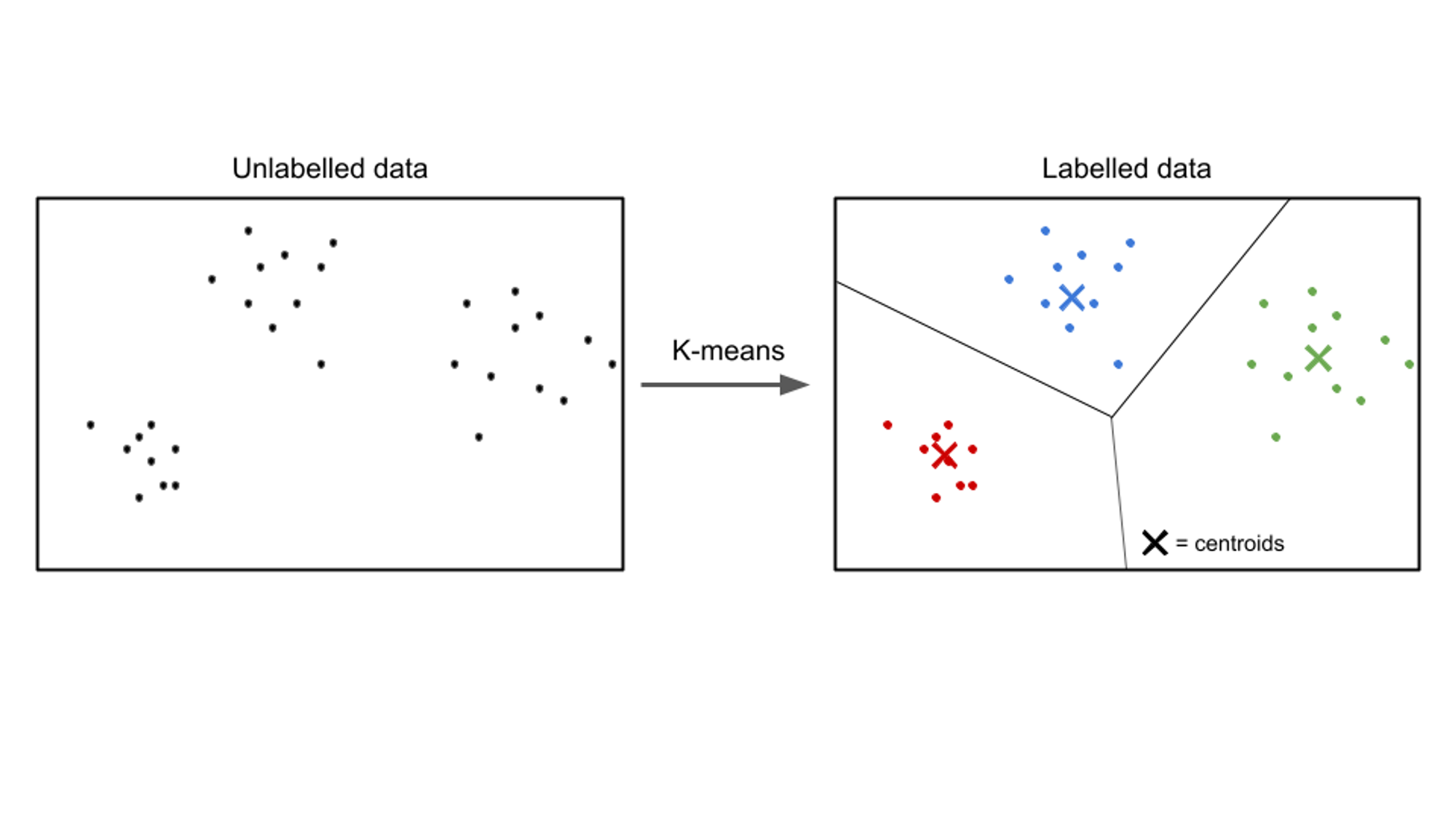
Denetimsiz öğrenme kullanım senaryosuna bir örnek, müşteri segmentasyonudur. Çeşitli sektörlerde işletmeler, pazarlama stratejilerini uyarlamak, tekliflerini kişiselleştirmek ve müşteri deneyimlerini optimize etmek için müşteri tabanlarını daha iyi anlamayı amaçlar. Denetimsiz öğrenme algoritmaları, müşterileri ortak özelliklerine ve davranışlarına göre farklı gruplara ayırmak için kullanılabilir.
En iyi uygulamalar, endüstri tarafından kabul edilen standartlar ve dahil edilen hile sayfası ile Git'i öğrenmek için uygulamalı, pratik kılavuzumuza göz atın. Googling Git komutlarını durdurun ve aslında öğrenmek o!
İşletmeler, kümeleme gibi denetimsiz öğrenme tekniklerini uygulayarak müşteri verileri içindeki anlamlı kalıpları ve grupları ortaya çıkarabilir. Örneğin, kümeleme algoritmaları benzer satın alma alışkanlıklarına, demografik özelliklere veya tercihlere sahip müşteri gruplarını belirleyebilir. Bu bilgiler, hedeflenen pazarlama kampanyaları oluşturmak, ürün tavsiyelerini optimize etmek ve müşteri memnuniyetini artırmak için kullanılabilir.
Ana Algoritma Sınıfları
Denetimli Öğrenme Algoritmaları
-
Doğrusal modeller: Özellikler ve hedef değişken arasındaki doğrusal ilişkilere dayalı olarak sürekli değişkenleri tahmin etmek için kullanılır.
-
Ağaç Tabanlı Modeller: Tahminler veya sınıflandırmalar yapmak için bir dizi ikili karar kullanılarak oluşturulur.
-
Topluluk Modelleri: Daha doğru tahminler yapmak için birden çok modeli (ağaç tabanlı veya doğrusal) birleştiren yöntem.
-
Sinir Ağı Modelleri: Birden fazla işlevin bir ağın düğümleri olarak çalıştığı, genel olarak insan beynine dayanan yöntemler.
Denetimsiz Öğrenme Algoritmaları
-
Hiyerarşik Kümeleme: Yinelemeli olarak birleştirerek veya bölerek bir küme hiyerarşisi oluşturur.
-
Hiyerarşik Olmayan Kümeleme: Verileri benzerliğe göre farklı kümelere ayırır.
-
Boyut Azaltma: En önemli bilgileri korurken verilerin boyutsallığını azaltır.
Model Değerlendirmesi
Denetimli Öğrenme
Denetimli öğrenme modellerinin performansını değerlendirmek için doğruluk, kesinlik, hatırlama, F1 puanı ve ROC-AUC dahil olmak üzere çeşitli ölçütler kullanılır. K-katlı çapraz doğrulama gibi çapraz doğrulama teknikleri, modelin genelleme performansını tahmin etmeye yardımcı olabilir.
Denetimsiz Öğrenme
Denetimsiz öğrenme algoritmalarını değerlendirmek, temel bir gerçek olmadığı için genellikle daha zordur. Kümeleme sonuçlarının kalitesini değerlendirmek için siluet puanı veya atalet gibi metrikler kullanılabilir. Görselleştirme teknikleri, kümelerin yapısına ilişkin içgörüler de sağlayabilir.
İpuçları
Denetimli Öğrenme
- Model performansını iyileştirmek için girdi verilerini önceden işleyin ve normalleştirin.
- Eksik değerleri, atama veya kaldırma yoluyla uygun şekilde işleyin.
- Özellik mühendisliği, modelin ilgili kalıpları yakalama yeteneğini geliştirebilir.
Denetimsiz Öğrenme
- Alan bilgisine dayalı olarak veya dirsek yöntemi gibi teknikleri kullanarak uygun küme sayısını seçin.
- Veri noktaları arasındaki benzerliği ölçmek için farklı mesafe ölçümlerini göz önünde bulundurun.
- Fazla uydurmayı önlemek için kümeleme sürecini düzenli hale getirin.
Özetle, makine öğrenimi çok sayıda görev, teknik, algoritma, model değerlendirme yöntemi ve yardımcı ipuçları içerir. Uygulayıcılar, bu yönleri kavrayarak, makine öğrenimini gerçek dünya sorunlarına verimli bir şekilde uygulayabilir ve verilerden önemli içgörüler elde edebilir. Verilen kod örnekleri, denetimli ve denetimsiz öğrenme algoritmalarının kullanımını gösterir ve bunların pratik uygulamalarını vurgular.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- EVM Finans. Merkezi Olmayan Finans için Birleşik Arayüz. Buradan Erişin.
- Kuantum Medya Grubu. IR/PR Güçlendirilmiş. Buradan Erişin.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Kaynak: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/