
Починаючи з випуску 6.14, Amazon EMR Studio підтримує інтерактивну аналітику на Amazon EMR без сервера. Тепер ви можете використовувати безсерверні програми EMR як обчислення, на додаток до Amazon EMR на кластерах EC2 і Amazon EMR на EKS віртуальні кластери для запуску ноутбуків JupyterLab із робочих просторів EMR Studio.
EMR Studio — це інтегроване середовище розробки (IDE), яке спрощує розробку, візуалізацію та налагодження аналітичних програм, написаних на PySpark, Python і Scala, для науковців та інженерів даних. EMR Serverless – це безсерверний варіант для Amazon EMR це спрощує запуск інфраструктури аналітики великих даних з відкритим кодом, наприклад Apache Spark, без налаштування, керування та масштабування кластерів або серверів.
У дописі ми демонструємо, як зробити наступне:
- Створіть безсерверну кінцеву точку EMR для інтерактивних програм
- Приєднайте кінцеву точку до існуючого середовища EMR Studio
- Створіть блокнот і запустіть інтерактивну програму
- Легко діагностуйте інтерактивні програми з EMR Studio
Передумови
У типовій організації адміністратор облікового запису AWS налаштує такі ресурси AWS, як AWS Identity and Access management (IAM) ролі, Служба простого зберігання Amazon (Amazon S3) відра та Віртуальна приватна хмара Amazon (Amazon VPC) для доступу до Інтернету та доступу до інших ресурсів у VPC. Вони призначають адміністраторів EMR Studio, які керують налаштуванням EMR Studios і призначенням користувачів певній EMR Studio. Після призначення розробники EMR Studio можуть використовувати EMR Studio для розробки та моніторингу робочих навантажень.
Переконайтеся, що ви налаштували такі ресурси, як сегмент S3, підмережі VPC та EMR Studio, у тому самому регіоні AWS.
Виконайте наступні кроки, щоб розгорнути ці передумови:
- Запустіть наступне AWS CloudFormation стек

- Введіть значення для AdminPassword та DevPassword і запишіть створені паролі.
- Вибирати МАЙБУТНІ.
- Збережіть налаштування за замовчуванням і виберіть МАЙБУТНІ знову.
- Select Я розумію, що AWS CloudFormation може створювати ресурси IAM із власними іменами.
- Виберіть Надіслати.
Ми також надали інструкції щодо розгортання цих ресурсів вручну зі зразками політик IAM у GitHub репо.
Налаштуйте EMR Studio та безсерверну інтерактивну програму
Після того, як адміністратор облікового запису AWS виконає необхідні вимоги, адміністратор EMR Studio може увійти в систему Консоль управління AWS для створення програми EMR Studio, Workspace і EMR Serverless.
Створіть EMR Studio та Workspace
Адміністратор EMR Studio повинен увійти в консоль за допомогою emrs-interactive-app-admin-user облікові дані користувача. Якщо ви розгорнули необхідні ресурси за допомогою наданого шаблону CloudFormation, використовуйте пароль, який ви надали як вхідний параметр.
- На консолі Amazon EMR виберіть EMR без сервера у навігаційній панелі.

- Вибирати ПОЧАТИ.
- Select Створіть і запустіть EMR Studio.
Буде створено Studio із назвою за замовчуванням studio_1 і робоча область із назвою за замовчуванням My_First_Workspace. Відкриється нова вкладка браузера для Studio_1 користувацький інтерфейс.
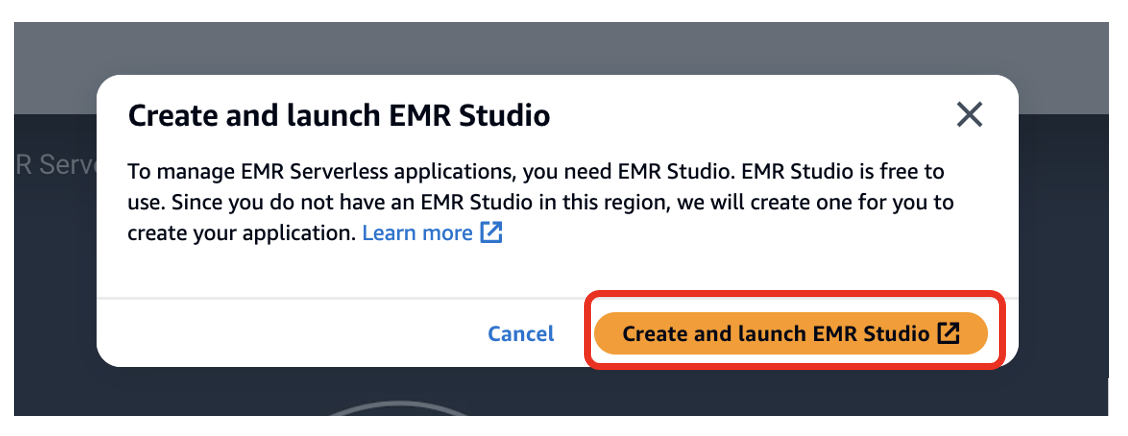
Створіть програму EMR Serverless
Щоб створити безсерверну програму EMR, виконайте такі дії:
- На консолі EMR Studio виберіть додатків у навігаційній панелі.
- Створіть новий додаток.
- для ІМ'Я, введіть назву (наприклад,
my-serverless-interactive-application). - для Параметри налаштування програмивиберіть Використовуйте спеціальні налаштування для інтерактивних навантажень.
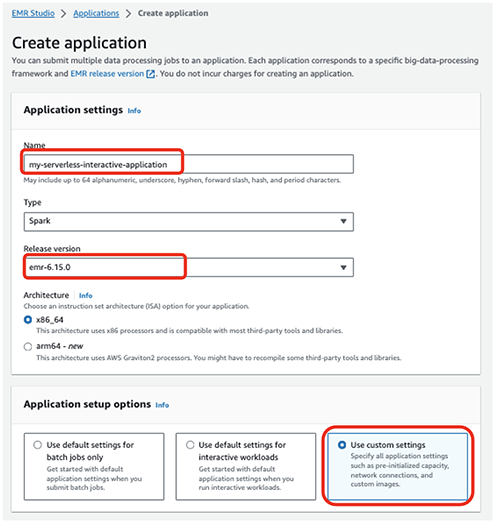
Для інтерактивних програм ми рекомендуємо попередньо ініціалізувати драйвер і робочі програми, налаштувавши попередньо ініціалізована ємність на момент створення програми. Це фактично створює теплий пул працівників для програми та підтримує ресурси, готові до споживання, дозволяючи програмі відповідати за лічені секунди. Додаткові рекомендації щодо створення безсерверних програм EMR див Визначте обмеження ресурсів для кожної команди для робочого навантаження з великими даними за допомогою Amazon EMR Serverless.
- У Інтерактивна кінцева точка розділ, виберіть Увімкнути інтерактивну кінцеву точку.
- У Мережеві з'єднання виберіть VPC, приватні підмережі та групу безпеки, яку ви створили раніше.
Якщо ви розгорнули стек CloudFormation, наданий у цій публікації, виберіть emr-serverless-sg як група безпеки.
VPC необхідний для робочого навантаження, щоб отримати доступ до Інтернету з програми EMR Serverless і завантажувати зовнішні пакети Python. VPC також дозволяє отримати доступ до таких ресурсів, як Служба реляційних баз даних Amazon (Amazon RDS) і Амазонська червона зміна які є у VPC з цієї програми. Підключення безсерверної програми до VPC може призвести до вичерпання IP-адрес у підмережі, тому переконайтеся, що у вашій підмережі достатньо IP-адрес.
- Вибирати Створіть і запустіть додаток.

На сторінці програм ви можете перевірити, чи змінився статус вашої безсерверної програми на Початок.
- Виберіть свою програму та виберіть Як це працює?.
- Вибирати Перегляд і запуск робочих областей.
- Вибирати Налаштувати студію.

- для Службова роль¸ надайте роль служби EMR Studio, яку ви створили як попередню умову (
emr-studio-service-role). - для Зберігання робочого простору, введіть шлях до відра S3, який ви створили як попередню умову (
emrserverless-interactive-blog-<account-id>-<region-name>). - Вибирати зберегти зміни.
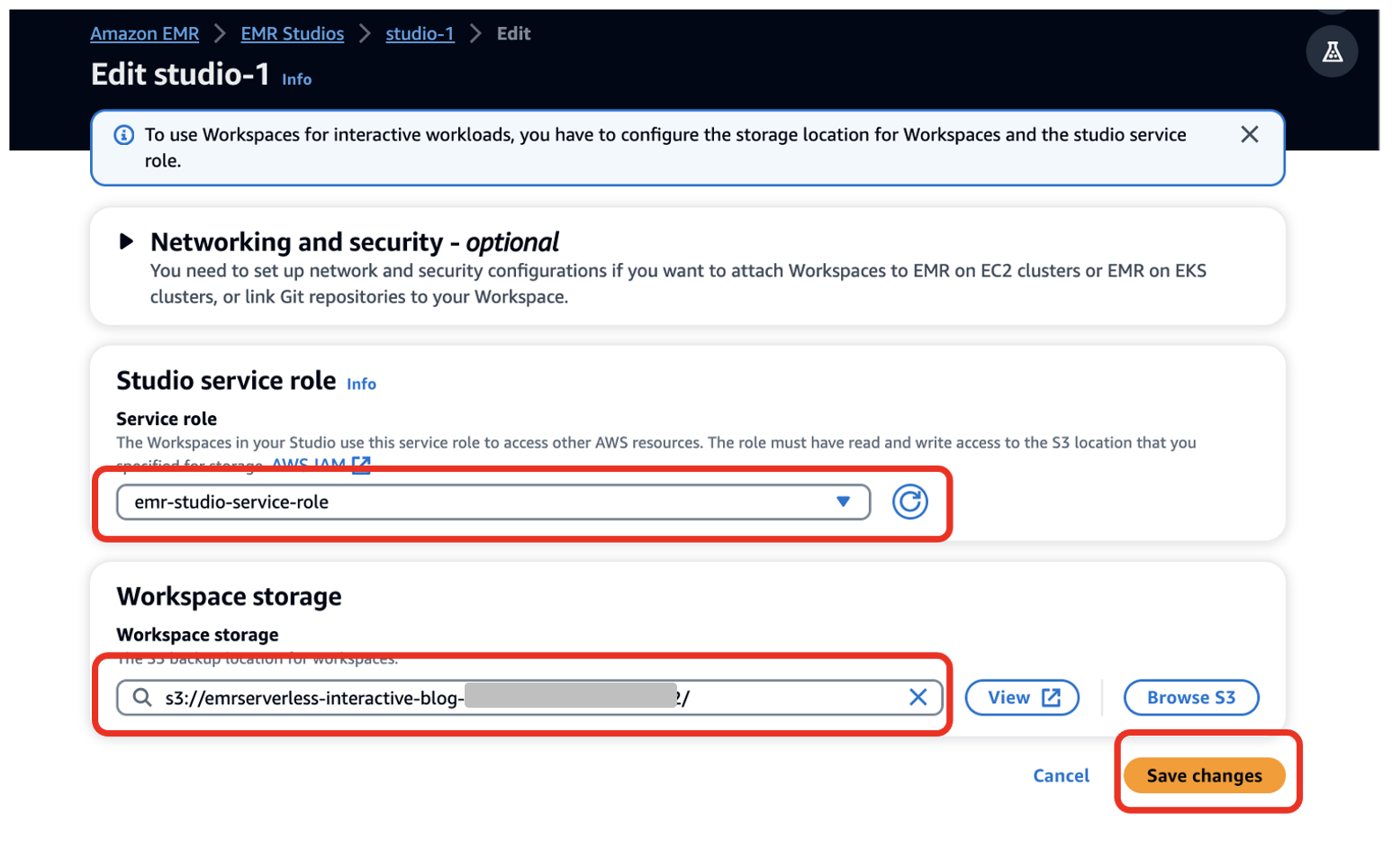
14. Перейдіть до консолі Studios, вибравши студії у лівому навігаційному меню в Студія ЕМР розділ. Зверніть увагу на URL-адреса доступу до студії з консолі Studios і надайте його своїм розробникам для запуску їхніх програм Spark.
Запустіть свою першу програму Spark
Після того як адміністратор EMR Studio створив програму Studio, Workspace і безсерверну програму, користувач Studio може використовувати Workspace і програму для розробки та моніторингу робочих навантажень Spark.
Запустіть Workspace і приєднайте безсерверну програму
Виконайте такі дії:
- Використовуючи URL-адресу Studio, надану адміністратором EMR Studio, увійдіть за допомогою
emrs-interactive-app-dev-userоблікові дані користувача, надані адміністратором облікового запису AWS.
Якщо ви розгорнули необхідні ресурси за допомогою наданого шаблону CloudFormation, використовуйте пароль, який ви надали як вхідний параметр.
на Робочі області ви можете перевірити стан свого робочого простору. Після запуску робочої області ви побачите зміну статусу на Готовий.
- Запустіть робочу область, вибравши назву робочої області (
My_First_Workspace).
Відкриється нова вкладка. Переконайтеся, що ваш браузер дозволяє спливаючі вікна.
- У робочій області виберіть обчислення (піктограма кластера) на панелі навігації.
- для Безсерверна програма EMR, виберіть свою програму (
my-serverless-interactive-application). - для Інтерактивна роль середовища виконання, виберіть інтерактивну роль середовища виконання (для цієї публікації ми використовуємо
emr-serverless-runtime-role). - Вибирати Приєднувати щоб підключити безсерверну програму як тип обчислення для всіх ноутбуків у цій робочій області.

Запустіть програму Spark в інтерактивному режимі
Виконайте такі дії:
- Виберіть Зразки зошитів (значок із трьома крапками) на панелі навігації та відкрийте
Getting-started-with-emr-serverlessзошит. - Вибирати Зберегти в Workspace.
Є три варіанти ядер для нашого ноутбука: Python 3, PySpark і Spark (для Scala).
- Коли з’явиться запит, виберіть PySpark як ядро.
- Вибирати Select.

Тепер ви можете запустити програму Spark. Для цього використовуйте %%configure Sparkmagic команда, яка налаштовує параметри створення сесії. Інтерактивні програми підтримують віртуальні середовища Python. Ми використовуємо спеціальне середовище в робочих вузлах, вказуючи шлях для іншого середовища виконання Python для середовища виконавця за допомогою spark.executorEnv.PYSPARK_PYTHON. Дивіться наступний код:
Встановити зовнішні пакети
Тепер, коли у вас є незалежне віртуальне середовище для працівників, ноутбуки EMR Studio дозволяють встановлювати зовнішні пакети з безсерверної програми за допомогою Spark install_pypi_package функціонувати через контекст Spark. Використання цієї функції робить пакет доступним для всіх безсерверних працівників EMR.
Спочатку встановіть matplotlib, пакет Python, з PyPi:
Якщо попередній крок не відповідає, перевірте налаштування VPC і переконайтеся, що його правильно налаштовано для доступу до Інтернету.
Тепер ви можете використовувати набір даних і візуалізувати свої дані.
Створюйте візуалізації
Для створення візуалізацій ми використовуємо загальнодоступний набір даних про жовті таксі Нью-Йорка:
У попередньому блоці коду ви читаєте файл Parquet із публічного відра в Amazon S3. Файл має заголовки, і ми хочемо, щоб Spark виводив схему. Потім ви використовуєте фрейм даних Spark для групування та підрахунку певних стовпців taxi_df:
Скористайтесь %%display magic, щоб переглянути результат у форматі таблиці:

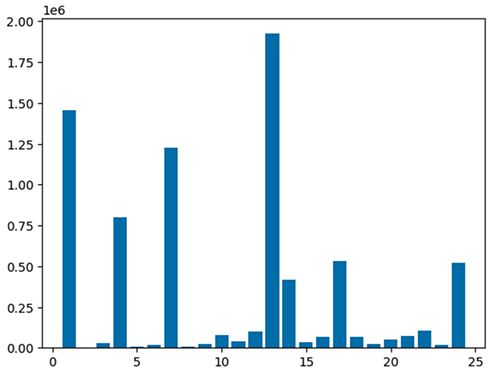
Ви також можете швидко візуалізувати свої дані за допомогою п’яти типів діаграм. Ви можете вибрати тип відображення, і діаграма відповідно зміниться. На наступному знімку екрана ми використовуємо гістограму для візуалізації наших даних.

Взаємодія з EMR Serverless за допомогою Spark SQL
Ви можете взаємодіяти з таблицями в Каталог даних AWS Glue за допомогою Spark SQL на EMR Serverless. У прикладі блокнота ми показуємо, як можна трансформувати дані за допомогою фрейму даних Spark.
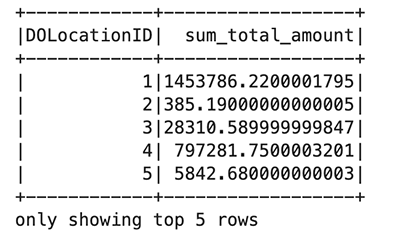
Спочатку створіть нове тимчасове подання під назвою таксі. Це дозволяє використовувати Spark SQL для вибору даних із цього перегляду. Потім створіть фрейм даних таксі для подальшої обробки:
У кожній клітинці блокнота EMR Studio ви можете розгорнути Spark Job Progress щоб переглянути різні етапи завдання, надісланого в EMR Serverless під час виконання цієї конкретної комірки. Ви можете побачити час, витрачений на виконання кожного етапу. У наступному прикладі етап 14 завдання містить 12 виконаних завдань. Крім того, якщо виникне будь-яка помилка, ви зможете переглянути журнали, що зробить усунення несправностей безпроблемним. Ми обговоримо це докладніше в наступному розділі.
![Job[14]: showString у NativeMethodAccessorImpl.java:0 і Job[15]: showString у NativeMethodAccessorImpl.java:0](https://xlera8.com/wp-content/uploads/2024/04/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio-amazon-web-services-11.png)
Використовуйте наведений нижче код, щоб візуалізувати оброблений кадр даних за допомогою пакета matplotlib. Ви використовуєте бібліотеку maptplotlib, щоб побудувати місце висадки та загальну суму у вигляді гістограми.
Діагностика інтерактивних програм
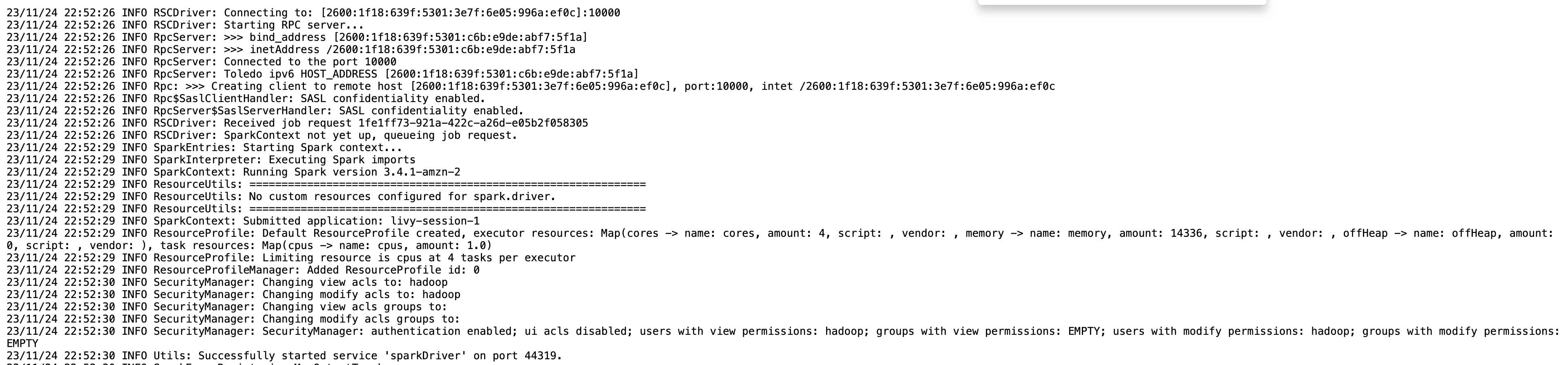
Ви можете отримати інформацію про сеанс для кінцевої точки Livy за допомогою %%info Sparkmagic. Це дає вам посилання для доступу до інтерфейсу користувача Spark, а також до журналу драйверів прямо у вашому блокноті.

Наступний знімок екрана — це фрагмент журналу драйверів для нашої програми, який ми відкрили за посиланням у нашому блокноті.
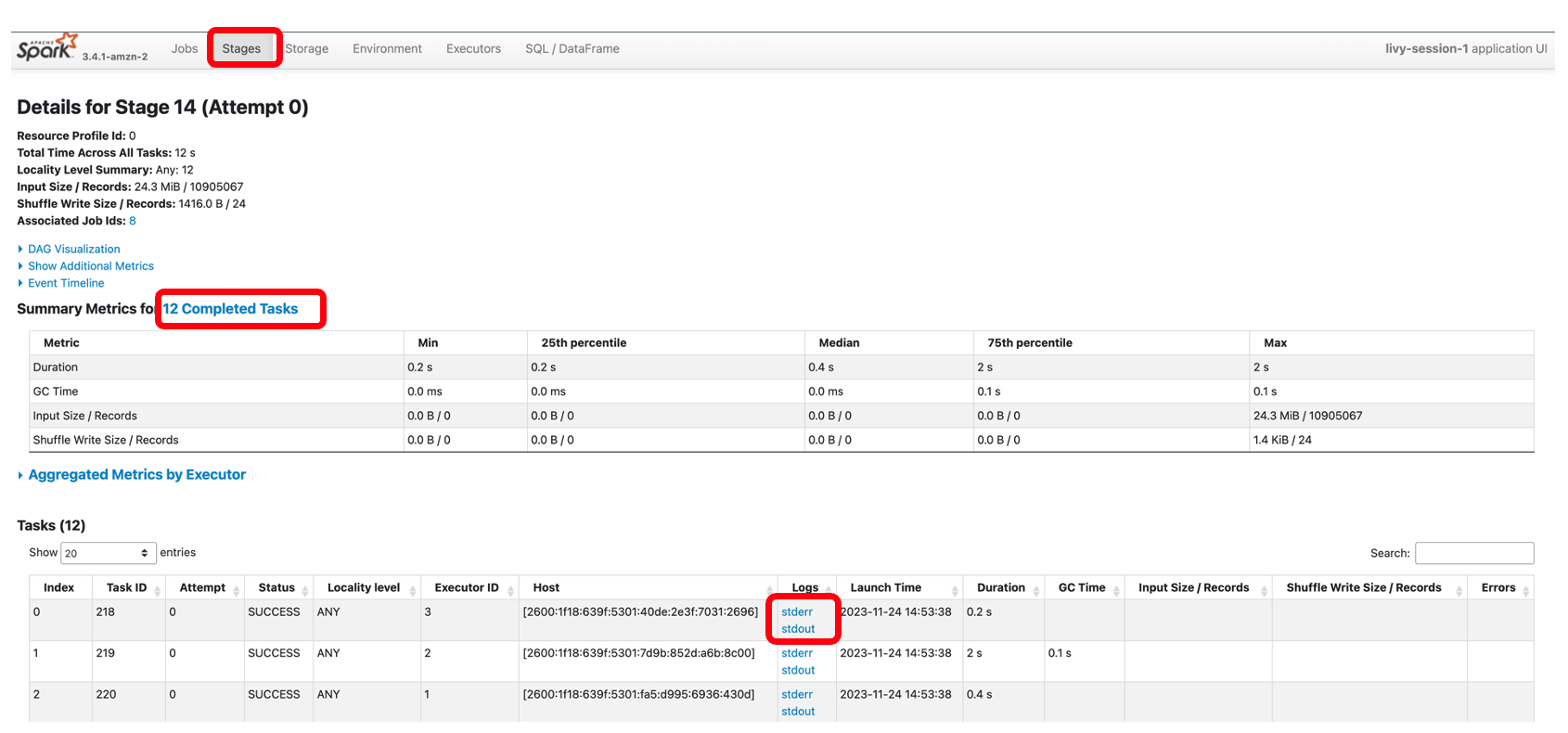
Так само ви можете вибрати посилання нижче Інтерфейс користувача Spark щоб відкрити інтерфейс користувача. На наступному знімку екрана показано Виконавці вкладка, яка надає доступ до журналів драйвера та виконавця.

На наступному знімку екрана показано етап 14, який відповідає етапу Spark SQL, який ми бачили раніше, під час якого ми обчислювали загальну суму зібраних таксі за місцеположенням, які були розбиті на 12 завдань. За допомогою інтерфейсу користувача Spark інтерактивна програма надає детальний статус на рівні завдання, деталі вводу-виводу та перемішування, а також посилання на відповідні журнали для кожного завдання на цьому етапі прямо з вашого блокнота, що забезпечує безпроблемне усунення несправностей.
Прибирати
Якщо ви більше не хочете зберігати ресурси, створені в цьому дописі, виконайте наведені нижче кроки очищення:
- Видаліть програму EMR Serverless.
- Видаліть EMR Studio та пов’язані робочі області та блокноти.
- Щоб видалити решту ресурсів, перейдіть до консолі CloudFormation, виберіть стек і виберіть видаляти.
Усі ресурси буде видалено, за винятком сегмента S3, політика видалення якого налаштована на збереження.
Висновок
У публікації показано, як запускати інтерактивні робочі навантаження PySpark в EMR Studio, використовуючи EMR Serverless як обчислення. Ви також можете створювати та контролювати програми Spark в інтерактивному робочому просторі JupyterLab.
У наступній публікації ми обговоримо додаткові можливості безсерверних інтерактивних програм EMR, як-от:
- Робота з такими ресурсами, як Amazon RDS і Amazon Redshift у вашому VPC (наприклад, для підключення JDBC/ODBC)
- Запуск транзакційних робочих навантажень за допомогою безсерверних кінцевих точок
Якщо ви вперше досліджуєте EMR Studio, рекомендуємо перевірити Семінари Amazon EMR і посилаючись на Створіть студію EMR.
Про авторів
 Секар Шрінівасан є головним спеціалістом з розробки рішень в AWS, який займається аналізом даних і ШІ. Секар має понад 20 років досвіду роботи з даними. Він захоплено допомагає клієнтам створювати масштабовані рішення, модернізуючи їхню архітектуру та генеруючи ідеї на основі їхніх даних. У вільний час він любить працювати над некомерційними проектами, спрямованими на освіту малозабезпечених дітей.
Секар Шрінівасан є головним спеціалістом з розробки рішень в AWS, який займається аналізом даних і ШІ. Секар має понад 20 років досвіду роботи з даними. Він захоплено допомагає клієнтам створювати масштабовані рішення, модернізуючи їхню архітектуру та генеруючи ідеї на основі їхніх даних. У вільний час він любить працювати над некомерційними проектами, спрямованими на освіту малозабезпечених дітей.
 Діша Умарвані є старшим архітектором даних Amazon Professional Services у Global Health Care and LifeSciences. Вона працювала з клієнтами над розробкою, архітектурою та впровадженням стратегії даних у великих масштабах. Вона спеціалізується на розробці архітектур Data Mesh для корпоративних платформ.
Діша Умарвані є старшим архітектором даних Amazon Professional Services у Global Health Care and LifeSciences. Вона працювала з клієнтами над розробкою, архітектурою та впровадженням стратегії даних у великих масштабах. Вона спеціалізується на розробці архітектур Data Mesh для корпоративних платформ.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/run-interactive-workloads-on-amazon-emr-serverless-from-amazon-emr-studio/