
Керовані робочі процеси Amazon для Apache Airflow (Amazon MWAA) — це керована служба оркестровки для Потік повітря Apache які ви можете використовувати для налаштування та керування конвеєрами даних у хмарі в масштабі. Apache Airflow — це інструмент із відкритим кодом, який використовується для програмного створення, планування та моніторингу послідовностей процесів і завдань, які називаються Робочі процеси. З Amazon MWAA ви можете використовувати Apache Airflow і Python для створення робочих процесів без необхідності керувати основною інфраструктурою для масштабованості, доступності та безпеки.
Використовуючи кілька облікових записів AWS, організації можуть ефективно масштабувати робоче навантаження та керувати своєю складністю в міру зростання. Цей підхід забезпечує надійний механізм для пом’якшення потенційного впливу збоїв або збоїв, гарантуючи, що критичні робочі навантаження залишаються в робочому стані. Крім того, це дає змогу оптимізувати витрати шляхом узгодження ресурсів із конкретними випадками використання, гарантуючи, що витрати добре контролюються. Ізолюючи робочі навантаження з певними вимогами безпеки або вимогами відповідності, організації можуть підтримувати найвищий рівень конфіденційності та безпеки даних. Крім того, можливість організувати декілька облікових записів AWS у структурований спосіб дозволяє узгодити ваші бізнес-процеси та ресурси відповідно до ваших унікальних операційних, нормативних і бюджетних вимог. Цей підхід сприяє ефективності, гнучкості та масштабованості, дозволяючи великим підприємствам задовольняти свої потреби та досягати своїх цілей.
Ця публікація демонструє, як організувати наскрізний конвеєр вилучення, перетворення та завантаження (ETL) за допомогою Служба простого зберігання Amazon (Amazon S3), Клей AWS та Amazon Redshift без сервера за допомогою Amazon MWAA.
Огляд рішення
У цій публікації ми розглядаємо варіант використання, коли команда розробки даних хоче побудувати процес ETL і надати найкращий досвід своїм кінцевим користувачам, коли вони хочуть запитувати найновіші дані після додавання нових необроблених файлів до Amazon S3 у центральному обліковий запис (обліковий запис A на наведеній нижче схемі архітектури). Команда розробки даних хоче відокремити необроблені дані у власний обліковий запис AWS (обліковий запис B на схемі) для підвищення безпеки та контролю. Вони також хочуть виконувати роботу з обробки та перетворення даних у своєму власному обліковому записі (Обліковий запис B), щоб розділити обов’язки та запобігти будь-яким ненавмисним змінам вихідних необроблених даних, наявних у центральному обліковому записі (Обліковий запис A). Цей підхід дозволяє команді обробляти необроблені дані, отримані з облікового запису A в обліковий запис B, який призначений для завдань обробки даних. Це забезпечує безпечне зберігання необроблених і оброблених даних між кількома обліковими записами, якщо це необхідно, для покращеного керування та безпеки даних.
Наше рішення використовує наскрізний конвеєр ETL, організований Amazon MWAA, який шукає нові додаткові файли в розташуванні Amazon S3 в обліковому записі A, де присутні необроблені дані. Це робиться шляхом виклику завдань AWS Glue ETL і запису в об’єкти даних у безсерверному кластері Redshift в обліковому записі B. Потім починає працювати конвеєр збережені процедури і команди SQL на Redshift Serverless. Після завершення виконання запитів an РОЗвантажити операція викликається зі сховища даних Redshift у відро S3 в обліковому записі A.
Оскільки безпека важлива, у цій публікації також описано, як налаштувати підключення Airflow за допомогою Менеджер секретів AWS щоб уникнути зберігання облікових даних бази даних у підключеннях і змінних Airflow.
Наступна діаграма ілюструє огляд архітектури компонентів, залучених до оркестровки робочого процесу.
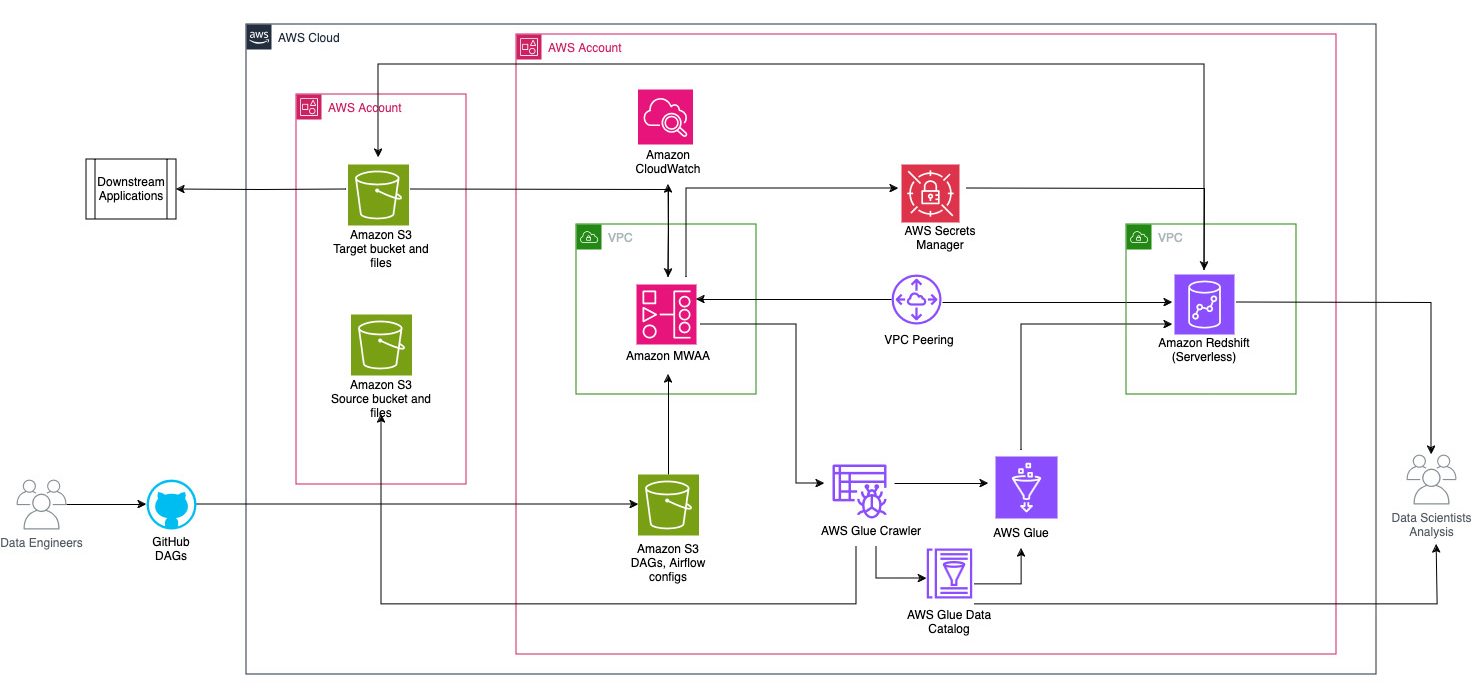
Робочий процес складається з наступних компонентів:
- Вихідний і цільовий сегменти S3 знаходяться в центральному обліковому записі (Обліковий запис A), тоді як Amazon MWAA, AWS Glue і Amazon Redshift знаходяться в іншому обліковому записі (Обліковий запис B). Між сегментами S3 в обліковому записі A з ресурсами в обліковому записі B налаштовано міжобліковий доступ, щоб мати можливість завантажувати та вивантажувати дані.
- У другому обліковому записі Amazon MWAA розміщено в одному VPC, а Redshift Serverless — в іншому VPC, які підключені через піринг VPC. Безсерверна робоча група Redshift захищена всередині приватних підмереж у трьох зонах доступності.
- Такі секрети, як ім’я користувача, пароль, порт БД і регіон AWS для Redshift Serverless, зберігаються в диспетчері секретів.
- Кінцеві точки VPC створено для Amazon S3 і Secrets Manager для взаємодії з іншими ресурсами.
- Зазвичай розробники даних створюють ациклічний графік, спрямований повітряним потоком (DAG) і передають свої зміни в GitHub. За допомогою дій GitHub вони розгортаються у відро S3 в обліковому записі B (для цієї публікації ми завантажуємо файли безпосередньо в сегмент S3). Відро S3 зберігає файли, пов’язані з Airflow, наприклад файли DAG,
requirements.txtфайли та плагіни. Сценарії та ресурси AWS Glue ETL зберігаються в іншому сегменті S3. Таке розділення допомагає зберегти організованість і уникнути плутанини. - Airflow DAG використовує різні оператори, датчики, підключення, завдання та правила для запуску конвеєра даних за потреби.
- Ви ввійшли в журнали Airflow Amazon CloudWatch, і сповіщення можна налаштувати для завдань моніторингу. Для отримання додаткової інформації див Панелі моніторингу та сигналізації на Amazon MWAA.
Передумови
Оскільки це рішення зосереджено на використанні Amazon MWAA для організації конвеєра ETL, вам потрібно заздалегідь налаштувати певні основні ресурси для облікових записів. Зокрема, вам потрібно створити сегменти та папки S3, ресурси AWS Glue і ресурси Redshift Serverless у відповідних облікових записах перед впровадженням повної інтеграції робочого процесу за допомогою Amazon MWAA.
Розгорніть ресурси в обліковому записі A за допомогою AWS CloudFormation
В обліковому записі A запустіть наданий AWS CloudFormation стек для створення таких ресурсів:
- Вихідні та цільові сегменти та папки S3. Як найкраща практика, структури вхідних і вихідних сегментів форматуються за допомогою розділення у стилі вулика
s3://<bucket>/products/YYYY/MM/DD/. - Зразок набору даних називається
products.csv, який ми використовуємо в цій публікації.
![]()
Завантажте завдання AWS Glue в Amazon S3 в обліковому записі B
В обліковому записі B створіть розташування Amazon S3 під назвою aws-glue-assets-<account-id>-<region>/scripts (якщо немає). Замініть параметри для ідентифікатора облікового запису та регіону в sample_glue_job.py сценарій і завантажте файл завдання AWS Glue у розташування Amazon S3.
Розгорніть ресурси в обліковому записі B за допомогою AWS CloudFormation
В обліковому записі B запустіть наданий шаблон стека CloudFormation, щоб створити такі ресурси:
- Відро S3
airflow-<username>-bucketдля зберігання пов’язаних із Airflow файлів із такою структурою:- даги – Папка для файлів DAG.
- plugins – Файл для будь-яких настроюваних або спільнотних плагінів Airflow.
- вимога - The
requirements.txtфайл для будь-яких пакетів Python. - scripts – Будь-які сценарії SQL, які використовуються в DAG.
- дані – Будь-які набори даних, що використовуються в DAG.
- Безсерверне середовище Redshift. Ім’я робочої групи та простір імен мають префікс
sample. - Середовище AWS Glue, яке містить:
- Клей AWS гусеничний, який сканує дані з вихідного сегмента S3
sample-inp-bucket-etl-<username>на рахунку А. - База даних називається
products_dbу каталозі даних AWS Glue. - ELT робота званий
sample_glue_job. Це завдання може читати файли зproductsу каталозі даних і завантажити дані в таблицю Redshiftproducts.
- Клей AWS гусеничний, який сканує дані з вихідного сегмента S3
- Кінцева точка шлюзу VPC для Amazon S3.
- Середовище Amazon MWAA. Докладні кроки щодо створення середовища Amazon MWAA за допомогою консолі Amazon MWAA див Представляємо керовані робочі процеси Amazon для Apache Airflow (MWAA).
![]()
Створіть ресурси Amazon Redshift
Створіть дві таблиці та збережену процедуру в робочій групі Redshift Serverless за допомогою products.sql файлу.
У цьому прикладі ми створюємо дві таблиці під назвою products та products_f. Ім'я збереженої процедури sp_products.
Налаштуйте дозволи Airflow
Після успішного створення середовища Amazon MWAA статус відображатиметься як наявний, Вибирати Відкрийте інтерфейс Airflow щоб переглянути інтерфейс Airflow. DAG автоматично синхронізуються з сегмента S3 і відображаються в інтерфейсі користувача. Однак на цьому етапі в папці S3 немає DAG.
Додайте керовану клієнтом політику AmazonMWAAFullConsoleAccess, який надає користувачам Airflow дозвіл на доступ Управління ідентифікацією та доступом AWS (IAM) і приєднайте цю політику до ролі Amazon MWAA. Для отримання додаткової інформації див Доступ до середовища Amazon MWAA.
Політики, пов’язані з роллю Amazon MWAA, мають повний доступ і повинні використовуватися лише для тестування в безпечному тестовому середовищі. Для виробничих розгортань дотримуйтеся принципу найменших привілеїв.
Налаштуйте середовище
У цьому розділі описано кроки для налаштування середовища. Процес включає наступні етапи високого рівня:
- Оновіть усіх необхідних постачальників.
- Налаштуйте міжобліковий доступ.
- Встановіть однорангове з’єднання VPC між Amazon MWAA VPC і Amazon Redshift VPC.
- Налаштуйте Secrets Manager для інтеграції з Amazon MWAA.
- Визначте підключення Airflow.
Оновіть провайдерів
Виконайте кроки в цьому розділі, якщо ваша версія Amazon MWAA менше 2.8.1 (остання версія на момент написання цієї публікації).
Провайдери це пакети, які підтримуються спільнотою та включають усі основні оператори, гачки та датчики для певної послуги. Постачальник Amazon використовується для взаємодії з такими службами AWS, як Amazon S3, Amazon Redshift Serverless, AWS Glue тощо. У постачальника Amazon є понад 200 модулів.
Незважаючи на те, що в Amazon MWAA підтримується версія Airflow 2.6.3, яка постачається разом із наданим Amazon пакетом версії 8.2.0, підтримка Amazon Redshift Serverless не була додана до версії пакета Amazon 8.4.0. Оскільки стандартна версія пакетного постачальника є старішою, ніж тоді, коли була представлена підтримка Redshift Serverless, версію постачальника потрібно оновити, щоб використовувати цю функцію.
Першим кроком є оновлення файлу обмежень і requirements.txt файл із правильними версіями. Відноситься до Зазначення нових пакетів провайдера кроки для оновлення пакета постачальника Amazon.
- Укажіть вимоги наступним чином:
- Оновіть версію у файлі обмежень до 8.4.0 або новішої.
- Додати constraints-3.11-updated.txt файл до
/dagsпапку.
Відноситься до Версії Apache Airflow на Amazon Managed Workflows для Apache Airflow для правильних версій файлу обмежень залежно від версії Airflow.
- Перейдіть до середовища Amazon MWAA та виберіть Редагувати.
- під Код DAG в Amazon S3, Для Файл вимог, виберіть останню версію.
- Вибирати зберегти.
Це оновить середовище, і нові постачальники стануть дійсними.
- Щоб перевірити версію постачальника, перейдіть до Провайдери під Адміністратор таблиці.
Версія пакета постачальника Amazon має бути 8.4.0, як показано на наступному знімку екрана. Якщо ні, під час завантаження сталася помилка requirements.txt. Щоб усунути будь-які помилки, перейдіть до консолі CloudWatch і відкрийте requirements_install_ip увійдіть Потоки журналів, де перераховані помилки. Відноситься до Увімкнення журналів на консолі Amazon MWAA для більш докладної інформації.

Налаштуйте міжобліковий доступ
Щоб отримати доступ до сегментів S3 для завантаження та вивантаження даних, потрібно налаштувати міжоблікові політики та ролі між обліковими записами A та B. Виконайте наступні дії:
- В обліковому записі A налаштуйте політику сегмента для сегмента
sample-inp-bucket-etl-<username>щоб надати дозволи ролям AWS Glue і Amazon MWAA в обліковому записі B для об’єктів у сегментіsample-inp-bucket-etl-<username>: - Подібним чином налаштуйте політику відра для відра
sample-opt-bucket-etl-<username>щоб надати дозволи ролям Amazon MWAA в обліковому записі B для розміщення об’єктів у цьому відрі: - В обліковому записі A створіть політику IAM під назвою
policy_for_roleA, який дозволяє виконувати необхідні дії Amazon S3 над вихідним сегментом: - Створіть нову роль IAM під назвою
RoleAз обліковим записом B як роллю довіреної особи та додайте цю політику до ролі. Це дозволяє обліковому запису B взяти на себе роль A для виконання необхідних дій Amazon S3 у вихідному сегменті. - В обліковому записі B створіть політику IAM під назвою
s3-cross-account-accessз дозволом на доступ до об’єктів у відріsample-inp-bucket-etl-<username>, який знаходиться на рахунку А. - Додайте цю політику до ролі AWS Glue і Amazon MWAA:
- В обліковому записі B створіть політику IAM
policy_for_roleBвизначення облікового запису А як довіреної особи. Нижче наведено політику довіриRoleAв обліковому записі А: - Створіть нову роль IAM під назвою
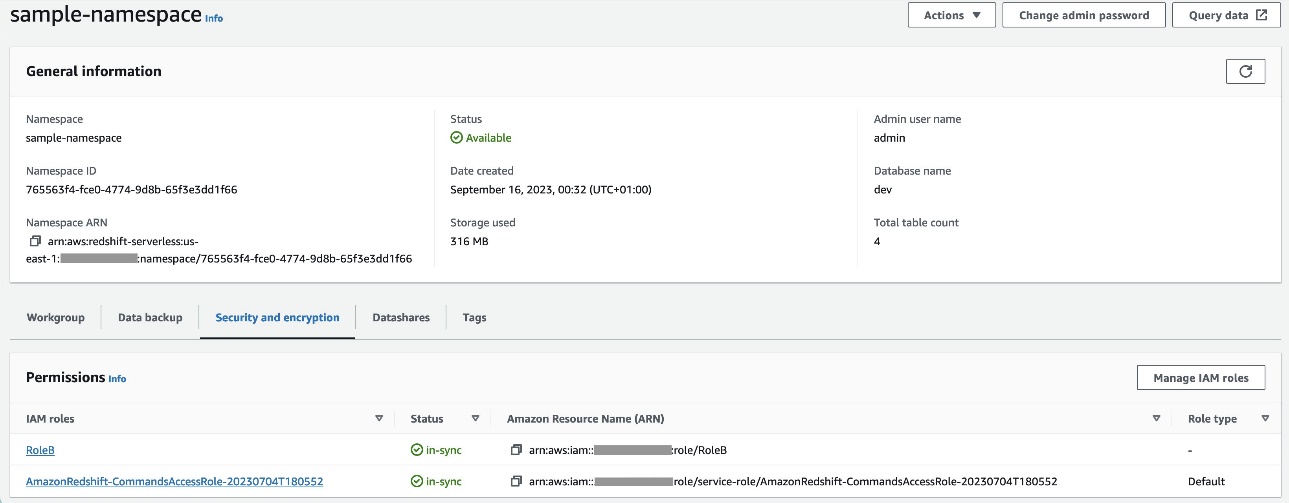
RoleBз Amazon Redshift як довіреним типом об’єкта та додайте цю політику до ролі. Це дозволяєRoleBприпуститиRoleAв обліковому записі A, а також бути прийнятим Amazon Redshift. - Приєднувати
RoleBу простір імен Redshift Serverless, тому Amazon Redshift може записувати об’єкти до вихідного сегмента S3 в обліковому записі A. - Прикріпіть поліс
policy_for_roleBдо ролі Amazon MWAA, що дає Amazon MWAA доступ до вихідного сегмента в обліковому записі A.
Відноситься до Як надати міжобліковий доступ до об’єктів, які знаходяться в сегментах Amazon S3? щоб дізнатися більше про налаштування доступу між обліковими записами до об’єктів в Amazon S3 від AWS Glue і Amazon MWAA. Відноситься до Як КОПІЮВАТИ або ВИВАНТАЖИТИ дані з Amazon Redshift у сегмент Amazon S3 в іншому обліковому записі? щоб дізнатися більше про налаштування ролей для вивантаження даних з Amazon Redshift на Amazon S3 з Amazon MWAA.
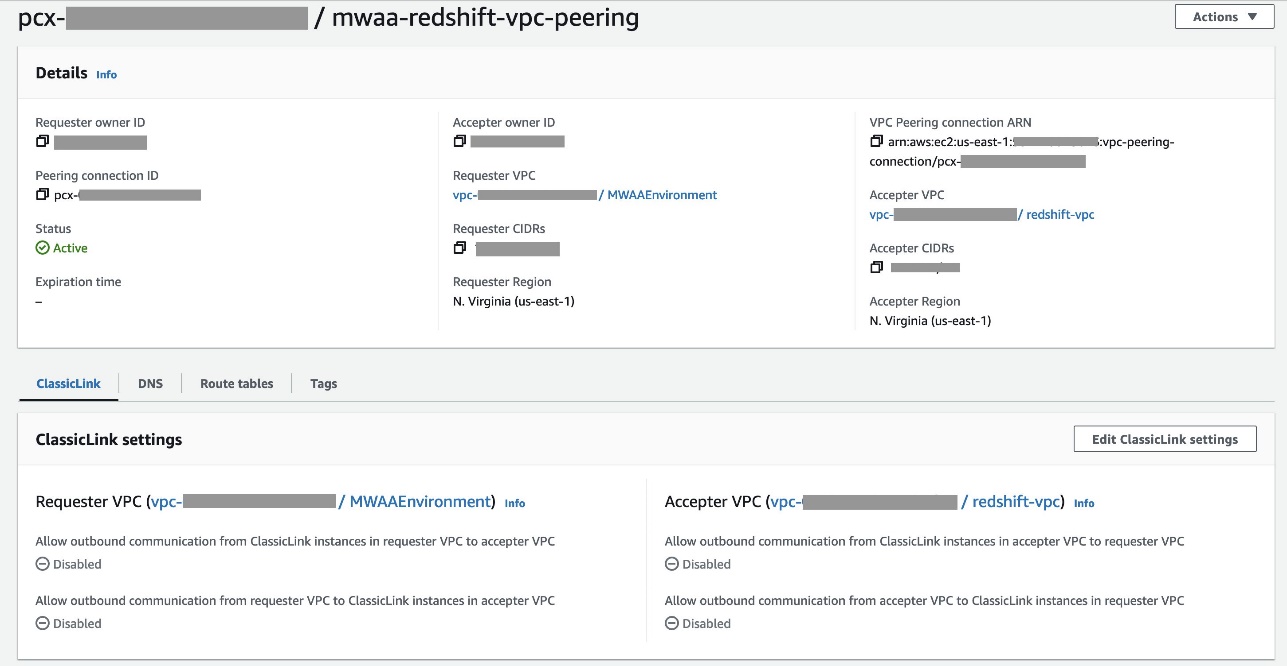
Налаштуйте піринг VPC між Amazon MWAA та Amazon Redshift VPC
Оскільки Amazon MWAA та Amazon Redshift знаходяться у двох окремих VPC, вам потрібно налаштувати між ними піринг VPC. Необхідно додати маршрут до таблиць маршрутів, пов’язаних із підмережами для обох служб. Відноситься до Робота з піринговими з'єднаннями VPC щоб дізнатися більше про піринг VPC.
Переконайтеся, що діапазон CIDR Amazon MWAA VPC дозволено в групі безпеки Redshift, а діапазон CIDR Amazon Redshift VPC дозволено в групі безпеки Amazon MWAA, як показано на наступному знімку екрана.
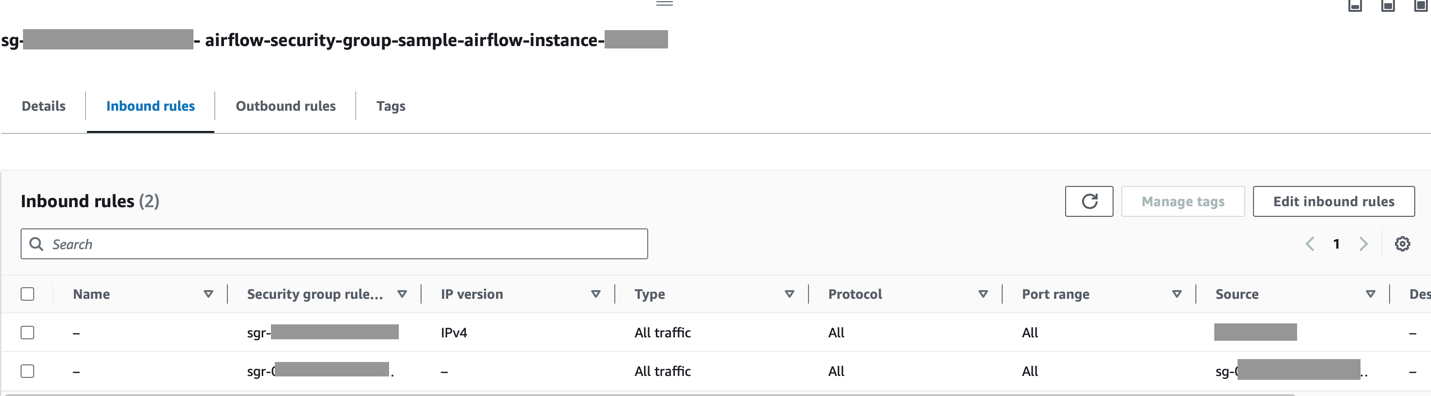
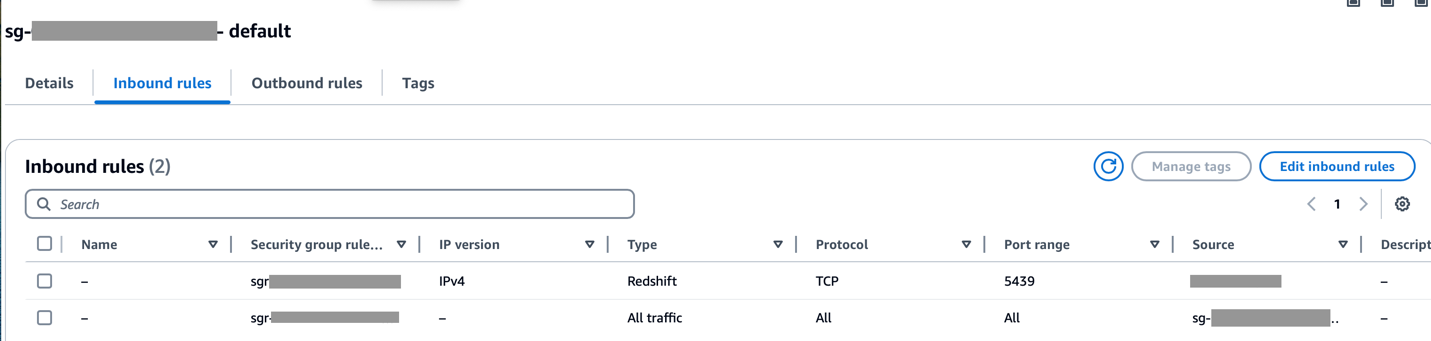
Якщо будь-який із попередніх кроків налаштовано неправильно, ви, ймовірно, зіткнетеся з помилкою «Час очікування з’єднання» під час запуску DAG.
Налаштуйте підключення Amazon MWAA за допомогою Secrets Manager
Коли конвеєр Amazon MWAA налаштовано на використання диспетчера секретів, він спочатку шукатиме з’єднання та змінні в альтернативній серверній частині (наприклад, диспетчер секретів). Якщо альтернативний сервер містить потрібне значення, воно повертається. В іншому випадку він перевірить базу даних метаданих на наявність значення та поверне його замість цього. Для отримання додаткової інформації зверніться до Налаштування підключення Apache Airflow за допомогою секрету AWS Secrets Manager.
Виконайте такі дії:
- Налаштування a Кінцева точка VPC щоб зв’язати Amazon MWAA та Secrets Manager (
com.amazonaws.us-east-1.secretsmanager).
Це дозволяє Amazon MWAA отримувати доступ до облікових даних, які зберігаються в диспетчері секретів.
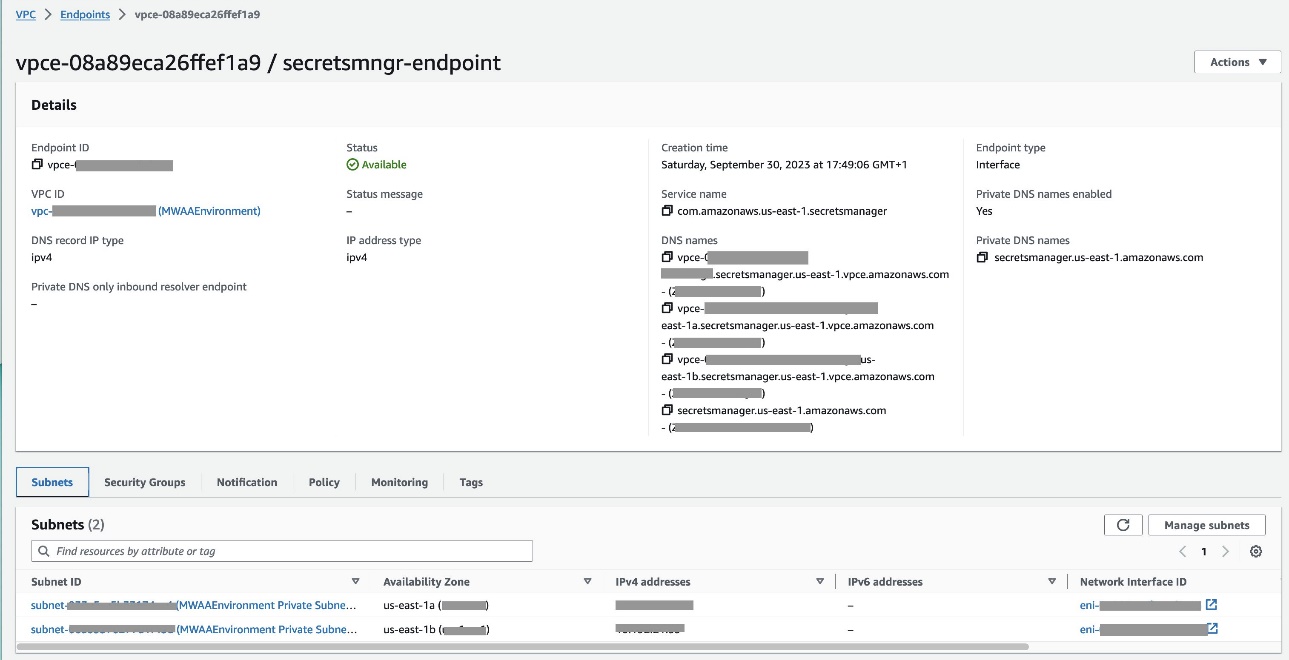
- Щоб надати Amazon MWAA дозвіл на доступ до секретних ключів Secrets Manager, додайте політику під назвою
SecretsManagerReadWriteдо IAM ролі середовища. - Щоб створити серверну частину Secrets Manager як параметр конфігурації Apache Airflow, перейдіть до параметрів конфігурації Airflow, додайте наступні пари ключ-значення та збережіть налаштування.
Це налаштовує Airflow на пошук рядків підключення та змінних у airflow/connections/* та airflow/variables/* шляхи:

- Щоб створити рядок URI підключення Airflow, перейдіть до AWS CloudShell і введіть в оболонку Python.
- Запустіть наступний код, щоб створити рядок URI підключення:
Рядок підключення має бути згенерований таким чином:
- Додайте підключення до диспетчера секретів за допомогою такої команди в Інтерфейс командного рядка AWS (AWS CLI).
Це також можна зробити з консолі диспетчера секретів. Це буде додано в диспетчер секретів як відкритий текст.
Використовуйте зв'язок airflow/connections/secrets_redshift_connection в DAG. Коли DAG запущено, він шукатиме це з’єднання та отримуватиме секрети з диспетчера секретів. В випадку RedshiftDataOperator, передайте secret_arn як параметр замість назви підключення.
Ви також можете додавати секрети за допомогою консолі диспетчера секретів як пари ключ-значення.
- Додайте інший секрет у Менеджер секретів і збережіть його як
airflow/connections/redshift_conn_test.

Створіть підключення Airflow через базу метаданих
Ви також можете створювати підключення в інтерфейсі користувача. У цьому випадку деталі підключення зберігатимуться в базі метаданих Airflow. Якщо середовище Amazon MWAA не налаштовано на використання серверної частини диспетчера секретів, воно перевірить базу даних метаданих на наявність значення та поверне його. Ви можете створити підключення Airflow за допомогою інтерфейсу користувача, AWS CLI або API. У цьому розділі ми покажемо, як створити з’єднання за допомогою інтерфейсу користувача Airflow.
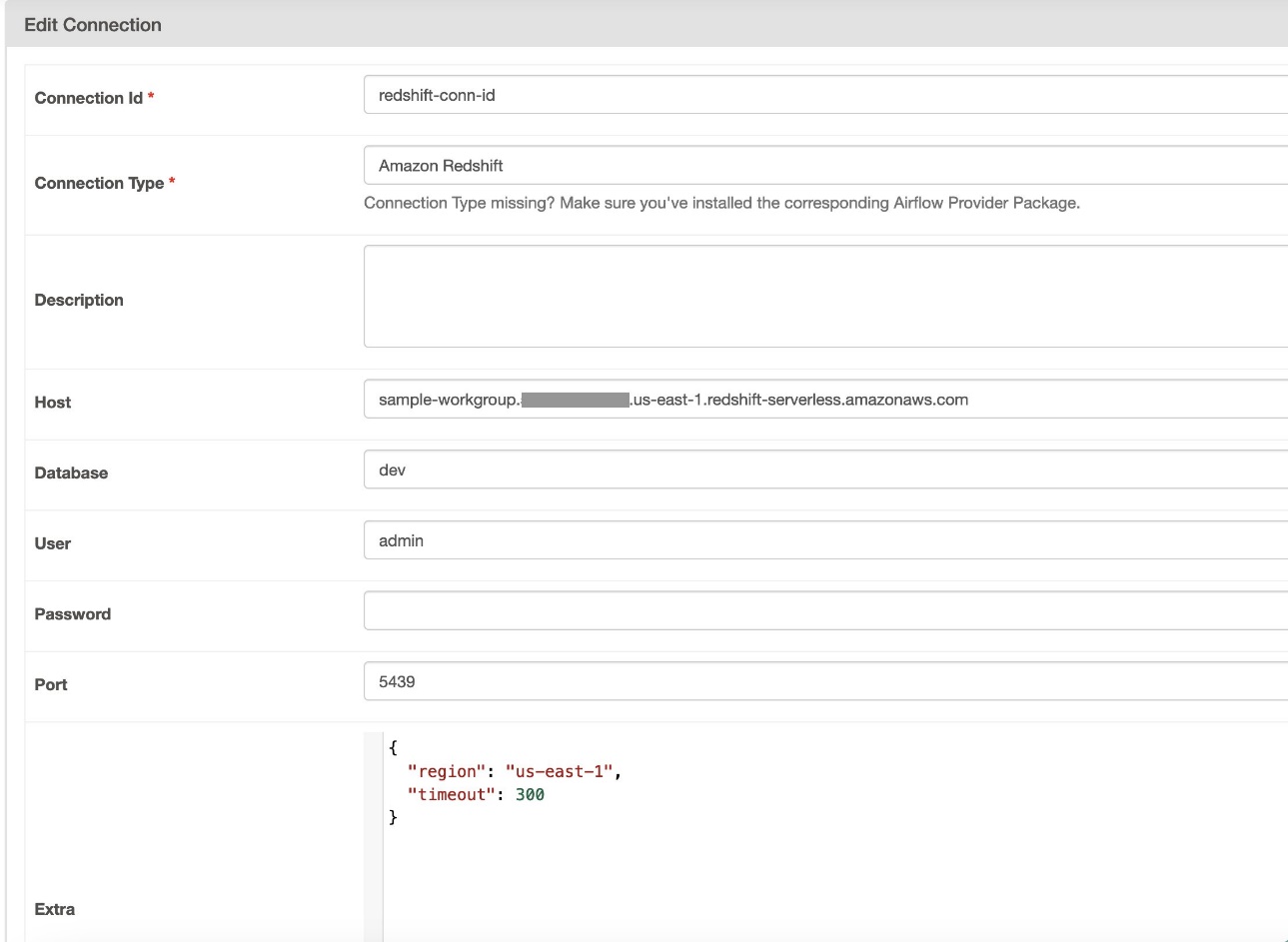
- для Ідентифікатор підключення, введіть назву з’єднання.
- для Тип з'єднаннявиберіть Амазонська червона зміна.
- для Господар, введіть кінцеву точку Redshift (без порту та бази даних) для Redshift Serverless.
- для Database, введіть
dev. - для користувач, введіть ім’я користувача адміністратора.
- для Пароль, введіть ваш пароль.
- для порт, використовуйте порт 5439.
- для Extra, встановіть
regionтаtimeoutпараметри - Перевірте з’єднання, а потім збережіть налаштування.
Створіть і запустіть DAG
У цьому розділі ми описуємо, як створити DAG за допомогою різних компонентів. Після того, як ви створите та запустите DAG, ви можете перевірити результати, зробивши запит до таблиць Redshift і перевіривши цільові сегменти S3.
Створіть DAG
У Airflow конвеєри даних визначені в коді Python як DAG. Ми створюємо DAG, який складається з різних операторів, датчиків, підключень, завдань і правил:
- DAG починається з пошуку вихідних файлів у відрі S3
sample-inp-bucket-etl-<username>за рахунком А за поточний день використаннямS3KeySensor. S3KeySensor використовується для очікування наявності одного чи кількох ключів у сегменті S3.- Наприклад, наше відро S3 розділено як
s3://bucket/products/YYYY/MM/DD/, тож наш датчик має перевіряти папки з поточною датою. Ми отримали поточну дату в DAG і передали їїS3KeySensor, який шукає будь-які нові файли в папці поточного дня. - Ми теж поставили
wildcard_matchasTrue, що дозволяє здійснювати пошук наbucket_keyінтерпретувати як шаблон підстановки Unix. Встановітьmodeдоrescheduleтак що завдання датчика звільняє робоче місце, коли критерії не задовольняються, і його переплановують на пізніший час. Як найкраща практика, використовуйте цей режим, колиpoke_intervalстановить більше 1 хвилини, щоб запобігти надмірному навантаженню планувальника.
- Наприклад, наше відро S3 розділено як
- Коли файл стає доступним у сегменті S3, сканер AWS Glue запускається за допомогою
GlueCrawlerOperatorщоб сканувати вихідне відро S3sample-inp-bucket-etl-<username>під обліковим записом A та оновлює метадані таблиці підproducts_dbбази даних у каталозі даних. Веб-сканер використовує роль AWS Glue і базу даних Data Catalog, які були створені на попередніх кроках. - DAG використовує
GlueCrawlerSensorдочекатися завершення сканера. - Коли роботу сканера завершено,
GlueJobOperatorвикористовується для запуску завдання AWS Glue. Назва сценарію AWS Glue (разом із розташуванням) передається оператору разом із роллю AWS Glue IAM. Інші параметри, якGlueVersion,NumberofWorkersтаWorkerTypeпередаються за допомогоюcreate_job_kwargsпараметр. - DAG використовує
GlueJobSensorдочекатися завершення роботи AWS Glue. Після завершення з’явиться проміжна таблиця Redshiftproductsбуде завантажено дані з файлу S3. - Ви можете підключитися до Amazon Redshift із Airflow за допомогою трьох різних Оператори:
PythonOperator.SQLExecuteQueryOperator, який використовує з’єднання PostgreSQL іredshift_defaultяк підключення за замовчуванням.RedshiftDataOperator, який використовує Redshift Data API таaws_defaultяк підключення за замовчуванням.
У нашому DAG ми використовуємо SQLExecuteQueryOperator та RedshiftDataOperator щоб показати, як використовувати ці оператори. Виконуються збережені процедури Redshift RedshiftDataOperator. DAG також виконує команди SQL в Amazon Redshift, щоб видалити дані з проміжної таблиці за допомогою SQLExecuteQueryOperator.
Оскільки ми налаштували наше середовище Amazon MWAA на пошук з’єднань у диспетчері секретів, під час роботи DAG він отримує з диспетчера секретів деталі підключення Redshift, як-от ім’я користувача, пароль, хост, порт і регіон. Якщо підключення не знайдено в диспетчері секретів, значення витягуються зі з’єднань за замовчуванням.
In SQLExecuteQueryOperator, ми передаємо ім’я підключення, яке ми створили в диспетчері секретів. Воно шукає airflow/connections/secrets_redshift_connection і отримує секрети з диспетчера секретів. Якщо диспетчер секретів не налаштовано, підключення, створене вручну (наприклад, redshift-conn-id) можна пройти.
In RedshiftDataOperator, ми передаємо secret_arn of the airflow/connections/redshift_conn_test підключення, створене в Secrets Manager як параметр.
- Як останнє завдання,
RedshiftToS3Operatorвикористовується для вивантаження даних із таблиці Redshift у сегмент S3sample-opt-bucket-etlна рахунку Б.airflow/connections/redshift_conn_testз диспетчера секретів використовується для вивантаження даних. TriggerRuleвстановлений вALL_DONE, що дозволяє виконувати наступний крок після завершення всіх попередніх завдань.- Залежність завдань визначається за допомогою
chain()функція, яка дозволяє паралельно виконувати завдання, якщо це необхідно. У нашому випадку ми хочемо, щоб усі завдання запускалися послідовно.
Нижче наведено повний код DAG. The dag_id має відповідати назві сценарію DAG, інакше його не буде синхронізовано з інтерфейсом користувача Airflow.
Перевірте запуск DAG
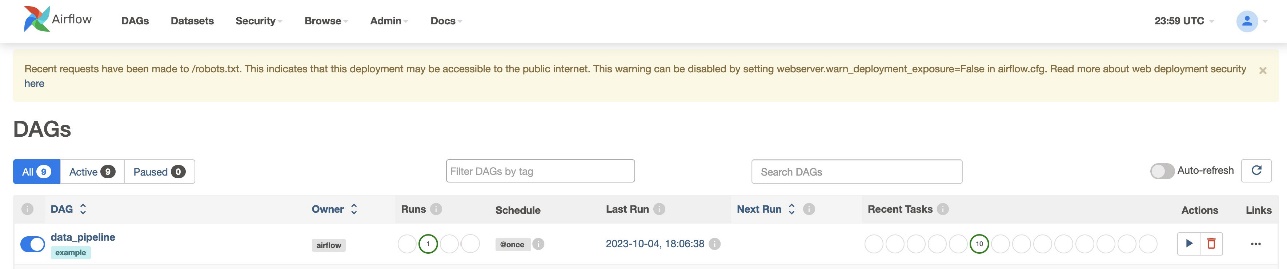
Після того, як ви створите файл DAG (замініть змінні в сценарії DAG) і завантажите його в s3://sample-airflow-instance/dags папку, вона буде автоматично синхронізована з інтерфейсом користувача Airflow. Усі DAG відображаються на DAG вкладка. Перемкнути ON можливість зробити DAG працездатним. Оскільки наш DAG налаштований на schedule="@once", вам потрібно вручну запустити завдання, вибравши піктограму запуску під Дії. Після завершення DAG статус оновлюється зеленим кольором, як показано на наступному знімку екрана.
У зв'язку у розділі є варіанти перегляду коду, графіка, сітки, журналу тощо. Виберіть Графік щоб візуалізувати DAG у форматі графіка. Як показано на наступному знімку екрана, кожен колір вузла позначає певний оператор, а колір контуру вузла позначає певний статус.

Перевірте результати
На консолі Amazon Redshift перейдіть до Редактор запитів версії 2 і виберіть дані в products_f стіл. Таблиця має бути завантажена та мати таку саму кількість записів, як файли S3.

На консолі Amazon S3 перейдіть до сегмента S3 s3://sample-opt-bucket-etl на рахунку Б. В product_f файли повинні бути створені в структурі папок s3://sample-opt-bucket-etl/products/YYYY/MM/DD/.

Прибирати
Очистіть ресурси, створені в рамках цієї публікації, щоб уникнути поточних платежів:
- Видаліть стеки CloudFormation і сегмент S3, які ви створили як передумови.
- Видаліть VPC і пірингові з’єднання VPC, політики та ролі між обліковими записами, а також секрети в диспетчері секретів.
Висновок
За допомогою Amazon MWAA ви можете створювати складні робочі процеси за допомогою Airflow і Python без керування кластерами, вузлами чи будь-якими іншими операційними витратами, які зазвичай пов’язані з розгортанням і масштабуванням Airflow у виробництві. У цій публікації ми показали, як Amazon MWAA забезпечує автоматичний спосіб отримання, трансформації, аналізу та розподілу даних між різними обліковими записами та службами в AWS. Більше прикладів інших операторів AWS див GitHub сховище; ми радимо вам дізнатися більше, спробувавши деякі з цих прикладів.
Про авторів

Радхіка Джаккула є архітектором рішень для прототипування великих даних в AWS. Вона допомагає клієнтам створювати прототипи за допомогою аналітичних служб AWS і спеціально створених баз даних. Вона є спеціалістом з оцінки широкого спектру вимог і застосування відповідних сервісів AWS, інструментів для великих даних і фреймворків для створення надійної архітектури.
 Сідхант Муралідхар є головним технічним менеджером з роботи з клієнтами в AWS. Він працює з великими корпоративними клієнтами, які працюють на AWS. Він захоплюється роботою з клієнтами та допомагає їм розробляти робочі навантаження для забезпечення витрат, надійності, продуктивності та операційної досконалості в масштабі їхньої хмарної подорожі. Він також має великий інтерес до аналізу даних.
Сідхант Муралідхар є головним технічним менеджером з роботи з клієнтами в AWS. Він працює з великими корпоративними клієнтами, які працюють на AWS. Він захоплюється роботою з клієнтами та допомагає їм розробляти робочі навантаження для забезпечення витрат, надійності, продуктивності та операційної досконалості в масштабі їхньої хмарної подорожі. Він також має великий інтерес до аналізу даних.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/big-data/orchestrate-an-end-to-end-etl-pipeline-using-amazon-s3-aws-glue-and-amazon-redshift-serverless-with-amazon-mwaa/