
Вступ
Машинне навчання (ML) — це галузь дослідження, яка зосереджена на розробці алгоритмів для автоматичного навчання з даних, створення прогнозів і виведення шаблонів без чітких вказівок, як це зробити. Він спрямований на створення систем, які автоматично вдосконалюються завдяки досвіду та даним.
Цього можна досягти за допомогою контрольованого навчання, коли модель навчається з використанням позначених даних для прогнозування, або за допомогою неконтрольованого навчання, коли модель намагається виявити закономірності чи кореляції в даних без конкретних цільових результатів, які слід передбачити.
ML став незамінним і широко використовуваним інструментом у різних дисциплінах, включаючи інформатику, біологію, фінанси та маркетинг. Він довів свою корисність у різноманітних програмах, таких як класифікація зображень, обробка природної мови та виявлення шахрайства.
Завдання машинного навчання
Машинне навчання можна умовно розділити на три основні завдання:
- Контрольоване навчання
- Непідконтрольне навчання
- Підсилення навчання
Тут ми зосередимося на перших двох випадках.
Навчання під наглядом
Контрольоване навчання передбачає навчання моделі на позначених даних, де вхідні дані поєднуються з відповідною вихідною або цільовою змінною. Мета полягає в тому, щоб вивчити функцію, яка може зіставляти вхідні дані з правильним виходом. Поширені алгоритми навчання під наглядом включають лінійну регресію, логістичну регресію, дерева рішень і опорні векторні машини.
Приклад коду навчання під наглядом за допомогою Python:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
У цьому простому прикладі коду ми навчаємо LinearRegression алгоритм від scikit-learn на наших навчальних даних, а потім застосувати його, щоб отримати прогнози для наших тестових даних.
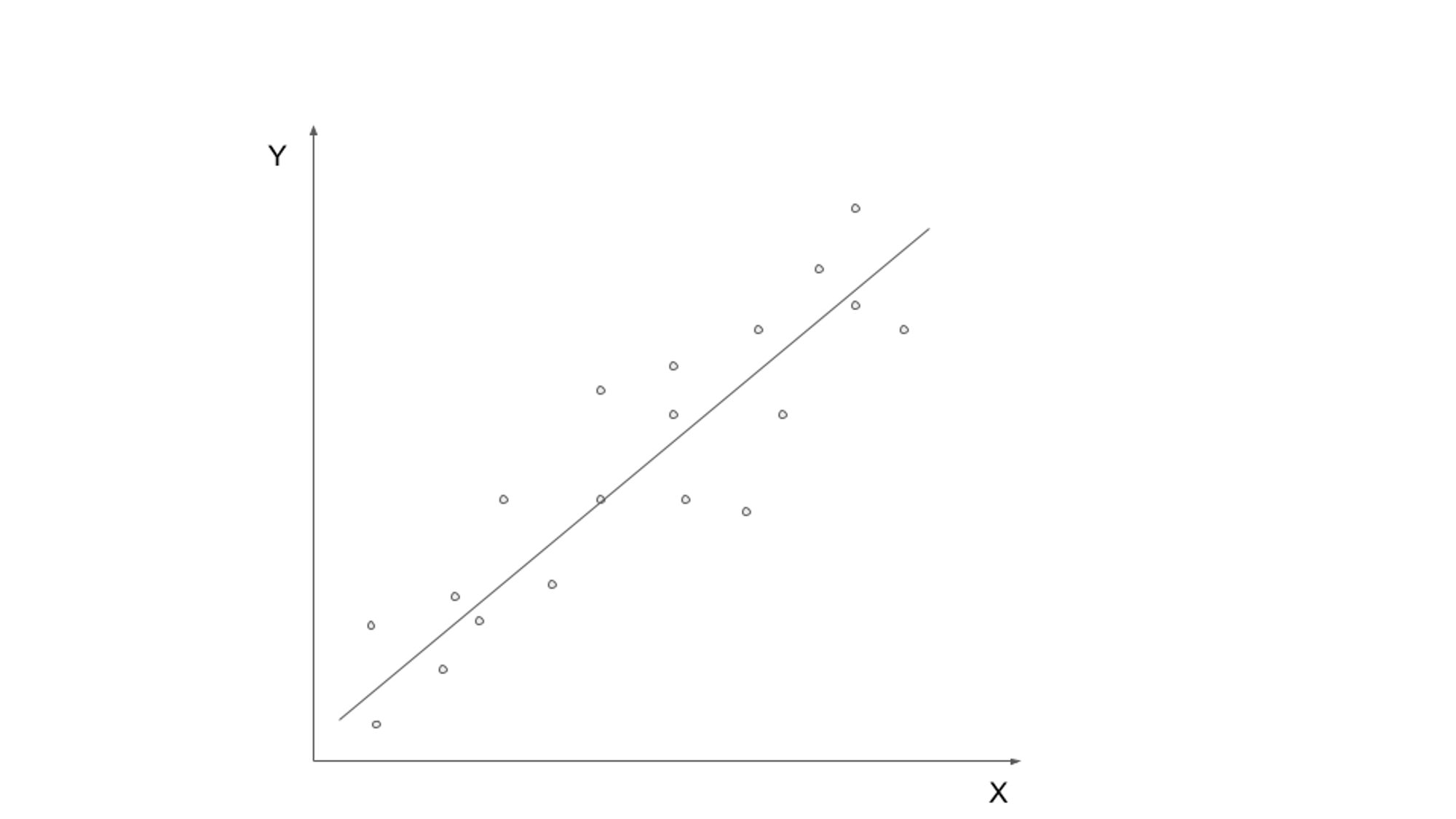
Одним із реальних прикладів використання навчання під наглядом є класифікація електронного спаму. З експоненційним зростанням електронної пошти ідентифікація та фільтрація спаму стала надзвичайно важливою. Використовуючи керовані алгоритми навчання, можна навчити модель розрізняти легітимні електронні листи та спам на основі позначених даних.
Модель навчання під наглядом можна навчити на наборі даних, що містить електронні листи, позначені як «спам» або «не спам». Модель вивчає закономірності та функції з даних із мітками, таких як наявність певних ключових слів, структура електронної пошти або інформація про відправника електронної пошти. Коли модель буде навчена, її можна буде використовувати для автоматичної класифікації вхідних електронних листів як спам чи не як спам, ефективно фільтруючи небажані повідомлення.
Навчання без нагляду
У неконтрольованому навчанні вхідні дані не позначені, а метою є виявлення шаблонів або структур у даних. Алгоритми неконтрольованого навчання спрямовані на пошук значущих представлень або кластерів у даних.
Приклади алгоритмів неконтрольованого навчання включають: k-означає кластеризацію, ієрархічна кластеризація та аналіз головних компонентів (PCA).
Приклад коду неконтрольованого навчання:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
У цьому простому прикладі коду ми навчаємо KMeans алгоритм від scikit-learn для ідентифікації трьох кластерів у наших даних і подальшого розміщення нових даних у цих кластерах.
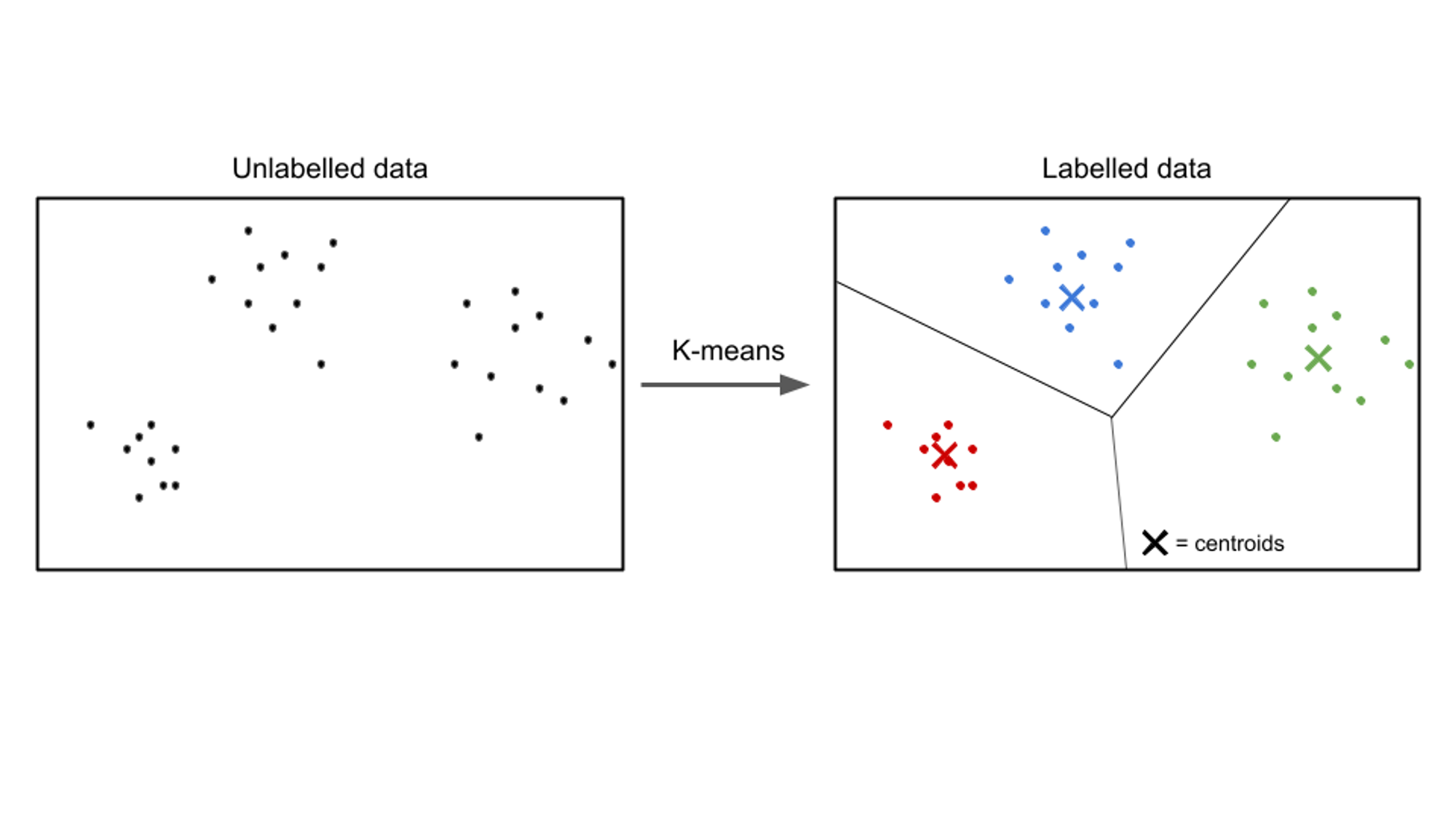
Прикладом неконтрольованого навчання є сегментація клієнтів. У різних галузях підприємства прагнуть краще зрозуміти свою клієнтську базу, щоб адаптувати свої маркетингові стратегії, персоналізувати свої пропозиції та оптимізувати взаємодію з клієнтами. Алгоритми неконтрольованого навчання можна використовувати, щоб розділити клієнтів на окремі групи на основі їхніх спільних характеристик і поведінки.
Ознайомтеся з нашим практичним практичним посібником із вивчення Git з передовими методами, прийнятими в галузі стандартами та включеною шпаргалкою. Припиніть гуглити команди Git і фактично вчитися це!
Застосовуючи методи неконтрольованого навчання, такі як кластеризація, компанії можуть виявити значущі закономірності та групи в даних своїх клієнтів. Наприклад, алгоритми кластеризації можуть ідентифікувати групи клієнтів зі схожими купівельними звичками, демографічними характеристиками чи вподобаннями. Цю інформацію можна використати для створення цільових маркетингових кампаній, оптимізації рекомендацій щодо продукту та підвищення рівня задоволеності клієнтів.
Основні класи алгоритмів
Контрольовані алгоритми навчання
-
Лінійні моделі: використовуються для прогнозування неперервних змінних на основі лінійних зв’язків між функціями та цільовою змінною.
-
Деревоподібні моделі: побудовані з використанням серії бінарних рішень для прогнозування або класифікації.
-
Ансамблеві моделі: метод, який поєднує кілька моделей (деревоподібних або лінійних) для більш точних прогнозів.
-
Моделі нейронних мереж: методи, які частково базуються на людському мозку, де кілька функцій працюють як вузли мережі.
Алгоритми неконтрольованого навчання
-
Ієрархічна кластеризація: будує ієрархію кластерів шляхом їх повторного злиття або розбиття.
-
Неієрархічна кластеризація: Розділяє дані на окремі кластери на основі подібності.
-
Зменшення розмірності: зменшує розмірність даних, зберігаючи найважливішу інформацію.
Оцінка моделі
Навчання під наглядом
Для оцінки ефективності моделей навчання під наглядом використовуються різні показники, зокрема точність, точність, запам’ятовування, оцінка F1 і ROC-AUC. Методи перехресної перевірки, такі як k-кратна перехресна перевірка, можуть допомогти оцінити ефективність узагальнення моделі.
Навчання без нагляду
Оцінка алгоритмів неконтрольованого навчання часто є складнішою, оскільки немає основної правди. Для оцінки якості результатів кластеризації можна використовувати такі показники, як оцінка силуету або інерція. Методи візуалізації також можуть надати уявлення про структуру кластерів.
Поради та хитрості
Навчання під наглядом
- Попередня обробка та нормалізація вхідних даних для покращення продуктивності моделі.
- Відповідним чином обробіть відсутні значення шляхом врахування чи видалення.
- Розробка функцій може покращити здатність моделі фіксувати релевантні шаблони.
Навчання без нагляду
- Виберіть відповідну кількість кластерів на основі знань предметної області або використовуючи такі методи, як метод ліктя.
- Розгляньте різні показники відстані, щоб виміряти подібність між точками даних.
- Упорядкуйте процес кластеризації, щоб уникнути переобладнання.
Підсумовуючи, машинне навчання включає численні завдання, прийоми, алгоритми, методи оцінки моделі та корисні підказки. Розуміючи ці аспекти, фахівці-практики можуть ефективно застосовувати машинне навчання до проблем реального світу та отримувати суттєві знання з даних. Наведені приклади коду демонструють використання контрольованих і неконтрольованих алгоритмів навчання, підкреслюючи їх практичну реалізацію.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- EVM Фінанси. Уніфікований інтерфейс для децентралізованих фінансів. Доступ тут.
- Quantum Media Group. ІЧ/ПР посилений. Доступ тут.
- PlatoAiStream. Web3 Data Intelligence. Розширення знань. Доступ тут.
- джерело: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/