
یہ پوسٹ Bosch Center for Artificial Intelligence (BCAI) سے Goktug Cinar، Michael Binder، اور Adrian Horvath نے مشترکہ طور پر لکھی ہے۔
زیادہ تر تنظیموں میں سٹریٹجک کاروباری فیصلوں اور مالیاتی منصوبہ بندی کے لیے محصول کی پیشن گوئی ایک مشکل لیکن اہم کام ہے۔ اکثر، مالیاتی تجزیہ کاروں کے ذریعہ آمدنی کی پیشن گوئی دستی طور پر کی جاتی ہے اور یہ وقت طلب اور ساپیکش دونوں ہوتا ہے۔ اس طرح کی دستی کوششیں خاص طور پر بڑے پیمانے پر، کثیر القومی کاروباری تنظیموں کے لیے چیلنجنگ ہوتی ہیں جن کے لیے وسیع پیمانے پر پروڈکٹ گروپس اور جغرافیائی علاقوں میں مختلف سطحوں پر آمدنی کی پیشن گوئی کی ضرورت ہوتی ہے۔ اس کے لیے نہ صرف درستگی کی ضرورت ہے بلکہ پیشین گوئیوں کی درجہ بندی کی ہم آہنگی بھی ضروری ہے۔
باش ایک کثیر القومی کارپوریشن ہے جس میں متعدد شعبوں میں کام کرنے والے اداروں بشمول آٹوموٹیو، صنعتی حل، اور اشیائے صرف۔ صحت مند کاروباری کارروائیوں پر درست اور مربوط آمدنی کی پیشن گوئی کے اثرات کو دیکھتے ہوئے، بوش سینٹر برائے مصنوعی ذہانت (BCAI) مالیاتی منصوبہ بندی کے عمل کی کارکردگی اور درستگی کو بہتر بنانے کے لیے مشین لرننگ (ML) کے استعمال میں بہت زیادہ سرمایہ کاری کر رہا ہے۔ مقصد یہ ہے کہ ML کے ذریعے معقول بیس لائن ریونیو کی پیشن گوئیاں فراہم کر کے دستی عمل کو کم کرنا ہے، جس میں مالیاتی تجزیہ کاروں کو اپنی صنعت اور ڈومین کے علم کا استعمال کرتے ہوئے کبھی کبھار ایڈجسٹمنٹ کی ضرورت ہوتی ہے۔
اس مقصد کو حاصل کرنے کے لیے، BCAI نے ایک داخلی پیشین گوئی کا فریم ورک تیار کیا ہے جو وسیع پیمانے پر بیس ماڈلز کے حسب ضرورت جوڑ کے ذریعے بڑے پیمانے پر درجہ بندی کی پیشن گوئی فراہم کرنے کے قابل ہے۔ ایک میٹا لرنر ہر بار سیریز سے نکالی گئی خصوصیات کی بنیاد پر بہترین کارکردگی کا مظاہرہ کرنے والے ماڈلز کا انتخاب کرتا ہے۔ پھر مجموعی پیشن گوئی حاصل کرنے کے لیے منتخب ماڈلز کی پیشن گوئیوں کا اوسط لیا جاتا ہے۔ آرکیٹیکچرل ڈیزائن کو ایک REST طرز کے انٹرفیس کے نفاذ کے ذریعے ماڈیولرائز اور قابل توسیع بنایا گیا ہے، جو اضافی ماڈلز کی شمولیت کے ذریعے کارکردگی میں مسلسل بہتری کی اجازت دیتا ہے۔
BCAI نے اس کے ساتھ شراکت کی۔ ایمیزون ایم ایل حل لیب (MLSL) ڈیپ نیورل نیٹ ورک (DNN) پر مبنی ماڈلز میں ریونیو کی پیشن گوئی کے لیے تازہ ترین پیش رفت کو شامل کرنے کے لیے۔ عصبی پیشن گوئی کرنے والوں میں حالیہ پیش رفت نے پیشین گوئی کے بہت سے عملی مسائل کے لیے جدید ترین کارکردگی کا مظاہرہ کیا ہے۔ روایتی پیشن گوئی کے ماڈلز کے مقابلے میں، بہت سے عصبی پیشن گوئی کرنے والے اضافی کوویریٹس یا ٹائم سیریز کے میٹا ڈیٹا کو شامل کر سکتے ہیں۔ ہم CNN-QR اور DeepAR+، دو آف دی شیلف ماڈلز شامل کرتے ہیں۔ ایمیزون کی پیشن گوئیکے ساتھ ساتھ ایک حسب ضرورت ٹرانسفارمر ماڈل کا استعمال کرتے ہوئے تربیت یافتہ ایمیزون سیج میکر. تینوں ماڈلز انکوڈر بیک بونز کے نمائندہ سیٹ کا احاطہ کرتے ہیں جو اکثر عصبی پیشن گوئی کرنے والوں میں استعمال ہوتے ہیں: convolutional neural network (CNN)، سیکوینشل ریکرنٹ نیورل نیٹ ورک (RNN)، اور ٹرانسفارمر پر مبنی انکوڈرز۔
BCAI-MLSL شراکت داری کو درپیش کلیدی چیلنجوں میں سے ایک COVID-19 کے اثرات کے تحت مضبوط اور معقول پیشین گوئیاں فراہم کرنا تھا، یہ ایک بے مثال عالمی واقعہ ہے جو عالمی کارپوریٹ مالیاتی نتائج پر زبردست اتار چڑھاؤ کا باعث ہے۔ چونکہ عصبی پیشن گوئی کرنے والوں کو تاریخی اعداد و شمار پر تربیت دی جاتی ہے، اس لیے زیادہ اتار چڑھاؤ والے ادوار سے باہر کی تقسیم کے ڈیٹا کی بنیاد پر پیدا ہونے والی پیشین گوئیاں غلط اور ناقابل اعتبار ہو سکتی ہیں۔ لہذا، ہم نے اس مسئلے کو حل کرنے کے لیے ٹرانسفارمر فن تعمیر میں ایک نقاب پوش توجہ کا طریقہ کار شامل کرنے کی تجویز پیش کی۔
اعصابی پیشن گوئی کرنے والوں کو ایک سنگل جوڑ ماڈل کے طور پر بنڈل کیا جا سکتا ہے، یا انفرادی طور پر بوش کے ماڈل کائنات میں شامل کیا جا سکتا ہے، اور REST API کے اختتامی نقطوں کے ذریعے آسانی سے رسائی حاصل کی جا سکتی ہے۔ ہم بیک ٹیسٹ نتائج کے ذریعے عصبی پیشن گوئی کرنے والوں کو جوڑنے کے لیے ایک نقطہ نظر تجویز کرتے ہیں، جو وقت کے ساتھ ساتھ مسابقتی اور مضبوط کارکردگی فراہم کرتا ہے۔ مزید برآں، ہم نے متعدد کلاسیکی درجہ بندی کی مفاہمت کی تکنیکوں کی چھان بین کی اور ان کا جائزہ لیا تاکہ یہ یقینی بنایا جا سکے کہ پیشن گوئیاں پروڈکٹ گروپس، جغرافیوں اور کاروباری تنظیموں میں ہم آہنگی سے جمع ہوں۔
اس پوسٹ میں، ہم مندرجہ ذیل کا مظاہرہ کرتے ہیں:
- درجہ بندی، بڑے پیمانے پر ٹائم سیریز کی پیشن گوئی کے مسائل کے لیے Forecast اور SageMaker کسٹم ماڈل ٹریننگ کا اطلاق کیسے کریں
- پیشن گوئی سے آف دی شیلف ماڈلز کے ساتھ حسب ضرورت ماڈلز کو کیسے جوڑنا ہے۔
- پیش گوئی کے مسائل پر خلل ڈالنے والے واقعات جیسے COVID-19 کے اثرات کو کیسے کم کیا جائے۔
- AWS پر اینڈ ٹو اینڈ فورکاسٹنگ ورک فلو کیسے بنایا جائے۔
چیلنجز
ہم نے دو چیلنجوں کو حل کیا: درجہ بندی، بڑے پیمانے پر محصول کی پیشن گوئی، اور طویل مدتی پیشن گوئی پر COVID-19 وبائی امراض کا اثر۔
درجہ بندی، بڑے پیمانے پر محصول کی پیشن گوئی
مالیاتی تجزیہ کاروں کو اہم مالیاتی اعداد و شمار کی پیشن گوئی کرنے کا کام سونپا جاتا ہے، بشمول آمدنی، آپریشنل اخراجات، اور R&D اخراجات۔ یہ میٹرکس جمع کی مختلف سطحوں پر کاروباری منصوبہ بندی کی بصیرت فراہم کرتے ہیں اور ڈیٹا پر مبنی فیصلہ سازی کو فعال کرتے ہیں۔ کسی بھی خودکار پیشین گوئی کے حل کو کاروباری لائن جمع کی کسی بھی من مانی سطح پر پیشن گوئی فراہم کرنے کی ضرورت ہے۔ بوش میں، مجموعوں کو درجہ بندی کی ساخت کی زیادہ عمومی شکل کے طور پر گروپ ٹائم سیریز کے طور پر تصور کیا جا سکتا ہے۔ مندرجہ ذیل اعداد و شمار دو سطحی ڈھانچے کے ساتھ ایک آسان مثال دکھاتا ہے، جو بوش میں درجہ بندی کی آمدنی کی پیشن گوئی کے ڈھانچے کی نقل کرتا ہے۔ کل آمدنی کو پروڈکٹ اور علاقے کی بنیاد پر مجموعوں کی متعدد سطحوں میں تقسیم کیا جاتا ہے۔
وقت کی سیریز کی کل تعداد جس کی Bosch میں پیشین گوئی کرنے کی ضرورت ہے لاکھوں کے پیمانے پر ہے۔ نوٹ کریں کہ اعلی سطحی ٹائم سیریز کو مصنوعات یا خطوں کے لحاظ سے تقسیم کیا جا سکتا ہے، جس سے نیچے کی سطح کی پیشین گوئیوں کے متعدد راستے بنتے ہیں۔ مستقبل میں 12 مہینوں کی پیشن گوئی افق کے ساتھ درجہ بندی کے ہر نوڈ پر محصول کی پیشن گوئی کی ضرورت ہے۔ ماہانہ تاریخی ڈیٹا دستیاب ہے۔
درجہ بندی کی ساخت کو مندرجہ ذیل شکل کا استعمال کرتے ہوئے سمنگ میٹرکس کے اشارے کے ساتھ پیش کیا جا سکتا ہے۔ S (ہینڈ مین اور ایتھاناسوپولوس):
![]()
اس مساوات میں ، Y مندرجہ ذیل کے برابر ہے:

یہاں، b وقت پر نیچے کی سطح کی ٹائم سیریز کی نمائندگی کرتا ہے۔ t.
COVID-19 وبائی امراض کے اثرات
کام اور سماجی زندگی کے تقریباً تمام پہلوؤں پر اس کے خلل انگیز اور بے مثال اثرات کی وجہ سے COVID-19 وبائی مرض نے پیشن گوئی کے لیے اہم چیلنجز لائے۔ طویل مدتی محصول کی پیشن گوئی کے لیے، خلل نے غیر متوقع بہاو اثرات بھی لائے۔ اس مسئلے کو واضح کرنے کے لیے، مندرجہ ذیل اعداد و شمار ایک نمونہ ٹائم سیریز دکھاتا ہے جہاں وبائی امراض کے آغاز میں مصنوعات کی آمدنی میں نمایاں کمی واقع ہوئی تھی اور اس کے بعد بتدریج بحالی ہوئی تھی۔ ایک عام اعصابی پیشن گوئی کا ماڈل آمدنی کا ڈیٹا لے گا جس میں آؤٹ آف ڈسٹری بیوشن (OOD) COVID دورانیے کو تاریخی سیاق و سباق کے ان پٹ کے ساتھ ساتھ ماڈل ٹریننگ کے لیے زمینی سچائی بھی شامل ہے۔ نتیجے کے طور پر، پیدا کی گئی پیشن گوئی اب قابل اعتماد نہیں ہے.

ماڈلنگ کے طریقے
اس سیکشن میں، ہم اپنے مختلف ماڈلنگ کے طریقوں پر تبادلہ خیال کرتے ہیں۔
ایمیزون کی پیشن گوئی
پیشن گوئی AWS کی طرف سے مکمل طور پر منظم AI/ML سروس ہے جو پہلے سے ترتیب شدہ، جدید ترین ٹائم سیریز کی پیشن گوئی کے ماڈل فراہم کرتی ہے۔ یہ ان پیشکشوں کو خودکار ہائپر پیرامیٹر آپٹیمائزیشن، جوڑ ماڈلنگ (پیش گوئی کے ذریعہ فراہم کردہ ماڈلز کے لیے) اور امکانی پیشن گوئی کی تیاری کے لیے اپنی داخلی صلاحیتوں کے ساتھ جوڑتا ہے۔ یہ آپ کو آسانی سے حسب ضرورت ڈیٹا سیٹس، پری پروسیس ڈیٹا، ٹرین کی پیشن گوئی کرنے والے ماڈلز، اور مضبوط پیشن گوئی پیدا کرنے کی اجازت دیتا ہے۔ سروس کا ماڈیولر ڈیزائن ہمیں مزید آسانی سے استفسار کرنے اور متوازی طور پر تیار کردہ اضافی حسب ضرورت ماڈلز سے پیشین گوئیوں کو یکجا کرنے کے قابل بناتا ہے۔
ہم پیشن گوئی سے دو نیورل فورکاسٹرز کو شامل کرتے ہیں: CNN-QR اور DeepAR+۔ دونوں کی نگرانی کے گہرے سیکھنے کے طریقے ہیں جو پورے ٹائم سیریز ڈیٹاسیٹ کے لیے ایک عالمی ماڈل کو تربیت دیتے ہیں۔ CNNQR اور DeepAR+ دونوں ماڈلز ہر بار سیریز کے بارے میں جامد میٹا ڈیٹا معلومات لے سکتے ہیں، جو ہمارے معاملے میں متعلقہ پروڈکٹ، علاقہ اور کاروباری تنظیم ہیں۔ وہ ماڈل میں ان پٹ کے حصے کے طور پر خود بخود وقتی خصوصیات جیسے سال کا مہینہ بھی شامل کرتے ہیں۔
COVID کے لیے توجہ کے ماسک کے ساتھ ٹرانسفارمر
ٹرانسفارمر فن تعمیر (واسوانی وغیرہ۔)، اصل میں قدرتی زبان کی پروسیسنگ (NLP) کے لیے ڈیزائن کیا گیا تھا، جو حال ہی میں ٹائم سیریز کی پیشن گوئی کے لیے ایک مقبول آرکیٹیکچرل انتخاب کے طور پر ابھرا ہے۔ یہاں، ہم نے ٹرانسفارمر فن تعمیر کا استعمال کیا جس میں بیان کیا گیا ہے۔ چاؤ وغیرہ۔ امکانی لاگ ویرل توجہ کے بغیر۔ ماڈل ایک انکوڈر اور ڈیکوڈر کو ملا کر ایک عام فن تعمیر کا ڈیزائن استعمال کرتا ہے۔ ریونیو کی پیشن گوئی کے لیے، ہم ڈیکوڈر کو ترتیب دیتے ہیں تاکہ 12 ماہ کے افق کی پیشن گوئی کو خود بخود انداز میں مہینہ بہ مہینہ پیدا کرنے کے بجائے براہ راست آؤٹ پٹ کریں۔ ٹائم سیریز کی فریکوئنسی کی بنیاد پر، وقت سے متعلق اضافی خصوصیات جیسے سال کا مہینہ ان پٹ متغیر کے طور پر شامل کیا جاتا ہے۔ میٹا معلومات (مصنوعات، علاقہ، کاروباری تنظیم) کو بیان کرنے والے اضافی کلیدی متغیرات کو ایک قابل تربیت ایمبیڈنگ پرت کے ذریعے نیٹ ورک میں فیڈ کیا جاتا ہے۔
مندرجہ ذیل خاکہ ٹرانسفارمر فن تعمیر اور توجہ کے ماسکنگ میکانزم کی وضاحت کرتا ہے۔ OOD ڈیٹا کو پیشن گوئی کو متاثر کرنے سے روکنے کے لیے، تمام انکوڈر اور ڈیکوڈر پرتوں پر توجہ کی ماسکنگ کا اطلاق ہوتا ہے، جیسا کہ نارنجی میں نمایاں کیا گیا ہے۔

ہم توجہ کے ماسک شامل کرکے OOD سیاق و سباق کی ونڈوز کے اثرات کو کم کرتے ہیں۔ ماڈل کو COVID کی مدت پر بہت کم توجہ دینے کی تربیت دی جاتی ہے جس میں ماسکنگ کے ذریعے آؤٹ لیرز ہوتے ہیں، اور نقاب پوش معلومات کے ساتھ پیشن گوئی انجام دیتے ہیں۔ توجہ کا ماسک ڈیکوڈر اور انکوڈر فن تعمیر کی ہر پرت پر لاگو ہوتا ہے۔ نقاب پوش ونڈو کو یا تو دستی طور پر یا آؤٹ لیئر ڈیٹیکشن الگورتھم کے ذریعے بیان کیا جا سکتا ہے۔ مزید برآں، ٹریننگ لیبل کے طور پر آؤٹ لیرز پر مشتمل ٹائم ونڈو کا استعمال کرتے ہوئے، نقصانات کو پیچھے سے نہیں پھیلایا جاتا ہے۔ اس توجہ کے ماسکنگ پر مبنی طریقہ کو دیگر نایاب واقعات کی وجہ سے آنے والی رکاوٹوں اور OOD کیسز کو سنبھالنے اور پیشین گوئیوں کی مضبوطی کو بہتر بنانے کے لیے لاگو کیا جا سکتا ہے۔
ماڈل کا جوڑا
ماڈل کا جوڑا اکثر پیش گوئی کے لیے سنگل ماڈلز سے بہتر کارکردگی کا مظاہرہ کرتا ہے — یہ ماڈل کی عمومی صلاحیت کو بہتر بناتا ہے اور وقفے وقفے اور وقفے وقفے سے مختلف خصوصیات کے ساتھ ٹائم سیریز کے ڈیٹا کو سنبھالنے میں بہتر ہے۔ ہم ماڈل کی کارکردگی اور پیشن گوئی کی مضبوطی کو بہتر بنانے کے لیے ماڈل کے جوڑ کی حکمت عملیوں کا ایک سلسلہ شامل کرتے ہیں۔ گہرے سیکھنے کے ماڈل کے جوڑ کی ایک عام شکل مختلف بے ترتیب وزن کی ابتدا کے ساتھ یا مختلف تربیتی دوروں سے ماڈل رنز کے مجموعی نتائج کو جمع کرنا ہے۔ ہم اس حکمت عملی کو ٹرانسفارمر ماڈل کے لیے پیشن گوئی حاصل کرنے کے لیے استعمال کرتے ہیں۔
ٹرانسفارمر، CNNQR، اور DeepAR+ جیسے مختلف ماڈل آرکیٹیکچرز کے اوپر ایک جوڑا بنانے کے لیے، ہم ایک پین-ماڈل جوڑ کی حکمت عملی استعمال کرتے ہیں جو بیک ٹیسٹ نتائج کی بنیاد پر ہر بار سیریز کے لیے ٹاپ-k بہترین کارکردگی والے ماڈلز کا انتخاب کرتی ہے اور ان کے اوسط چونکہ بیک ٹیسٹ نتائج براہ راست تربیت یافتہ Forecast ماڈلز سے برآمد کیے جا سکتے ہیں، اس لیے یہ حکمت عملی ہمیں ٹرانسفارمر جیسے کسٹم ماڈلز سے حاصل کردہ بہتری کے ساتھ Forecast جیسی ٹرنکی سروسز سے فائدہ اٹھانے کے قابل بناتی ہے۔ اس طرح کے اختتام سے آخر تک ماڈل کے جوڑ کے انداز میں میٹا لرنر کو تربیت دینے یا ماڈل کے انتخاب کے لیے ٹائم سیریز کی خصوصیات کا حساب لگانے کی ضرورت نہیں ہے۔
درجہ بندی کی مفاہمت
درجہ بندی کی پیشن گوئی مفاہمت کے لیے پوسٹ پروسیسنگ کے اقدامات کے طور پر فریم ورک وسیع پیمانے پر تکنیکوں کو شامل کرنے کے لیے موافق ہے، بشمول نیچے سے اوپر (BU)، پیشن گوئی کے تناسب کے ساتھ اوپر سے نیچے مفاہمت (TDFP)، عام کم سے کم مربع (OLS)، اور وزنی کم سے کم مربع (او ایل ایس)۔ WLS)۔ اس پوسٹ میں تمام تجرباتی نتائج پیشین گوئی کے تناسب کے ساتھ اوپر سے نیچے مفاہمت کا استعمال کرتے ہوئے رپورٹ کیے گئے ہیں۔
فن تعمیر کا جائزہ
ہم نے AWS پر ایک خودکار اینڈ ٹو اینڈ ورک فلو تیار کیا ہے تاکہ پیشن گوئی، سیج میکر، ایمیزون سادہ اسٹوریج سروس (ایمیزون S3)، او ڈبلیو ایس لامبڈا۔, AWS اسٹیپ فنکشنز، اور AWS کلاؤڈ ڈویلپمنٹ کٹ (AWS CDK)۔ تعینات کردہ حل REST API کا استعمال کرتے ہوئے انفرادی ٹائم سیریز کی پیشن گوئی فراہم کرتا ہے۔ ایمیزون API گیٹ وے، نتائج کو پہلے سے طے شدہ JSON فارمیٹ میں واپس کر کے۔
مندرجہ ذیل خاکہ آخر سے آخر تک پیشین گوئی کے کام کے بہاؤ کو واضح کرتا ہے۔

فن تعمیر کے لیے کلیدی ڈیزائن کے تحفظات استرتا، کارکردگی، اور صارف دوستی ہیں۔ کم سے کم مطلوبہ تبدیلیوں کے ساتھ، ترقی اور تعیناتی کے دوران الگورتھم کے متنوع سیٹ کو شامل کرنے کے لیے نظام کو کافی حد تک ورسٹائل ہونا چاہیے، اور مستقبل میں نئے الگورتھم شامل کرتے وقت اسے آسانی سے بڑھایا جا سکتا ہے۔ تربیت کے وقت کو کم کرنے اور تازہ ترین پیشن گوئی کو تیزی سے حاصل کرنے کے لیے سسٹم کو کم از کم اوور ہیڈ کا اضافہ کرنا چاہیے اور Forecast اور SageMaker دونوں کے لیے متوازی تربیت کی حمایت کرنی چاہیے۔ آخر میں، سسٹم کو تجرباتی مقاصد کے لیے استعمال کرنا آسان ہونا چاہیے۔
اینڈ ٹو اینڈ ورک فلو ترتیب وار درج ذیل ماڈیولز کے ذریعے چلتا ہے:
- ڈیٹا ری فارمیٹنگ اور تبدیلی کے لیے ایک پری پروسیسنگ ماڈیول
- سیج میکر پر پیشن گوئی ماڈل اور کسٹم ماڈل دونوں کو شامل کرنے والا ایک ماڈل ٹریننگ ماڈیول (دونوں متوازی چل رہے ہیں)
- ایک پوسٹ پروسیسنگ ماڈیول جو ماڈل کے جوڑ، درجہ بندی کی مفاہمت، میٹرکس، اور رپورٹ جنریشن کی حمایت کرتا ہے۔
سٹیپ فنکشنز ایک ریاستی مشین کے طور پر سرے سے آخر تک ورک فلو کو منظم اور ترتیب دیتا ہے۔ اسٹیٹ مشین رن کو ایک JSON فائل کے ساتھ ترتیب دیا گیا ہے جس میں تمام ضروری معلومات شامل ہیں، بشمول Amazon S3 میں تاریخی آمدنی کی CSV فائلوں کا مقام، پیشن گوئی کے آغاز کا وقت، اور اختتام سے آخر تک کام کے فلو کو چلانے کے لیے ماڈل ہائپر پیرامیٹر کی ترتیبات۔ لامبڈا فنکشنز کا استعمال کرتے ہوئے اسٹیٹ مشین میں ماڈل ٹریننگ کو متوازی بنانے کے لیے غیر مطابقت پذیر کالیں بنائی جاتی ہیں۔ تمام تاریخی ڈیٹا، کنفگ فائلز، پیشن گوئی کے نتائج، نیز انٹرمیڈیٹ نتائج جیسے بیک ٹیسٹنگ کے نتائج Amazon S3 میں محفوظ ہیں۔ REST API کو Amazon S3 کے اوپر بنایا گیا ہے تاکہ پیشن گوئی کے نتائج کے بارے میں استفسار کرنے کے لیے قابل استفسار انٹرفیس فراہم کیا جا سکے۔ پیشن گوئی کے نئے ماڈلز اور معاون افعال جیسے پیشن گوئی کی تصویری رپورٹیں تیار کرنے کے لیے نظام کو بڑھایا جا سکتا ہے۔
تشخیص
اس سیکشن میں، ہم تجرباتی سیٹ اپ کی تفصیل دیتے ہیں۔ کلیدی اجزاء میں ڈیٹاسیٹ، تشخیصی میٹرکس، بیک ٹیسٹ ونڈوز، اور ماڈل سیٹ اپ اور ٹریننگ شامل ہیں۔
ڈیٹا بیس
بامعنی ڈیٹاسیٹ کا استعمال کرتے ہوئے بوش کی مالی رازداری کے تحفظ کے لیے، ہم نے ایک مصنوعی ڈیٹاسیٹ استعمال کیا جس میں بوش کے ایک کاروباری یونٹ سے حقیقی دنیا کے ریونیو ڈیٹاسیٹ سے ملتے جلتے شماریاتی خصوصیات ہیں۔ ڈیٹاسیٹ میں مجموعی طور پر 1,216 ٹائم سیریز ہے جس میں ماہانہ فریکوئنسی میں ریونیو ریکارڈ کیا گیا ہے، جس میں جنوری 2016 سے اپریل 2022 تک کا احاطہ کیا گیا ہے۔ ڈیٹاسیٹ کو 877 ٹائم سیریز کے ساتھ انتہائی دانے دار سطح (نیچے ٹائم سیریز) کے ساتھ ڈیلیور کیا گیا ہے، جس میں گروپ بند ٹائم سیریز کی ساخت کی نمائندگی کی گئی ہے۔ بطور خلاصہ میٹرکس S۔ ہر بار سیریز تین جامد واضح صفات کے ساتھ منسلک ہوتی ہے، جو حقیقی ڈیٹاسیٹ میں پروڈکٹ کے زمرے، علاقے اور تنظیمی اکائی سے مطابقت رکھتی ہے (مصنوعی ڈیٹا میں گمنام)۔
تشخیصی میٹرکس
ہم ماڈل کی کارکردگی کا جائزہ لینے اور تقابلی تجزیہ کرنے کے لیے میڈین-مین آرکٹینجینٹ مطلق فیصدی خرابی (میڈین-MAAPE) اور وزنی-MAAPE استعمال کرتے ہیں، جو بوش میں استعمال ہونے والے معیاری میٹرکس ہیں۔ MAAPE عام طور پر کاروباری سیاق و سباق میں استعمال ہونے والے اوسط مطلق فیصدی غلطی (MAPE) میٹرک کی خامیوں کو دور کرتا ہے۔ میڈین-MAAPE ہر بار سیریز پر انفرادی طور پر شمار کیے جانے والے MAAPEs کے میڈین کو کمپیوٹنگ کرکے ماڈل کی کارکردگی کا ایک جائزہ پیش کرتا ہے۔ وزنی-MAAPE انفرادی MAAPEs کے وزنی مجموعہ کی اطلاع دیتا ہے۔ وزن پورے ڈیٹا سیٹ کی مجموعی آمدنی کے مقابلے میں ہر بار کی سیریز کے لیے آمدنی کا تناسب ہے۔ Weighted-MAAPE پیشن گوئی کی درستگی کے بہاو کاروباری اثرات کو بہتر طور پر ظاہر کرتا ہے۔ دونوں میٹرکس 1,216 ٹائم سیریز کے پورے ڈیٹاسیٹ پر رپورٹ کیے گئے ہیں۔
بیک ٹیسٹ ونڈوز
ہم ماڈل کی کارکردگی کا موازنہ کرنے کے لیے 12 ماہ کی بیک ٹیسٹ ونڈوز کا استعمال کرتے ہیں۔ مندرجہ ذیل اعداد و شمار تجربات میں استعمال ہونے والی بیکٹیسٹ ونڈوز کی وضاحت کرتا ہے اور تربیت اور ہائپر پیرامیٹر آپٹیمائزیشن (HPO) کے لیے استعمال ہونے والے متعلقہ ڈیٹا کو نمایاں کرتا ہے۔ COVID-19 شروع ہونے کے بعد بیک ٹیسٹ ونڈوز کے لیے، نتیجہ اپریل سے مئی 2020 تک کے OOD ان پٹ سے متاثر ہوتا ہے، اس کی بنیاد پر جو ہم نے ریونیو ٹائم سیریز سے مشاہدہ کیا ہے۔

ماڈل سیٹ اپ اور تربیت
ٹرانسفارمر ٹریننگ کے لیے، ہم نے کوانٹائل نقصان کا استعمال کیا اور ہر بار سیریز کو ٹرانسفارمر میں فیڈ کرنے اور ٹریننگ نقصان کا حساب لگانے سے پہلے اس کی تاریخی اوسط قدر کا استعمال کرتے ہوئے اسکیل کیا۔ میں لاگو MeanScaler کا استعمال کرتے ہوئے درستگی میٹرکس کا حساب لگانے کے لیے حتمی پیشین گوئیوں کو دوبارہ اسکیل کیا جاتا ہے۔ گلوون ٹی ایس. ہم گزشتہ 18 مہینوں کے ماہانہ ریونیو ڈیٹا کے ساتھ ایک سیاق و سباق کی ونڈو کا استعمال کرتے ہیں، جو جولائی 2018 سے جون 2019 تک کی بیک ٹیسٹ ونڈو میں HPO کے ذریعے منتخب کی گئی ہے۔ جامد زمرہ واری ایبلز کی شکل میں ہر بار سیریز کے بارے میں اضافی میٹا ڈیٹا ایک ایمبیڈنگ کے ذریعے ماڈل میں فیڈ کیا جاتا ہے۔ ٹرانسفارمر کی تہوں کو کھانا کھلانے سے پہلے تہہ لگائیں۔ ہم ٹرانسفارمر کو پانچ مختلف بے ترتیب وزن کے آغاز کے ساتھ تربیت دیتے ہیں اور ہر رن کے لیے آخری تین عہدوں سے پیشن گوئی کے نتائج کی اوسط کرتے ہیں، کل اوسطاً 15 ماڈلز۔ ٹریننگ کے وقت کو کم کرنے کے لیے پانچ ماڈل ٹریننگ رنز کو متوازی بنایا جا سکتا ہے۔ نقاب پوش ٹرانسفارمر کے لیے، ہم اپریل سے مئی 2020 کے مہینوں کو آؤٹ لئیر کے طور پر بتاتے ہیں۔
تمام پیشن گوئی ماڈل ٹریننگ کے لیے، ہم نے خودکار HPO کو فعال کیا، جو صارف کے مخصوص بیک ٹیسٹ پیریڈ کی بنیاد پر ماڈل اور ٹریننگ کے پیرامیٹرز کو منتخب کر سکتا ہے، جو کہ ٹریننگ اور HPO کے لیے استعمال ہونے والی ڈیٹا ونڈو میں آخری 12 مہینوں پر سیٹ ہے۔
تجرباتی نتائج
ہم ہائیپرپیرامیٹر کے ایک ہی سیٹ کا استعمال کرتے ہوئے نقاب پوش اور بے نقاب ٹرانسفارمرز کو تربیت دیتے ہیں، اور COVID-19 جھٹکے کے فوراً بعد بیک ٹیسٹ ونڈوز کے لیے ان کی کارکردگی کا موازنہ کرتے ہیں۔ نقاب پوش ٹرانسفارمر میں، دو نقاب پوش مہینے اپریل اور مئی 2020 ہیں۔ درج ذیل جدول میں جون 12 سے شروع ہونے والی 2020 ماہ کی پیشن گوئی ونڈوز کے ساتھ بیک ٹیسٹ پیریڈز کی سیریز کے نتائج دکھائے گئے ہیں۔ ہم مشاہدہ کر سکتے ہیں کہ نقاب پوش ٹرانسفارمر مسلسل غیر نقاب شدہ ورژن سے بہتر کارکردگی کا مظاہرہ کرتا ہے۔ .

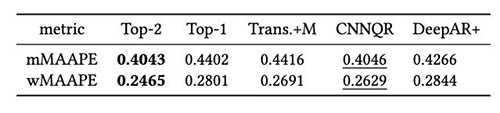
ہم نے بیک ٹیسٹ کے نتائج کی بنیاد پر ماڈل کے جوڑ کی حکمت عملی پر مزید جانچ کی۔ خاص طور پر، ہم ان دو صورتوں کا موازنہ کرتے ہیں جب صرف اعلی کارکردگی کا مظاہرہ کرنے والے ماڈل کو منتخب کیا جاتا ہے بمقابلہ جب سب سے اوپر دو کارکردگی دکھانے والے ماڈلز کو منتخب کیا جاتا ہے، اور ماڈل کی اوسط پیشن گوئی کی اوسط قدر کی گنتی کے ذریعے انجام دی جاتی ہے۔ ہم مندرجہ ذیل اعداد و شمار میں بیس ماڈلز اور جوڑا ماڈلز کی کارکردگی کا موازنہ کرتے ہیں۔ نوٹ کریں کہ عصبی پیشن گوئی کرنے والوں میں سے کوئی بھی مسلسل رولنگ بیک ٹیسٹ ونڈوز کے لیے دوسروں سے بہتر کارکردگی کا مظاہرہ نہیں کرتا ہے۔


درج ذیل جدول سے پتہ چلتا ہے کہ، اوسطاً، سب سے اوپر کے دو ماڈلز کی جوڑ توڑ ماڈلنگ بہترین کارکردگی دیتی ہے۔ CNNQR دوسرا بہترین نتیجہ فراہم کرتا ہے۔
نتیجہ
اس پوسٹ میں دکھایا گیا ہے کہ کس طرح بڑے پیمانے پر پیشین گوئی کے مسائل کے لیے ایک اینڈ ٹو اینڈ ایم ایل حل تیار کیا جاتا ہے جس میں Forecast اور SageMaker پر تربیت یافتہ ایک حسب ضرورت ماڈل شامل ہے۔ آپ کی کاروباری ضروریات اور ایم ایل کے علم پر منحصر ہے، آپ پیشن گوئی کے ماڈل کی تعمیر، ٹرین، اور تعیناتی کے عمل کو آف لوڈ کرنے کے لیے پیشن گوئی جیسی مکمل طور پر منظم سروس استعمال کر سکتے ہیں۔ SageMaker کے ساتھ مخصوص ٹیوننگ میکانزم کے ساتھ اپنا حسب ضرورت ماڈل بنائیں؛ یا دونوں خدمات کو ملا کر ماڈل جوڑنا انجام دیں۔
اگر آپ اپنی مصنوعات اور خدمات میں ایم ایل کے استعمال کو تیز کرنے میں مدد چاہتے ہیں، تو براہ کرم رابطہ کریں۔ ایمیزون ایم ایل حل لیب پروگرام.
حوالہ جات
Hyndman RJ، Athanasopoulos G. پیشن گوئی: اصول اور عمل. OT ٹیکسٹس؛ 2018 مئی 8۔
واسوانی اے، شازیر این، پرمار این، اسزکوریت جے، جونز ایل، گومز اے این، قیصر Ł، پولوسوخن I۔ توجہ صرف آپ کی ضرورت ہے۔ نیورل انفارمیشن پروسیسنگ سسٹم میں پیشرفت۔ 2017؛ 30۔
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Informer: Beyond Efficient Transformer for long sequence time-series forecasting. AAAI 2021 کی کارروائی 2 فروری۔
مصنفین کے بارے میں
 گوکٹگ سینار رابرٹ بوش ایل ایل سی اور بوش سنٹر فار آرٹیفیشل انٹیلی جنس میں ایم ایل اور اعدادوشمار پر مبنی پیشن گوئی کا لیڈ ایم ایل سائنسدان اور ٹیکنیکل لیڈ ہے۔ وہ پیشن گوئی کے ماڈلز، درجہ بندی کے استحکام، اور ماڈل کے امتزاج کی تکنیکوں کے ساتھ ساتھ سافٹ ویئر ڈویلپمنٹ ٹیم کی تحقیق کی رہنمائی کرتا ہے جو ان ماڈلز کی پیمائش کرتی ہے اور ان کو اندرونی اینڈ ٹو اینڈ فنانشل فورکاسٹنگ سافٹ ویئر کے حصے کے طور پر کام کرتی ہے۔
گوکٹگ سینار رابرٹ بوش ایل ایل سی اور بوش سنٹر فار آرٹیفیشل انٹیلی جنس میں ایم ایل اور اعدادوشمار پر مبنی پیشن گوئی کا لیڈ ایم ایل سائنسدان اور ٹیکنیکل لیڈ ہے۔ وہ پیشن گوئی کے ماڈلز، درجہ بندی کے استحکام، اور ماڈل کے امتزاج کی تکنیکوں کے ساتھ ساتھ سافٹ ویئر ڈویلپمنٹ ٹیم کی تحقیق کی رہنمائی کرتا ہے جو ان ماڈلز کی پیمائش کرتی ہے اور ان کو اندرونی اینڈ ٹو اینڈ فنانشل فورکاسٹنگ سافٹ ویئر کے حصے کے طور پر کام کرتی ہے۔
 مائیکل بائنڈر بوش گلوبل سروسز میں ایک پروڈکٹ کا مالک ہے، جہاں وہ مالیاتی اہم اعداد و شمار کی بڑے پیمانے پر خودکار ڈیٹا سے چلنے والی پیشن گوئی کے لیے کمپنی کی وسیع پیشن گوئی کرنے والی تجزیاتی ایپلی کیشن کی ترقی، تعیناتی اور نفاذ کو مربوط کرتا ہے۔
مائیکل بائنڈر بوش گلوبل سروسز میں ایک پروڈکٹ کا مالک ہے، جہاں وہ مالیاتی اہم اعداد و شمار کی بڑے پیمانے پر خودکار ڈیٹا سے چلنے والی پیشن گوئی کے لیے کمپنی کی وسیع پیشن گوئی کرنے والی تجزیاتی ایپلی کیشن کی ترقی، تعیناتی اور نفاذ کو مربوط کرتا ہے۔
 ایڈرین ہوروتھ بوش سینٹر فار آرٹیفیشل انٹیلی جنس میں ایک سافٹ ویئر ڈویلپر ہے، جہاں وہ مختلف پیشن گوئی کے ماڈلز کی بنیاد پر پیشین گوئیاں بنانے کے لیے نظام تیار کرتا ہے اور اسے برقرار رکھتا ہے۔
ایڈرین ہوروتھ بوش سینٹر فار آرٹیفیشل انٹیلی جنس میں ایک سافٹ ویئر ڈویلپر ہے، جہاں وہ مختلف پیشن گوئی کے ماڈلز کی بنیاد پر پیشین گوئیاں بنانے کے لیے نظام تیار کرتا ہے اور اسے برقرار رکھتا ہے۔
 پانپن سو AWS میں Amazon ML Solutions Lab کے ساتھ ایک سینئر اپلائیڈ سائنٹسٹ اور مینیجر ہیں۔ وہ مشین لرننگ الگورتھم کی تحقیق اور ترقی پر کام کر رہی ہے تاکہ ان کے AI اور کلاؤڈ کو اپنانے کو تیز کرنے کے لیے صنعتی عمودی کی ایک قسم میں اعلیٰ اثر والے کسٹمر ایپلی کیشنز کے لیے۔ اس کی تحقیقی دلچسپی میں ماڈل کی تشریح، وجہ تجزیہ، ہیومن ان دی لوپ AI اور انٹرایکٹو ڈیٹا ویژولائزیشن شامل ہے۔
پانپن سو AWS میں Amazon ML Solutions Lab کے ساتھ ایک سینئر اپلائیڈ سائنٹسٹ اور مینیجر ہیں۔ وہ مشین لرننگ الگورتھم کی تحقیق اور ترقی پر کام کر رہی ہے تاکہ ان کے AI اور کلاؤڈ کو اپنانے کو تیز کرنے کے لیے صنعتی عمودی کی ایک قسم میں اعلیٰ اثر والے کسٹمر ایپلی کیشنز کے لیے۔ اس کی تحقیقی دلچسپی میں ماڈل کی تشریح، وجہ تجزیہ، ہیومن ان دی لوپ AI اور انٹرایکٹو ڈیٹا ویژولائزیشن شامل ہے۔
 جسلین گریوال ایمیزون ویب سروسز میں ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ مشین لرننگ کا استعمال کرتے ہوئے حقیقی دنیا کے مسائل کو حل کرنے کے لیے AWS صارفین کے ساتھ کام کرتی ہے، خاص طور پر درست ادویات اور جینومکس پر توجہ مرکوز کرتے ہوئے۔ بائیو انفارمیٹکس، آنکولوجی اور کلینیکل جینومکس میں اس کا پس منظر مضبوط ہے۔ وہ مریضوں کی دیکھ بھال کو بہتر بنانے کے لیے AI/ML اور کلاؤڈ سروسز استعمال کرنے کا شوق رکھتی ہے۔
جسلین گریوال ایمیزون ویب سروسز میں ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ مشین لرننگ کا استعمال کرتے ہوئے حقیقی دنیا کے مسائل کو حل کرنے کے لیے AWS صارفین کے ساتھ کام کرتی ہے، خاص طور پر درست ادویات اور جینومکس پر توجہ مرکوز کرتے ہوئے۔ بائیو انفارمیٹکس، آنکولوجی اور کلینیکل جینومکس میں اس کا پس منظر مضبوط ہے۔ وہ مریضوں کی دیکھ بھال کو بہتر بنانے کے لیے AI/ML اور کلاؤڈ سروسز استعمال کرنے کا شوق رکھتی ہے۔
 سیلوان سینتھیویل AWS میں Amazon ML Solutions Lab کے ساتھ ایک سینئر ML انجینئر ہے، جو مشین لرننگ، گہری سیکھنے کے مسائل، اور اینڈ ٹو اینڈ ML سلوشنز پر صارفین کی مدد کرنے پر توجہ مرکوز کرتا ہے۔ وہ Amazon Comprehend Medical کے بانی انجینئرنگ لیڈ تھے اور انہوں نے متعدد AWS AI سروسز کے ڈیزائن اور فن تعمیر میں تعاون کیا۔
سیلوان سینتھیویل AWS میں Amazon ML Solutions Lab کے ساتھ ایک سینئر ML انجینئر ہے، جو مشین لرننگ، گہری سیکھنے کے مسائل، اور اینڈ ٹو اینڈ ML سلوشنز پر صارفین کی مدد کرنے پر توجہ مرکوز کرتا ہے۔ وہ Amazon Comprehend Medical کے بانی انجینئرنگ لیڈ تھے اور انہوں نے متعدد AWS AI سروسز کے ڈیزائن اور فن تعمیر میں تعاون کیا۔
 Ruilin Zhang AWS میں Amazon ML Solutions Lab کے ساتھ SDE ہے۔ وہ عام کاروباری مسائل کو حل کرنے کے لیے حل تیار کرکے صارفین کو AWS AI خدمات کو اپنانے میں مدد کرتا ہے۔
Ruilin Zhang AWS میں Amazon ML Solutions Lab کے ساتھ SDE ہے۔ وہ عام کاروباری مسائل کو حل کرنے کے لیے حل تیار کرکے صارفین کو AWS AI خدمات کو اپنانے میں مدد کرتا ہے۔
 شان رائے AWS میں Amazon ML Solutions Lab کے ساتھ Sr. ML سٹریٹجسٹ ہے۔ وہ AWS کی کلاؤڈ بیسڈ AI/ML خدمات کا استعمال کرتے ہوئے صنعتوں کے متنوع سپیکٹرم میں صارفین کے ساتھ کام کرتا ہے تاکہ ان کی انتہائی اہم اور جدید کاروباری ضروریات کو حل کیا جا سکے۔
شان رائے AWS میں Amazon ML Solutions Lab کے ساتھ Sr. ML سٹریٹجسٹ ہے۔ وہ AWS کی کلاؤڈ بیسڈ AI/ML خدمات کا استعمال کرتے ہوئے صنعتوں کے متنوع سپیکٹرم میں صارفین کے ساتھ کام کرتا ہے تاکہ ان کی انتہائی اہم اور جدید کاروباری ضروریات کو حل کیا جا سکے۔
 لن لی چیونگ AWS میں Amazon ML Solutions Lab ٹیم کے ساتھ ایک اپلائیڈ سائنس مینیجر ہے۔ وہ نئی بصیرتیں دریافت کرنے اور پیچیدہ مسائل کو حل کرنے کے لیے مصنوعی ذہانت اور مشین لرننگ کو دریافت کرنے اور لاگو کرنے کے لیے اسٹریٹجک AWS صارفین کے ساتھ کام کرتی ہے۔
لن لی چیونگ AWS میں Amazon ML Solutions Lab ٹیم کے ساتھ ایک اپلائیڈ سائنس مینیجر ہے۔ وہ نئی بصیرتیں دریافت کرنے اور پیچیدہ مسائل کو حل کرنے کے لیے مصنوعی ذہانت اور مشین لرننگ کو دریافت کرنے اور لاگو کرنے کے لیے اسٹریٹجک AWS صارفین کے ساتھ کام کرتی ہے۔