
تعارف
مشین لرننگ (ML) مطالعہ کا ایک شعبہ ہے جو ڈیٹا سے خود بخود سیکھنے کے لیے الگورتھم تیار کرنے، پیشین گوئیاں کرنے اور پیٹرن کا اندازہ لگانے پر توجہ مرکوز کرتا ہے بغیر اسے واضح طور پر بتائے کہ اسے کیسے کرنا ہے۔ اس کا مقصد ایسے سسٹم بنانا ہے جو تجربے اور ڈیٹا کے ساتھ خود بخود بہتر ہوں۔
یہ زیر نگرانی سیکھنے کے ذریعے حاصل کیا جا سکتا ہے، جہاں ماڈل کو لیبل والے ڈیٹا کا استعمال کرتے ہوئے پیشین گوئیاں کرنے کے لیے تربیت دی جاتی ہے، یا غیر زیر نگرانی سیکھنے کے ذریعے، جہاں ماڈل متوقع ہدف کے نتائج کے بغیر ڈیٹا کے اندر پیٹرن یا ارتباط کو ننگا کرنے کی کوشش کرتا ہے۔
ایم ایل کمپیوٹر سائنس، حیاتیات، مالیات، اور مارکیٹنگ سمیت مختلف شعبوں میں ایک ناگزیر اور وسیع پیمانے پر کام کرنے والے ٹول کے طور پر ابھرا ہے۔ اس نے تصویر کی درجہ بندی، قدرتی زبان کی پروسیسنگ، اور دھوکہ دہی کا پتہ لگانے جیسے متنوع ایپلی کیشنز میں اپنی افادیت کو ثابت کیا ہے۔
مشین لرننگ ٹاسکس
مشین لرننگ کو بڑے پیمانے پر تین اہم کاموں میں تقسیم کیا جا سکتا ہے:
- زیر نگرانی سیکھنا۔
- غیر نگرانی سیکھنے
- کمک سیکھنا
یہاں، ہم پہلی دو صورتوں پر توجہ مرکوز کریں گے۔
زیر نگرانی سیکھنا
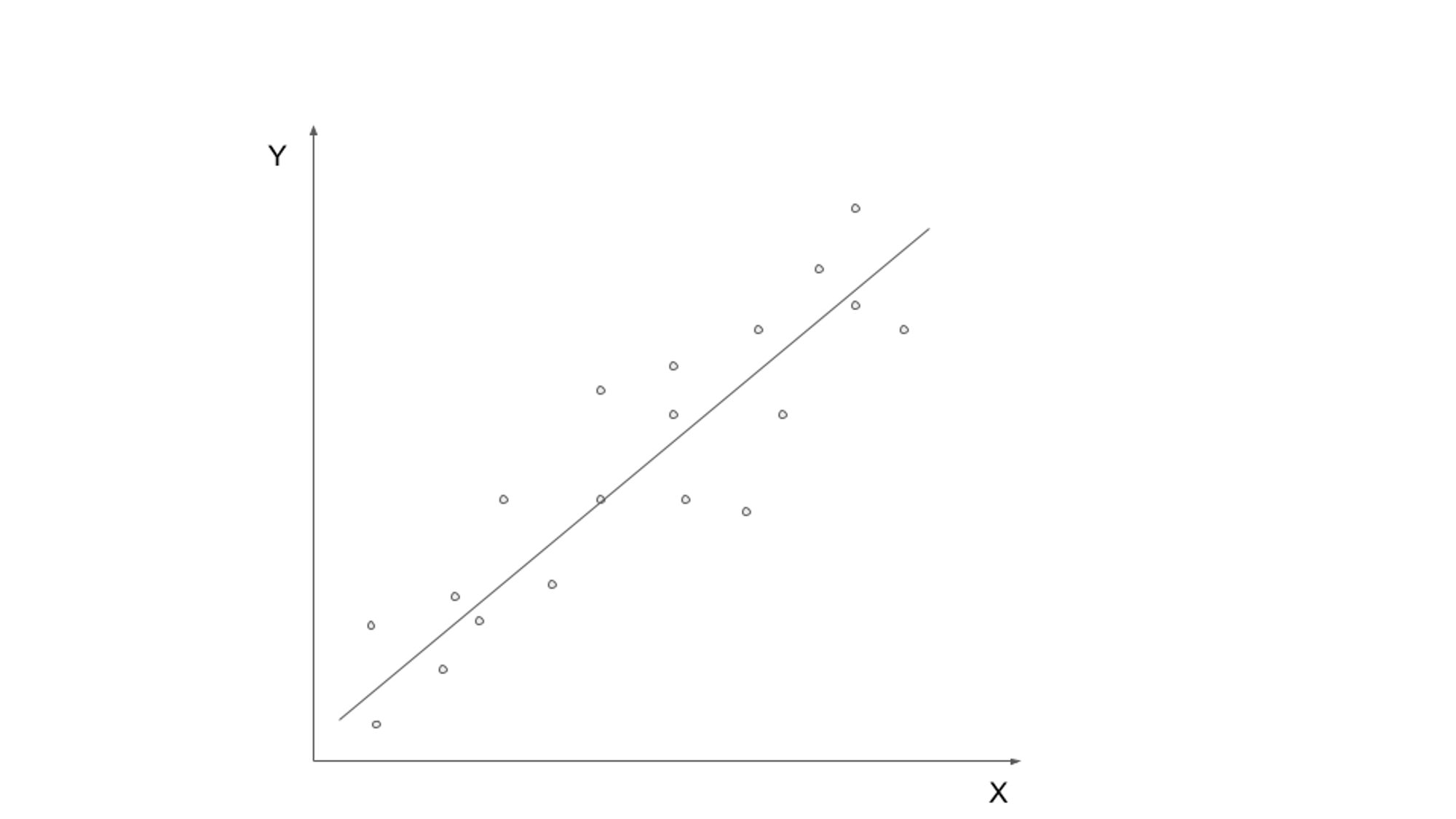
زیر نگرانی سیکھنے میں لیبل لگائے گئے ڈیٹا پر ایک ماڈل کی تربیت شامل ہوتی ہے، جہاں ان پٹ ڈیٹا کو متعلقہ آؤٹ پٹ یا ہدف متغیر کے ساتھ جوڑا جاتا ہے۔ مقصد ایک ایسا فنکشن سیکھنا ہے جو ان پٹ ڈیٹا کو درست آؤٹ پٹ پر نقشہ بنا سکے۔ عام زیر نگرانی سیکھنے کے الگورتھم میں لکیری رجعت، لاجسٹک ریگریشن، فیصلہ کے درخت، اور معاون ویکٹر مشینیں شامل ہیں۔
Python کا استعمال کرتے ہوئے زیر نگرانی لرننگ کوڈ کی مثال:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
اس سادہ کوڈ کی مثال میں، ہم تربیت دیتے ہیں۔ LinearRegression ہمارے تربیتی ڈیٹا پر scikit-learn سے الگورتھم، اور پھر ہمارے ٹیسٹ ڈیٹا کے لیے پیشین گوئیاں حاصل کرنے کے لیے اسے لاگو کریں۔
زیر نگرانی سیکھنے کا ایک حقیقی دنیا کے استعمال کا معاملہ ای میل سپیم کی درجہ بندی ہے۔ ای میل کمیونیکیشن کی تیزی سے ترقی کے ساتھ، سپیم ای میلز کی شناخت اور فلٹرنگ بہت اہم ہو گئی ہے۔ زیر نگرانی سیکھنے کے الگورتھم کو استعمال کرتے ہوئے، لیبل والے ڈیٹا کی بنیاد پر جائز ای میلز اور اسپام کے درمیان فرق کرنے کے لیے ماڈل کو تربیت دینا ممکن ہے۔
زیر نگرانی سیکھنے کے ماڈل کو ایک ڈیٹا سیٹ پر تربیت دی جا سکتی ہے جس میں ای میلز پر مشتمل "سپیم" یا "اسپام نہیں" کا لیبل لگا ہوا ہے۔ ماڈل لیبل لگائے گئے ڈیٹا سے پیٹرن اور خصوصیات سیکھتا ہے، جیسے کہ کچھ مطلوبہ الفاظ کی موجودگی، ای میل کی ساخت، یا ای میل بھیجنے والے کی معلومات۔ ماڈل کے تربیت یافتہ ہونے کے بعد، اس کا استعمال خود بخود آنے والی ای میلز کو سپیم یا غیر سپیم کے طور پر درجہ بندی کرنے کے لیے، مؤثر طریقے سے ناپسندیدہ پیغامات کو فلٹر کرنے کے لیے استعمال کیا جا سکتا ہے۔
غیر سروے شدہ سیکھنا
غیر زیر نگرانی سیکھنے میں، ان پٹ ڈیٹا کو لیبل نہیں کیا جاتا ہے، اور مقصد ڈیٹا کے اندر پیٹرن یا ڈھانچے کو دریافت کرنا ہے۔ غیر زیر نگرانی سیکھنے کے الگورتھم کا مقصد ڈیٹا میں معنی خیز نمائندگی یا کلسٹرز تلاش کرنا ہے۔
غیر زیر نگرانی سیکھنے کے الگورتھم کی مثالیں شامل ہیں۔ k کا مطلب ہے کلسٹرنگ, درجہ بندی کلسٹرنگ، اور پرنسپل جزو تجزیہ (PCA).
غیر زیر نگرانی لرننگ کوڈ کی مثال:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
اس سادہ کوڈ کی مثال میں، ہم تربیت دیتے ہیں۔ KMeans ہمارے ڈیٹا میں تین کلسٹرز کی نشاندہی کرنے اور پھر نئے ڈیٹا کو ان کلسٹرز میں فٹ کرنے کے لیے scikit-learn سے الگورتھم۔
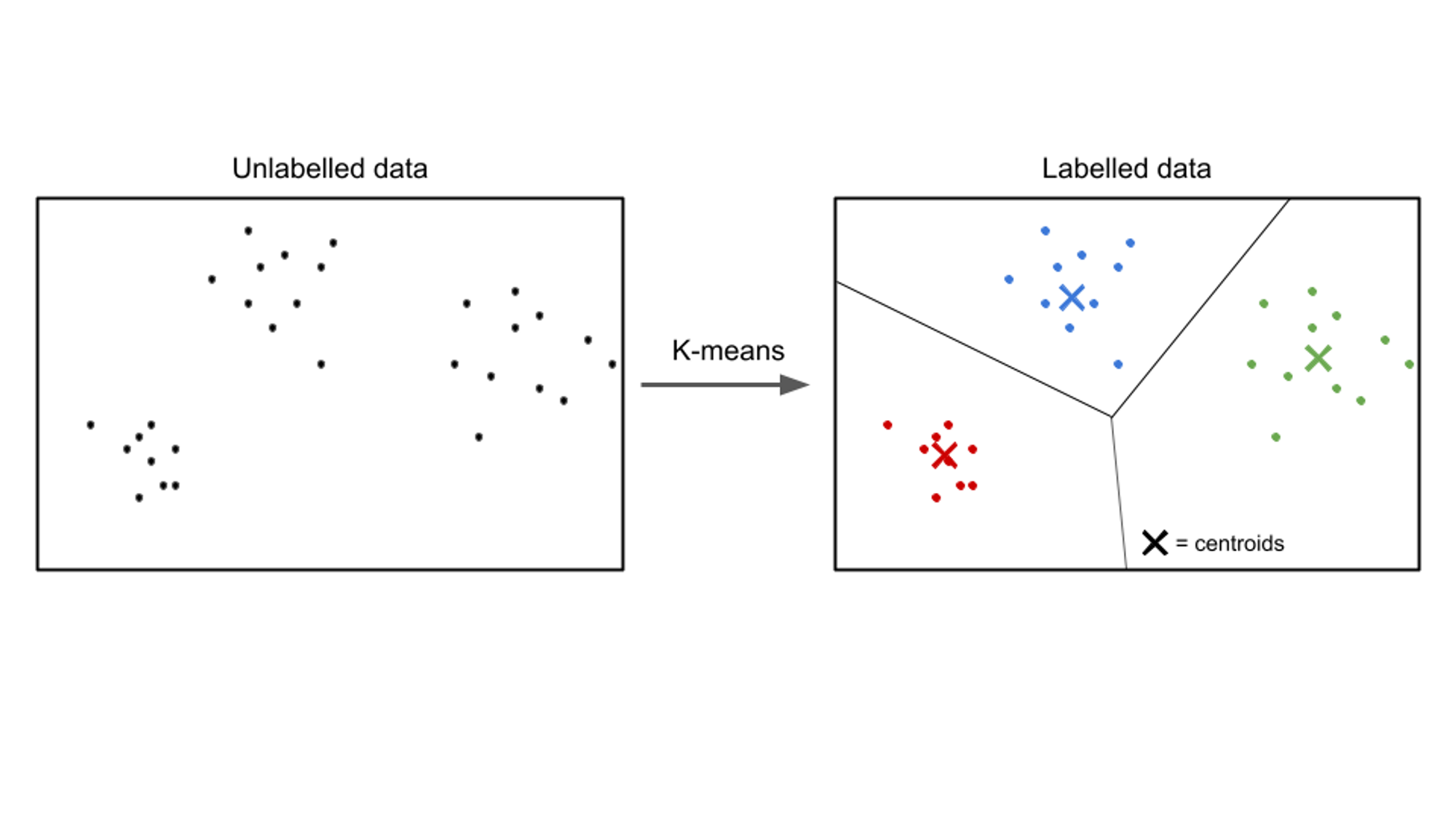
غیر زیر نگرانی سیکھنے کے استعمال کے معاملے کی ایک مثال گاہک کی تقسیم ہے۔ مختلف صنعتوں میں، کاروبار کا مقصد اپنی مارکیٹنگ کی حکمت عملیوں کو تیار کرنے، اپنی پیشکشوں کو ذاتی بنانے، اور کسٹمر کے تجربات کو بہتر بنانے کے لیے اپنے کسٹمر بیس کو بہتر طور پر سمجھنا ہے۔ غیر زیر نگرانی سیکھنے کے الگورتھم کو صارفین کو ان کی مشترکہ خصوصیات اور طرز عمل کی بنیاد پر الگ الگ گروپس میں تقسیم کرنے کے لیے استعمال کیا جا سکتا ہے۔
بہترین طرز عمل، صنعت کے لیے منظور شدہ معیارات، اور چیٹ شیٹ کے ساتھ Git سیکھنے کے لیے ہمارے ہینڈ آن، عملی گائیڈ کو دیکھیں۔ گوگلنگ گٹ کمانڈز کو روکیں اور اصل میں سیکھ یہ!
غیر زیر نگرانی سیکھنے کی تکنیکوں کو لاگو کرنے سے، جیسے کہ کلسٹرنگ، کاروبار اپنے کسٹمر ڈیٹا کے اندر بامعنی نمونوں اور گروپوں کو ننگا کر سکتے ہیں۔ مثال کے طور پر، کلسٹرنگ الگورتھم اسی طرح کی خریداری کی عادات، آبادیات، یا ترجیحات والے صارفین کے گروپوں کی شناخت کر سکتے ہیں۔ اس معلومات کو ٹارگٹڈ مارکیٹنگ کی مہمات بنانے، مصنوعات کی سفارشات کو بہتر بنانے، اور صارفین کی اطمینان کو بہتر بنانے کے لیے استعمال کیا جا سکتا ہے۔
اہم الگورتھم کلاسز
زیر نگرانی سیکھنے کے الگورتھم
-
لکیری ماڈل: خصوصیات اور ہدف متغیر کے درمیان لکیری تعلقات کی بنیاد پر مسلسل متغیرات کی پیشین گوئی کے لیے استعمال کیا جاتا ہے۔
-
درخت پر مبنی ماڈلز: پیشین گوئیاں یا درجہ بندی کرنے کے لیے بائنری فیصلوں کی ایک سیریز کا استعمال کرتے ہوئے بنائے گئے ہیں۔
-
انسمبل ماڈلز: وہ طریقہ جو زیادہ درست پیشین گوئیاں کرنے کے لیے متعدد ماڈلز (درخت پر مبنی یا لکیری) کو یکجا کرتا ہے۔
-
نیورل نیٹ ورک ماڈلز: انسانی دماغ پر ڈھیلے طریقے سے مبنی طریقے، جہاں متعدد افعال ایک نیٹ ورک کے نوڈس کے طور پر کام کرتے ہیں۔
غیر زیر نگرانی سیکھنے کے الگورتھم
-
درجہ بندی کے جھرمٹ: کلسٹروں کو تکراری طور پر ضم یا تقسیم کرکے ان کا درجہ بندی بناتا ہے۔
-
غیر درجہ بندی کلسٹرنگ: ڈیٹا کو مماثلت کی بنیاد پر الگ الگ کلسٹرز میں تقسیم کرتا ہے۔
-
جہت میں کمی: انتہائی اہم معلومات کو محفوظ رکھتے ہوئے ڈیٹا کی جہت کو کم کرتا ہے۔
ماڈل کی تشخیص
زیر نگرانی سیکھنا
زیر نگرانی سیکھنے کے ماڈلز کی کارکردگی کا جائزہ لینے کے لیے، مختلف میٹرکس کا استعمال کیا جاتا ہے، بشمول درستگی، درستگی، یاد کرنا، F1 سکور، اور ROC-AUC۔ کراس توثیق کی تکنیک، جیسے کے فولڈ کراس توثیق، ماڈل کی عمومی کارکردگی کا اندازہ لگانے میں مدد کر سکتی ہے۔
غیر سروے شدہ سیکھنا
غیر زیر نگرانی سیکھنے کے الگورتھم کا اندازہ لگانا اکثر زیادہ مشکل ہوتا ہے کیونکہ اس میں کوئی حقیقت نہیں ہے۔ کلسٹرنگ کے نتائج کے معیار کو جانچنے کے لیے میٹرکس جیسے سلہیٹ سکور یا جڑتا استعمال کیا جا سکتا ہے۔ تصور کی تکنیک کلسٹرز کی ساخت کے بارے میں بھی بصیرت فراہم کر سکتی ہے۔
ٹپس اور ٹرکس
زیر نگرانی سیکھنا
- ماڈل کی کارکردگی کو بہتر بنانے کے لیے ان پٹ ڈیٹا کو پری پروسیس اور نارملائز کریں۔
- گمشدہ اقدار کو مناسب طریقے سے ہینڈل کریں، یا تو الزام لگا کر یا ہٹا کر۔
- فیچر انجینئرنگ ماڈل کی متعلقہ نمونوں کو حاصل کرنے کی صلاحیت کو بڑھا سکتی ہے۔
غیر سروے شدہ سیکھنا
- ڈومین کے علم کی بنیاد پر یا کہنی کے طریقہ کار جیسی تکنیک کا استعمال کرتے ہوئے کلسٹرز کی مناسب تعداد کا انتخاب کریں۔
- ڈیٹا پوائنٹس کے درمیان مماثلت کی پیمائش کرنے کے لیے مختلف فاصلاتی میٹرکس پر غور کریں۔
- زیادہ فٹنگ سے بچنے کے لیے کلسٹرنگ کے عمل کو باقاعدہ بنائیں۔
خلاصہ یہ کہ مشین لرننگ میں متعدد کام، تکنیک، الگورتھم، ماڈل کی تشخیص کے طریقے، اور مددگار اشارے شامل ہیں۔ ان پہلوؤں کو سمجھ کر، پریکٹیشنرز مشین لرننگ کو حقیقی دنیا کے مسائل پر مؤثر طریقے سے لاگو کر سکتے ہیں اور ڈیٹا سے اہم بصیرت حاصل کر سکتے ہیں۔ دیے گئے کوڈ کی مثالیں زیر نگرانی اور غیر زیر نگرانی سیکھنے کے الگورتھم کے استعمال کو ظاہر کرتی ہیں، ان کے عملی نفاذ کو نمایاں کرتی ہیں۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- ای وی ایم فنانس۔ وکندریقرت مالیات کے لیے متحد انٹرفیس۔ یہاں تک رسائی حاصل کریں۔
- کوانٹم میڈیا گروپ۔ آئی آر/پی آر ایمپلیفائیڈ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 ڈیٹا انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/