
تعارف
مصنوعی ذہانت (AI) مختلف صنعتوں میں نمایاں پیش رفت کر رہی ہے، اور صحت کی دیکھ بھال بھی اس سے مستثنیٰ نہیں ہے۔ صحت کی دیکھ بھال میں AI کے اندر سب سے زیادہ امید افزا شعبوں میں سے ایک نیچرل لینگویج پروسیسنگ (NLP) ہے، جو کہ زیادہ موثر اور درست ڈیٹا تجزیہ اور مواصلات کی سہولت فراہم کرکے مریضوں کی دیکھ بھال میں انقلاب لانے کی صلاحیت رکھتا ہے۔
NLP صحت کی دیکھ بھال کے میدان میں ایک گیم چینجر ثابت ہوا ہے۔ NLP صحت کی دیکھ بھال فراہم کرنے والے مریضوں کی دیکھ بھال فراہم کرنے کے طریقے کو تبدیل کر رہا ہے۔ آبادی کی صحت کے انتظام سے لے کر بیماری کا پتہ لگانے تک، NLP صحت کی دیکھ بھال کرنے والے پیشہ ور افراد کو باخبر فیصلے کرنے اور علاج کے بہتر نتائج فراہم کرنے میں مدد کر رہا ہے۔
سیکھنے کے مقاصد
- صحت کی دیکھ بھال میں NLP اور AI کے استعمال کو سمجھنا اور تجزیہ کرنا
- NLP کی بنیادی باتوں پر گرفت حاصل کرنا
- صحت کی دیکھ بھال میں عام طور پر استعمال ہونے والی NLP لائبریریوں کے بارے میں جاننا
- صحت کی دیکھ بھال میں NLP کے استعمال کے معاملات کے بارے میں جاننا
اس مضمون کے ایک حصے کے طور پر شائع کیا گیا تھا۔ ڈیٹا سائنس بلاگتھون.
کی میز کے مندرجات
- صحت کی دیکھ بھال میں AI اور NLP کے استعمال کی ترغیب
- نیچرل لینگویج پروسیسنگ کیا ہے؟
- NLP میں استعمال ہونے والی مختلف تکنیکیں۔
3.1 اصول پر مبنی تکنیکیں۔
3.2 مشین لرننگ ماڈلز کا استعمال کرتے ہوئے شماریاتی تکنیک
3.3 ٹرانسفر لرننگ - مختلف NLP لائبریریاں اور ان کا فریم ورک
- بڑی زبان کے ماڈل (LLM) کیا ہیں؟
- کلینیکل ٹیکسٹ میں NLP - مختلف نقطہ نظر کی ضرورت
- صحت کی دیکھ بھال کی صنعت میں استعمال ہونے والی کچھ NLP لائبریریاں
- کلینیکل ڈیٹاسیٹس کو سمجھنا
- کلینیکل ڈیٹا کی مختلف اقسام کیا ہیں؟
- صحت کی دیکھ بھال کی صنعت میں NLP کے کیسز اور درخواستیں استعمال کریں۔
- کلینیکل ٹیکسٹ کے ساتھ NLP پائپ لائن کیسے بنائیں؟
11.1 حل ڈیزائن
11.2 مرحلہ وار کوڈ - نتیجہ
صحت کی دیکھ بھال میں AI اور NLP کے استعمال کی ترغیب
استعمال کرنے کی ترغیب AI اور صحت کی دیکھ بھال میں NLP کی بنیاد صحت کی دیکھ بھال کے اخراجات کو کم کرتے ہوئے مریضوں کی دیکھ بھال اور علاج کے نتائج کو بہتر بنانے میں ہے۔ صحت کی دیکھ بھال کی صنعت بڑی مقدار میں ڈیٹا تیار کرتی ہے، بشمول EMRs، طبی نوٹس، اور صحت سے متعلق سوشل میڈیا پوسٹس، جو مریض کی صحت اور علاج کے نتائج کے بارے میں قیمتی بصیرت فراہم کر سکتی ہیں۔ تاہم، اس ڈیٹا کا زیادہ تر حصہ غیر ساختہ اور دستی طور پر تجزیہ کرنا مشکل ہے۔
مزید برآں، صحت کی دیکھ بھال کی صنعت کو کئی چیلنجوں کا سامنا ہے، جیسے کہ عمر رسیدہ آبادی، دائمی بیماریوں کی بڑھتی ہوئی شرح، اور صحت کی دیکھ بھال کرنے والے پیشہ ور افراد کی کمی۔
ان چیلنجوں کی وجہ سے صحت کی دیکھ بھال کی زیادہ موثر اور موثر فراہمی کی ضرورت بڑھ رہی ہے۔
غیر ساختہ طبی اعداد و شمار سے قیمتی بصیرت فراہم کرکے، NLP مریضوں کی دیکھ بھال اور علاج کے نتائج کو بہتر بنانے میں مدد کر سکتا ہے اور زیادہ باخبر طبی فیصلے کرنے میں صحت کی دیکھ بھال کے پیشہ ور افراد کی مدد کر سکتا ہے۔
نیچرل لینگویج پروسیسنگ کیا ہے؟
نیچرل لینگویج پروسیسنگ (NLP) مصنوعی ذہانت (AI) کا ایک ذیلی فیلڈ ہے جو کمپیوٹر اور انسانی زبانوں کے درمیان تعامل سے متعلق ہے۔ یہ انسانی زبان کا تجزیہ کرنے، سمجھنے اور تخلیق کرنے کے لیے کمپیوٹیشنل تکنیک کا استعمال کرتا ہے۔ NLP بہت سے ایپلی کیشنز میں استعمال ہوتا ہے، بشمول تقریر کی شناخت، مشینی ترجمہ، جذبات کا تجزیہ، اور متن کا خلاصہ۔
اب ہم این ایل پی کی مختلف تکنیکوں، لائبریریوں اور فریم ورک کو تلاش کریں گے۔
NLP میں استعمال ہونے والی مختلف تکنیکیں۔
این ایل پی انڈسٹری میں عام طور پر استعمال ہونے والی دو تکنیکیں ہیں۔
1. اصول پر مبنی تکنیکیں: پہلے سے طے شدہ گرامر کے قواعد اور لغات پر انحصار کریں۔
2. شماریاتی تکنیک: زبان کا تجزیہ اور سمجھنے کے لیے مشین لرننگ الگورتھم کا استعمال کریں
3. استعمال کرتے ہوئے بڑی زبان کا ماڈل ٹرانسفر لرننگ
یہاں مختلف NLP کاموں کے ساتھ ایک معیاری NLP پائپ لائن ہے۔
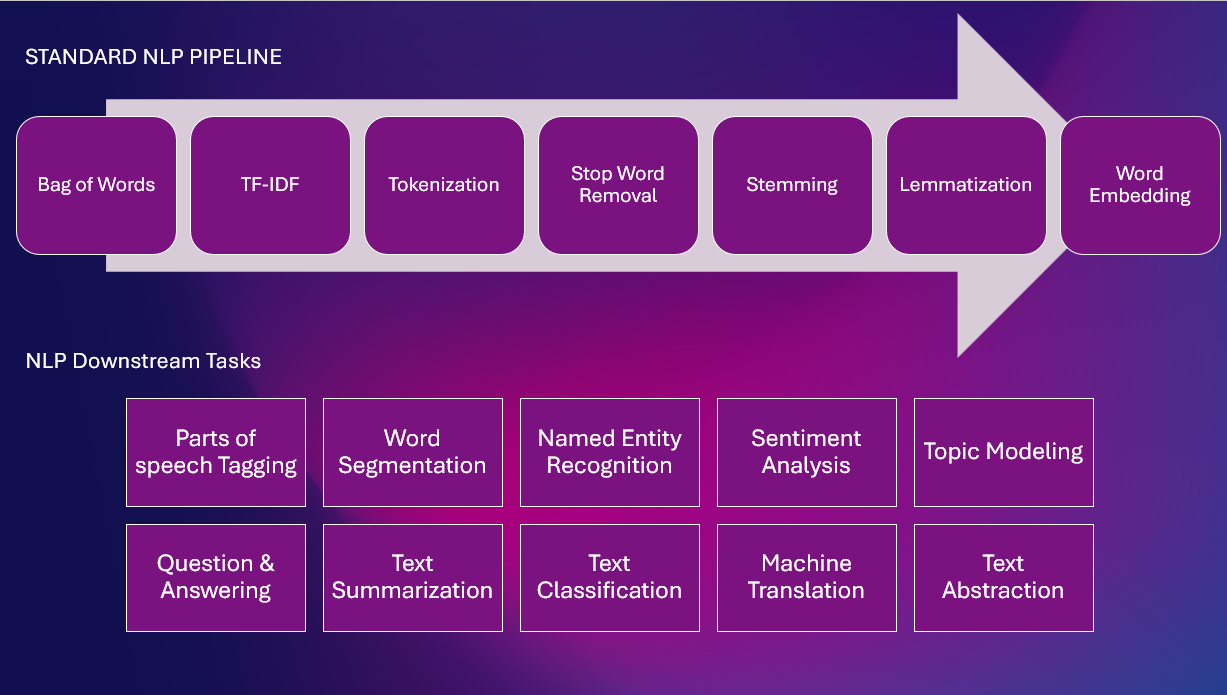
اصول پر مبنی تکنیک
ان تکنیکوں میں متن سے بامعنی معلومات نکالنے کے لیے ہاتھ سے تیار کردہ قواعد یا نمونوں کا ایک سیٹ بنانا شامل ہے۔ اصول پر مبنی نظام عام طور پر مخصوص نمونوں کی وضاحت کرکے کام کرتے ہیں جو ہدف کی معلومات سے مماثل ہوتے ہیں، جیسے کہ نام شدہ اداروں یا مخصوص مطلوبہ الفاظ، اور پھر ان نمونوں کی بنیاد پر اس معلومات کو نکالتے ہیں۔ اصول پر مبنی نظام تیز، قابل اعتماد، اور سیدھے ہیں، لیکن وہ معیار اور مقرر کردہ قواعد کی تعداد سے محدود ہیں، اور ان کو برقرار رکھنا اور اپ ڈیٹ کرنا مشکل ہو سکتا ہے۔
مثال کے طور پر، نام شدہ ہستی کی شناخت کے لیے ایک اصول پر مبنی نظام کو متن میں مناسب اسموں کی شناخت کرنے اور انہیں پہلے سے طے شدہ ہستی کی اقسام میں درجہ بندی کرنے کے لیے ڈیزائن کیا جا سکتا ہے، جیسے کہ ایک شخص، مقام، تنظیم، بیماری، منشیات وغیرہ۔ نظام ایک سیریز کا استعمال کرے گا۔ متن میں پیٹرن کی نشاندہی کرنے کے لیے قواعد جو ہر ایک ہستی کی قسم کے معیار سے مماثل ہوں، جیسے کہ افراد کے ناموں کے لیے کیپٹلائزیشن یا تنظیموں کے لیے مخصوص مطلوبہ الفاظ۔
مشین لرننگ ماڈلز کا استعمال کرتے ہوئے شماریاتی تکنیک
یہ تکنیک اعداد و شمار میں پیٹرن سیکھنے اور ان پیٹرن کی بنیاد پر پیشین گوئیاں کرنے کے لیے شماریاتی الگورتھم کا استعمال کرتی ہیں۔ مشین لرننگ ماڈلز کو بڑی مقدار میں تشریح شدہ ڈیٹا پر تربیت دی جا سکتی ہے، جس سے وہ اصول پر مبنی نظاموں کے مقابلے میں زیادہ لچکدار اور توسیع پذیر ہوتے ہیں۔ NLP میں مشین لرننگ کے کئی قسم کے ماڈلز استعمال کیے جاتے ہیں، بشمول فیصلہ درخت, بے ترتیب جنگلات, ویکٹر مشینوں کی حمایت کرتے ہیں۔، اور نیند نیٹ ورک.
مثال کے طور پر، جذباتی تجزیہ کے لیے مشین لرننگ ماڈل کو تشریح شدہ متن کے ایک بڑے کارپس پر تربیت دی جا سکتی ہے، جہاں ہر متن کو مثبت، منفی، یا غیر جانبدار کے طور پر ٹیگ کیا جاتا ہے۔ ماڈل اعداد و شمار کے اعداد و شمار کے نمونوں کو سیکھے گا جو مثبت اور منفی متن میں فرق کرتے ہیں اور پھر ان نمونوں کو نئے، غیر دیکھے ہوئے متن پر پیشین گوئیاں کرنے کے لیے استعمال کرتے ہیں۔ اس نقطہ نظر کا فائدہ یہ ہے کہ ماڈل جذباتی نمونوں کی شناخت کرنا سیکھ سکتا ہے جو قواعد میں واضح طور پر بیان نہیں کیے گئے ہیں۔
ٹرانسفر لرننگ
یہ تکنیکیں ایک ہائبرڈ نقطہ نظر ہیں جو اصول پر مبنی اور مشین لرننگ ماڈلز کی طاقتوں کو یکجا کرتی ہیں۔ ٹرانسفر لرننگ پہلے سے تربیت یافتہ مشین لرننگ ماڈل کا استعمال کرتی ہے، جیسے کہ ایک لینگویج ماڈل جو ٹیکسٹ کے بڑے کارپس پر تربیت یافتہ ہے، کسی مخصوص کام یا ڈومین کو ٹھیک کرنے کے لیے نقطہ آغاز کے طور پر۔ یہ نقطہ نظر پہلے سے تربیت یافتہ ماڈل سے سیکھے گئے عمومی علم کا فائدہ اٹھاتا ہے، تربیت کے لیے درکار لیبل والے ڈیٹا کی مقدار کو کم کرتا ہے اور کسی خاص کام پر تیز اور زیادہ درست پیشین گوئیاں کرنے کی اجازت دیتا ہے۔
مثال کے طور پر، نام شدہ ہستی کی شناخت کے لیے منتقلی سیکھنے کا طریقہ تشریح شدہ طبی متن کے چھوٹے کارپس پر پہلے سے تربیت یافتہ زبان کے ماڈل کو ٹھیک بنا سکتا ہے۔ ماڈل پہلے سے تربیت یافتہ ماڈل سے سیکھے گئے عمومی علم کے ساتھ شروع ہوگا اور پھر طبی متن کے نمونوں سے بہتر طور پر ملنے کے لیے اس کے وزن کو ایڈجسٹ کرے گا۔ یہ نقطہ نظر تربیت کے لیے درکار لیبل والے ڈیٹا کی مقدار کو کم کر دے گا اور اس کے نتیجے میں میڈیکل ڈومین میں نام کی ہستی کی شناخت کے لیے زیادہ درست ماڈل سامنے آئے گا۔
مختلف NLP لائبریریاں اور ان کا فریم ورک
مختلف لائبریریاں NLP فعالیتوں کی ایک وسیع رینج فراہم کرتی ہیں۔ جیسا کہ :

نیچرل لینگویج پروسیسنگ (NLP) لائبریریاں اور فریم ورک ایسے سافٹ ویئر ٹولز ہیں جو NLP ایپلی کیشنز کو تیار اور تعینات کرنے میں مدد کرتے ہیں۔ کئی NLP لائبریریاں اور فریم ورک دستیاب ہیں، جن میں سے ہر ایک کی طاقت، کمزوریاں، اور فوکس ایریاز ہیں۔
یہ ٹولز ان الگورتھم کی پیچیدگی کے لحاظ سے مختلف ہوتے ہیں جن کو وہ سپورٹ کرتے ہیں، ان ماڈلز کا سائز جو وہ سنبھال سکتے ہیں، استعمال میں آسانی اور کسٹمائزیشن کی ڈگری جس کی وہ اجازت دیتے ہیں۔
بڑی زبان کے ماڈل (LLM) کیا ہیں؟
بڑے زبان کے ماڈلز کو ڈیٹا کی بڑی مقدار پر تربیت دی جاتی ہے۔ انسان جیسا متن تیار کر سکتا ہے اور اعلیٰ درستگی کے ساتھ وسیع پیمانے پر NLP کام انجام دے سکتا ہے۔
یہاں بڑے زبان کے ماڈلز کی کچھ مثالیں ہیں اور ہر ایک کی مختصر وضاحت:
GPT-3 (جنریٹو پری ٹرینڈ ٹرانسفارمر 3): OpenAI کی طرف سے تیار کردہ، GPT-3 ایک بڑا ٹرانسفارمر پر مبنی لینگویج ماڈل ہے جو انسانی جیسا متن بنانے کے لیے گہری سیکھنے کے الگورتھم کا استعمال کرتا ہے۔ اسے متنی اعداد و شمار کے ایک بڑے ذخیرے پر تربیت دی گئی ہے، جس سے یہ ایک پرامپٹ کی بنیاد پر مربوط اور سیاق و سباق کے لحاظ سے مناسب متن کے جوابات پیدا کر سکتا ہے۔
برٹ (ٹرانسفارمرز سے دو طرفہ انکوڈر کی نمائندگی): گوگل کے ذریعہ تیار کردہ، BERT ایک ٹرانسفارمر پر مبنی زبان کا ماڈل ہے جسے ٹیکسٹ ڈیٹا کے ایک بڑے کارپس پر پہلے سے تربیت دی گئی ہے۔ اسے NLP کاموں کی ایک وسیع رینج پر اچھی کارکردگی کا مظاہرہ کرنے کے لیے ڈیزائن کیا گیا ہے، جیسے کہ ایک جملے میں سیاق و سباق اور الفاظ کے درمیان تعلقات کو انکوڈنگ کرکے، نام کی ہستی کی شناخت، سوال کے جوابات، اور متن کی درجہ بندی۔
روبرٹا (مضبوطی سے آپٹمائزڈ BERT اپروچ): Facebook AI کی طرف سے تیار کردہ، RoBERTa BERT کا ایک قسم ہے جسے NLP کاموں کے لیے ٹھیک بنایا گیا ہے اور بہتر بنایا گیا ہے۔ اسے ٹیکسٹ ڈیٹا کے ایک بڑے کارپس پر تربیت دی گئی ہے اور یہ BERT سے مختلف تربیتی حکمت عملی استعمال کرتی ہے، جس کی وجہ سے NLP بینچ مارکس پر کارکردگی بہتر ہوتی ہے۔
ELMO (زبان کے ماڈلز سے ایمبیڈنگز): ایلن انسٹی ٹیوٹ برائے AI کی طرف سے تیار کردہ، ELMo ایک گہرا سیاق و سباق سے متعلق الفاظ کی نمائندگی کا ماڈل ہے جو متن کے اعداد و شمار کے ایک بڑے کارپس سے زبان کی نمائندگی سیکھنے کے لیے دو طرفہ LSTM (طویل مختصر مدتی میموری) نیٹ ورک کا استعمال کرتا ہے۔ ELMo کو مخصوص NLP کاموں کے لیے ٹھیک بنایا جا سکتا ہے یا دوسرے مشین لرننگ ماڈلز کے لیے فیچر ایکسٹریکٹر کے طور پر استعمال کیا جا سکتا ہے۔
ULMFiT (یونیورسل لینگویج ماڈل فائن ٹیوننگ): FastAI کی طرف سے تیار کردہ، ULMFiT ایک منتقلی سیکھنے کا طریقہ ہے جو مخصوص این ایل پی ٹاسک پر پہلے سے تربیت یافتہ لینگویج ماڈل کو ٹاسک کے لیے مخصوص تشریح شدہ ڈیٹا کی تھوڑی مقدار کا استعمال کرتے ہوئے ٹھیک کرتا ہے۔ ULMFiT نے NLP بینچ مارکس کی ایک وسیع رینج پر جدید ترین کارکردگی حاصل کی ہے اور اسے NLP میں ٹرانسفر لرننگ کی ایک اہم مثال سمجھا جاتا ہے۔
کلینیکل ٹیکسٹ میں NLP: مختلف نقطہ نظر کی ضرورت
کلینیکل متن اکثر غیر ساختہ ہوتا ہے اور اس میں بہت سارے طبی الفاظ اور مخففات ہوتے ہیں، جس سے روایتی NLP ماڈلز کو سمجھنا اور اس پر کارروائی کرنا مشکل ہو جاتا ہے۔ مزید برآں، طبی متن میں اکثر اہم معلومات شامل ہوتی ہیں جیسے کہ بیماری، ادویات، مریض کی معلومات، تشخیص، اور علاج کے منصوبے، جن کے لیے مخصوص NLP ماڈلز کی ضرورت ہوتی ہے جو اس طبی معلومات کو درست طریقے سے نکال سکیں اور سمجھ سکیں۔
کلینیکل ٹیکسٹ کو مختلف NLP ماڈلز کی ضرورت کی ایک اور وجہ یہ ہے کہ اس میں مختلف ذرائع، جیسے EHRs، کلینیکل نوٹس، اور ریڈیولوجی رپورٹس میں پھیلے ہوئے ڈیٹا کی ایک بڑی مقدار ہے، جس کو مربوط کرنے کی ضرورت ہے۔ اس کے لیے ایسے ماڈلز کی ضرورت ہے جو متن اور لنک کو پروسیس کر سکیں اور سمجھ سکیں اور ڈیٹا کو مختلف ذرائع میں مربوط کر سکیں اور طبی اعتبار سے قابل قبول تعلقات قائم کر سکیں۔
آخر میں، طبی متن اکثر حساس مریض کی معلومات پر مشتمل ہوتا ہے اور اسے HIPAA جیسے سخت ضوابط سے محفوظ رکھنے کی ضرورت ہوتی ہے۔ کلینیکل ٹیکسٹ کو پروسیس کرنے کے لیے استعمال ہونے والے NLP ماڈلز کو ضروری بصیرت فراہم کرتے ہوئے حساس مریض کی معلومات کی شناخت اور حفاظت کرنے کے قابل ہونا چاہیے۔
صحت کی دیکھ بھال کی صنعت میں استعمال ہونے والی کچھ NLP لائبریریاں
طب کے اندر متنی اعداد و شمار کے لیے ایک مخصوص نیچرل لینگویج پروسیسنگ (NLP) سسٹم کی ضرورت ہوتی ہے جو مختلف ذرائع سے طبی معلومات نکالنے کے قابل ہو جیسے طبی متن اور دیگر طبی دستاویزات۔
یہاں NLP لائبریریوں اور میڈیکل ڈومین کے لیے مخصوص ماڈلز کی فہرست ہے:
spaCy: یہ ایک اوپن سورس NLP لائبریری ہے جو میڈیکل ڈومین سمیت مختلف ڈومینز کے لیے آؤٹ آف دی باکس ماڈل فراہم کرتی ہے۔
Scispacy: spaCy کا ایک خصوصی ورژن جو خاص طور پر سائنسی اور بایومیڈیکل ٹیکسٹ پر تربیت یافتہ ہے، جو اسے طبی متن کی پروسیسنگ کے لیے مثالی بناتا ہے۔
BioBERT: ایک پہلے سے تربیت یافتہ ٹرانسفارمر پر مبنی ماڈل خاص طور پر بائیو میڈیکل ڈومین کے لیے ڈیزائن کیا گیا ہے۔ یہ Wiki + Books + PubMed + PMC کے ساتھ پہلے سے تربیت یافتہ ہے۔
ClinicalBERT: MIMIC-III ڈیٹا بیس سے کلینیکل نوٹس اور ڈسچارج سمریوں پر کارروائی کرنے کے لیے ڈیزائن کیا گیا ایک اور پہلے سے تربیت یافتہ ماڈل۔
میڈ7: ایک ٹرانسفارمر پر مبنی ماڈل جسے الیکٹرانک ہیلتھ ریکارڈز (EHR) پر تربیت دی گئی تھی تاکہ تشخیص، ادویات، اور لیبارٹری ٹیسٹ سمیت سات کلیدی طبی تصورات کو نکالا جا سکے۔
DisMod-ML: بیماری کی ماڈلنگ کے لیے ایک امکانی ماڈلنگ فریم ورک جو طبی متن پر کارروائی کرنے کے لیے NLP تکنیک کا استعمال کرتا ہے۔
طبی: متن سے طبی معلومات نکالنے کے لیے ایک اصول پر مبنی NLP نظام۔
یہ کچھ مشہور NLP لائبریریاں اور ماڈلز ہیں جو خاص طور پر میڈیکل ڈومین کے لیے بنائے گئے ہیں۔ وہ پہلے سے تربیت یافتہ ماڈلز سے لے کر اصول پر مبنی نظام تک بہت سی خصوصیات پیش کرتے ہیں، اور صحت کی دیکھ بھال کرنے والی تنظیموں کو طبی متن کو مؤثر طریقے سے پروسیس کرنے میں مدد کر سکتے ہیں۔
ہمارے NER ماڈل میں، ہم spaCy اور Scispacy استعمال کریں گے۔ یہ لائبریریاں گوگل کولاب یا مقامی انفراسٹرکچر پر چلانے کے لیے نسبتاً آسان ہیں۔
BioBERT اور ClinicalBERT وسائل پر مشتمل بڑے زبان کے ماڈلز کو GPUs اور اعلیٰ بنیادی ڈھانچے کی ضرورت ہے۔
کلینیکل ڈیٹاسیٹس کو سمجھنا
طبی متن کا ڈیٹا مختلف ذرائع سے حاصل کیا جا سکتا ہے، جیسے کہ الیکٹرانک ہیلتھ ریکارڈز (EHRs)، طبی جریدے، کلینیکل نوٹس، طبی ویب سائٹس، اور ڈیٹا بیس۔ ان میں سے کچھ ذرائع عوامی طور پر دستیاب ڈیٹا سیٹس فراہم کرتے ہیں جنہیں NLP ماڈلز کی تربیت کے لیے استعمال کیا جا سکتا ہے، جبکہ دیگر کو ڈیٹا تک رسائی سے پہلے منظوری اور اخلاقی تحفظات کی ضرورت پڑ سکتی ہے۔ میڈیکل ٹیکسٹ ڈیٹا کے ذرائع میں شامل ہیں:
1. اوپن سورس میڈیکل کارپورا جیسے MIMIC-III ڈیٹا بیس 2001 اور 2012 کے درمیان بیت اسرائیل ڈیکونس میڈیکل سینٹر میں دیکھ بھال حاصل کرنے والے مریضوں کا ایک بڑا، کھلے عام قابل رسائی الیکٹرانک ہیلتھ ریکارڈز (EHRs) ڈیٹا بیس ہے۔ صحت کی دیکھ بھال کرنے والے پیشہ ور افراد، جیسے نرسوں اور معالجین کے نوٹس۔ مزید برآں، ڈیٹا بیس میں مریضوں کے ICU قیام کے بارے میں معلومات شامل ہیں، بشمول ICU کی قسم، قیام کی لمبائی، اور نتائج۔ MIMIC-III میں موجود ڈیٹا کی شناخت نہیں کی گئی ہے اور اسے تحقیقی مقاصد کے لیے استعمال کیا جا سکتا ہے تاکہ پیش گوئی کرنے والے ماڈلز اور طبی فیصلے کے معاون نظام کی ترقی میں مدد کی جا سکے۔
2. نیشنل لائبریری آف میڈیسن کلینیکل ٹرریالس ویب سائٹ پر کلینیکل ٹرائل ڈیٹا اور بیماری کی نگرانی کا ڈیٹا موجود ہے۔
3. نیشنل انسٹی ٹیوٹ آف ہیلتھ کی نیشنل لائبریری آف میڈیسن، نیشنل سینٹرز فار بائیو ٹیکنالوجی انفارمیشن (NCBIاور ورلڈ ہیلتھ آرگنائزیشن (ڈبلیو)
4. صحت کی دیکھ بھال کے ادارے اور تنظیمیں جیسے ہسپتال، کلینک، اور فارماسیوٹیکل کمپنیاں الیکٹرانک ہیلتھ ریکارڈز، کلینیکل نوٹس، میڈیکل ٹرانسکرپشن، اور میڈیکل رپورٹس کے ذریعے بڑی مقدار میں میڈیکل ٹیکسٹ ڈیٹا تیار کرتی ہیں۔
5. طبی تحقیقی جرائد اور ڈیٹا بیس، جیسے PubMed اور CINAHL، شائع شدہ طبی تحقیقی مضامین اور خلاصوں کی وسیع مقدار پر مشتمل ہیں۔
6. ٹویٹر جیسے سوشل میڈیا پلیٹ فارمز مریض کے نقطہ نظر، منشیات کے جائزے، اور تجربات میں حقیقی وقت کی بصیرت فراہم کر سکتے ہیں۔
میڈیکل ٹیکسٹ ڈیٹا کا استعمال کرتے ہوئے NLP ماڈلز کو تربیت دینے کے لیے، یہ ضروری ہے کہ ڈیٹا کے معیار اور مطابقت پر غور کیا جائے اور اس بات کو یقینی بنایا جائے کہ یہ مناسب طریقے سے پہلے سے پروسیس اور فارمیٹ کیا گیا ہے۔ مزید برآں، حساس طبی معلومات کے ساتھ کام کرتے وقت اخلاقی اور قانونی تحفظات پر عمل کرنا ضروری ہے۔
کلینیکل ڈیٹا کی مختلف اقسام کیا ہیں؟
کئی قسم کے طبی ڈیٹا عام طور پر صحت کی دیکھ بھال میں استعمال ہوتے ہیں:

کلینیکل ڈیٹا سے مراد افراد کی صحت کی دیکھ بھال کے بارے میں معلومات ہیں، بشمول مریض کی طبی تاریخ، تشخیص، علاج، لیبارٹری کے نتائج، امیجنگ اسٹڈیز، اور دیگر متعلقہ صحت کی معلومات۔
EHR/EMR ڈیٹا ڈیموگرافک ڈیٹا سے منسلک ہیں (اس میں ذاتی معلومات جیسے عمر، جنس، نسل، اور رابطے کی معلومات شامل ہیں۔)، مریض کا تیار کردہ ڈیٹا (اس قسم کا ڈیٹا مریض خود تیار کرتا ہے، بشمول مریض کی رپورٹ کردہ نتائج کے اقدامات اور مریض کے ذریعے جمع کی گئی معلومات۔ صحت کا ڈیٹا تیار کیا گیا ہے۔)
ڈیٹا کے دوسرے سیٹ ہیں:
جینومک ڈیٹا: اس قسم کا تعلق کسی فرد کی جینیاتی معلومات سے ہے، بشمول ڈی این اے کی ترتیب اور مارکر۔
پہننے کے قابل ڈیوائس کا ڈیٹا: اس ڈیٹا میں پہننے کے قابل آلات جیسے فٹنس ٹریکرز اور ہارٹ مانیٹر سے جمع کی گئی معلومات شامل ہیں۔
ہر قسم کا طبی ڈیٹا مریض کی صحت کا ایک جامع نظریہ فراہم کرنے میں منفرد کردار ادا کرتا ہے اور اسے صحت کی دیکھ بھال فراہم کرنے والے اور محققین مریض کی دیکھ بھال کو بہتر بنانے اور علاج کے فیصلوں سے آگاہ کرنے کے لیے مختلف طریقوں سے استعمال کرتے ہیں۔
صحت کی دیکھ بھال کی صنعت میں NLP کے کیسز اور درخواستیں استعمال کریں۔
قدرتی زبان کی پروسیسنگ (NLP) کو صحت کی دیکھ بھال کی صنعت میں بڑے پیمانے پر اپنایا گیا ہے اور اس کے استعمال کے کئی معاملات ہیں۔ ان میں سے کچھ نمایاں ہیں:
آبادی صحت: NLP کا استعمال غیر ساختہ طبی ڈیٹا کی بڑی مقدار پر کارروائی کرنے کے لیے کیا جا سکتا ہے جیسے کہ طبی ریکارڈ، سروے، اور دعوؤں کے ڈیٹا کو پیٹرن، ارتباط اور بصیرت کی شناخت کے لیے۔ اس سے آبادی کی صحت کی نگرانی اور بیماریوں کا جلد پتہ لگانے میں مدد ملتی ہے۔
مریض نگہداشت: NLP کا استعمال مریضوں کے الیکٹرانک ہیلتھ ریکارڈز (EHRs) پر کارروائی کرنے کے لیے کیا جا سکتا ہے تاکہ اہم معلومات جیسے کہ تشخیص، ادویات اور علامات کو نکالا جا سکے۔ یہ معلومات مریض کی دیکھ بھال کو بہتر بنانے اور ذاتی نوعیت کا علاج فراہم کرنے کے لیے استعمال کی جا سکتی ہیں۔
بیماری کا پتہ لگانا: این ایل پی کو متعدی بیماریوں کے پھیلنے کا پتہ لگانے کے لیے بڑے پیمانے پر ٹیکسٹ ڈیٹا، جیسے سائنسی مضامین، خبروں کے مضامین، اور سوشل میڈیا پوسٹس پر کارروائی کے لیے استعمال کیا جا سکتا ہے۔
کلینیکل ڈیسیژن سپورٹ سسٹم (CDSS): NLP کا استعمال صحت کی دیکھ بھال فراہم کرنے والوں کو حقیقی وقت میں فیصلے کی مدد فراہم کرنے کے لیے مریضوں کے الیکٹرانک ہیلتھ ریکارڈ کا تجزیہ کرنے کے لیے کیا جا سکتا ہے۔ یہ علاج کے بہترین ممکنہ اختیارات فراہم کرنے اور دیکھ بھال کے مجموعی معیار کو بہتر بنانے میں مدد کرتا ہے۔
طبی آزمائش: NLP ارتباط اور ممکنہ نئے علاج کی شناخت کے لیے کلینیکل ٹرائل ڈیٹا پر کارروائی کر سکتا ہے۔
منشیات کے منفی واقعات: NLP کا استعمال منشیات کے حفاظتی ڈیٹا کی بڑی مقدار پر کارروائی کرنے کے لیے کیا جا سکتا ہے تاکہ منفی واقعات اور منشیات کے تعاملات کی نشاندہی کی جا سکے۔
صحت سے متعلق صحت: NLP کا استعمال جینومک ڈیٹا اور میڈیکل ریکارڈ پر کارروائی کرنے کے لیے کیا جا سکتا ہے تاکہ انفرادی مریضوں کے لیے ذاتی نوعیت کے علاج کے اختیارات کی شناخت کی جا سکے۔
میڈیکل پروفیشنل کی کارکردگی میں بہتری: NLP معمول کے کاموں کو خودکار کر سکتا ہے جیسے کہ میڈیکل کوڈنگ، ڈیٹا انٹری، اور کلیم پروسیسنگ، طبی پیشہ ور افراد کو مریضوں کی بہتر دیکھ بھال فراہم کرنے پر توجہ دینے کے لیے آزاد کر سکتا ہے۔
یہ صرف چند مثالیں ہیں کہ کس طرح NLP صحت کی دیکھ بھال کی صنعت میں انقلاب برپا کرتی ہے۔ جیسا کہ NLP ٹیکنالوجی آگے بڑھ رہی ہے، ہم مستقبل میں صحت کی دیکھ بھال میں NLP کے مزید اختراعی استعمال دیکھنے کی توقع کر سکتے ہیں۔
کلینیکل ٹیکسٹ کے ساتھ NLP پائپ لائن کیسے بنائیں؟
ہم کلینیکل ٹیکسٹ کے لیے SciSpacy NER ماڈل کا استعمال کرتے ہوئے قدم بہ قدم Spacy پائپ لائن تیار کریں گے۔
مقصد: اس پروجیکٹ کا مقصد ایک NLP پائپ لائن تعمیر کرنا ہے جس میں SciSpacy کا استعمال کرتے ہوئے طبی متن پر اپنی مرضی کے مطابق نام کی ہستی کی شناخت انجام دی جائے۔
نتائج: نتیجہ طبی متن سے بیماریوں، ادویات، اور دوائیوں کی خوراک کے بارے میں معلومات حاصل کرے گا، جس کے بعد مختلف NLP ڈاؤن اسٹریم ایپلی کیشنز میں استعمال کیا جا سکتا ہے۔
حل ڈیزائن:
یہاں کلینکل ٹیکسٹ سے ہستی کی معلومات نکالنے کا اعلیٰ سطحی حل ہے۔ NER نکالنا ایک اہم NLP کام ہے جو زیادہ تر NLP پائپ لائنوں میں استعمال ہوتا ہے۔
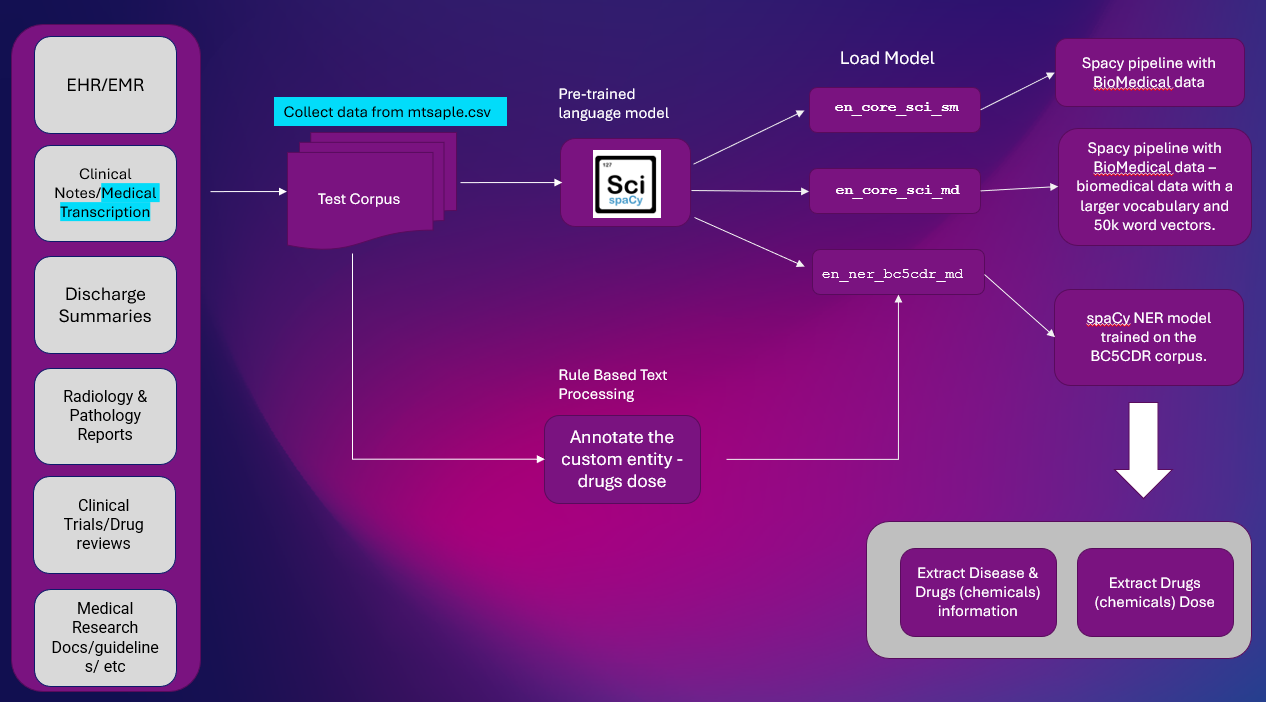
: پلیٹ فارم گوگل کولاب۔
NLP لائبریریاں: spaCy اور SciSpacy
ڈیٹا سیٹ: mtsample.csv (mtsample سے ڈیٹا کو ختم کیا گیا)۔
ہم نے استعمال کیا ہے سکسپاسی پہلے سے تربیت یافتہ NER ماڈل en_ner_bc5cdr_md-0.5.1 بیماری اور ادویات نکالنے کے لیے۔ منشیات کو کیمیکل کے طور پر نکالا جاتا ہے۔
en_ner_bc5cdr_md-0.5.1 بائیو میڈیکل ڈومین میں نامزد ہستی کی شناخت (NER) کے لیے ایک spaCy ماڈل ہے۔
"bc5cdr" سے مراد ہے۔ BC5CDR کارپس، ایک بائیو میڈیکل ٹیکسٹ کارپس جو ماڈل کی تربیت کے لیے استعمال ہوتا ہے۔ نام میں "md" سے مراد بائیو میڈیکل ڈومین ہے۔ نام میں "0.5.1" ماڈل کے ورژن سے مراد ہے۔
ہم mtsample.csv سے نمونہ "ٹرانسکرپشن" کا متن استعمال کریں گے اور منشیات کی خوراک نکالنے کے لیے اصول پر مبنی پیٹرن کا استعمال کرتے ہوئے تشریح کریں گے۔
مرحلہ وار کوڈ:
اسپیسی اور اسپیسی پیکجز انسٹال کریں۔ spaCy ماڈل مخصوص NLP کاموں کو انجام دینے کے لیے بنائے گئے ہیں، جیسے کہ ٹوکنائزیشن، پارٹ آف اسپیچ ٹیگنگ، اور نام شدہ ہستی کی شناخت۔
!pip install -U spacy !pip install scispacy
سکیسپیسی بیس ماڈلز اور NER ماڈلز انسٹال کریں۔
en_ner_bc5cdr_md-0.5.1 ماڈل کو خاص طور پر بائیو میڈیکل ٹیکسٹ میں نامی ہستیوں کو پہچاننے کے لیے ڈیزائن کیا گیا ہے، جیسے کہ بیماریوں، جینز، اور ادویات، بطور کیمیکل۔
یہ ماڈل بایومیڈیکل ڈومین میں NLP کاموں کے لیے کارآمد ثابت ہو سکتا ہے، جیسے معلومات نکالنا، متن کی درجہ بندی، اور سوال جواب۔
!pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_sm-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_md-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_ner_bc5cdr_md-0.5.1.tar.gz
دوسرے پیکجز انسٹال کریں۔
pip انسٹال رینڈر
پیکجز درآمد کریں۔
امپورٹ سکیسپیسی امپورٹ سپیسی # کور ماڈل درآمد کریں en_core_sci_sm درآمد کریں en_core_sci_md
#NER کے مخصوص ماڈل en_ner_bc5cdr_md درآمد کرتے ہیں #سپاسی امپورٹ ڈسپلیسی امپورٹ پانڈوں سے ڈیٹا نکالنے اور ڈسپلے کرنے کے ٹولز بطور pd
ازگر کوڈ:
نمونے کے اعداد و شمار کے ساتھ ماڈلز کی جانچ کریں۔
# استعمال کرنے کے لیے مخصوص ٹرانسکرپشن کا انتخاب کریں (قطار 3، کالم "ٹرانسکرپشن") اور اسکیسپیسی NER ماڈل ٹیکسٹ = mtsample_df.loc[10, "ٹرانسکرپشن"] کی جانچ کریں۔

مخصوص ماڈل لوڈ کریں: en_core_sci_sm اور متن کو پاس کریں۔
nlp_sm = en_core_sci_sm.load() doc = nlp_sm (متن)
#نتیجے میں ڈسپلے کریں۔
ہستی نکالنا displacy_image = displacy.render(doc, jupyter=True,style='ent')

نوٹ کریں کہ ہستی کو یہاں ٹیگ کیا گیا ہے۔ زیادہ تر طبی اصطلاحات۔ تاہم، یہ عام ہستی ہیں۔
اب مخصوص ماڈل لوڈ کریں: en_core_sci_md اور متن کو پاس کریں۔
nlp_md = en_core_sci_md.load() doc = nlp_md (متن)
# ڈسپلے کے نتیجے میں ہستی نکالنا
displacy_image = displacy.render(doc, jupyter=True,style='ent')

اس بار نمبروں کو بھی en_core_sci_md کے ذریعہ اداروں کے طور پر ٹیگ کیا گیا ہے۔
اب مخصوص ماڈل لوڈ کریں: en_ner_bc5cdr_md درآمد کریں اور متن کو پاس کریں۔
nlp_bc = en_ner_bc5cdr_md.load() doc = nlp_bc(text) # ڈسپلے کے نتیجے میں ہستی نکالنا displacy_image = displacy.render(doc, jupyter=True,style='ent')

اب دو طبی اداروں کو ٹیگ کیا گیا ہے: بیماری اور کیمیائی (منشیات)۔
ہستی کو ظاہر کریں۔
پرنٹ کریں
ٹیکسٹ اسٹارٹ اینڈ ENTITY TYPE
موربڈ موٹاپا 26 40 بیماری
موربڈ موٹاپا 70 84 بیماری
وزن میں کمی 400 411 بیماری
مارکین 1256 1264 کیمیکل
NAN کی قدروں کو چھوڑنے اور حسب ضرورت ہستی کے ماڈل کے لیے ایک بے ترتیب چھوٹا نمونہ بنانے کے لیے کلینیکل ٹیکسٹ پر کارروائی کریں۔
mtsample_df.dropna(subset=['transcription'], inplace=True) mtsample_df_subset = mtsample_df.sample(n=100, replace=False, random_state=42) mtsample_df_subset.info() mtsample_df_subset.info() mtsample_df.
spaCy میچر - اصول پر مبنی مماثلت ریگولر ایکسپریشنز کے استعمال سے مشابہت رکھتی ہے، لیکن spaCy اضافی صلاحیتیں فراہم کرتی ہے۔ کسی دستاویز کے اندر ٹوکنز اور رشتوں کا استعمال آپ کو ان نمونوں کی شناخت کرنے کے قابل بناتا ہے جن میں NER ماڈلز کی مدد سے ہستیوں کو شامل کیا جاتا ہے۔ مقصد متن سے منشیات کے ناموں اور ان کی خوراکوں کا پتہ لگانا ہے، جو دواؤں کی غلطیوں کو معیارات اور رہنما خطوط کے ساتھ موازنہ کر کے ان کا پتہ لگانے میں مدد کر سکتا ہے۔
مقصد متن سے منشیات کے ناموں اور ان کی خوراکوں کا پتہ لگانا ہے، جو دواؤں کی غلطیوں کو معیارات اور رہنما خطوط کے ساتھ موازنہ کر کے ان کا پتہ لگانے میں مدد کر سکتا ہے۔
Spacy.matcher سے میچر درآمد کریں۔
پیٹرن = [{'ENT_TYPE':'CHEMICAL'}، {'LIKE_NUM': True}, {'IS_ASCII': True}] matcher = matcher(nlp_bc.vocab) matcher.add("DRUG_DOSE", [pattern])
mtsample_df_subset['transcription'] میں ٹرانسکرپشن کے لیے: doc = nlp_bc(ٹرانسکرپشن) میچز = میچر(دستاویز) match_id کے لیے، شروع، میچوں میں اختتام: string_id = nlp_bc.vocab.strings[match_id] # حاصل کریں سٹرنگ کی نمائندگی آرٹ span = docst :end] # مماثل اسپین جو دوائیوں کی خوراک شامل کرتا ہے پرنٹ (span.text, start, end, string_id,) #Doc.ents میں ent کے لیے بیماری اور دوائیں شامل کریں: print(ent.text, ent.start_char, ent.end_char, ent .label_)
آؤٹ پٹ کلینیکل ٹیکسٹ کے نمونے سے نکالے گئے اداروں کو ظاہر کرے گا۔
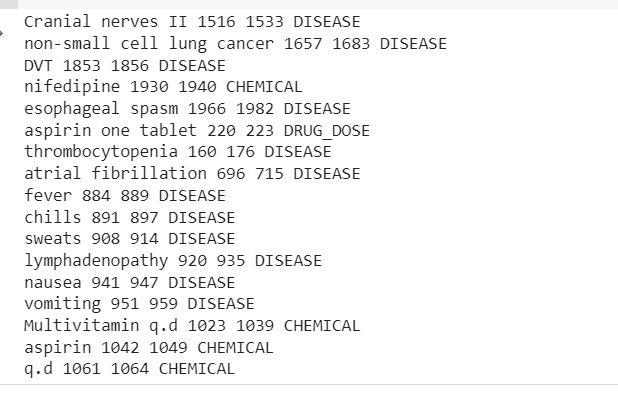
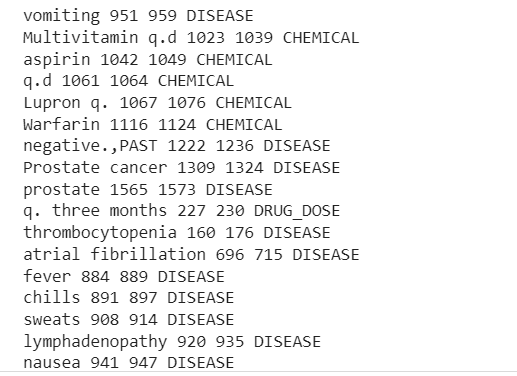
اب ہم پائپ لائن نکالی ہوئی دیکھ سکتے ہیں۔ بیماری، منشیات (کیمیکل)، اور منشیات کی خوراک طبی متن سے معلومات۔
کچھ غلط درجہ بندی ہے، لیکن ہم مزید ڈیٹا کا استعمال کرتے ہوئے ماڈل کی کارکردگی کو بڑھا سکتے ہیں۔
اب ہم ان طبی اداروں کو مختلف کاموں میں استعمال کر سکتے ہیں جیسے کہ بیماری کا پتہ لگانا، پیشین گوئی کا تجزیہ، طبی فیصلہ کی معاونت کا نظام، طبی متن کی درجہ بندی، خلاصہ، سوالات کے جوابات، اور بہت کچھ۔
نتیجہ
1. اس مضمون میں، ہم نے ہیلتھ کیئر میں NLP کی کچھ اہم خصوصیات کی کھوج کی ہے، جو صحت کی دیکھ بھال کے پیچیدہ متن کے ڈیٹا کو سمجھنے میں مدد کرے گی۔
ہم نے scispaCy اور spaCy کو بھی لاگو کیا اور پہلے سے تربیت یافتہ NER ماڈل اور اصول پر مبنی میچر کے ذریعے ایک سادہ حسب ضرورت NER ماڈل بنایا۔ جب کہ ہم نے صرف ایک NER ماڈل کا احاطہ کیا ہے، بہت سے دوسرے دستیاب ہیں، اور دریافت کرنے کے لیے اضافی فعالیت کی ایک وسیع مقدار۔
2. scispaCy فریم ورک کے اندر، تلاش کرنے کے لیے متعدد اضافی تکنیکیں موجود ہیں، جن میں مخففات کا پتہ لگانے، انحصار پارس کرنے، اور انفرادی جملوں کی شناخت کے طریقے شامل ہیں۔
3. صحت کی دیکھ بھال کے لیے NLP کے تازہ ترین رجحانات میں ڈومین کے لیے مخصوص ماڈلز جیسے BioBERT اور ClinicalBert کی ترقی اور GPT-3 جیسے بڑے زبان کے ماڈلز کا استعمال شامل ہے۔ یہ ماڈل اعلیٰ سطح کی درستگی اور کارکردگی پیش کرتے ہیں، لیکن ان کے استعمال سے تعصب، رازداری اور ڈیٹا پر کنٹرول کے بارے میں بھی خدشات پیدا ہوتے ہیں۔
چیٹ جی پی ٹی (اوپن اے آئی کے ذریعہ تیار کردہ ایک اعلی درجے کی بات چیت کا اے آئی ماڈل) پہلے ہی NLP دنیا میں بہت بڑا اثر ڈال رہا ہے۔ ماڈل کو انٹرنیٹ سے ٹیکسٹ ڈیٹا کی ایک بڑی مقدار پر تربیت دی جاتی ہے اور اس میں یہ صلاحیت ہوتی ہے کہ وہ اسے موصول ہونے والے ان پٹ کی بنیاد پر انسانوں کی طرح ٹیکسٹ جوابات دے سکے۔ اسے مختلف کاموں کے لیے استعمال کیا جا سکتا ہے جیسے سوال کے جوابات، خلاصہ، ترجمہ وغیرہ۔ ماڈل کو مخصوص استعمال کے معاملات کے لیے بھی ٹھیک بنایا گیا ہے، جیسے کہ کوڈ بنانا یا مضامین لکھنا، ان مخصوص علاقوں میں اپنی کارکردگی کو بڑھانے کے لیے۔
5. تاہم، اپنے بے شمار فوائد کے باوجود، صحت کی دیکھ بھال میں NLP اپنے چیلنجوں کے بغیر نہیں ہے۔ NLP ماڈلز کی درستگی اور انصاف پسندی کو یقینی بنانا اور ڈیٹا پرائیویسی کے خدشات پر قابو پانا کچھ ایسے چیلنجز ہیں جن سے نمٹنے کی ضرورت ہے تاکہ صحت کی دیکھ بھال میں NLP کی صلاحیت کو مکمل طور پر محسوس کیا جا سکے۔
6. اس کے بہت سے فوائد کے ساتھ، صحت کی دیکھ بھال کے پیشہ ور افراد کے لیے یہ ضروری ہے کہ وہ NLP کو قبول کریں اور اپنے ورک فلو میں شامل کریں۔ اگرچہ اس پر قابو پانے کے لیے بہت سے چیلنجز ہیں، صحت کی دیکھ بھال میں NLP یقینی طور پر دیکھنے اور اس میں سرمایہ کاری کرنے کا رجحان ہے۔
اس مضمون میں دکھایا گیا میڈیا Analytics ودھیا کی ملکیت نہیں ہے اور مصنف کی صوابدید پر استعمال ہوتا ہے۔
متعلقہ
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.analyticsvidhya.com/blog/2023/02/extracting-medical-information-from-clinical-text-with-nlp/