
Bài đăng này được đồng viết bởi Goktug Cinar, Michael Binder và Adrian Horvath từ Trung tâm Trí tuệ Nhân tạo Bosch (BCAI).
Dự báo doanh thu là một nhiệm vụ đầy thách thức nhưng rất quan trọng đối với các quyết định kinh doanh chiến lược và lập kế hoạch tài chính ở hầu hết các tổ chức. Thông thường, việc dự báo doanh thu được các nhà phân tích tài chính thực hiện thủ công và vừa tốn thời gian vừa mang tính chủ quan. Những nỗ lực thủ công như vậy đặc biệt là thách thức đối với các tổ chức kinh doanh đa quốc gia, quy mô lớn vốn yêu cầu dự báo doanh thu trên nhiều nhóm sản phẩm và khu vực địa lý ở nhiều cấp độ chi tiết. Điều này không chỉ đòi hỏi độ chính xác mà còn sự mạch lạc về thứ bậc của các dự báo.
Bosch là một tập đoàn đa quốc gia với các đơn vị hoạt động trong nhiều lĩnh vực, bao gồm ô tô, giải pháp công nghiệp và hàng tiêu dùng. Do tác động của việc dự báo doanh thu chính xác và mạch lạc đối với hoạt động kinh doanh lành mạnh, Trung tâm trí tuệ nhân tạo Bosch (BCAI) đã đầu tư rất nhiều vào việc sử dụng máy học (ML) để nâng cao hiệu quả và độ chính xác của quy trình lập kế hoạch tài chính. Mục tiêu là giảm bớt các quy trình thủ công bằng cách cung cấp các dự báo doanh thu cơ bản hợp lý thông qua ML, chỉ thỉnh thoảng các nhà phân tích tài chính mới cần điều chỉnh bằng cách sử dụng kiến thức về lĩnh vực và ngành của họ.
Để đạt được mục tiêu này, BCAI đã phát triển một khung dự báo nội bộ có khả năng cung cấp các dự báo phân cấp quy mô lớn thông qua tập hợp tùy chỉnh của nhiều mô hình cơ sở. Người học meta chọn các mô hình hoạt động tốt nhất dựa trên các tính năng được trích xuất từ mỗi chuỗi thời gian. Sau đó, các dự báo từ các mô hình đã chọn sẽ được tính trung bình để có được dự báo tổng hợp. Thiết kế kiến trúc được mô-đun hóa và có thể mở rộng thông qua việc triển khai giao diện kiểu REST, cho phép cải thiện hiệu suất liên tục thông qua việc đưa vào các mô hình bổ sung.
BCAI hợp tác với Phòng thí nghiệm giải pháp Amazon ML (MLSL) để kết hợp những tiến bộ mới nhất trong các mô hình dựa trên mạng thần kinh sâu (DNN) để dự báo doanh thu. Những tiến bộ gần đây trong công cụ dự báo thần kinh đã chứng tỏ hiệu suất vượt trội cho nhiều vấn đề dự báo thực tế. So với các mô hình dự báo truyền thống, nhiều nhà dự báo thần kinh có thể kết hợp các đồng biến hoặc siêu dữ liệu bổ sung của chuỗi thời gian. Chúng tôi bao gồm CNN-QR và DeepAR+, hai mô hình sẵn có trong Dự báo Amazon, cũng như mô hình Máy biến áp tùy chỉnh được đào tạo bằng cách sử dụng Amazon SageMaker. Ba mô hình bao gồm một tập hợp đại diện của các bộ mã hóa chính thường được sử dụng trong các bộ dự báo thần kinh: mạng thần kinh tích chập (CNN), mạng thần kinh tái phát tuần tự (RNN) và bộ mã hóa dựa trên máy biến áp.
Một trong những thách thức chính mà mối quan hệ đối tác BCAI-MLSL phải đối mặt là đưa ra những dự báo mạnh mẽ và hợp lý dưới tác động của COVID-19, một sự kiện toàn cầu chưa từng có gây ra biến động lớn về kết quả tài chính doanh nghiệp toàn cầu. Bởi vì các nhà dự báo thần kinh được đào tạo về dữ liệu lịch sử nên các dự báo được tạo dựa trên dữ liệu không được phân phối từ các giai đoạn có nhiều biến động hơn có thể không chính xác và không đáng tin cậy. Do đó, chúng tôi đã đề xuất bổ sung cơ chế chú ý đeo mặt nạ trong kiến trúc Transformer để giải quyết vấn đề này.
Các công cụ dự báo thần kinh có thể được nhóm lại thành một mô hình tổng hợp duy nhất hoặc được tích hợp riêng lẻ vào hệ thống mô hình của Bosch và có thể truy cập dễ dàng thông qua các điểm cuối API REST. Chúng tôi đề xuất một cách tiếp cận để tập hợp các nhà dự báo thần kinh thông qua kết quả kiểm tra ngược, mang lại hiệu suất cạnh tranh và mạnh mẽ theo thời gian. Ngoài ra, chúng tôi đã điều tra và đánh giá một số kỹ thuật đối chiếu thứ bậc cổ điển để đảm bảo rằng các dự báo được tổng hợp mạch lạc giữa các nhóm sản phẩm, khu vực địa lý và tổ chức kinh doanh.
Trong bài đăng này, chúng tôi chứng minh những điều sau:
- Cách áp dụng dự báo và đào tạo mô hình tùy chỉnh SageMaker cho các vấn đề dự báo chuỗi thời gian quy mô lớn, có thứ bậc
- Cách kết hợp các mô hình tùy chỉnh với các mô hình có sẵn từ Dự báo
- Cách giảm tác động của các sự kiện đột phá như COVID-19 đối với các vấn đề dự báo
- Cách xây dựng quy trình dự báo toàn diện trên AWS
Những thách thức
Chúng tôi đã giải quyết hai thách thức: tạo ra dự báo doanh thu quy mô lớn, có thứ bậc và tác động của đại dịch COVID-19 đối với hoạt động dự báo dài hạn.
Dự báo doanh thu quy mô lớn, phân cấp
Các nhà phân tích tài chính có nhiệm vụ dự báo các số liệu tài chính quan trọng, bao gồm doanh thu, chi phí hoạt động và chi tiêu R&D. Các số liệu này cung cấp thông tin chuyên sâu về lập kế hoạch kinh doanh ở các cấp độ tổng hợp khác nhau và cho phép đưa ra quyết định dựa trên dữ liệu. Bất kỳ giải pháp dự báo tự động nào cũng cần cung cấp dự báo ở bất kỳ cấp độ tổng hợp ngành nghề kinh doanh tùy ý nào. Tại Bosch, các tập hợp có thể được hình dung dưới dạng chuỗi thời gian được nhóm lại như một dạng cấu trúc phân cấp tổng quát hơn. Hình dưới đây thể hiện một ví dụ đơn giản với cấu trúc hai cấp, mô phỏng cấu trúc dự báo doanh thu phân cấp tại Bosch. Tổng doanh thu được chia thành nhiều cấp độ tổng hợp dựa trên sản phẩm và khu vực.
Tổng số chuỗi thời gian cần dự báo tại Bosch lên tới hàng triệu. Lưu ý rằng chuỗi thời gian cấp cao nhất có thể được phân chia theo sản phẩm hoặc khu vực, tạo ra nhiều đường dẫn đến dự báo cấp thấp nhất. Doanh thu cần được dự báo ở mọi nút trong hệ thống phân cấp với tầm dự báo là 12 tháng trong tương lai. Dữ liệu lịch sử hàng tháng có sẵn.
Cấu trúc phân cấp có thể được biểu diễn bằng dạng sau với ký hiệu ma trận tổng S (Hyndman và Athanasopoulos):
![]()
Trong phương trình này, Y bằng như sau:

Ở đây, b đại diện cho chuỗi thời gian cấp dưới cùng tại thời điểm t.
Tác động của đại dịch COVID-19
Đại dịch COVID-19 mang đến những thách thức đáng kể cho công tác dự báo do những tác động đột phá và chưa từng có của nó đối với hầu hết các khía cạnh công việc và đời sống xã hội. Để dự báo doanh thu dài hạn, sự gián đoạn cũng mang đến những tác động không mong muốn đến hạ nguồn. Để minh họa vấn đề này, hình dưới đây hiển thị chuỗi thời gian mẫu trong đó doanh thu sản phẩm giảm đáng kể khi bắt đầu đại dịch và dần dần phục hồi sau đó. Một mô hình dự báo thần kinh điển hình sẽ lấy dữ liệu doanh thu bao gồm cả giai đoạn COVID ngoài phân phối (OOD) làm đầu vào bối cảnh lịch sử, cũng như thông tin cơ bản cho việc đào tạo mô hình. Kết quả là các dự báo được đưa ra không còn đáng tin cậy nữa.

Phương pháp mô hình hóa
Trong phần này, chúng ta thảo luận về các phương pháp mô hình hóa khác nhau.
Dự báo Amazon
Dự báo là dịch vụ AI/ML được quản lý toàn phần từ AWS, cung cấp các mô hình dự báo chuỗi thời gian tiên tiến, được cấu hình sẵn. Nó kết hợp các dịch vụ này với các khả năng nội bộ của nó để tối ưu hóa siêu tham số tự động, lập mô hình tổng thể (đối với các mô hình do Dự báo cung cấp) và tạo dự báo xác suất. Điều này cho phép bạn dễ dàng nhập các tập dữ liệu tùy chỉnh, xử lý trước dữ liệu, đào tạo các mô hình dự báo và tạo ra các dự báo mạnh mẽ. Thiết kế mô-đun của dịch vụ còn cho phép chúng tôi dễ dàng truy vấn và kết hợp các dự đoán từ các mô hình tùy chỉnh bổ sung được phát triển song song.
Chúng tôi kết hợp hai công cụ dự báo thần kinh từ Dự báo: CNN-QR và DeepAR+. Cả hai đều là phương pháp học sâu có giám sát nhằm đào tạo mô hình toàn cầu cho toàn bộ tập dữ liệu chuỗi thời gian. Cả hai mô hình CNNQR và DeepAR+ đều có thể lấy thông tin siêu dữ liệu tĩnh về từng chuỗi thời gian, đó là sản phẩm, khu vực và tổ chức kinh doanh tương ứng trong trường hợp của chúng tôi. Chúng cũng tự động thêm các đặc điểm thời gian như tháng trong năm làm một phần đầu vào cho mô hình.
Máy biến áp với mặt nạ chú ý cho COVID
Kiến trúc máy biến áp (Vaswani và cộng sự.), ban đầu được thiết kế để xử lý ngôn ngữ tự nhiên (NLP), gần đây đã nổi lên như một lựa chọn kiến trúc phổ biến để dự báo chuỗi thời gian. Ở đây, chúng tôi sử dụng kiến trúc Transformer được mô tả trong Zhou và cộng sự. không có nhật ký xác suất và sự chú ý thưa thớt. Mô hình sử dụng thiết kế kiến trúc điển hình bằng cách kết hợp bộ mã hóa và bộ giải mã. Để dự báo doanh thu, chúng tôi định cấu hình bộ giải mã để xuất trực tiếp dự báo trong khoảng thời gian 12 tháng thay vì tạo dự báo từng tháng theo cách tự hồi quy. Dựa trên tần suất của chuỗi thời gian, các tính năng bổ sung liên quan đến thời gian như tháng trong năm sẽ được thêm làm biến đầu vào. Các biến phân loại bổ sung mô tả thông tin meta (sản phẩm, khu vực, tổ chức kinh doanh) được đưa vào mạng thông qua lớp nhúng có thể đào tạo.
Sơ đồ sau minh họa kiến trúc Transformer và cơ chế che giấu sự chú ý. Mặt nạ chú ý được áp dụng trên tất cả các lớp mã hóa và giải mã, như được đánh dấu bằng màu cam, để ngăn dữ liệu OOD ảnh hưởng đến dự báo.

Chúng tôi giảm thiểu tác động của cửa sổ ngữ cảnh OOD bằng cách thêm mặt nạ chú ý. Mô hình này được đào tạo để chú ý rất ít đến giai đoạn COVID có chứa các ngoại lệ thông qua việc che giấu và thực hiện dự báo với thông tin bị che giấu. Mặt nạ chú ý được áp dụng xuyên suốt mọi lớp của kiến trúc bộ giải mã và bộ mã hóa. Cửa sổ bị che có thể được chỉ định thủ công hoặc thông qua thuật toán phát hiện ngoại lệ. Ngoài ra, khi sử dụng cửa sổ thời gian chứa các giá trị ngoại lệ làm nhãn huấn luyện, tổn thất sẽ không được truyền ngược. Phương pháp dựa trên mặt nạ chú ý này có thể được áp dụng để xử lý sự gián đoạn và các trường hợp OOD do các sự kiện hiếm gặp khác gây ra, đồng thời cải thiện độ tin cậy của dự báo.
Dàn người mẫu
Tổ hợp mô hình thường hoạt động tốt hơn các mô hình đơn lẻ để dự báo—nó cải thiện khả năng tổng quát hóa của mô hình và xử lý dữ liệu chuỗi thời gian tốt hơn với các đặc điểm khác nhau về tính tuần hoàn và tính không liên tục. Chúng tôi kết hợp một loạt chiến lược tập hợp mô hình để cải thiện hiệu suất mô hình và độ tin cậy của dự báo. Một dạng phổ biến của tổ hợp mô hình học sâu là tổng hợp kết quả từ các lần chạy mô hình với các lần khởi tạo trọng số ngẫu nhiên khác nhau hoặc từ các giai đoạn đào tạo khác nhau. Chúng tôi sử dụng chiến lược này để có được dự báo cho mô hình Transformer.
Để tiếp tục xây dựng một tổ hợp dựa trên các kiến trúc mô hình khác nhau, chẳng hạn như Transformer, CNNQR và DeepAR+, chúng tôi sử dụng chiến lược tập hợp mô hình pan để chọn ra các mô hình hoạt động tốt nhất hàng đầu cho mỗi chuỗi thời gian dựa trên kết quả kiểm tra ngược và thu được chúng. trung bình. Vì kết quả backtest có thể được xuất trực tiếp từ các mô hình Dự báo đã được đào tạo nên chiến lược này cho phép chúng tôi tận dụng các dịch vụ chìa khóa trao tay như Dự báo với những cải tiến thu được từ các mô hình tùy chỉnh như Transformer. Cách tiếp cận tập hợp mô hình từ đầu đến cuối như vậy không yêu cầu đào tạo người học siêu dữ liệu hoặc tính toán các tính năng chuỗi thời gian để lựa chọn mô hình.
Hòa hợp thứ bậc
Khung này có khả năng thích ứng để kết hợp nhiều kỹ thuật như các bước xử lý hậu kỳ để đối chiếu dự báo theo cấp bậc, bao gồm đối chiếu từ dưới lên (BU), đối chiếu từ trên xuống với tỷ lệ dự báo (TDFP), bình phương tối thiểu thông thường (OLS) và bình phương tối thiểu có trọng số ( WLS). Tất cả các kết quả thử nghiệm trong bài đăng này được báo cáo bằng cách sử dụng đối chiếu từ trên xuống với các tỷ lệ dự báo.
Tổng quan kiến trúc
Chúng tôi đã phát triển quy trình làm việc toàn diện tự động trên AWS để tạo dự báo doanh thu bằng cách sử dụng các dịch vụ bao gồm Dự báo, SageMaker, Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), AWS Lambda, Chức năng bước AWSvà Bộ công cụ phát triển đám mây AWS (AWS CDK). Giải pháp được triển khai cung cấp các dự báo chuỗi thời gian riêng lẻ thông qua API REST bằng cách sử dụng Cổng API Amazon, bằng cách trả về kết quả ở định dạng JSON được xác định trước.
Sơ đồ sau đây minh họa quy trình dự báo từ đầu đến cuối.

Những cân nhắc thiết kế chính cho kiến trúc là tính linh hoạt, hiệu suất và tính thân thiện với người dùng. Hệ thống phải đủ linh hoạt để kết hợp một bộ thuật toán đa dạng trong quá trình phát triển và triển khai, với những thay đổi cần thiết tối thiểu và có thể dễ dàng mở rộng khi thêm các thuật toán mới trong tương lai. Hệ thống cũng phải bổ sung chi phí tối thiểu và hỗ trợ đào tạo song song cho cả Dự báo và SageMaker để giảm thời gian đào tạo và nhận được dự báo mới nhất nhanh hơn. Cuối cùng, hệ thống phải đơn giản để sử dụng cho mục đích thử nghiệm.
Quy trình làm việc từ đầu đến cuối tuần tự chạy qua các mô-đun sau:
- Một mô-đun tiền xử lý để định dạng lại và chuyển đổi dữ liệu
- Mô-đun đào tạo mô hình kết hợp cả mô hình Dự báo và mô hình tùy chỉnh trên SageMaker (cả hai đều chạy song song)
- Một mô-đun xử lý hậu kỳ hỗ trợ tập hợp mô hình, đối chiếu thứ bậc, số liệu và tạo báo cáo
Step Functions tổ chức và điều phối quy trình làm việc từ đầu đến cuối dưới dạng máy trạng thái. Quá trình chạy máy trạng thái được định cấu hình bằng tệp JSON chứa tất cả thông tin cần thiết, bao gồm vị trí của tệp CSV doanh thu lịch sử trong Amazon S3, thời gian bắt đầu dự báo và cài đặt siêu tham số mô hình để chạy quy trình làm việc toàn diện. Các lệnh gọi không đồng bộ được tạo để song song hóa việc đào tạo mô hình trong máy trạng thái bằng cách sử dụng các hàm Lambda. Tất cả dữ liệu lịch sử, tệp cấu hình, kết quả dự báo cũng như kết quả trung gian như kết quả kiểm tra ngược đều được lưu trữ trong Amazon S3. API REST được xây dựng dựa trên Amazon S3 để cung cấp giao diện có thể truy vấn để truy vấn kết quả dự báo. Hệ thống có thể được mở rộng để kết hợp các mô hình dự báo mới và các chức năng hỗ trợ như tạo báo cáo trực quan hóa dự báo.
Đánh giá
Trong phần này, chúng tôi trình bày chi tiết cách thiết lập thử nghiệm. Các thành phần chính bao gồm tập dữ liệu, số liệu đánh giá, cửa sổ kiểm tra ngược cũng như thiết lập và đào tạo mô hình.
Bộ dữ liệu
Để bảo vệ quyền riêng tư tài chính của Bosch trong khi sử dụng tập dữ liệu có ý nghĩa, chúng tôi đã sử dụng tập dữ liệu tổng hợp có các đặc điểm thống kê tương tự như tập dữ liệu doanh thu trong thế giới thực từ một đơn vị kinh doanh tại Bosch. Tập dữ liệu chứa tổng cộng 1,216 chuỗi thời gian với doanh thu được ghi theo tần suất hàng tháng, từ tháng 2016 năm 2022 đến tháng 877 năm XNUMX. Tập dữ liệu được phân phối với XNUMX chuỗi thời gian ở cấp độ chi tiết nhất (chuỗi thời gian dưới cùng), với cấu trúc chuỗi thời gian được nhóm tương ứng được biểu thị dưới dạng ma trận tổng S. Mỗi chuỗi thời gian được liên kết với ba thuộc tính phân loại tĩnh, tương ứng với danh mục sản phẩm, khu vực và đơn vị tổ chức trong tập dữ liệu thực (được ẩn danh trong dữ liệu tổng hợp).
Các chỉ số đánh giá
Chúng tôi sử dụng Lỗi phần trăm tuyệt đối Arctangent trung bình (trung bình-MAAPE) và MAAPE có trọng số để đánh giá hiệu suất mô hình và thực hiện phân tích so sánh, là số liệu tiêu chuẩn được sử dụng tại Bosch. MAAPE giải quyết những thiếu sót của chỉ số Lỗi phần trăm tuyệt đối trung bình (MAPE) thường được sử dụng trong bối cảnh kinh doanh. Median-MAAPE cung cấp cái nhìn tổng quan về hiệu suất của mô hình bằng cách tính giá trị trung bình của các MAAPE được tính riêng trên từng chuỗi thời gian. Weighted-MAAPE báo cáo sự kết hợp có trọng số của các MAAPE riêng lẻ. Trọng số là tỷ lệ doanh thu của từng chuỗi thời gian so với doanh thu tổng hợp của toàn bộ tập dữ liệu. MAAPE có trọng số phản ánh tốt hơn tác động kinh doanh hạ nguồn của độ chính xác dự báo. Cả hai số liệu đều được báo cáo trên toàn bộ tập dữ liệu của 1,216 chuỗi thời gian.
Cửa sổ kiểm tra lại
Chúng tôi sử dụng khoảng thời gian backtest 12 tháng luân phiên để so sánh hiệu suất của mô hình. Hình dưới đây minh họa các cửa sổ backtest được sử dụng trong các thử nghiệm và nêu bật dữ liệu tương ứng được sử dụng để đào tạo và tối ưu hóa siêu tham số (HPO). Đối với các khoảng thời gian kiểm tra lại sau khi COVID-19 bắt đầu, kết quả bị ảnh hưởng bởi dữ liệu đầu vào OOD từ tháng 2020 đến tháng XNUMX năm XNUMX, dựa trên những gì chúng tôi quan sát được từ chuỗi thời gian doanh thu.

Thiết lập và đào tạo mô hình
Đối với đào tạo về Transformer, chúng tôi đã sử dụng tổn thất lượng tử và chia tỷ lệ cho từng chuỗi thời gian bằng cách sử dụng giá trị trung bình lịch sử của nó trước khi đưa nó vào Transformer và tính toán tổn thất đào tạo. Dự báo cuối cùng được điều chỉnh lại tỷ lệ để tính toán số liệu chính xác bằng cách sử dụng MeanScaler được triển khai trong GluonTS. Chúng tôi sử dụng cửa sổ ngữ cảnh với dữ liệu doanh thu hàng tháng trong 18 tháng qua, được chọn qua HPO trong cửa sổ kiểm tra ngược từ tháng 2018 năm 2019 đến tháng 15 năm 2020. Siêu dữ liệu bổ sung về từng chuỗi thời gian ở dạng biến phân loại tĩnh được đưa vào mô hình thông qua quá trình nhúng lớp trước khi đưa nó vào các lớp máy biến áp. Chúng tôi huấn luyện Transformer với năm lần khởi tạo trọng số ngẫu nhiên khác nhau và tính trung bình các kết quả dự báo từ ba kỷ nguyên cuối cùng cho mỗi lần chạy, tổng cộng là trung bình XNUMX mô hình. Năm đợt đào tạo mô hình có thể được thực hiện song song để giảm thời gian đào tạo. Đối với Máy biến áp đeo mặt nạ, chúng tôi chỉ ra các tháng từ tháng XNUMX đến tháng XNUMX năm XNUMX là các giá trị ngoại lệ.
Đối với tất cả quá trình đào tạo mô hình Dự báo, chúng tôi đã bật HPO tự động, có thể chọn mô hình và tham số đào tạo dựa trên khoảng thời gian kiểm tra ngược do người dùng chỉ định, được đặt thành 12 tháng qua trong cửa sổ dữ liệu được sử dụng cho đào tạo và HPO.
Kết quả thử nghiệm
Chúng tôi đào tạo các Máy biến áp đeo mặt nạ và không đeo mặt nạ bằng cách sử dụng cùng một bộ siêu tham số và so sánh hiệu suất của chúng với các cửa sổ kiểm tra lại ngay sau cú sốc do dịch bệnh COVID-19. Trong Transformer đeo mặt nạ, hai tháng bị che là tháng 2020 và tháng 12 năm 2020. Bảng sau đây hiển thị kết quả từ một loạt giai đoạn backtest với khoảng thời gian dự báo XNUMX tháng bắt đầu từ tháng XNUMX năm XNUMX. Chúng ta có thể quan sát thấy rằng Transformer bị che luôn hoạt động tốt hơn phiên bản không đeo mặt nạ .

Chúng tôi tiếp tục thực hiện đánh giá về chiến lược tập hợp mô hình dựa trên kết quả kiểm tra ngược. Cụ thể, chúng tôi so sánh hai trường hợp khi chỉ chọn mô hình hoạt động tốt nhất với khi chọn hai mô hình hoạt động tốt nhất và tính trung bình của mô hình được thực hiện bằng cách tính giá trị trung bình của các dự báo. Chúng tôi so sánh hiệu suất của các mô hình cơ sở và các mô hình tập hợp trong các hình sau. Lưu ý rằng không có nhà dự báo thần kinh nào luôn thực hiện tốt hơn những người khác trong khoảng thời gian thử nghiệm ngược.


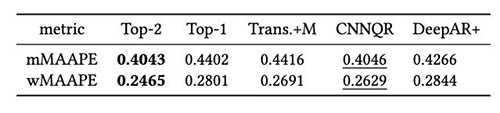
Bảng sau đây cho thấy rằng, tính trung bình, việc lập mô hình tổng hợp của hai mô hình hàng đầu sẽ mang lại hiệu suất tốt nhất. CNNQR cung cấp kết quả tốt thứ hai.
Kết luận
Bài đăng này trình bày cách xây dựng giải pháp ML toàn diện cho các vấn đề dự báo quy mô lớn bằng cách kết hợp Dự báo và mô hình tùy chỉnh được đào tạo trên SageMaker. Tùy thuộc vào nhu cầu kinh doanh và kiến thức ML của bạn, bạn có thể sử dụng dịch vụ được quản lý hoàn toàn như Dự báo để giảm tải quá trình xây dựng, đào tạo và triển khai mô hình dự báo; xây dựng mô hình tùy chỉnh của bạn với các cơ chế điều chỉnh cụ thể với SageMaker; hoặc thực hiện việc tổng hợp mô hình bằng cách kết hợp hai dịch vụ.
Nếu bạn muốn giúp tăng tốc việc sử dụng ML trong các sản phẩm và dịch vụ của mình, vui lòng liên hệ với Phòng thí nghiệm giải pháp Amazon ML chương trình.
dự án
Hyndman RJ, Athanasopoulos G. Dự báo: nguyên tắc và thực hành. OText; Ngày 2018 tháng 8 năm XNUMX
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Tất cả những gì bạn cần là chú ý. Những tiến bộ trong hệ thống xử lý thông tin thần kinh. 2017;30.
Chu H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Người cung cấp thông tin: Ngoài máy biến áp hiệu quả để dự báo chuỗi thời gian dài. Kỷ yếu của AAAI 2021 ngày 2 tháng XNUMX.
Về các tác giả
 Goktug Cinar là nhà khoa học ML hàng đầu và là trưởng nhóm kỹ thuật của ML và dự báo dựa trên số liệu thống kê tại Robert Bosch LLC và Trung tâm Trí tuệ Nhân tạo Bosch. Ông lãnh đạo việc nghiên cứu các mô hình dự báo, hợp nhất thứ bậc và kỹ thuật kết hợp mô hình cũng như nhóm phát triển phần mềm mở rộng các mô hình này và phục vụ chúng như một phần của phần mềm dự báo tài chính nội bộ từ đầu đến cuối.
Goktug Cinar là nhà khoa học ML hàng đầu và là trưởng nhóm kỹ thuật của ML và dự báo dựa trên số liệu thống kê tại Robert Bosch LLC và Trung tâm Trí tuệ Nhân tạo Bosch. Ông lãnh đạo việc nghiên cứu các mô hình dự báo, hợp nhất thứ bậc và kỹ thuật kết hợp mô hình cũng như nhóm phát triển phần mềm mở rộng các mô hình này và phục vụ chúng như một phần của phần mềm dự báo tài chính nội bộ từ đầu đến cuối.
 Michael Binder là chủ sở hữu sản phẩm tại Bosch Global Services, nơi ông điều phối việc phát triển, triển khai và triển khai ứng dụng phân tích dự đoán trên toàn công ty để dự báo các số liệu tài chính quan trọng dựa trên dữ liệu tự động quy mô lớn.
Michael Binder là chủ sở hữu sản phẩm tại Bosch Global Services, nơi ông điều phối việc phát triển, triển khai và triển khai ứng dụng phân tích dự đoán trên toàn công ty để dự báo các số liệu tài chính quan trọng dựa trên dữ liệu tự động quy mô lớn.
 Adrian Horvath là Nhà phát triển phần mềm tại Trung tâm Trí tuệ nhân tạo Bosch, nơi ông phát triển và duy trì các hệ thống để tạo dự đoán dựa trên các mô hình dự báo khác nhau.
Adrian Horvath là Nhà phát triển phần mềm tại Trung tâm Trí tuệ nhân tạo Bosch, nơi ông phát triển và duy trì các hệ thống để tạo dự đoán dựa trên các mô hình dự báo khác nhau.
 Panpan Xu là Nhà khoa học và Quản lý Ứng dụng Cấp cao của Phòng thí nghiệm Giải pháp Amazon ML tại AWS. Cô ấy đang nghiên cứu và phát triển các thuật toán Học máy cho các ứng dụng khách hàng có tác động cao trong nhiều ngành dọc công nghiệp để tăng tốc độ áp dụng AI và đám mây của họ. Mối quan tâm nghiên cứu của cô ấy bao gồm khả năng diễn giải mô hình, phân tích nhân quả, AI trong vòng lặp của con người và trực quan hóa dữ liệu tương tác.
Panpan Xu là Nhà khoa học và Quản lý Ứng dụng Cấp cao của Phòng thí nghiệm Giải pháp Amazon ML tại AWS. Cô ấy đang nghiên cứu và phát triển các thuật toán Học máy cho các ứng dụng khách hàng có tác động cao trong nhiều ngành dọc công nghiệp để tăng tốc độ áp dụng AI và đám mây của họ. Mối quan tâm nghiên cứu của cô ấy bao gồm khả năng diễn giải mô hình, phân tích nhân quả, AI trong vòng lặp của con người và trực quan hóa dữ liệu tương tác.
 Jasleen Grewal là Nhà khoa học ứng dụng tại Amazon Web Services, nơi cô làm việc với khách hàng AWS để giải quyết các vấn đề trong thế giới thực bằng cách sử dụng máy học, đặc biệt tập trung vào y học chính xác và bộ gen. Cô có kiến thức nền tảng vững chắc về tin học sinh học, ung thư học và gen di truyền học lâm sàng. Cô ấy đam mê sử dụng AI / ML và các dịch vụ đám mây để cải thiện việc chăm sóc bệnh nhân.
Jasleen Grewal là Nhà khoa học ứng dụng tại Amazon Web Services, nơi cô làm việc với khách hàng AWS để giải quyết các vấn đề trong thế giới thực bằng cách sử dụng máy học, đặc biệt tập trung vào y học chính xác và bộ gen. Cô có kiến thức nền tảng vững chắc về tin học sinh học, ung thư học và gen di truyền học lâm sàng. Cô ấy đam mê sử dụng AI / ML và các dịch vụ đám mây để cải thiện việc chăm sóc bệnh nhân.
 Selvan Senthivel là Kỹ sư ML Cấp cao của Phòng thí nghiệm Giải pháp ML của Amazon tại AWS, tập trung vào việc trợ giúp khách hàng về máy học, các vấn đề học sâu và các giải pháp ML đầu cuối. Ông là trưởng nhóm kỹ thuật sáng lập của Amazon Toàn diện Y tế và đóng góp vào thiết kế và kiến trúc của nhiều dịch vụ AWS AI.
Selvan Senthivel là Kỹ sư ML Cấp cao của Phòng thí nghiệm Giải pháp ML của Amazon tại AWS, tập trung vào việc trợ giúp khách hàng về máy học, các vấn đề học sâu và các giải pháp ML đầu cuối. Ông là trưởng nhóm kỹ thuật sáng lập của Amazon Toàn diện Y tế và đóng góp vào thiết kế và kiến trúc của nhiều dịch vụ AWS AI.
 Ruilin Zhang là một SDE thuộc Phòng thí nghiệm giải pháp máy học Amazon tại AWS. Anh giúp khách hàng áp dụng các dịch vụ AI của AWS bằng cách xây dựng các giải pháp để giải quyết các vấn đề kinh doanh thường gặp.
Ruilin Zhang là một SDE thuộc Phòng thí nghiệm giải pháp máy học Amazon tại AWS. Anh giúp khách hàng áp dụng các dịch vụ AI của AWS bằng cách xây dựng các giải pháp để giải quyết các vấn đề kinh doanh thường gặp.
 Shane Rai là Nhà chiến lược ML cấp cao của Phòng thí nghiệm giải pháp máy học Amazon tại AWS. Anh làm việc với khách hàng thuộc nhiều ngành khác nhau để giải quyết các nhu cầu kinh doanh cấp bách và đổi mới nhất của họ bằng cách sử dụng các dịch vụ AI/ML dựa trên đám mây đa dạng của AWS.
Shane Rai là Nhà chiến lược ML cấp cao của Phòng thí nghiệm giải pháp máy học Amazon tại AWS. Anh làm việc với khách hàng thuộc nhiều ngành khác nhau để giải quyết các nhu cầu kinh doanh cấp bách và đổi mới nhất của họ bằng cách sử dụng các dịch vụ AI/ML dựa trên đám mây đa dạng của AWS.
 Lâm Lực Hoành là Giám đốc khoa học ứng dụng của nhóm Phòng thí nghiệm giải pháp Amazon ML tại AWS. Cô làm việc với các khách hàng chiến lược của AWS để khám phá và áp dụng trí tuệ nhân tạo cũng như học máy nhằm khám phá những hiểu biết mới và giải quyết các vấn đề phức tạp.
Lâm Lực Hoành là Giám đốc khoa học ứng dụng của nhóm Phòng thí nghiệm giải pháp Amazon ML tại AWS. Cô làm việc với các khách hàng chiến lược của AWS để khám phá và áp dụng trí tuệ nhân tạo cũng như học máy nhằm khám phá những hiểu biết mới và giải quyết các vấn đề phức tạp.