
Trong một kho dữ liệu, một kích thước là một cấu trúc phân loại các sự kiện và biện pháp để cho phép người dùng trả lời các câu hỏi kinh doanh. Để minh họa một ví dụ, trong một miền bán hàng điển hình, khách hàng, thời gian hoặc sản phẩm là các tham số và giao dịch bán hàng là một thực tế. Các thuộc tính trong thứ nguyên có thể thay đổi theo thời gian—khách hàng có thể thay đổi địa chỉ của họ, nhân viên có thể chuyển từ vị trí nhà thầu sang vị trí toàn thời gian hoặc sản phẩm có thể có nhiều bản sửa đổi. MỘT từ từ thay đổi kích thước (SCD) là một khái niệm kho dữ liệu chứa dữ liệu tương đối tĩnh có thể thay đổi chậm trong một khoảng thời gian. Có ba loại SCD chính được duy trì trong kho dữ liệu: Loại 1 (không có lịch sử), Loại 2 (toàn bộ lịch sử) và Loại 3 (lịch sử hạn chế). Thu thập dữ liệu thay đổi (CDC) là một đặc điểm của cơ sở dữ liệu cung cấp khả năng xác định dữ liệu đã thay đổi giữa hai lần tải cơ sở dữ liệu, để có thể thực hiện một hành động trên dữ liệu đã thay đổi.
Khi các tổ chức trên toàn cầu đang hiện đại hóa nền tảng dữ liệu của họ với các kho dữ liệu trên Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), việc xử lý SCD trong kho dữ liệu có thể là một thách thức. Điều này càng trở nên khó khăn hơn khi các hệ thống nguồn không cung cấp cơ chế xác định dữ liệu đã thay đổi để xử lý trong hồ dữ liệu và khiến quá trình xử lý dữ liệu trở nên rất phức tạp nếu nguồn dữ liệu ở dạng bán cấu trúc thay vì cơ sở dữ liệu. Mục tiêu chính trong khi xử lý SCD Loại 2 là xác định ngày bắt đầu và ngày kết thúc của tập dữ liệu một cách chính xác để theo dõi các thay đổi trong kho dữ liệu, bởi vì điều này cung cấp khả năng báo cáo tại thời điểm cho các ứng dụng tiêu thụ.
Trong bài đăng này, chúng tôi tập trung vào việc trình bày cách xác định dữ liệu đã thay đổi cho nguồn bán cấu trúc (JSON) và nắm bắt toàn bộ các thay đổi dữ liệu lịch sử (SCD Type 2) và lưu trữ chúng trong hồ dữ liệu S3, sử dụng Keo AWS và định dạng hồ dữ liệu mở Delta.io. Việc triển khai này hỗ trợ các trường hợp sử dụng sau:
- Theo dõi SCD Loại 2 với ngày bắt đầu và ngày kết thúc để xác định các bản ghi lịch sử đầy đủ và hiện tại và một cờ để xác định các bản ghi đã xóa trong kho dữ liệu (xóa logic)
- Sử dụng các công cụ tiêu dùng như amazon Athena để truy vấn hồ sơ lịch sử liền mạch
Tổng quan về giải pháp
Bài đăng này trình bày giải pháp với trường hợp sử dụng từ đầu đến cuối bằng cách sử dụng bộ dữ liệu nhân viên mẫu. Bộ dữ liệu đại diện cho các chi tiết của nhân viên như ID, tên, địa chỉ, số điện thoại, nhà thầu hay không, v.v. Để chứng minh việc triển khai SCD, hãy xem xét các giả định sau:
- Nhóm kỹ thuật dữ liệu nhận các tệp hàng ngày là ảnh chụp nhanh đầy đủ của các bản ghi và không chứa bất kỳ cơ chế nào để xác định các thay đổi của bản ghi nguồn
- Nhóm được giao nhiệm vụ triển khai chức năng SCD Loại 2 để xác định các bản ghi mới, cập nhật và đã xóa khỏi nguồn và để lưu giữ các thay đổi lịch sử trong kho dữ liệu
- Do các hệ thống nguồn không cung cấp khả năng CDC, nên cần phát triển một cơ chế để xác định các bản ghi mới, cập nhật và đã xóa và duy trì chúng trong lớp hồ dữ liệu
Kiến trúc được triển khai như sau:
- Hệ thống nguồn nhập các tệp trong bộ chứa đích S3 (bước này được mô phỏng bằng cách tạo các bản ghi mẫu bằng cách sử dụng AWS Lambda chức năng vào thùng hạ cánh)
- Công việc AWS Glue (công việc Delta) chọn tệp dữ liệu nguồn và xử lý dữ liệu đã thay đổi từ lần tải tệp trước đó (phần chèn mới, cập nhật cho bản ghi hiện có và bản ghi đã xóa khỏi nguồn) vào kho dữ liệu S3 (bộ chứa lớp đã xử lý)
- Kiến trúc sử dụng định dạng hồ dữ liệu mở (Delta) và xây dựng hồ dữ liệu S3 dưới dạng Hồ Delta, định dạng này có thể thay đổi được vì các thay đổi mới có thể được cập nhật, các phần chèn mới có thể được thêm vào và việc xóa nguồn có thể được xác định và đánh dấu chính xác với một
delete_flaggiá trị - Trình thu thập dữ liệu AWS Glue lập danh mục dữ liệu mà Athena có thể truy vấn
Sơ đồ sau đây minh họa kiến trúc của chúng tôi.

Điều kiện tiên quyết
Trước khi bắt đầu, hãy đảm bảo bạn có các điều kiện tiên quyết sau:
Triển khai giải pháp
Đối với giải pháp này, chúng tôi cung cấp mẫu CloudFormation để thiết lập các dịch vụ có trong kiến trúc nhằm cho phép triển khai lặp lại. Mẫu này tạo các tài nguyên sau:
- Hai bộ chứa S3: một bộ chứa đích để lưu trữ dữ liệu nhân viên mẫu và một bộ chứa lớp đã xử lý cho kho dữ liệu có thể thay đổi (Delta Lake)
- Hàm Lambda để tạo bản ghi mẫu
- Công việc trích xuất, biến đổi và tải AWS Glue (ETL) để xử lý dữ liệu nguồn từ bộ chứa hạ cánh sang bộ chứa đã xử lý
Để triển khai giải pháp, hãy hoàn thành các bước sau:
- Chọn Khởi chạy Stack để khởi chạy ngăn xếp CloudFormation:
![]()
- Nhập tên ngăn xếp.
- Chọn Tôi xác nhận rằng AWS CloudFormation có thể tạo tài nguyên IAM với tên tùy chỉnh.
- Chọn Tạo ngăn xếp.
Sau khi triển khai ngăn xếp CloudFormation hoàn tất, hãy điều hướng đến bảng điều khiển AWS CloudFormation để lưu ý các tài nguyên sau trên bảng điều khiển Kết quả đầu ra tab:
- Tài nguyên hồ dữ liệu – Các thùng S3
scd-blog-landing-xxxxvàscd-blog-processed-xxxx(gọi làscd-blog-landingvàscd-blog-processedtrong các phần tiếp theo của bài viết này) - Trình tạo bản ghi mẫu Hàm Lambda –
SampleDataGenaratorLambda-<CloudFormation Stack Name>(gọi làSampleDataGeneratorLambda) - Cơ sở dữ liệu danh mục dữ liệu keo AWS –
deltalake_xxxxxx(gọi làdeltalake) - Công việc AWS Glue Delta –
<CloudFormation-Stack-Name>-src-to-processed(gọi làsrc-to-processed)
Lưu ý rằng việc triển khai ngăn xếp CloudFormation trong tài khoản của bạn sẽ phát sinh phí sử dụng AWS.
Kiểm tra triển khai SCD Loại 2
Với cơ sở hạ tầng sẵn có, bạn đã sẵn sàng thử nghiệm thiết kế giải pháp tổng thể và truy vấn các bản ghi lịch sử từ bộ dữ liệu nhân viên. Bài đăng này được thiết kế để triển khai cho trường hợp sử dụng thực tế của khách hàng, nơi bạn nhận được dữ liệu ảnh chụp nhanh đầy đủ hàng ngày. Chúng tôi kiểm tra các khía cạnh sau của việc triển khai SCD:
- Chạy tác vụ AWS Glue cho lần tải đầu tiên
- Mô phỏng một kịch bản không có thay đổi đối với nguồn
- Mô phỏng các kịch bản chèn, cập nhật và xóa bằng cách thêm các bản ghi mới, sửa đổi và xóa các bản ghi hiện có
- Mô phỏng tình huống trong đó bản ghi đã xóa trở lại dưới dạng phần chèn mới
Tạo tập dữ liệu nhân viên mẫu
Để kiểm tra giải pháp và trước khi bạn có thể bắt đầu nhập dữ liệu ban đầu, nguồn dữ liệu cần được xác định. Để đơn giản hóa bước đó, một hàm Lambda đã được triển khai trong ngăn xếp CloudFormation mà bạn vừa triển khai.

Mở chức năng và định cấu hình sự kiện thử nghiệm, với mặc định hello-world sự kiện mẫu JSON như trong ảnh chụp màn hình sau. Cung cấp tên sự kiện mà không có bất kỳ thay đổi nào đối với mẫu và lưu sự kiện thử nghiệm.

Chọn Thử nghiệm để gọi một sự kiện thử nghiệm, sự kiện này sẽ gọi hàm Lambda để tạo bản ghi mẫu.

Khi hàm Lambda hoàn thành lệnh gọi của nó, bạn sẽ có thể xem tập dữ liệu nhân viên mẫu sau đây trong bộ chứa đích.
Chạy công việc AWS Glue
Xác nhận nếu bạn thấy tập dữ liệu nhân viên trong đường dẫn s3://scd-blog-landing/dataset/employee/. Bạn có thể tải xuống tập dữ liệu và mở nó trong trình chỉnh sửa mã, chẳng hạn như Mã VS. Sau đây là một ví dụ về tập dữ liệu:
Tải xuống tập dữ liệu và luôn sẵn sàng vì bạn sẽ sửa đổi tập dữ liệu cho các trường hợp sử dụng trong tương lai để mô phỏng các thao tác chèn, cập nhật và xóa. Tập dữ liệu mẫu được tạo cho bạn sẽ hoàn toàn khác với những gì bạn thấy trong ví dụ trước.
Để chạy công việc, hãy hoàn thành các bước sau:
- Trên bảng điều khiển AWS Glue, hãy chọn việc làm trong khung điều hướng.
- Chọn công việc
src-to-processed. - trên Chạy tab, chọn chạy.
Khi tác vụ AWS Glue được chạy lần đầu tiên, tác vụ này sẽ đọc tập dữ liệu nhân viên từ đường dẫn bộ chứa hạ cánh và nhập dữ liệu vào bộ chứa đã xử lý dưới dạng bảng Delta.

Khi công việc hoàn tất, bạn có thể tạo trình thu thập thông tin để xem tải dữ liệu ban đầu. Ảnh chụp màn hình sau đây cho thấy cơ sở dữ liệu có sẵn trên Cơ sở dữ liệu .

- Chọn Trình thu thập thông tin trong khung điều hướng.
- Chọn Tạo trình thu thập thông tin.

- Đặt tên cho trình thu thập thông tin của bạn
delta-lake-crawler, sau đó chọn Sau.

- Chọn Chưa được đối với dữ liệu đã được ánh xạ tới các bảng AWS Glue.
- Chọn Thêm nguồn dữ liệu.

- trên Nguồn dữ liệu menu thả xuống, chọn Hồ Delta.
- Nhập đường dẫn đến bảng Delta.
- Chọn Tạo bảng gốc.
- Chọn Thêm nguồn dữ liệu Delta Lake.

- Chọn Sau.

- Chọn vai trò được tạo bởi mẫu CloudFormation, sau đó chọn Sau.

- Chọn cơ sở dữ liệu được tạo bởi mẫu CloudFormation, sau đó chọn Sau.

- Chọn Tạo trình thu thập thông tin.

- Chọn trình thu thập thông tin của bạn và chọn chạy.

Truy vấn dữ liệu
Sau khi trình thu thập thông tin hoàn tất, bạn có thể xem bảng mà nó đã tạo.

Để truy vấn dữ liệu, hãy hoàn thành các bước sau:
- Chọn bảng nhân viên và trên Hoạt động menu, chọn Xem dữ liệu.

Bạn được chuyển hướng đến bảng điều khiển Athena. Nếu bạn không có công cụ Athena mới nhất, hãy tạo một nhóm làm việc Athena mới với công cụ Athena mới nhất.
- Theo Quản trị trong ngăn điều hướng, chọn Nhóm làm việc.

- Chọn Tạo nhóm làm việc.

- Đặt tên cho nhóm làm việc, chẳng hạn như
DeltaWorkgroup. - Chọn Athena SQL làm động cơ, và chọn Athena engine phiên bản 3 cho Phiên bản công cụ truy vấn.

- Chọn Tạo nhóm làm việc.

- Sau khi bạn tạo nhóm làm việc, hãy chọn nhóm làm việc (
DeltaWorkgroup) trên menu thả xuống trong trình chỉnh sửa truy vấn Athena.

- Chạy truy vấn sau trên
employeebàn:
Lưu ý: Cập nhật tên cơ sở dữ liệu chính xác từ kết quả đầu ra của CloudFormation trước khi chạy truy vấn trên.
Bạn có thể quan sát thấy rằng employee bảng có 25 bản ghi. Ảnh chụp màn hình sau đây hiển thị tổng số bản ghi nhân viên với một số bản ghi mẫu.

Bảng Delta được lưu trữ với một emp_key, là duy nhất cho mỗi và mọi thay đổi và được sử dụng để theo dõi các thay đổi. Các emp_key được tạo cho mỗi lần chèn, cập nhật và xóa và có thể được sử dụng để tìm tất cả các thay đổi liên quan đến một emp_id.
Sản phẩm emp_key được tạo bằng thuật toán băm SHA256, như được hiển thị trong đoạn mã sau:
Thực hiện chèn, cập nhật và xóa
Trước khi thực hiện các thay đổi đối với tập dữ liệu, hãy chạy lại công việc đó một lần nữa. Giả sử rằng tải hiện tại từ nguồn giống như tải ban đầu và không có thay đổi nào, tác vụ AWS Glue sẽ không thực hiện bất kỳ thay đổi nào đối với tập dữ liệu. Sau khi công việc hoàn thành, hãy chạy phần trước Select truy vấn trong trình chỉnh sửa truy vấn Athena và xác nhận rằng vẫn còn 25 bản ghi đang hoạt động với các giá trị sau:
- Tất cả 25 bản ghi với cột
isCurrent=true - Tất cả 25 bản ghi với cột
end_date=Null - Tất cả 25 bản ghi với cột
delete_flag=false
Sau khi bạn xác nhận công việc trước đó chạy với các giá trị này, hãy sửa đổi tập dữ liệu ban đầu của chúng tôi với các thay đổi sau:
- Thay đổi
isContractorgắn cờ chofalse(đổi nó thànhtruenếu tập dữ liệu của bạn đã hiển thịfalse) Choemp_id=12. - Xóa toàn bộ hàng ở đâu
emp_id=8(đảm bảo lưu bản ghi trong trình soạn thảo văn bản, vì chúng tôi sử dụng bản ghi này trong trường hợp sử dụng khác). - Sao chép hàng cho
emp_id=25và chèn một hàng mới. Thay đổiemp_idđược26và đảm bảo cũng thay đổi giá trị cho các cột khác.
Sau khi chúng tôi thực hiện những thay đổi này, tập dữ liệu nguồn nhân viên trông giống như mã sau (để dễ đọc, chúng tôi chỉ bao gồm các bản ghi đã thay đổi như được mô tả trong ba bước trước):
- Bây giờ, tải lên thay đổi
fake_emp_data.jsontập tin vào cùng một tiền tố nguồn.
- Sau khi bạn tải tập dữ liệu nhân viên đã thay đổi lên Amazon S3, hãy điều hướng đến bảng điều khiển AWS Glue và chạy công việc.
- Khi công việc hoàn tất, hãy chạy truy vấn sau trong trình chỉnh sửa truy vấn Athena và xác nhận rằng có tổng cộng 27 bản ghi với các giá trị sau:
Lưu ý: Cập nhật tên cơ sở dữ liệu chính xác từ đầu ra CloudFormation trước khi chạy truy vấn trên.

- Chạy một truy vấn khác trong trình chỉnh sửa truy vấn Athena và xác nhận rằng có 4 bản ghi được trả về với các giá trị sau:
Lưu ý: Cập nhật tên cơ sở dữ liệu chính xác từ đầu ra CloudFormation trước khi chạy truy vấn trên.

Bạn sẽ thấy hai bản ghi cho emp_id=12:
- Một
emp_id=12bản ghi với các giá trị sau (đối với bản ghi đã được nhập như một phần của lần tải ban đầu):emp_key=44cebb094ef289670e2c9325d5f3e4ca18fdd53850b7ccd98d18c7a57cb6d4b4isCurrent=falsedelete_flag=falseend_date=’2023-03-02’
- Thứ hai
emp_id=12bản ghi với các giá trị sau (đối với bản ghi đã được nhập như một phần của thay đổi đối với nguồn):emp_key=b60547d769e8757c3ebf9f5a1002d472dbebebc366bfbc119227220fb3a3b108isCurrent=truedelete_flag=falseend_date=Null(hoặc chuỗi rỗng)
Kỷ lục cho emp_id=8 đã bị xóa trong nguồn như một phần của lần chạy này sẽ vẫn tồn tại nhưng với những thay đổi sau đối với các giá trị:
isCurrent=falseend_date=’2023-03-02’delete_flag=true
Bản ghi nhân viên mới sẽ được chèn với các giá trị sau:
emp_id=26isCurrent=trueend_date=NULL(hoặc chuỗi rỗng)delete_flag=false
Lưu ý rằng emp_key giá trị trong bảng thực tế của bạn có thể khác với giá trị được cung cấp ở đây làm ví dụ.
- Đối với các lần xóa, chúng tôi kiểm tra emp_id từ bảng cơ sở cùng với tệp nguồn mới và tham gia bên trong emp_key.
- Nếu điều kiện được đánh giá là đúng, thì chúng tôi sẽ kiểm tra xem bảng cơ sở nhân viên emp_key có bằng các bản cập nhật mới emp_key hay không và lấy bản ghi hiện tại, chưa xóa (isCurrent=true và delete_flag=false).
- Chúng tôi hợp nhất các thay đổi xóa từ tệp mới với bảng cơ sở cho tất cả các hàng điều kiện xóa phù hợp và cập nhật thông tin sau:
isCurrent=falsedelete_flag=trueend_date=current_date
Xem mã sau đây:
- Đối với cả cập nhật và chèn, chúng tôi kiểm tra điều kiện nếu bảng cơ sở
employee.emp_idbằng vớinew changes.emp_idvàemployee.emp_keybằngnew changes.emp_key, trong khi chỉ truy xuất các bản ghi hiện tại. - Nếu điều kiện này đánh giá là
true, sau đó chúng tôi nhận được bản ghi hiện tại (isCurrent=truevàdelete_flag=false). - Chúng tôi hợp nhất các thay đổi bằng cách cập nhật như sau:
- Nếu điều kiện thứ hai đánh giá là
true:isCurrent=falseend_date=current_date
- Hoặc chúng tôi chèn toàn bộ hàng như sau nếu điều kiện thứ hai ước tính là
false:emp_id=new record’s emp_keyemp_key=new record’s emp_keyfirst_name=new record’s first_namelast_name=new record’s last_nameaddress=new record’s addressphone_number=new record’s phone_numberisContractor=new record’s isContractorstart_date=current_dateend_date=NULL(hoặc chuỗi rỗng)isCurrent=truedelete_flag=false
- Nếu điều kiện thứ hai đánh giá là
Xem mã sau đây:
Ở bước cuối cùng, hãy đưa bản ghi đã xóa từ thay đổi trước đó trở lại tập dữ liệu nguồn và xem cách nó được chèn lại vào tập dữ liệu nguồn. employee bảng trong hồ dữ liệu và quan sát cách duy trì toàn bộ lịch sử.
Hãy sửa đổi tập dữ liệu đã thay đổi của chúng tôi từ bước trước và thực hiện các thay đổi sau.
- Thêm đã xóa
emp_id=8quay lại tập dữ liệu.
Sau khi thực hiện những thay đổi này, tập dữ liệu nguồn nhân viên của tôi trông giống như mã sau (để dễ đọc, chúng tôi chỉ bao gồm bản ghi đã thêm như được mô tả trong bước trước):
{"emp_id":8,"first_name":"Teresa","last_name":"Estrada","Address":"339 Scott ValleynGonzalesfort, PA 18212","phone_number":"435-600-3162","isContractor":false}
- Tải tệp dữ liệu nhân viên đã thay đổi lên cùng một tiền tố nguồn.

- Sau khi bạn tải lên thay đổi
fake_emp_data.jsontập dữ liệu sang Amazon S3, điều hướng đến bảng điều khiển AWS Glue và chạy lại công việc. - Khi công việc hoàn tất, hãy chạy truy vấn sau trong trình chỉnh sửa truy vấn Athena và xác nhận rằng có tổng cộng 28 bản ghi với các giá trị sau:
Lưu ý: Cập nhật tên cơ sở dữ liệu chính xác từ đầu ra CloudFormation trước khi chạy truy vấn trên.

- Chạy truy vấn sau và xác nhận có 5 bản ghi:
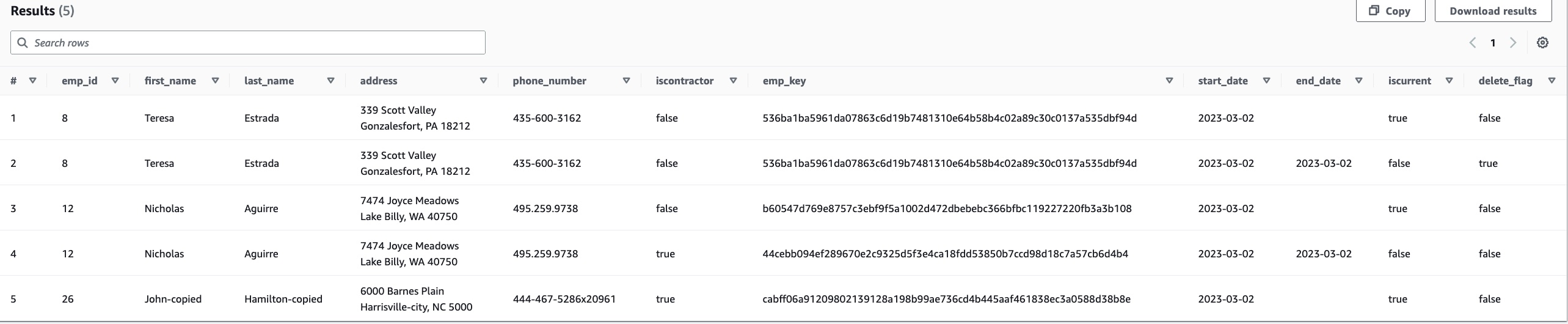
Bạn sẽ thấy hai bản ghi cho emp_id=8:
- Một
emp_id=8bản ghi với các giá trị sau (bản ghi cũ đã bị xóa):emp_key=536ba1ba5961da07863c6d19b7481310e64b58b4c02a89c30c0137a535dbf94disCurrent=falsedeleted_flag=trueend_date=’2023-03-02’
- Một
emp_id=8bản ghi với các giá trị sau (bản ghi mới được chèn trong lần chạy cuối cùng):emp_key=536ba1ba5961da07863c6d19b7481310e64b58b4c02a89c30c0137a535dbf94disCurrent=truedeleted_flag=falseend_date=NULL(hoặc chuỗi rỗng)
Sản phẩm emp_key giá trị trong bảng thực tế của bạn có thể khác với giá trị được cung cấp ở đây làm ví dụ. Cũng lưu ý rằng vì đây là cùng một bản ghi đã xóa được chèn lại trong lần tải tiếp theo mà không có bất kỳ thay đổi nào, nên sẽ không có thay đổi nào đối với emp_key.
Truy vấn mẫu của người dùng cuối
Sau đây là một số truy vấn mẫu của người dùng cuối để chứng minh cách duyệt lịch sử dữ liệu thay đổi của nhân viên để báo cáo:
- Truy vấn 1 – Truy xuất danh sách tất cả nhân viên đã rời khỏi tổ chức trong tháng hiện tại (ví dụ: tháng 2023 năm XNUMX).

Truy vấn trước đó sẽ trả về hai bản ghi nhân viên đã rời khỏi tổ chức.
- Truy vấn 2 – Truy xuất danh sách nhân viên mới gia nhập tổ chức trong tháng hiện tại (ví dụ: tháng 2023 năm XNUMX).
Lưu ý: Cập nhật tên cơ sở dữ liệu chính xác từ đầu ra CloudFormation trước khi chạy truy vấn trên.

Truy vấn trước đó sẽ trả về 23 bản ghi nhân viên đang hoạt động đã tham gia tổ chức.
- Truy vấn 3 – Tìm lịch sử của bất kỳ nhân viên nào trong tổ chức (trong trường hợp này là nhân viên 18).
Lưu ý: Cập nhật tên cơ sở dữ liệu chính xác từ đầu ra CloudFormation trước khi chạy truy vấn trên.

Trong truy vấn trước, chúng ta có thể quan sát thấy rằng nhân viên 18 đã có hai thay đổi đối với hồ sơ nhân viên của họ trước khi họ rời khỏi tổ chức.
Lưu ý rằng kết quả dữ liệu được cung cấp trong ví dụ này khác với kết quả bạn sẽ thấy trong các bản ghi cụ thể của mình dựa trên dữ liệu mẫu do hàm Lambda tạo ra.
Làm sạch
Khi bạn đã thử nghiệm xong giải pháp này, hãy dọn sạch tài nguyên của mình để tránh phát sinh phí AWS:
- Làm trống các thùng S3.
- Xóa ngăn xếp khỏi bảng điều khiển AWS CloudFormation.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách xác định dữ liệu đã thay đổi cho nguồn dữ liệu bán cấu trúc và lưu giữ các thay đổi lịch sử (SCD Loại 2) trên S3 Delta Lake, khi hệ thống nguồn không thể cung cấp khả năng thu thập dữ liệu thay đổi, với AWS Keo dán. Bạn có thể mở rộng thêm giải pháp này để cho phép các ứng dụng xuôi tuyến xây dựng các tùy chỉnh bổ sung từ dữ liệu CDC được thu thập trong kho dữ liệu.
Ngoài ra, bạn có thể mở rộng giải pháp này như một phần của sự phối hợp bằng cách sử dụng Chức năng bước AWS hoặc các bộ điều phối thường được sử dụng khác mà tổ chức của bạn đã quen thuộc. Bạn cũng có thể mở rộng giải pháp này bằng cách thêm các phân vùng khi thích hợp. Bạn cũng có thể duy trì bảng delta bằng cách nén chặt các tập tin nhỏ.
Giới thiệu về tác giả
 Nith Govindasivan, là Kiến trúc sư Data Lake với Dịch vụ chuyên nghiệp AWS, nơi anh giúp giới thiệu khách hàng trên hành trình kiến trúc dữ liệu hiện đại của họ thông qua việc triển khai các giải pháp Big Data & Analytics. Ngoài công việc, Nith là một người hâm mộ cuồng nhiệt môn Cricket, xem hầu hết mọi môn cricket trong thời gian rảnh rỗi và thích lái xe đường dài cũng như đi du lịch quốc tế.
Nith Govindasivan, là Kiến trúc sư Data Lake với Dịch vụ chuyên nghiệp AWS, nơi anh giúp giới thiệu khách hàng trên hành trình kiến trúc dữ liệu hiện đại của họ thông qua việc triển khai các giải pháp Big Data & Analytics. Ngoài công việc, Nith là một người hâm mộ cuồng nhiệt môn Cricket, xem hầu hết mọi môn cricket trong thời gian rảnh rỗi và thích lái xe đường dài cũng như đi du lịch quốc tế.
 Vijay Velpula là Kiến trúc sư dữ liệu với AWS Professional Services. Anh ấy giúp khách hàng triển khai các Giải pháp phân tích và dữ liệu lớn. Ngoài công việc, anh ấy thích dành thời gian cho gia đình, đi du lịch, đi bộ đường dài và đi xe đạp.
Vijay Velpula là Kiến trúc sư dữ liệu với AWS Professional Services. Anh ấy giúp khách hàng triển khai các Giải pháp phân tích và dữ liệu lớn. Ngoài công việc, anh ấy thích dành thời gian cho gia đình, đi du lịch, đi bộ đường dài và đi xe đạp.
 Sriharsh Adari là Kiến trúc sư giải pháp cao cấp tại Amazon Web Services (AWS), nơi anh ấy giúp khách hàng làm việc ngược lại từ kết quả kinh doanh để phát triển các giải pháp sáng tạo trên AWS. Trong những năm qua, anh ấy đã giúp nhiều khách hàng trong việc chuyển đổi nền tảng dữ liệu trên các ngành dọc của ngành. Lĩnh vực chuyên môn cốt lõi của ông bao gồm Chiến lược công nghệ, Phân tích dữ liệu và Khoa học dữ liệu. Trong thời gian rảnh rỗi, anh ấy thích chơi thể thao, say sưa xem các chương trình TV và chơi Tabla.
Sriharsh Adari là Kiến trúc sư giải pháp cao cấp tại Amazon Web Services (AWS), nơi anh ấy giúp khách hàng làm việc ngược lại từ kết quả kinh doanh để phát triển các giải pháp sáng tạo trên AWS. Trong những năm qua, anh ấy đã giúp nhiều khách hàng trong việc chuyển đổi nền tảng dữ liệu trên các ngành dọc của ngành. Lĩnh vực chuyên môn cốt lõi của ông bao gồm Chiến lược công nghệ, Phân tích dữ liệu và Khoa học dữ liệu. Trong thời gian rảnh rỗi, anh ấy thích chơi thể thao, say sưa xem các chương trình TV và chơi Tabla.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/implement-slowly-changing-dimensions-in-a-data-lake-using-aws-glue-and-delta/