
این پست توسط Goktug Cinar، Michael Binder و Adrian Horvath از مرکز هوش مصنوعی Bosch (BCAI) نوشته شده است.
پیش بینی درآمد یک کار چالش برانگیز و در عین حال حیاتی برای تصمیم گیری های استراتژیک تجاری و برنامه ریزی مالی در اکثر سازمان ها است. اغلب، پیش بینی درآمد به صورت دستی توسط تحلیلگران مالی انجام می شود و هم زمان بر و هم ذهنی است. چنین تلاشهای دستی بهویژه برای سازمانهای تجاری چندملیتی در مقیاس بزرگ که نیاز به پیشبینی درآمد در طیف وسیعی از گروههای محصول و مناطق جغرافیایی در سطوح مختلف جزئیات دارند، چالش برانگیز است. این امر نه تنها به دقت، بلکه به انسجام سلسله مراتبی پیش بینی ها نیز نیاز دارد.
بوش یک شرکت چند ملیتی با نهادهایی است که در بخشهای مختلف از جمله خودرو، راهحلهای صنعتی و کالاهای مصرفی فعالیت میکنند. با توجه به تأثیر پیشبینی دقیق و منسجم درآمد بر عملکرد سالم کسبوکار، مرکز هوش مصنوعی بوش (BCAI) به شدت در استفاده از یادگیری ماشین (ML) برای بهبود کارایی و دقت فرآیندهای برنامه ریزی مالی سرمایه گذاری کرده است. هدف کاهش فرآیندهای دستی با ارائه پیشبینیهای درآمد پایه معقول از طریق ML است، تنها با تعدیلهای گاه به گاه مورد نیاز تحلیلگران مالی با استفاده از دانش صنعت و حوزه خود.
برای دستیابی به این هدف، BCAI یک چارچوب پیشبینی داخلی ایجاد کرده است که قادر به ارائه پیشبینیهای سلسله مراتبی در مقیاس بزرگ از طریق مجموعههای سفارشیشده طیف گستردهای از مدلهای پایه است. یک فراآموز بهترین مدل ها را بر اساس ویژگی های استخراج شده از هر سری زمانی انتخاب می کند. سپس پیشبینیهای مدلهای انتخابشده برای به دست آوردن پیشبینی انبوه، میانگینگیری میشوند. طراحی معماری از طریق اجرای یک رابط به سبک REST، مدولار شده و قابل توسعه است، که امکان بهبود عملکرد مداوم را از طریق گنجاندن مدلهای اضافی فراهم میکند.
BCAI با آزمایشگاه راه حل های آمازون ام ال (MLSL) برای ترکیب آخرین پیشرفتها در مدلهای مبتنی بر شبکه عصبی عمیق (DNN) برای پیشبینی درآمد. پیشرفتهای اخیر در پیشبینیکنندههای عصبی، عملکرد پیشرفتهای را برای بسیاری از مشکلات پیشبینی عملی نشان دادهاند. در مقایسه با مدلهای پیشبینی سنتی، بسیاری از پیشبینیکنندههای عصبی میتوانند متغیرهای کمکی یا ابردادههای سریهای زمانی را ترکیب کنند. ما شامل CNN-QR و DeepAR+، دو مدل خارج از قفسه هستیم پیش بینی آمازون، و همچنین یک مدل ترانسفورماتور سفارشی آموزش دیده با استفاده از آمازون SageMaker. این سه مدل مجموعهای از ستونهای رمزگذار را که اغلب در پیشبینیکنندههای عصبی استفاده میشوند، پوشش میدهند: شبکه عصبی کانولوشنال (CNN)، شبکه عصبی بازگشتی متوالی (RNN)، و رمزگذارهای مبتنی بر ترانسفورماتور.
یکی از چالشهای کلیدی که مشارکت BCAI-MLSL با آن مواجه بود، ارائه پیشبینیهای قوی و معقول تحت تأثیر COVID-19 بود، یک رویداد جهانی بیسابقه که باعث نوسانات زیادی در نتایج مالی شرکتهای جهانی میشود. از آنجایی که پیشبینیکنندگان عصبی بر اساس دادههای تاریخی آموزش دیدهاند، پیشبینیهای ایجاد شده بر اساس دادههای خارج از توزیع از دورههای پرنوسانتر میتواند نادرست و غیرقابل اعتماد باشد. بنابراین، ما اضافه کردن یک مکانیسم توجه پوشیده در معماری ترانسفورماتور را برای رسیدگی به این موضوع پیشنهاد کردیم.
پیشبینیکنندههای عصبی را میتوان بهعنوان یک مدل واحد جمعآوری کرد، یا بهصورت جداگانه در جهان مدل Bosch گنجانید، و از طریق نقاط پایانی REST API به راحتی قابل دسترسی بود. ما رویکردی را برای جمعکردن پیشبینیکنندگان عصبی از طریق نتایج آزمون پسزمینه پیشنهاد میکنیم که عملکرد رقابتی و قوی را در طول زمان ارائه میدهد. علاوه بر این، تعدادی از تکنیکهای تطبیق سلسله مراتبی کلاسیک را بررسی و ارزیابی کردیم تا اطمینان حاصل کنیم که پیشبینیها به طور منسجم در گروههای محصول، مناطق جغرافیایی و سازمانهای تجاری جمع میشوند.
در این پست موارد زیر را نشان می دهیم:
- نحوه اعمال آموزش مدل سفارشی Forecast و SageMaker برای مشکلات پیشبینی سری زمانی سلسله مراتبی و در مقیاس بزرگ
- نحوه ترکیب مدل های سفارشی با مدل های خارج از قفسه از Forecast
- چگونه می توان تأثیر رویدادهای مخرب مانند COVID-19 را بر مشکلات پیش بینی کاهش داد
- نحوه ایجاد یک گردش کار پیشبینی سرتاسر در AWS
چالش ها
ما به دو چالش پرداختیم: ایجاد پیشبینی درآمد در مقیاس بزرگ و سلسله مراتبی و تأثیر همهگیری COVID-19 بر پیشبینی بلندمدت.
پیش بینی درآمد سلسله مراتبی در مقیاس بزرگ
تحلیلگران مالی وظیفه پیش بینی ارقام مالی کلیدی از جمله درآمد، هزینه های عملیاتی و هزینه های تحقیق و توسعه را دارند. این معیارها بینش برنامهریزی کسبوکار را در سطوح مختلف تجمیع ارائه میکنند و تصمیمگیری مبتنی بر دادهها را امکانپذیر میکنند. هر راهحل پیشبینی خودکار باید پیشبینیهایی را در هر سطح دلخواه از تجمیع خطوط تجاری ارائه کند. در Bosch، تجمیعها را میتوان به صورت سریهای زمانی گروهبندیشده بهعنوان شکل کلیتری از ساختار سلسله مراتبی تصور کرد. شکل زیر یک مثال ساده شده با ساختار دو سطحی را نشان می دهد که ساختار پیش بینی درآمد سلسله مراتبی در Bosch را تقلید می کند. کل درآمد بر اساس محصول و منطقه به سطوح مختلف تجمیع تقسیم می شود.
تعداد کل سری های زمانی که باید در بوش پیش بینی شوند در مقیاس میلیون ها است. توجه داشته باشید که سریهای زمانی سطح بالا را میتوان بر اساس محصولات یا مناطق تقسیم کرد و مسیرهای متعددی را برای پیشبینیهای سطح پایین ایجاد کرد. درآمد باید در هر گره در سلسله مراتب با افق پیش بینی 12 ماه آینده پیش بینی شود. داده های تاریخی ماهانه در دسترس است.
ساختار سلسله مراتبی را می توان با استفاده از فرم زیر با نماد یک ماتریس جمع نمایش داد S (هایندمن و آتاناسوپولوس):
![]()
در این معادله ، Y برابر با موارد زیر است:

در اینجا، b نشان دهنده سری زمانی سطح پایین در آن زمان است t.
تأثیرات همه گیری COVID-19
همهگیری COVID-19 به دلیل تأثیرات مخرب و بیسابقهای که بر تقریباً تمام جنبههای زندگی کاری و اجتماعی دارد، چالشهای مهمی را برای پیشبینی به همراه داشت. برای پیشبینی درآمد بلندمدت، این اختلال همچنین تأثیرات غیرمنتظرهای در پاییندست به همراه داشت. برای نشان دادن این مشکل، شکل زیر یک سری زمانی نمونه را نشان میدهد که در آن درآمد محصول در شروع همهگیری کاهش قابل توجهی را تجربه کرد و پس از آن به تدریج بهبود یافت. یک مدل پیشبینی عصبی معمولی دادههای درآمدی از جمله دوره کووید خارج از توزیع (OOD) را بهعنوان ورودی بافت تاریخی و همچنین حقیقت پایه برای آموزش مدل را در نظر میگیرد. در نتیجه، پیش بینی های تولید شده دیگر قابل اعتماد نیستند.

رویکردهای مدلسازی
در این بخش، رویکردهای مختلف مدلسازی خود را مورد بحث قرار می دهیم.
پیش بینی آمازون
Forecast یک سرویس کاملاً مدیریتشده AI/ML از AWS است که مدلهای پیشبینی سریهای زمانی پیشرفته و از پیش پیکربندی شده را ارائه میکند. این پیشنهادات را با قابلیتهای داخلی خود برای بهینهسازی خودکار فراپارامتر، مدلسازی مجموعه (برای مدلهای ارائهشده توسط Forecast)، و تولید پیشبینی احتمالی ترکیب میکند. این به شما امکان می دهد به راحتی مجموعه داده های سفارشی را دریافت کنید، داده ها را پیش پردازش کنید، مدل های پیش بینی را آموزش دهید و پیش بینی های قوی ایجاد کنید. طراحی مدولار این سرویس ما را قادر می سازد تا به راحتی پیش بینی های مدل های سفارشی اضافی را که به صورت موازی توسعه یافته اند، جستجو و ترکیب کنیم.
ما دو پیشبینیکننده عصبی را از Forecast ترکیب میکنیم: CNN-QR و DeepAR+. هر دو روش یادگیری عمیق تحت نظارت هستند که یک مدل جهانی را برای کل مجموعه داده سری زمانی آموزش می دهند. هر دو مدل CNNQR و DeepAR+ می توانند اطلاعات فراداده ایستا را در مورد هر سری زمانی که محصول، منطقه و سازمان تجاری مربوطه در مورد ما هستند، دریافت کنند. آنها همچنین به طور خودکار ویژگی های زمانی مانند ماه سال را به عنوان بخشی از ورودی به مدل اضافه می کنند.
ترانسفورماتور با ماسک های توجه برای COVID
معماری ترانسفورماتور (واسوانی و همکاران) که در اصل برای پردازش زبان طبیعی (NLP) طراحی شده بود، اخیراً به عنوان یک انتخاب معماری محبوب برای پیشبینی سریهای زمانی ظهور کرده است. در اینجا، ما از معماری Transformer که در آن توضیح داده شده است استفاده کردیم ژو و همکاران بدون توجه پراکنده ورود به سیستم احتمالی. این مدل از یک طراحی معماری معمولی با ترکیب یک رمزگذار و یک رمزگشا استفاده می کند. برای پیشبینی درآمد، ما رمزگشا را به گونهای پیکربندی میکنیم که بهجای تولید پیشبینی ماه به ماه به صورت خودبازگشت، پیشبینی افق 12 ماهه را مستقیماً خروجی دهد. بر اساس فراوانی سری های زمانی، ویژگی های مربوط به زمان اضافی مانند ماه سال به عنوان متغیر ورودی اضافه می شود. متغیرهای طبقهبندی اضافی که اطلاعات متا (محصول، منطقه، سازمان تجاری) را توصیف میکنند از طریق یک لایه تعبیهپذیر قابل آموزش به شبکه وارد میشوند.
نمودار زیر معماری ترانسفورماتور و مکانیسم پوشش توجه را نشان می دهد. پوشش توجه در تمام لایههای رمزگذار و رمزگشا اعمال میشود، همانطور که با رنگ نارنجی مشخص شده است، برای جلوگیری از تأثیر دادههای OOD بر پیشبینیها.

ما با افزودن ماسکهای توجه، تأثیر پنجرههای زمینه OOD را کاهش میدهیم. این مدل به گونهای آموزش دیده است که توجه بسیار کمی به دوره COVID که شامل موارد پرت از طریق پوشاندن است، اعمال کند و پیشبینی را با اطلاعات پوشانده انجام میدهد. ماسک توجه در تمام لایههای معماری رمزگشا و رمزگذار اعمال میشود. پنجره پوشانده شده را می توان به صورت دستی یا از طریق یک الگوریتم تشخیص بیرونی مشخص کرد. علاوه بر این، هنگام استفاده از یک پنجره زمانی حاوی مقادیر پرت به عنوان برچسبهای آموزشی، تلفات پس از انتشار باز نمیشوند. این روش مبتنی بر پوشاندن توجه را می توان برای رسیدگی به اختلالات و موارد OOD ناشی از سایر رویدادهای نادر و بهبود استحکام پیش بینی ها به کار برد.
مجموعه مدل
مجموعه مدل اغلب از مدلهای منفرد برای پیشبینی بهتر عمل میکند – تعمیمپذیری مدل را بهبود میبخشد و در مدیریت دادههای سری زمانی با ویژگیهای متفاوت در تناوب و متناوب بهتر است. ما مجموعه ای از استراتژی های مجموعه مدل را برای بهبود عملکرد مدل و استحکام پیش بینی ها ترکیب می کنیم. یکی از شکلهای رایج مجموعه مدلهای یادگیری عمیق، جمعآوری نتایج حاصل از اجرای مدل با مقادیر اولیه وزن تصادفی مختلف، یا دورههای آموزشی مختلف است. ما از این استراتژی برای به دست آوردن پیش بینی برای مدل ترانسفورماتور استفاده می کنیم.
برای ساخت بیشتر یک مجموعه بر روی معماریهای مدلهای مختلف، مانند Transformer، CNNQR، و DeepAR+، از یک استراتژی گروه پان-مدل استفاده میکنیم که بهترین مدلهای با بهترین عملکرد را برای هر سری زمانی بر اساس نتایج بکآست انتخاب میکند و آنها را به دست میآورد. میانگین ها از آنجایی که نتایج آزمون پشتیبان را میتوان مستقیماً از مدلهای Forecast آموزشدیده صادر کرد، این استراتژی ما را قادر میسازد تا از خدمات کلید در دست مانند Forecast با پیشرفتهایی که از مدلهای سفارشی مانند Transformer به دست میآید، بهره ببریم. چنین رویکرد مجموعه مدل سرتاسری نیازی به آموزش فراآموز یا محاسبه ویژگیهای سری زمانی برای انتخاب مدل ندارد.
آشتی سلسله مراتبی
این چارچوب برای ترکیب طیف وسیعی از تکنیکها به عنوان مراحل پسپردازش برای تطبیق پیشبینی سلسله مراتبی، از جمله از پایین به بالا (BU)، تطبیق از بالا به پایین با نسبتهای پیشبینی (TDFP)، حداقل مربع معمولی (OLS) و حداقل مربعات وزنی سازگار است. WLS). تمام نتایج تجربی در این پست با استفاده از تطبیق از بالا به پایین با نسبت های پیش بینی گزارش شده است.
نمای کلی معماری
ما یک گردش کار خودکار سرتاسر در AWS ایجاد کردیم تا با استفاده از خدماتی از جمله Forecast، SageMaker، پیشبینی درآمد ایجاد کنیم. سرویس ذخیره سازی ساده آمازون (Amazon S3) AWS لامبدا, توابع مرحله AWSو کیت توسعه ابری AWS (AWS CDK). راه حل مستقر شده پیش بینی های سری زمانی فردی را از طریق یک REST API با استفاده از ارائه می دهد دروازه API آمازون، با برگرداندن نتایج در قالب JSON از پیش تعریف شده.
نمودار زیر روند کار پیش بینی انتها به انتها را نشان می دهد.

ملاحظات کلیدی طراحی برای معماری تطبیق پذیری، عملکرد و کاربر پسند بودن است. این سیستم باید به اندازه کافی تطبیق پذیر باشد تا مجموعه متنوعی از الگوریتم ها را در طول توسعه و استقرار، با حداقل تغییرات مورد نیاز ترکیب کند، و می تواند به راحتی هنگام افزودن الگوریتم های جدید در آینده گسترش یابد. این سیستم همچنین باید حداقل سربار اضافه کند و از آموزش موازی برای Forecast و SageMaker پشتیبانی کند تا زمان آموزش کاهش یابد و آخرین پیش بینی سریعتر به دست آید. در نهایت، استفاده از سیستم برای اهداف آزمایشی باید ساده باشد.
گردش کار انتها به انتها به طور متوالی از طریق ماژول های زیر اجرا می شود:
- یک ماژول پیش پردازش برای قالب بندی مجدد داده ها و تبدیل
- یک ماژول آموزشی مدل که هر دو مدل Forecast و مدل سفارشی را در SageMaker ترکیب می کند (هر دو به صورت موازی اجرا می شوند)
- یک ماژول پس پردازش که از مجموعه مدل، تطبیق سلسله مراتبی، معیارها و تولید گزارش پشتیبانی می کند.
Step Functions گردش کار را از انتها به انتها به عنوان یک ماشین حالت سازماندهی و هماهنگ می کند. اجرای ماشین حالت با یک فایل JSON حاوی تمام اطلاعات لازم، از جمله مکان فایلهای CSV درآمد تاریخی در آمازون S3، زمان شروع پیشبینی، و تنظیمات فراپارامتر مدل برای اجرای گردش کار سرتاسر پیکربندی شده است. فراخوانی های ناهمزمان برای موازی سازی آموزش مدل در ماشین حالت با استفاده از توابع لامبدا ایجاد می شوند. تمام دادههای تاریخی، فایلهای پیکربندی، نتایج پیشبینی، و همچنین نتایج میانی مانند نتایج آزمایشهای برگشتی در آمازون S3 ذخیره میشوند. REST API بر روی Amazon S3 ساخته شده است تا یک رابط قابل پرس و جو برای جستجوی نتایج پیش بینی ارائه دهد. این سیستم را می توان برای ترکیب مدل های پیش بینی جدید و عملکردهای پشتیبانی مانند تولید گزارش های تجسم پیش بینی گسترش داد.
ارزیابی
در این بخش، تنظیمات آزمایش را به تفصیل شرح می دهیم. اجزای کلیدی شامل مجموعه داده، معیارهای ارزیابی، پنجرههای بکآست و راهاندازی و آموزش مدل است.
مجموعه داده
برای محافظت از حریم خصوصی مالی Bosch در حالی که از یک مجموعه داده معنادار استفاده میکنیم، از یک مجموعه داده مصنوعی استفاده کردیم که دارای ویژگیهای آماری مشابه با مجموعه دادههای درآمد واقعی از یک واحد تجاری در Bosch است. مجموعه داده در مجموع شامل 1,216 سری زمانی با درآمد ثبت شده در یک فرکانس ماهانه است که از ژانویه 2016 تا آوریل 2022 را پوشش می دهد. مجموعه داده با 877 سری زمانی در دانه بندی ترین سطح (سری های زمانی پایین)، با ساختار سری زمانی گروه بندی شده مربوطه ارائه می شود. به عنوان یک ماتریس جمع S. هر سری زمانی با سه ویژگی مقوله ای ایستا مرتبط است که مربوط به دسته محصول، منطقه و واحد سازمانی در مجموعه داده واقعی است (ناشناس در داده های مصنوعی).
معیارهای ارزیابی
برای ارزیابی عملکرد مدل و انجام تجزیه و تحلیل مقایسهای که معیارهای استاندارد مورد استفاده در بوش هستند، از خطای درصد مطلق آرکتانژانت میانه میانگین (متوسط-MAAPE) و وزنی-MAAPE استفاده میکنیم. MAAPE به کاستیهای معیار میانگین درصد خطای مطلق (MAPE) که معمولاً در زمینه کسبوکار استفاده میشود، میپردازد. Median-MAAPE یک نمای کلی از عملکرد مدل را با محاسبه میانه MAAPEها که به صورت جداگانه در هر سری زمانی محاسبه می شود، ارائه می دهد. Weighted-MAAPE ترکیب وزنی از MAAPEهای منفرد را گزارش می کند. وزن ها نسبت درآمد هر سری زمانی در مقایسه با درآمد کل مجموعه داده است. Weighted-MAAPE تأثیرات تجاری پایین دستی از دقت پیشبینی را بهتر منعکس میکند. هر دو معیار در کل مجموعه داده 1,216 سری زمانی گزارش شده است.
بک تست ویندوز
برای مقایسه عملکرد مدل از پنجره های بک تست 12 ماهه استفاده می کنیم. شکل زیر پنجرههای بکآست مورد استفاده در آزمایشها را نشان میدهد و دادههای مربوطه مورد استفاده برای آموزش و بهینهسازی هایپرپارامتر (HPO) را برجسته میکند. برای پنجرههای بکآست پس از شروع COVID-19، بر اساس آنچه از سری زمانی درآمد مشاهده کردیم، نتیجه تحت تأثیر ورودیهای OOD از آوریل تا مه 2020 قرار میگیرد.

راه اندازی و آموزش مدل
برای آموزش ترانسفورماتور، از تلفات کمی استفاده کردیم و هر سری زمانی را با استفاده از میانگین تاریخی آن، قبل از وارد کردن آن به ترانسفورماتور و محاسبه تلفات آموزشی، مقیاسبندی کردیم. پیشبینیهای نهایی برای محاسبه معیارهای دقت، با استفاده از MeanScaler پیادهسازی شده در GluonTS. ما از یک پنجره زمینه با دادههای درآمد ماهانه از 18 ماه گذشته استفاده میکنیم که از طریق HPO در پنجره بکآست از جولای 2018 تا ژوئن 2019 انتخاب شده است. فرادادههای اضافی درباره هر سری زمانی به شکل متغیرهای طبقهبندی ایستا از طریق یک جاسازی به مدل داده میشوند. قبل از تغذیه آن به لایه های ترانسفورماتور، لایه لایه کنید. ما ترانسفورماتور را با پنج مقدار اولیه وزن تصادفی مختلف آموزش میدهیم و میانگین نتایج پیشبینی از سه دوره آخر را برای هر اجرا، در مجموع به طور متوسط 15 مدل، میدهیم. برای کاهش زمان تمرین، می توان پنج دوره آموزشی مدل را موازی کرد. برای ترانسفورماتور ماسکدار، ماههای آوریل تا می ۲۰۲۰ را بهعنوان نقاط پرت نشان میدهیم.
برای تمام آموزشهای مدل Forecast، HPO خودکار را فعال کردهایم که میتواند مدل و پارامترهای آموزشی را بر اساس یک دوره بکآست مشخص شده توسط کاربر انتخاب کند که در پنجره داده مورد استفاده برای آموزش و HPO روی 12 ماه گذشته تنظیم شده است.
نتایج آزمایش
ما ترانسفورماتورهای نقابدار و بدون ماسک را با استفاده از مجموعه ای از فراپارامترها آموزش دادیم و عملکرد آنها را بلافاصله پس از شوک کووید-19 برای پنجره های بک تست مقایسه کردیم. در ترانسفورماتور ماسکدار، دو ماه ماسکدار آوریل و می 2020 هستند. جدول زیر نتایج مجموعهای از دورههای بکآزمایی با پنجرههای پیشبینی 12 ماهه را نشان میدهد که از ژوئن 2020 شروع میشود. .

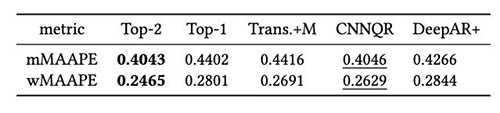
ما ارزیابی بیشتر بر روی استراتژی گروه مدل بر اساس نتایج بکآست انجام دادیم. به طور خاص، ما دو مورد را که فقط مدل با عملکرد برتر انتخاب میشود در مقابل زمانی که دو مدل برتر انتخاب میشوند، مقایسه میکنیم و میانگینگیری مدل با محاسبه مقدار میانگین پیشبینیها انجام میشود. عملکرد مدل های پایه و مدل های مجموعه را در شکل های زیر مقایسه می کنیم. توجه داشته باشید که هیچ یک از پیشبینیکنندههای عصبی بهطور پیوسته برای پنجرههای بکآستمون از دیگران بهتر عمل نمیکنند.


جدول زیر نشان می دهد که به طور متوسط، مدل سازی گروهی از دو مدل برتر بهترین عملکرد را ارائه می دهد. CNNQR دومین نتیجه برتر را ارائه می دهد.
نتیجه
این پست نشان می دهد که چگونه می توان یک راه حل ML سرتاسر برای مشکلات پیش بینی در مقیاس بزرگ با ترکیب Forecast و یک مدل سفارشی آموزش دیده در SageMaker ایجاد کرد. بسته به نیازهای تجاری و دانش ML خود، می توانید از یک سرویس کاملاً مدیریت شده مانند Forecast برای تخلیه فرآیند ساخت، آموزش و استقرار یک مدل پیش بینی استفاده کنید. مدل سفارشی خود را با مکانیسم های تنظیم خاص با SageMaker بسازید. یا با ترکیب این دو سرویس، مدل سازی را انجام دهید.
اگر برای تسریع استفاده از ML در محصولات و خدمات خود کمک میخواهید، لطفاً با شماره تماس بگیرید آزمایشگاه راه حل های آمازون ام ال برنامه است.
منابع
Hyndman RJ، Athanasopoulos G. Forecasting: اصول و عمل. OTexts; 2018 مه 8.
Vaswani A، Shazeer N، Parmar N، Uszkoreit J، Jones L، Gomez AN، Kaiser Ł، Polosukhin I. توجه شما تنها چیزی است که نیاز دارید. پیشرفت در سیستم های پردازش اطلاعات عصبی 2017؛ 30.
Zhou H، Zhang S، Peng J، Zhang S، Li J، Xiong H، Zhang W. Informer: فراتر از ترانسفورماتور کارآمد برای پیشبینی سریهای زمانی طولانی. InProceedings AAAI 2021 2 فوریه.
درباره نویسنده
 گوکتوگ چینار یک دانشمند برجسته ML و سرپرست فنی پیش بینی ML و آماری در Robert Bosch LLC و Bosch Center for Artificial Intelligence است. او تحقیقات مدلهای پیشبینی، تلفیق سلسله مراتبی، و تکنیکهای ترکیب مدل و همچنین تیم توسعه نرمافزار را رهبری میکند که این مدلها را مقیاسبندی کرده و آنها را به عنوان بخشی از نرمافزار پیشبینی مالی داخلی سرتاسر ارائه میکند.
گوکتوگ چینار یک دانشمند برجسته ML و سرپرست فنی پیش بینی ML و آماری در Robert Bosch LLC و Bosch Center for Artificial Intelligence است. او تحقیقات مدلهای پیشبینی، تلفیق سلسله مراتبی، و تکنیکهای ترکیب مدل و همچنین تیم توسعه نرمافزار را رهبری میکند که این مدلها را مقیاسبندی کرده و آنها را به عنوان بخشی از نرمافزار پیشبینی مالی داخلی سرتاسر ارائه میکند.
 مایکل بایندر مالک محصول در Bosch Global Services است، جایی که او توسعه، استقرار و اجرای برنامه تحلیل پیشبینی گسترده شرکت را برای پیشبینی خودکار دادههای مبتنی بر مقیاس بزرگ از ارقام کلیدی مالی هماهنگ میکند.
مایکل بایندر مالک محصول در Bosch Global Services است، جایی که او توسعه، استقرار و اجرای برنامه تحلیل پیشبینی گسترده شرکت را برای پیشبینی خودکار دادههای مبتنی بر مقیاس بزرگ از ارقام کلیدی مالی هماهنگ میکند.
 آدریان هوروات یک توسعهدهنده نرمافزار در مرکز هوش مصنوعی بوش است، جایی که سیستمهایی را برای ایجاد پیشبینیها بر اساس مدلهای پیشبینی مختلف توسعه و نگهداری میکند.
آدریان هوروات یک توسعهدهنده نرمافزار در مرکز هوش مصنوعی بوش است، جایی که سیستمهایی را برای ایجاد پیشبینیها بر اساس مدلهای پیشبینی مختلف توسعه و نگهداری میکند.
 پانپان خو یک دانشمند و مدیر ارشد کاربردی در آزمایشگاه راه حل های آمازون ML در AWS است. او در حال کار بر روی تحقیق و توسعه الگوریتمهای یادگیری ماشینی برای برنامههای کاربردی مشتری با تاثیر بالا در انواع عمودیهای صنعتی برای تسریع در پذیرش هوش مصنوعی و ابری آنها است. علاقه تحقیقاتی او شامل تفسیرپذیری مدل، تحلیل علی، هوش مصنوعی انسان در حلقه و تجسم داده های تعاملی است.
پانپان خو یک دانشمند و مدیر ارشد کاربردی در آزمایشگاه راه حل های آمازون ML در AWS است. او در حال کار بر روی تحقیق و توسعه الگوریتمهای یادگیری ماشینی برای برنامههای کاربردی مشتری با تاثیر بالا در انواع عمودیهای صنعتی برای تسریع در پذیرش هوش مصنوعی و ابری آنها است. علاقه تحقیقاتی او شامل تفسیرپذیری مدل، تحلیل علی، هوش مصنوعی انسان در حلقه و تجسم داده های تعاملی است.
 جاسلین گروال یک دانشمند کاربردی در خدمات وب آمازون است، جایی که او با مشتریان AWS برای حل مشکلات دنیای واقعی با استفاده از یادگیری ماشین، با تمرکز ویژه بر پزشکی دقیق و ژنومیک کار می کند. او پیشینه قوی در بیوانفورماتیک، انکولوژی و ژنومیک بالینی دارد. او علاقه زیادی به استفاده از AI/ML و خدمات ابری برای بهبود مراقبت از بیمار دارد.
جاسلین گروال یک دانشمند کاربردی در خدمات وب آمازون است، جایی که او با مشتریان AWS برای حل مشکلات دنیای واقعی با استفاده از یادگیری ماشین، با تمرکز ویژه بر پزشکی دقیق و ژنومیک کار می کند. او پیشینه قوی در بیوانفورماتیک، انکولوژی و ژنومیک بالینی دارد. او علاقه زیادی به استفاده از AI/ML و خدمات ابری برای بهبود مراقبت از بیمار دارد.
 سلوان سنتیول یک مهندس ارشد ML با آمازون ML Solutions Lab در AWS است که بر کمک به مشتریان در زمینه یادگیری ماشینی، مشکلات یادگیری عمیق و راهحلهای ML سرتاسر تمرکز دارد. او یکی از بنیانگذاران مهندسی آمازون Comprehend Medical بود و در طراحی و معماری چندین سرویس هوش مصنوعی AWS مشارکت داشت.
سلوان سنتیول یک مهندس ارشد ML با آمازون ML Solutions Lab در AWS است که بر کمک به مشتریان در زمینه یادگیری ماشینی، مشکلات یادگیری عمیق و راهحلهای ML سرتاسر تمرکز دارد. او یکی از بنیانگذاران مهندسی آمازون Comprehend Medical بود و در طراحی و معماری چندین سرویس هوش مصنوعی AWS مشارکت داشت.
 رویلین ژانگ یک SDE با آمازون ML Solutions Lab در AWS است. او با ایجاد راهحلهایی برای رفع مشکلات تجاری رایج، به مشتریان کمک میکند تا خدمات هوش مصنوعی AWS را اتخاذ کنند.
رویلین ژانگ یک SDE با آمازون ML Solutions Lab در AWS است. او با ایجاد راهحلهایی برای رفع مشکلات تجاری رایج، به مشتریان کمک میکند تا خدمات هوش مصنوعی AWS را اتخاذ کنند.
 شین رای Sr. ML استراتژیست با آمازون ML Solutions Lab در AWS است. او با مشتریان در طیف متنوعی از صنایع کار می کند تا مبرم ترین و مبتکرانه ترین نیازهای تجاری آنها را با استفاده از وسعت خدمات AI/ML مبتنی بر ابر AWS برطرف کند.
شین رای Sr. ML استراتژیست با آمازون ML Solutions Lab در AWS است. او با مشتریان در طیف متنوعی از صنایع کار می کند تا مبرم ترین و مبتکرانه ترین نیازهای تجاری آنها را با استفاده از وسعت خدمات AI/ML مبتنی بر ابر AWS برطرف کند.
 لین لی چئونگ یک مدیر علوم کاربردی با تیم آمازون ML Solutions Lab در AWS است. او با مشتریان استراتژیک AWS کار می کند تا هوش مصنوعی و یادگیری ماشینی را برای کشف بینش های جدید و حل مشکلات پیچیده کاوش و استفاده کند.
لین لی چئونگ یک مدیر علوم کاربردی با تیم آمازون ML Solutions Lab در AWS است. او با مشتریان استراتژیک AWS کار می کند تا هوش مصنوعی و یادگیری ماشینی را برای کشف بینش های جدید و حل مشکلات پیچیده کاوش و استفاده کند.