
Tämän viestin ovat kirjoittaneet Goktug Cinar, Michael Binder ja Adrian Horvath Bosch Center for Artificial Intelligencesta (BCAI).
Liikevaihdon ennustaminen on haastava mutta tärkeä tehtävä strategisissa liiketoimintapäätöksissä ja finanssisuunnittelussa useimmissa organisaatioissa. Talousanalyytikot tekevät tulojen ennustamisen usein manuaalisesti, ja se on sekä aikaa vievää että subjektiivista. Tällaiset manuaaliset toimet ovat erityisen haastavia suurille, monikansallisille yritysorganisaatioille, jotka vaativat tuloennusteita useille tuoteryhmille ja maantieteellisille alueille useilla eri tarkkuudella. Tämä edellyttää ennusteiden tarkkuuden lisäksi myös hierarkkista yhtenäisyyttä.
Bosch on monikansallinen yhtiö, jonka kokonaisuudet toimivat useilla sektoreilla, mukaan lukien autoteollisuus, teollisuusratkaisut ja kulutushyödykkeet. Kun otetaan huomioon tarkan ja johdonmukaisen tuloennusteen vaikutus terveeseen liiketoimintaan, Boschin tekoälykeskus (BCAI) on panostanut voimakkaasti koneoppimisen (ML) käyttöön parantaakseen taloussuunnitteluprosessien tehokkuutta ja tarkkuutta. Tavoitteena on keventää manuaalisia prosesseja tarjoamalla kohtuulliset lähtötason tuottoennusteet ML:n kautta, joihin toimiala- ja toimialaosaamistaan hyödyntävät talousanalyytikot tarvitsevat vain satunnaisia muutoksia.
Tämän tavoitteen saavuttamiseksi BCAI on kehittänyt sisäisen ennustekehyksen, joka pystyy tarjoamaan laajamittaisia hierarkkisia ennusteita useiden perusmallien mukautettujen ryhmien kautta. Metaoppija valitsee parhaiten suoriutuvat mallit kustakin aikasarjasta poimittujen ominaisuuksien perusteella. Valittujen mallien ennusteista lasketaan sitten keskiarvo, jotta saadaan koostettu ennuste. Arkkitehtoninen suunnittelu on modulaarinen ja laajennettavissa toteuttamalla REST-tyylinen käyttöliittymä, joka mahdollistaa jatkuvan suorituskyvyn parantamisen lisämalleja lisäämällä.
BCAI teki yhteistyötä Amazon ML Solutions Lab (MLSL), joka sisältää viimeisimmät edistysaskeleet syvän neuroverkkoon (DNN) perustuvissa malleissa tulojen ennustamiseen. Äskettäiset edistysaskeleet hermoennusteissa ovat osoittaneet huippuluokan suorituskyvyn monissa käytännön ennustamisongelmissa. Perinteisiin ennustemalleihin verrattuna monet neuroennustajat voivat sisällyttää aikasarjan kovariaatteja tai metatietoja. Mukana on CNN-QR ja DeepAR+, kaksi hyllystä valmistettua mallia Amazonin sääennuste, sekä mukautettu Transformer-malli, joka on koulutettu käyttämällä Amazon Sage Maker. Nämä kolme mallia kattavat edustavan joukon enkooderin runkoja, joita usein käytetään neuroennusteissa: konvoluutiohermoverkko (CNN), peräkkäinen toistuva hermoverkko (RNN) ja muuntajapohjaiset kooderit.
Yksi BCAI-MLSL-kumppanuuden keskeisistä haasteista oli tarjota vankkoja ja järkeviä ennusteita COVID-19:n vaikutukselle, joka on ennennäkemätön globaali tapahtuma, joka aiheuttaa suurta vaihtelua globaalien yritysten taloudellisissa tuloksissa. Koska hermosolujen ennustajat on koulutettu historiatietoihin, ennusteet, jotka on luotu epävakaampien ajanjaksojen jakelun ulkopuolisten tietojen perusteella, voivat olla epätarkkoja ja epäluotettavia. Siksi ehdotimme naamioituneen huomion mekanismin lisäämistä Transformer-arkkitehtuuriin tämän ongelman ratkaisemiseksi.
Neuraaliennusteet voidaan niputtaa yhdeksi kokonaisuudeksi malliksi tai liittää yksittäin Boschin mallimaailmaan, ja niitä voidaan käyttää helposti REST API -päätepisteiden kautta. Ehdotamme lähestymistapaa hermoennustajien yhdistämiseksi backtest-tulosten avulla, mikä tarjoaa kilpailukykyisen ja vankan suorituskyvyn ajan mittaan. Lisäksi tutkimme ja arvioimme useita klassisia hierarkkisia täsmäytystekniikoita varmistaaksemme, että ennusteet kootaan johdonmukaisesti tuoteryhmien, maantieteellisten alueiden ja liiketoimintaorganisaatioiden välillä.
Tässä viestissä esittelemme seuraavaa:
- Kuinka soveltaa Forecast- ja SageMaker mukautettua mallikoulutusta hierarkkisiin, laajamittaisiin aikasarjaennustusongelmiin
- Kuinka yhdistää mukautettuja malleja Forecastin valmiisiin malleihin
- Kuinka vähentää häiritsevien tapahtumien, kuten COVID-19, vaikutusta ennustamisongelmiin
- Kuinka rakentaa päästä päähän -ennustetyönkulku AWS:lle
Haasteet
Vastasimme kahteen haasteeseen: hierarkkisten, laajamittaisten tuloennusteiden luomiseen ja COVID-19-pandemian vaikutuksiin pitkän aikavälin ennusteisiin.
Hierarkkinen, laajamittainen tuloennuste
Talousanalyytikoiden tehtävänä on ennakoida keskeisiä taloudellisia lukuja, mukaan lukien tuotot, toimintakulut ja T&K-menot. Nämä mittarit tarjoavat näkemyksiä liiketoiminnan suunnittelusta eri tasoilla ja mahdollistavat tietopohjaisen päätöksenteon. Kaikkien automaattisten ennusteratkaisujen on tarjottava ennusteita mille tahansa liiketoimintalinjojen yhdistämisen tasolle. Boschilla aggregaatiot voidaan kuvitella ryhmiteltyinä aikasarjoina yleisempänä hierarkkisen rakenteen muotona. Seuraavassa kuvassa on yksinkertaistettu esimerkki, jossa on kaksitasoinen rakenne, joka jäljittelee Boschin hierarkkista tuloennusterakennetta. Kokonaistulot on jaettu useisiin eri tasoihin tuotteen ja alueen perusteella.
Boschilla ennustettavien aikasarjojen kokonaismäärä on miljoonien mittakaavassa. Huomaa, että ylimmän tason aikasarjat voidaan jakaa joko tuotteiden tai alueiden mukaan, jolloin luodaan useita polkuja alimman tason ennusteisiin. Tulot on ennustettava jokaisessa hierarkian solmussa 12 kuukauden ennustehorisontilla tulevaisuuteen. Kuukausittaiset historiatiedot ovat saatavilla.
Hierarkkinen rakenne voidaan esittää seuraavalla lomakkeella summausmatriisin merkinnällä S (Hyndman ja Athanasopoulos):
![]()
Tässä yhtälössä Y vastaa seuraavaa:

Täällä b edustaa alimman tason aikasarjaa hetkellä t.
COVID-19-pandemian vaikutukset
COVID-19-pandemia toi merkittäviä haasteita ennustamiseen, koska sillä on häiritseviä ja ennennäkemättömiä vaikutuksia lähes kaikkiin työ- ja yhteiskuntaelämän osa-alueisiin. Pitkän aikavälin liikevaihdon ennustamiseen häiriö toi myös odottamattomia loppupään vaikutuksia. Tämän ongelman havainnollistamiseksi seuraavassa kuvassa on esimerkkiaikasarja, jossa tuotetulot laskivat merkittävästi pandemian alussa ja palautuivat vähitellen sen jälkeen. Tyypillinen hermoennustemalli käyttää tulotietoja, mukaan lukien jakelun ulkopuolinen (OOD) COVID-kausi historiallisen kontekstin syötteenä, sekä mallikoulutuksen perustotuuksia. Tämän seurauksena tuotetut ennusteet eivät ole enää luotettavia.

Mallintamisen lähestymistavat
Tässä osiossa käsittelemme erilaisia mallinnusmenetelmiämme.
Amazonin sääennuste
Forecast on täysin hallittu AWS:n AI/ML-palvelu, joka tarjoaa esikonfiguroituja, huippuluokan aikasarjaennustemalleja. Se yhdistää nämä tarjoukset sisäisiin ominaisuuksiinsa automaattista hyperparametrien optimointia, ensemble-mallinnusta varten (Forecastin tarjoamille malleille) ja todennäköisyysennusteiden luomista varten. Tämän avulla voit helposti käyttää mukautettuja tietojoukkoja, esikäsitellä tietoja, kouluttaa ennustemalleja ja luoda vankkoja ennusteita. Palvelun modulaarisen rakenteen ansiosta voimme lisäksi helposti kysyä ja yhdistää ennusteita muista rinnakkain kehitetyistä mukautetuista malleista.
Sisältää kaksi Forecastin hermoennustetta: CNN-QR ja DeepAR+. Molemmat ovat valvottuja syväoppimismenetelmiä, jotka kouluttavat globaalin mallin koko aikasarjatietojoukolle. Sekä CNNQR- että DeepAR+-mallit voivat ottaa vastaan staattista metatietoa kustakin aikasarjasta, joka on meidän tapauksessamme vastaava tuote, alue ja liiketoimintaorganisaatio. Ne lisäävät myös automaattisesti ajallisia ominaisuuksia, kuten vuoden kuukauden, osana mallin syötettä.
Muuntaja huomiomaskeilla COVIDia varten
Transformer-arkkitehtuuri (Vaswani et ai.), joka alun perin suunniteltu luonnollisen kielen käsittelyyn (NLP), nousi äskettäin suosituksi arkkitehtoniseksi valinnaksi aikasarjaennusteissa. Tässä käytimme kohdassa kuvattua Transformer-arkkitehtuuria Zhou et ai. ilman todennäköisyyspohjaista puuhaa vähäistä huomiota. Mallissa käytetään tyypillistä arkkitehtuurisuunnittelua yhdistämällä kooderi ja dekooderi. Tulojen ennustamista varten määritämme dekooderin tulostamaan suoraan 12 kuukauden horisontin ennusteen sen sijaan, että se generoisi ennusteen kuukausittain automaattisesti regressiivisellä tavalla. Aikasarjan tiheyden perusteella syöttömuuttujaksi lisätään aikaan liittyviä lisäominaisuuksia, kuten vuoden kuukausi. Muut metatietoa kuvaavat kategorialliset muuttujat (tuote, alue, yritysorganisaatio) syötetään verkkoon koulutettavan upotuskerroksen kautta.
Seuraava kaavio havainnollistaa muuntajan arkkitehtuuria ja huomion peittomekanismia. Huomiopeitto on käytössä kaikissa enkooderi- ja dekooderitasoissa, kuten on korostettu oranssilla, jotta OOD-tiedot eivät vaikuta ennusteisiin.

Vähennämme OOD-kontekstiikkunoiden vaikutusta lisäämällä huomionaamioita. Malli on koulutettu kiinnittämään vain vähän huomiota COVID-jaksoon, joka sisältää poikkeavuuksia maskauksen kautta, ja se suorittaa ennusteen peitetyillä tiedoilla. Huomiomaski on käytössä kaikilla dekooderin ja enkooderin arkkitehtuurin kerroksilla. Maskattu ikkuna voidaan määrittää joko manuaalisesti tai poikkeamien havaitsemisalgoritmin avulla. Lisäksi, kun käytetään aikaikkunaa, joka sisältää poikkeavia arvoja koulutustunnisteina, häviöitä ei levitetä takaisin. Tällä huomion peittämiseen perustuvalla menetelmällä voidaan käsitellä muiden harvinaisten tapahtumien aiheuttamia häiriöitä ja OOD-tapauksia sekä parantaa ennusteiden luotettavuutta.
Mallikokonaisuus
Mallikokonaisuus päihittää usein yksittäiset mallit ennustamisessa – se parantaa mallin yleistettävyyttä ja käsittelee paremmin aikasarjatietoja, joiden jaksollisuus ja jaksottaisuus vaihtelevat. Sisällytämme sarjan mallikokonaisuusstrategioita parantaaksemme mallin suorituskykyä ja ennusteiden kestävyyttä. Yksi yleinen syväoppimismallikokonaisuuden muoto on koota tulokset malliajoista erilaisilla satunnaisten painojen alustoilla tai eri harjoittelujaksoilla. Käytämme tätä strategiaa saadaksemme ennusteita Transformer-mallille.
Rakentaaksemme kokonaisuutta eri malliarkkitehtuurien, kuten Transformerin, CNNQR:n ja DeepAR+:n päälle, käytämme yleismallikokonaisuusstrategiaa, joka valitsee kullekin aikasarjalle top k parhaiten suoriutuvaa mallia backtest-tulosten perusteella ja saa niiden tulokset. keskiarvot. Koska backtest-tulokset voidaan viedä suoraan koulutetuista Forecast-malleista, tämä strategia antaa meille mahdollisuuden hyödyntää avaimet käteen -palveluita, kuten Forecastia, mukautetuista malleista, kuten Transformerista, saatujen parannusten avulla. Tällainen kokonaisvaltainen mallikokonaisuus ei vaadi meta-oppijan kouluttamista tai aikasarjaominaisuuksien laskemista mallin valintaa varten.
Hierarkkinen sovitus
Kehys on mukautuva sisältämään laajan valikoiman tekniikoita hierarkkisen ennusteen täsmäytyksen jälkikäsittelyvaiheina, mukaan lukien alhaalta ylös (BU), ylhäältä alas täsmäytys ennustesuhteiden kanssa (TDFP), tavallinen pienimmän neliösumma (OLS) ja painotettu pienimmän neliösumman ( WLS). Kaikki tämän viestin kokeelliset tulokset raportoidaan käyttämällä ylhäältä alas -sovitusta ennustesuhteiden kanssa.
Arkkitehtuurin yleiskatsaus
Kehitimme AWS:lle automatisoidun päästä päähän -työnkulun tuottoennusteiden luomiseen käyttämällä palveluita, kuten Forecast, SageMaker, Amazonin yksinkertainen tallennuspalvelu (Amazon S3), AWS Lambda, AWS-vaihetoiminnotja AWS Cloud Development Kit (AWS CDK). Käyttöön otettu ratkaisu tarjoaa yksittäisiä aikasarjaennusteita REST API:n kautta käyttämällä Amazon API -yhdyskäytävä, palauttamalla tulokset ennalta määritetyssä JSON-muodossa.
Seuraava kaavio havainnollistaa päästä päähän -ennusteen työnkulkua.

Arkkitehtuurin tärkeimmät suunnittelunäkökohdat ovat monipuolisuus, suorituskyky ja käyttäjäystävällisyys. Järjestelmän tulee olla riittävän monipuolinen sisällyttääkseen erilaisia algoritmeja kehityksen ja käyttöönoton aikana minimaalisilla tarvittavilla muutoksilla, ja sitä voidaan helposti laajentaa lisättäessä uusia algoritmeja tulevaisuudessa. Järjestelmän tulisi myös lisätä vähimmäismäärää ja tukea rinnakkaista koulutusta sekä Forecastille että SageMakerille, jotta harjoitusaika lyhenisi ja uusin ennuste saadaan nopeammin. Lopuksi järjestelmän tulisi olla helppokäyttöinen kokeilutarkoituksiin.
Päästä päähän -työnkulku kulkee peräkkäin seuraavien moduulien läpi:
- Esikäsittelymoduuli tietojen uudelleenmuotoilua ja muuntamista varten
- Mallin koulutusmoduuli, joka sisältää sekä Forecast-mallin että mukautetun mallin SageMakerissa (molemmat toimivat rinnakkain)
- Jälkikäsittelymoduuli, joka tukee mallikokonaisuutta, hierarkkista täsmäytystä, mittareita ja raporttien luomista
Step Functions järjestää ja ohjaa työnkulun päästä päähän tilakoneena. Tilakoneen ajo on määritetty JSON-tiedostolla, joka sisältää kaikki tarvittavat tiedot, mukaan lukien historiallisten tulojen CSV-tiedostojen sijainnit Amazon S3:ssa, ennusteen alkamisaika ja mallin hyperparametriasetukset päästä päähän -työnkulun suorittamiseksi. Asynkroniset kutsut luodaan rinnakkain mallin harjoittelun tilakoneessa käyttämällä lambda-funktioita. Kaikki historialliset tiedot, konfigurointitiedostot, ennustetulokset sekä välitulokset, kuten jälkitestaustulokset, tallennetaan Amazon S3:een. REST API on rakennettu Amazon S3:n päälle, jotta se tarjoaa kyselyn mahdollistavan käyttöliittymän ennustetulosten kyselyyn. Järjestelmää voidaan laajentaa sisältämään uusia ennustemalleja ja tukitoimintoja, kuten ennusteen visualisointiraporttien luontia.
Arviointi
Tässä osiossa kerromme yksityiskohtaisesti kokeilun asetuksista. Keskeisiä komponentteja ovat tietojoukko, arviointimittarit, backtest-ikkunat sekä mallin asetukset ja koulutus.
aineisto
Suojellaksemme Boschin taloudellista yksityisyyttä, kun käytämme merkityksellistä tietojoukkoa, käytimme synteettistä tietojoukkoa, jolla on samanlaiset tilastolliset ominaisuudet kuin yhdestä Boschin liiketoimintayksiköstä peräisin olevalla todellisella tulotietojoukolla. Aineisto sisältää yhteensä 1,216 2016 aikasarjaa, joiden tulot kirjataan kuukausittain, ja ne kattavat tammikuun 2022 ja huhtikuun 877 välisen ajan. Aineisto toimitetaan XNUMX aikasarjalla kaikkein yksityiskohtaisimmalla tasolla (alempi aikasarja), jossa on edustettuna vastaava ryhmitelty aikasarjarakenne. summausmatriisina S. Jokaiseen aikasarjaan liittyy kolme staattista kategorista attribuuttia, jotka vastaavat tuoteluokkaa, aluetta ja organisaatioyksikköä todellisessa tietojoukossa (anonymisoituina synteettisissä tiedoissa).
Arviointitiedot
Käytämme mediaani-Mean Arctangent Absolute Percentage Error -virhettä (mediaani-MAAPE) ja painotettua-MAAPE:tä mallin suorituskyvyn arvioimiseen ja vertailevan analyysin tekemiseen, jotka ovat Boschin vakiomittareita. MAAPE korjaa liiketoiminnassa yleisesti käytetyn MAPE (Mean Absolute Percentage Error) -mittarin puutteet. Mediaani-MAAPE antaa yleiskatsauksen mallin toimivuudesta laskemalla kullekin aikasarjalle erikseen laskettujen MAAPE-arvojen mediaanin. Painotettu-MAAPE raportoi yksittäisten MAAPE:iden painotetun yhdistelmän. Painot ovat kunkin aikasarjan tuoton osuutta verrattuna koko tietojoukon yhteenlaskettuun tuottoon. Painotettu-MAAPE heijastaa paremmin ennusteen tarkkuuden loppupään liiketoimintavaikutuksia. Molemmat mittarit raportoidaan koko 1,216 XNUMX aikasarjan tietojoukosta.
Backtest ikkunat
Käytämme pyöriviä 12 kuukauden takatestiikkunoita mallien suorituskyvyn vertailuun. Seuraava kuva havainnollistaa kokeissa käytettyjä backtest-ikkunoita ja korostaa niitä vastaavat tiedot, joita käytetään koulutukseen ja hyperparametrien optimointiin (HPO). COVID-19:n alkamisen jälkeisten backtest-ikkunoiden tulokseen vaikuttavat OOD-syötteet huhti-toukokuussa 2020 tulojen aikasarjojen perusteella.

Mallin asennus ja koulutus
Transformer-koulutuksessa käytimme kvantiilihäviötä ja skaalattiin jokainen aikasarja käyttämällä sen historiallista keskiarvoa ennen sen syöttämistä Transformeriin ja harjoitushäviön laskemista. Lopulliset ennusteet skaalataan takaisin tarkkuusmittareiden laskemiseksi käyttäen MeanScaleria, joka on toteutettu GluonTS. Käytämme konteksti-ikkunaa, jossa on kuukausittaiset tulotiedot viimeiseltä 18 kuukaudelta, jotka on valittu HPO:n kautta backtest-ikkunassa heinäkuusta 2018 kesäkuuhun 2019. Jokaisesta aikasarjasta staattisten kategoristen muuttujien muodossa olevat lisämetatiedot syötetään malliin upotuksen kautta. kerros ennen kuin syötät sen muuntajakerroksiin. Harjoittelemme Transformeria viidellä eri satunnaisen painon alustuksella ja laskemme kunkin ajon kolmen viimeisen aikakauden ennustetulosten keskiarvon, yhteensä keskimäärin 15 mallia. Viisi malliharjoittelua voidaan rinnastaa harjoitusajan lyhentämiseksi. Naamioidun Transformerin osalta ilmoitamme kuukaudet huhtikuusta toukokuuhun 2020 poikkeavina kuukausina.
Kaikille Forecast-mallikoulutukselle otimme käyttöön automaattisen HPO:n, joka voi valita mallin ja harjoitusparametrit käyttäjän määrittämän backtest-jakson perusteella, joka on asetettu koulutukseen ja HPO:n tietoikkunaan viimeisten 12 kuukauden ajalle.
Kokeilutulokset
Koulutimme naamioituneita ja peittämättömiä muuntajia käyttämällä samoja hyperparametrijoukkoja ja vertailimme niiden suorituskykyä backtest-ikkunoissa välittömästi COVID-19-shokin jälkeen. Maskoidussa Transformerissa kaksi peitettyä kuukautta ovat huhti- ja toukokuu 2020. Seuraavassa taulukossa on tulokset sarjasta takatestausjaksoja, joissa on 12 kuukauden ennusteikkunat kesäkuusta 2020 alkaen. Voimme havaita, että maskattu Transformer on jatkuvasti tehokkaampi kuin peittämätön versio. .

Lisäksi suoritimme mallikokonaisuusstrategian arvioinnin taustatestien tulosten perusteella. Erityisesti vertaamme kahta tapausta, joissa valitaan vain tehokkain malli, ja kun valitaan kaksi tehokkainta mallia, ja mallin keskiarvo suoritetaan laskemalla ennusteiden keskiarvo. Vertailemme perusmallien ja kokonaisuusmallien suorituskykyä seuraavissa kuvissa. Huomaa, että yksikään hermoennusteista ei johdonmukaisesti suoriudu muita paremmin pyörivien backtest-ikkunoiden osalta.


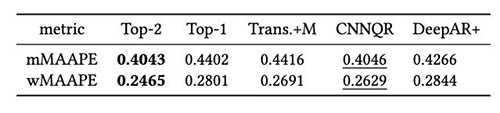
Seuraava taulukko osoittaa, että keskimäärin kahden parhaan mallin kokonaismallinnus antaa parhaan suorituskyvyn. CNNQR tarjoaa toiseksi parhaan tuloksen.
Yhteenveto
Tämä viesti osoitti, kuinka rakentaa päästä-päähän ML-ratkaisu laajamittaisiin ennustusongelmiin yhdistämällä Forecast ja mukautettu malli, joka on koulutettu SageMakerilla. Liiketoimintatarpeistasi ja ML-tiedoistasi riippuen voit käyttää täysin hallittua palvelua, kuten Forecast, ennustemallin rakennus-, koulutus- ja käyttöönottoprosessin purkamiseen. rakenna mukautettu mallisi erityisillä viritysmekanismeilla SageMakerin avulla; tai suorita mallien kokoonpano yhdistämällä nämä kaksi palvelua.
Jos haluat apua ML:n käytön nopeuttamiseen tuotteissasi ja palveluissasi, ota yhteyttä Amazon ML Solutions Lab ohjelma.
Viitteet
Hyndman RJ, Athanasopoulos G. Ennustaminen: periaatteet ja käytäntö. OTexts; 2018 toukokuuta 8.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Huomio on kaikki mitä tarvitset. Edistys neuroinformaation käsittelyjärjestelmissä. 2017;30.
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Informer: Beyond tehokas muuntaja pitkän sekvenssin aikasarjan ennustamiseen. InProceedings of AAAI 2021 2. helmikuuta.
Tietoja Tekijät
 Goktug Cinar on johtava ML-tutkija ja ML- ja tilastoihin perustuvan ennustamisen tekninen johtaja Robert Bosch LLC:ssä ja Bosch Center for Artificial Intelligence -keskuksessa. Hän johtaa ennustemallien, hierarkkisen konsolidoinnin ja mallien yhdistämistekniikoiden tutkimusta sekä ohjelmistokehitystiimiä, joka skaalaa nämä mallit ja palvelee niitä osana sisäistä päästä päähän talousennusteohjelmistoa.
Goktug Cinar on johtava ML-tutkija ja ML- ja tilastoihin perustuvan ennustamisen tekninen johtaja Robert Bosch LLC:ssä ja Bosch Center for Artificial Intelligence -keskuksessa. Hän johtaa ennustemallien, hierarkkisen konsolidoinnin ja mallien yhdistämistekniikoiden tutkimusta sekä ohjelmistokehitystiimiä, joka skaalaa nämä mallit ja palvelee niitä osana sisäistä päästä päähän talousennusteohjelmistoa.
 Michael Binder on tuotteen omistaja Bosch Global Servicesissä, missä hän koordinoi yrityksen laajuisen ennakoivan analytiikkasovelluksen kehitystä, käyttöönottoa ja käyttöönottoa taloudellisten tunnuslukujen laajamittaiseen automatisoituun datapohjaiseen ennustamiseen.
Michael Binder on tuotteen omistaja Bosch Global Servicesissä, missä hän koordinoi yrityksen laajuisen ennakoivan analytiikkasovelluksen kehitystä, käyttöönottoa ja käyttöönottoa taloudellisten tunnuslukujen laajamittaiseen automatisoituun datapohjaiseen ennustamiseen.
 Adrian Horváth on ohjelmistokehittäjä Bosch Center for Artificial Intelligence -keskuksessa, jossa hän kehittää ja ylläpitää järjestelmiä ennusteiden luomiseksi erilaisiin ennustemalleihin perustuen.
Adrian Horváth on ohjelmistokehittäjä Bosch Center for Artificial Intelligence -keskuksessa, jossa hän kehittää ja ylläpitää järjestelmiä ennusteiden luomiseksi erilaisiin ennustemalleihin perustuen.
 Panpan Xu on vanhempi soveltuva tutkija ja johtaja Amazon ML Solutions Labissa AWS:ssä. Hän työskentelee koneoppimisalgoritmien tutkimuksen ja kehittämisen parissa vaikuttaville asiakassovelluksille useilla eri teollisuudenaloilla nopeuttaakseen heidän tekoälyn ja pilven käyttöönottoa. Hänen tutkimuskohteenaan ovat mallien tulkittavuus, syy-analyysi, ihmissilmukan tekoäly ja interaktiivinen datan visualisointi.
Panpan Xu on vanhempi soveltuva tutkija ja johtaja Amazon ML Solutions Labissa AWS:ssä. Hän työskentelee koneoppimisalgoritmien tutkimuksen ja kehittämisen parissa vaikuttaville asiakassovelluksille useilla eri teollisuudenaloilla nopeuttaakseen heidän tekoälyn ja pilven käyttöönottoa. Hänen tutkimuskohteenaan ovat mallien tulkittavuus, syy-analyysi, ihmissilmukan tekoäly ja interaktiivinen datan visualisointi.
 Jasleen Grewal on soveltuva tutkija Amazon Web Services -palvelussa, jossa hän työskentelee AWS-asiakkaiden kanssa ratkaistakseen todellisen maailman ongelmia koneoppimisen avulla keskittyen erityisesti tarkkuuslääketieteeseen ja genomiikkaan. Hänellä on vahva tausta bioinformatiikasta, onkologiasta ja kliinisestä genomiikasta. Hän on intohimoinen AI/ML- ja pilvipalvelujen käyttämiseen potilaiden hoidon parantamiseen.
Jasleen Grewal on soveltuva tutkija Amazon Web Services -palvelussa, jossa hän työskentelee AWS-asiakkaiden kanssa ratkaistakseen todellisen maailman ongelmia koneoppimisen avulla keskittyen erityisesti tarkkuuslääketieteeseen ja genomiikkaan. Hänellä on vahva tausta bioinformatiikasta, onkologiasta ja kliinisestä genomiikasta. Hän on intohimoinen AI/ML- ja pilvipalvelujen käyttämiseen potilaiden hoidon parantamiseen.
 Selvan Senthivel on vanhempi ML-insinööri AWS:n Amazon ML Solutions Labissa, ja hän keskittyy auttamaan asiakkaita koneoppimisessa, syväoppimisongelmissa ja päästä päähän ML-ratkaisuissa. Hän oli Amazon Comprehend Medicalin perustajajohtaja ja osallistui useiden AWS AI -palveluiden suunnitteluun ja arkkitehtuuriin.
Selvan Senthivel on vanhempi ML-insinööri AWS:n Amazon ML Solutions Labissa, ja hän keskittyy auttamaan asiakkaita koneoppimisessa, syväoppimisongelmissa ja päästä päähän ML-ratkaisuissa. Hän oli Amazon Comprehend Medicalin perustajajohtaja ja osallistui useiden AWS AI -palveluiden suunnitteluun ja arkkitehtuuriin.
 Ruilin Zhang on SDE AWS:n Amazon ML Solutions Labin kanssa. Hän auttaa asiakkaita ottamaan käyttöön AWS AI -palveluita rakentamalla ratkaisuja yleisiin liiketoimintaongelmiin.
Ruilin Zhang on SDE AWS:n Amazon ML Solutions Labin kanssa. Hän auttaa asiakkaita ottamaan käyttöön AWS AI -palveluita rakentamalla ratkaisuja yleisiin liiketoimintaongelmiin.
 Shane Rai on vanhempi ML-strategi AWS:n Amazon ML Solutions Labissa. Hän työskentelee asiakkaiden kanssa useilla eri toimialoilla ratkaistakseen heidän kiireellisimmät ja innovatiivisimmat liiketoimintatarpeensa AWS:n pilvipohjaisten AI/ML-palvelujen avulla.
Shane Rai on vanhempi ML-strategi AWS:n Amazon ML Solutions Labissa. Hän työskentelee asiakkaiden kanssa useilla eri toimialoilla ratkaistakseen heidän kiireellisimmät ja innovatiivisimmat liiketoimintatarpeensa AWS:n pilvipohjaisten AI/ML-palvelujen avulla.
 Lin Lee Cheong on sovelletun tieteen johtaja Amazon ML Solutions Lab -tiimissä AWS:ssä. Hän työskentelee strategisten AWS-asiakkaiden kanssa tutkiakseen ja soveltaakseen tekoälyä ja koneoppimista löytääkseen uusia oivalluksia ja ratkaistakseen monimutkaisia ongelmia.
Lin Lee Cheong on sovelletun tieteen johtaja Amazon ML Solutions Lab -tiimissä AWS:ssä. Hän työskentelee strategisten AWS-asiakkaiden kanssa tutkiakseen ja soveltaakseen tekoälyä ja koneoppimista löytääkseen uusia oivalluksia ja ratkaistakseen monimutkaisia ongelmia.