
La formation de grands modèles de langage (LLM) avec des milliards de paramètres peut être difficile. En plus de concevoir l'architecture du modèle, les chercheurs doivent mettre en place des techniques de formation de pointe pour la formation distribuée, telles que le support de précision mixte, l'accumulation de gradient et les points de contrôle. Avec de grands modèles, la configuration de la formation est encore plus difficile car la mémoire disponible dans un seul accélérateur limite la taille des modèles formés en utilisant uniquement le parallélisme des données, et l'utilisation de la formation parallèle de modèles nécessite un niveau supplémentaire de modifications du code de formation. Les bibliothèques telles que Vitesse profonde (une bibliothèque d'optimisation d'apprentissage en profondeur open source pour PyTorch) relève certains de ces défis et peut aider à accélérer le développement et la formation de modèles.
Dans ce billet, nous avons mis en place une formation sur le processeur Intel Habana Gaudi Cloud de calcul élastique Amazon (Amazon EC2) DL1 instances et quantifier les avantages de l'utilisation d'un cadre de mise à l'échelle tel que DeepSpeed. Nous présentons les résultats de mise à l'échelle pour un modèle de transformateur de type codeur (BERT avec 340 millions à 1.5 milliard de paramètres). Pour le modèle à 1.5 milliard de paramètres, nous avons atteint une efficacité de mise à l'échelle de 82.7 % sur 128 accélérateurs (16 instances dl1.24xlarge) en utilisant DeepSpeed Zéro optimisations de l'étape 1. Les états de l'optimiseur ont été partitionnés par DeepSpeed pour entraîner de grands modèles à l'aide du paradigme parallèle des données. Cette approche a été étendue pour former un modèle de 5 milliards de paramètres en utilisant le parallélisme des données. Nous avons également utilisé la prise en charge native de Gaudi du type de données BF16 pour réduire la taille de la mémoire et augmenter les performances d'entraînement par rapport à l'utilisation du type de données FP32. En conséquence, nous avons atteint la convergence du modèle de pré-formation (phase 1) en 16 heures (notre objectif était de former un grand modèle en une journée) pour le modèle BERT à 1.5 milliard de paramètres en utilisant le ensemble de données wikicorpus-fr.
Configuration de la formation
Nous avons provisionné un cluster de calcul géré composé de 16 instances dl1.24xlarge à l'aide de Lot AWS. Nous avons développé un Atelier AWS Batch qui illustre les étapes de configuration du cluster de formation distribué avec AWS Batch. Chaque instance dl1.24xlarge dispose de huit accélérateurs Habana Gaudi, chacun avec 32 Go de mémoire et un réseau RoCE entièrement maillé entre les cartes avec une bande passante d'interconnexion bidirectionnelle totale de 700 Gbps chacune (voir Analyse approfondie des instances Amazon EC2 DL1 pour plus d'informations). Le cluster dl1.24xlarge utilisait également quatre Adaptateurs AWS Elastic Fabric (EFA), avec un total de 400 Gbps d'interconnexion entre les nœuds.
L'atelier de formation distribuée illustre les étapes de mise en place du cluster de formation distribuée. L'atelier présente la configuration de la formation distribuée à l'aide d'AWS Batch et, en particulier, la fonctionnalité de tâches parallèles multi-nœuds pour lancer des tâches de formation conteneurisées à grande échelle sur des clusters entièrement gérés. Plus précisément, un environnement de calcul AWS Batch entièrement géré est créé avec des instances DL1. Les conteneurs sont tirés de Registre des conteneurs élastiques Amazon (Amazon ECR) et lancé automatiquement dans les instances du cluster en fonction de la définition de tâche parallèle à plusieurs nœuds. L'atelier se termine par l'exécution d'une formation parallèle de données multi-nœuds et multi-HPU d'un modèle BERT (340 millions à 1.5 milliard de paramètres) utilisant PyTorch et DeepSpeed.
Pré-formation BERT 1.5B avec DeepSpeed
Habana SynapseAI v1.5 et v1.6 prend en charge les optimisations DeepSpeed ZeRO1. Le Fourche Habana du dépôt DeepSpeed GitHub comprend les modifications nécessaires pour supporter les accélérateurs Gaudi. Il existe une prise en charge complète des données distribuées parallèles (multi-cartes, multi-instances), des optimisations ZeRO1 et des types de données BF16.
Toutes ces fonctionnalités sont activées sur le Référentiel de référence du modèle BERT 1.5B, qui introduit un modèle d'encodeur bidirectionnel à 48 couches, 1600 dimensions cachées et 25 têtes, dérivé d'une implémentation BERT. Le référentiel contient également l'implémentation de base du modèle BERT Large : une architecture de réseau neuronal à 24 couches, 1024 16 masquées, 340 têtes et XNUMX millions de paramètres. Les scripts de modélisation de pré-formation sont dérivés du Référentiel d'exemples d'apprentissage en profondeur NVIDIA pour télécharger les données wikicorpus_en, prétraiter les données brutes en jetons et diviser les données en ensembles de données h5 plus petits pour un apprentissage parallèle des données distribuées. Vous pouvez adopter cette approche générique pour former vos architectures de modèles PyTorch personnalisées à l'aide de vos ensembles de données à l'aide d'instances DL1.
Résultats de la mise à l'échelle de la pré-formation (phase 1)
Pour la pré-formation de grands modèles à grande échelle, nous nous sommes principalement concentrés sur deux aspects de la solution : les performances de formation, mesurées par le temps de formation, et la rentabilité de l'obtention d'une solution entièrement convergée. Ensuite, nous approfondissons ces deux mesures avec la pré-formation BERT 1.5B comme exemple.
Mise à l'échelle des performances et du temps de formation
Nous commençons par mesurer les performances de l'implémentation BERT Large comme référence pour l'évolutivité. Le tableau suivant répertorie le débit mesuré des séquences par seconde à partir de 1 à 8 instances dl1.24xlarge (avec huit périphériques accélérateurs par instance). En utilisant le débit d'une seule instance comme référence, nous avons mesuré l'efficacité de la mise à l'échelle sur plusieurs instances, ce qui est un levier important pour comprendre la métrique de formation prix-performance.
| Nombre d'instances | Nombre d'accélérateurs | Séquences par seconde | Séquences par seconde par accélérateur | Efficacité de mise à l'échelle |
| 1 | 8 | 1,379.76 | 172.47 | 100.0% |
| 2 | 16 | 2,705.57 | 169.10 | 98.04% |
| 4 | 32 | 5,291.58 | 165.36 | 95.88% |
| 8 | 64 | 9,977.54 | 155.90 | 90.39% |
La figure suivante illustre l'efficacité de la mise à l'échelle.

Pour BERT 1.5B, nous avons modifié les hyperparamètres du modèle dans le référentiel de référence pour garantir la convergence. La taille de lot effective par accélérateur a été fixée à 384 (pour une utilisation maximale de la mémoire), avec des micro-lots de 16 par pas et 24 pas d'accumulation de gradient. Des taux d'apprentissage de 0.0015 et 0.003 ont été utilisés pour 8 et 16 nœuds, respectivement. Avec ces configurations, nous avons réalisé la convergence de la phase 1 de pré-formation de BERT 1.5B sur 8 instances dl1.24xlarge (64 accélérateurs) en environ 25 heures et 15 heures sur 16 instances dl1.24xlarge (128 accélérateurs). La figure suivante montre la perte moyenne en fonction du nombre d'époques d'entraînement, à mesure que nous augmentons le nombre d'accélérateurs.

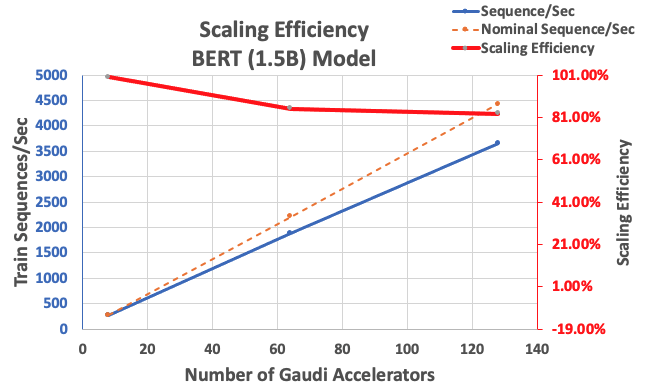
Avec la configuration décrite précédemment, nous avons obtenu une efficacité de mise à l'échelle forte de 85 % avec 64 accélérateurs et de 83 % avec 128 accélérateurs, à partir d'une base de référence de 8 accélérateurs dans une seule instance. Le tableau suivant résume les paramètres.
| Nombre d'instances | Nombre d'accélérateurs | Séquences par seconde | Séquences par seconde par accélérateur | Efficacité de mise à l'échelle |
| 1 | 8 | 276.66 | 34.58 | 100.0% |
| 8 | 64 | 1,883.63 | 29.43 | 85.1% |
| 16 | 128 | 3,659.15 | 28.59 | 82.7% |
La figure suivante illustre l'efficacité de la mise à l'échelle.
Conclusion
Dans cet article, nous avons évalué la prise en charge de DeepSpeed par Habana SynapseAI v1.5/v1.6 et comment cela aide à faire évoluer la formation LLM sur les accélérateurs Habana Gaudi. La pré-formation d'un modèle BERT de 1.5 milliard de paramètres a pris 16 heures pour converger sur un groupe de 128 accélérateurs Gaudi, avec une mise à l'échelle de 85 %. Nous vous encourageons à jeter un coup d'œil à l'architecture démontrée dans le Atelier AWS et envisagez de l'adopter pour former des architectures de modèles PyTorch personnalisées à l'aide d'instances DL1.
À propos des auteurs
 Mahadevan Balasubramaniam est un architecte principal de solutions pour l'informatique autonome avec près de 20 ans d'expérience dans le domaine de l'apprentissage approfondi basé sur la physique, de la construction et du déploiement de jumeaux numériques pour les systèmes industriels à grande échelle. Mahadevan a obtenu son doctorat en génie mécanique du Massachusetts Institute of Technology et a plus de 25 brevets et publications à son actif.
Mahadevan Balasubramaniam est un architecte principal de solutions pour l'informatique autonome avec près de 20 ans d'expérience dans le domaine de l'apprentissage approfondi basé sur la physique, de la construction et du déploiement de jumeaux numériques pour les systèmes industriels à grande échelle. Mahadevan a obtenu son doctorat en génie mécanique du Massachusetts Institute of Technology et a plus de 25 brevets et publications à son actif.
 RJ est un ingénieur de l'équipe Search M5 qui dirige les efforts de construction de systèmes d'apprentissage en profondeur à grande échelle pour la formation et l'inférence. En dehors du travail, il explore différentes cuisines culinaires et pratique des sports de raquette.
RJ est un ingénieur de l'équipe Search M5 qui dirige les efforts de construction de systèmes d'apprentissage en profondeur à grande échelle pour la formation et l'inférence. En dehors du travail, il explore différentes cuisines culinaires et pratique des sports de raquette.
 Sundar Ranganathan est le responsable du développement commercial, ML Frameworks au sein de l'équipe Amazon EC2. Il se concentre sur les charges de travail ML à grande échelle sur les services AWS comme Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch et Amazon SageMaker. Son expérience comprend des rôles de direction dans la gestion et le développement de produits chez NetApp, Micron Technology, Qualcomm et Mentor Graphics.
Sundar Ranganathan est le responsable du développement commercial, ML Frameworks au sein de l'équipe Amazon EC2. Il se concentre sur les charges de travail ML à grande échelle sur les services AWS comme Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch et Amazon SageMaker. Son expérience comprend des rôles de direction dans la gestion et le développement de produits chez NetApp, Micron Technology, Qualcomm et Mentor Graphics.
 Patni abhinandais est ingénieur logiciel senior chez Amazon Search. Il se concentre sur la construction de systèmes et d'outils pour la formation évolutive en apprentissage profond distribué et l'inférence en temps réel.
Patni abhinandais est ingénieur logiciel senior chez Amazon Search. Il se concentre sur la construction de systèmes et d'outils pour la formation évolutive en apprentissage profond distribué et l'inférence en temps réel.
 Pierre-Yves Aquilanti est responsable des solutions Frameworks ML chez Amazon Web Services, où il aide à développer les meilleures solutions de frameworks ML basées sur le cloud du secteur. Il a une formation en calcul haute performance et avant de rejoindre AWS, Pierre-Yves travaillait dans l'industrie pétrolière et gazière. Pierre-Yves est originaire de France et détient un doctorat. en Informatique de l'Université de Lille.
Pierre-Yves Aquilanti est responsable des solutions Frameworks ML chez Amazon Web Services, où il aide à développer les meilleures solutions de frameworks ML basées sur le cloud du secteur. Il a une formation en calcul haute performance et avant de rejoindre AWS, Pierre-Yves travaillait dans l'industrie pétrolière et gazière. Pierre-Yves est originaire de France et détient un doctorat. en Informatique de l'Université de Lille.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Financement EVM. Interface unifiée pour la finance décentralisée. Accéder ici.
- Groupe de médias quantiques. IR/PR amplifié. Accéder ici.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/accelerate-pytorch-with-deepspeed-to-train-large-language-models-with-intel-habana-gaudi-based-dl1-ec2-instances/