
Image par l'éditeur
Nous avons vu de grands modèles de langage (LLM) cracher chaque semaine, avec de plus en plus de chatbots à utiliser. Cependant, il peut être difficile de déterminer lequel est le meilleur, les progrès de chacun et lequel est le plus utile.
Étreindre a un classement Open LLM qui suit, évalue et classe les LLM au fur et à mesure de leur publication. Ils utilisent un cadre unique qui est utilisé pour tester des modèles de langage génératif sur différentes tâches d'évaluation.
Récemment, LLaMA (Large Language Model Meta AI) était en tête du classement et a récemment été détrôné par un nouveau LLM pré-formé - Falcon 40B.
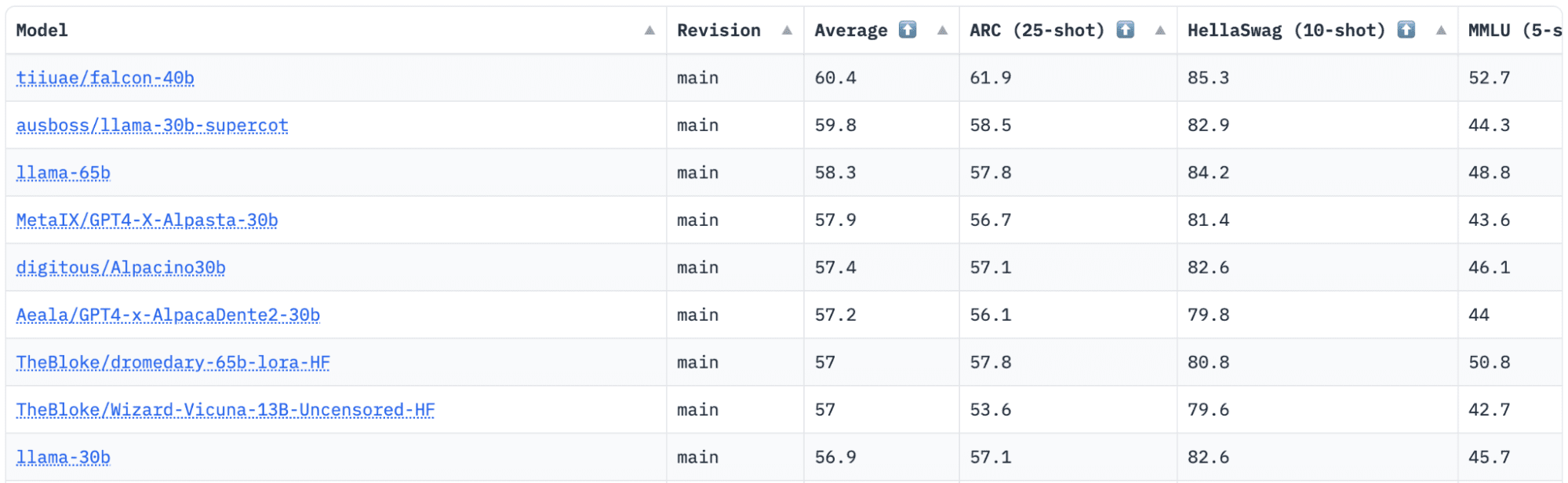
Image Classement Open LLM de HuggingFace
LLM Faucon a été fondée et construite par le Institut d'innovation technologique (TII), une entreprise qui fait partie du Conseil de recherche sur les technologies avancées du gouvernement d'Abu Dhabi. Le gouvernement supervise la recherche technologique dans l'ensemble des Émirats arabes unis, où l'équipe de scientifiques, de chercheurs et d'ingénieurs se concentre sur la fourniture de technologies transformatrices et de découvertes scientifiques.
Faucon-40B est un LLM fondamental avec des paramètres 40B, s'entraînant sur un billion de jetons. Le Falcon 40B est un modèle à décodeur autorégressif uniquement. Un modèle de décodeur autorégressif uniquement signifie que le modèle est formé pour prédire le jeton suivant dans une séquence compte tenu des jetons précédents. Le modèle GPT en est un bon exemple.
Il a été démontré que l'architecture de Falcon surpasse de manière significative GPT-3 pour seulement 75 % du budget de calcul de formation, et ne nécessite que ? du calcul au moment de l'inférence.
La qualité des données à grande échelle était un objectif important de l'équipe du Technology Innovation Institute, car nous savons que les LLM sont très sensibles à la qualité des données de formation. L'équipe a construit un pipeline de données qui s'est adapté à des dizaines de milliers de cœurs de processeur pour un traitement rapide et a pu extraire du contenu de haute qualité du Web à l'aide d'un filtrage et d'une déduplication étendus.
Ils ont aussi une autre version plus petite : Faucon-7B qui a des paramètres 7B, formés sur des jetons 1,500B. Ainsi qu'un Falcon-40B-Instruireet Falcon-7B-Instruire modèles disponibles, si vous recherchez un modèle de chat prêt à l'emploi.
Que peut faire le Falcon 40B ?
Semblable à d'autres LLM, le Falcon 40B peut :
- Générer du contenu créatif
- Résoudre des problèmes complexes
- Opérations de service à la clientèle
- Assistants virtuels
- Traduction
- Analyse des sentiments.
- Réduisez et automatisez le travail « répétitif ».
- Aider les entreprises émiraties à devenir plus efficaces
Comment le Falcon 40B a-t-il été entraîné ?
Entrainé sur 1 384 milliards de jetons, il a fallu 1,000 GPU sur AWS, sur deux mois. Formé sur XNUMX XNUMX milliards de jetons de Web raffiné, un énorme ensemble de données Web en anglais construit par TII.
Les données de pré-formation consistaient en une collecte de données publiques sur le Web, à l'aide de CommonCrawl. L'équipe a traversé une phase de filtrage approfondie pour supprimer le texte généré par la machine, et le contenu pour adultes ainsi que toute déduplication pour produire un ensemble de données de pré-formation de près de cinq billions de jetons a été assemblé.
Construit sur CommonCrawl, l'ensemble de données RefinedWeb a montré que les modèles atteignent de meilleures performances que les modèles formés sur des ensembles de données organisés. RefinedWeb est également compatible avec le multimodal.
Une fois prêt, Falcon a été validé par rapport à des références open source telles que EAI Harness, HELM et BigBench.
Ils ont Falcon LLM open source au public, rendant les Falcon 40B et 7B plus accessibles aux chercheurs et aux développeurs car ils sont basés sur la version 2.0 de la licence Apache.
Le LLM, qui était autrefois réservé à la recherche et à un usage commercial, est maintenant devenu open source pour répondre à la demande mondiale d'accès inclusif à l'IA. Il est désormais exempt de redevances pour les restrictions d'utilisation commerciale, car les Émirats arabes unis se sont engagés à modifier les défis et les frontières au sein de l'IA et comment elle jouera un rôle important à l'avenir.
Visant à cultiver un écosystème de collaboration, d'innovation et de partage des connaissances dans le monde de l'IA, Apache 2.0 garantit la sécurité et la sécurité des logiciels open source.
Si vous voulez essayer une version plus simple du Falcon-40B qui convient mieux aux instructions génériques dans le style d'un chatbot, vous voulez utiliser le Falcon-7B.
Alors, commençons…
Si vous ne l'avez pas déjà fait, installez les packages suivants :
!pip install transformers
!pip install einops
!pip install accelerate
!pip install xformers
Une fois que vous avez installé ces packages, vous pouvez ensuite passer à l'exécution du code fourni pour Instruction Falcon 7-B:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch model = "tiiuae/falcon-7b-instruct" tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline( "text-generation", model=model, tokenizer=tokenizer, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto",
)
sequences = pipeline( "Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.nDaniel: Hello, Girafatron!nGirafatron:", max_length=200, do_sample=True, top_k=10, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences: print(f"Result: {seq['generated_text']}")
Se tenant comme le meilleur modèle open-source disponible, Falcon a pris la couronne LLaMAs, et les gens sont étonnés de son architecture fortement optimisée, open-source avec une licence unique, et il est disponible en deux tailles : paramètres 40B et 7B.
Avez-vous essayé? Si vous en avez, faites-nous savoir dans les commentaires ce que vous en pensez.
Nisha Arya est Data Scientist, rédacteur technique indépendant et Community Manager chez KDnuggets. Elle est particulièrement intéressée à fournir des conseils de carrière en science des données ou des tutoriels et des connaissances théoriques sur la science des données. Elle souhaite également explorer les différentes façons dont l'intelligence artificielle est/peut bénéficier à la longévité de la vie humaine. Une apprenante passionnée, cherchant à élargir ses connaissances techniques et ses compétences en écriture, tout en aidant à guider les autres.
En savoir plus sur ce sujet
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Financement EVM. Interface unifiée pour la finance décentralisée. Accéder ici.
- Groupe de médias quantiques. IR/PR amplifié. Accéder ici.
- PlatoAiStream. Intelligence des données Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.kdnuggets.com/2023/06/falcon-llm-new-king-llms.html?utm_source=rss&utm_medium=rss&utm_campaign=falcon-llm-the-new-king-of-open-source-llms
Falcon LLM : le nouveau roi des LLM open source - KDnuggets
Republié par Platon
Image par l'éditeur
Nous avons vu de grands modèles de langage (LLM) cracher chaque semaine, avec de plus en plus de chatbots à utiliser. Cependant, il peut être difficile de déterminer lequel est le meilleur, les progrès de chacun et lequel est le plus utile.
Étreindre a un classement Open LLM qui suit, évalue et classe les LLM au fur et à mesure de leur publication. Ils utilisent un cadre unique qui est utilisé pour tester des modèles de langage génératif sur différentes tâches d'évaluation.
Récemment, LLaMA (Large Language Model Meta AI) était en tête du classement et a récemment été détrôné par un nouveau LLM pré-formé - Falcon 40B.
Image Classement Open LLM de HuggingFace
LLM Faucon a été fondée et construite par le Institut d'innovation technologique (TII), une entreprise qui fait partie du Conseil de recherche sur les technologies avancées du gouvernement d'Abu Dhabi. Le gouvernement supervise la recherche technologique dans l'ensemble des Émirats arabes unis, où l'équipe de scientifiques, de chercheurs et d'ingénieurs se concentre sur la fourniture de technologies transformatrices et de découvertes scientifiques.
Faucon-40B est un LLM fondamental avec des paramètres 40B, s'entraînant sur un billion de jetons. Le Falcon 40B est un modèle à décodeur autorégressif uniquement. Un modèle de décodeur autorégressif uniquement signifie que le modèle est formé pour prédire le jeton suivant dans une séquence compte tenu des jetons précédents. Le modèle GPT en est un bon exemple.
Il a été démontré que l'architecture de Falcon surpasse de manière significative GPT-3 pour seulement 75 % du budget de calcul de formation, et ne nécessite que ? du calcul au moment de l'inférence.
La qualité des données à grande échelle était un objectif important de l'équipe du Technology Innovation Institute, car nous savons que les LLM sont très sensibles à la qualité des données de formation. L'équipe a construit un pipeline de données qui s'est adapté à des dizaines de milliers de cœurs de processeur pour un traitement rapide et a pu extraire du contenu de haute qualité du Web à l'aide d'un filtrage et d'une déduplication étendus.
Ils ont aussi une autre version plus petite : Faucon-7B qui a des paramètres 7B, formés sur des jetons 1,500B. Ainsi qu'un Falcon-40B-Instruireet Falcon-7B-Instruire modèles disponibles, si vous recherchez un modèle de chat prêt à l'emploi.
Que peut faire le Falcon 40B ?
Semblable à d'autres LLM, le Falcon 40B peut :
Comment le Falcon 40B a-t-il été entraîné ?
Entrainé sur 1 384 milliards de jetons, il a fallu 1,000 GPU sur AWS, sur deux mois. Formé sur XNUMX XNUMX milliards de jetons de Web raffiné, un énorme ensemble de données Web en anglais construit par TII.
Les données de pré-formation consistaient en une collecte de données publiques sur le Web, à l'aide de CommonCrawl. L'équipe a traversé une phase de filtrage approfondie pour supprimer le texte généré par la machine, et le contenu pour adultes ainsi que toute déduplication pour produire un ensemble de données de pré-formation de près de cinq billions de jetons a été assemblé.
Construit sur CommonCrawl, l'ensemble de données RefinedWeb a montré que les modèles atteignent de meilleures performances que les modèles formés sur des ensembles de données organisés. RefinedWeb est également compatible avec le multimodal.
Une fois prêt, Falcon a été validé par rapport à des références open source telles que EAI Harness, HELM et BigBench.
Ils ont Falcon LLM open source au public, rendant les Falcon 40B et 7B plus accessibles aux chercheurs et aux développeurs car ils sont basés sur la version 2.0 de la licence Apache.
Le LLM, qui était autrefois réservé à la recherche et à un usage commercial, est maintenant devenu open source pour répondre à la demande mondiale d'accès inclusif à l'IA. Il est désormais exempt de redevances pour les restrictions d'utilisation commerciale, car les Émirats arabes unis se sont engagés à modifier les défis et les frontières au sein de l'IA et comment elle jouera un rôle important à l'avenir.
Visant à cultiver un écosystème de collaboration, d'innovation et de partage des connaissances dans le monde de l'IA, Apache 2.0 garantit la sécurité et la sécurité des logiciels open source.
Si vous voulez essayer une version plus simple du Falcon-40B qui convient mieux aux instructions génériques dans le style d'un chatbot, vous voulez utiliser le Falcon-7B.
Alors, commençons…
Si vous ne l'avez pas déjà fait, installez les packages suivants :
Une fois que vous avez installé ces packages, vous pouvez ensuite passer à l'exécution du code fourni pour Instruction Falcon 7-B:
Se tenant comme le meilleur modèle open-source disponible, Falcon a pris la couronne LLaMAs, et les gens sont étonnés de son architecture fortement optimisée, open-source avec une licence unique, et il est disponible en deux tailles : paramètres 40B et 7B.
Avez-vous essayé? Si vous en avez, faites-nous savoir dans les commentaires ce que vous en pensez.
Nisha Arya est Data Scientist, rédacteur technique indépendant et Community Manager chez KDnuggets. Elle est particulièrement intéressée à fournir des conseils de carrière en science des données ou des tutoriels et des connaissances théoriques sur la science des données. Elle souhaite également explorer les différentes façons dont l'intelligence artificielle est/peut bénéficier à la longévité de la vie humaine. Une apprenante passionnée, cherchant à élargir ses connaissances techniques et ses compétences en écriture, tout en aidant à guider les autres.
En savoir plus sur ce sujet
MetaMask et Crypto Tax Calculator s'associent pour sauver les investisseurs en crypto cette saison fiscale
Meilleurs joueurs disponibles pour la deuxième journée du repêchage de la NFL 3
Litecoin évolue dans une fourchette en raison de l'ambivalence des commerçants
Alien : Rogue Incursion arrive sur Quest 3, PSVR 2 et PC VR
"Alien: Rogue Incursion" enfin annoncé par Veteran VR Studio, prévu pour fin 2024
Stripe réintègre le marché des paiements cryptographiques avec le stablecoin USDC – Tech Startups
Les 10 plus gros cycles de financement de la semaine : Xaira et d'autres startups d'IA ont une semaine énorme
Anxiété liée à la gamme EV : tout est vraiment dans votre esprit – CleanTechnica