
Ezt a bejegyzést Goktug Cinar, Michael Binder és Adrian Horvath társírók, a Bosch Center for Artificial Intelligence (BCAI) munkatársai.
A bevétel-előrejelzés a legtöbb szervezetben kihívást jelentő, de kulcsfontosságú feladat a stratégiai üzleti döntések és a költségvetési tervezés során. A bevétel-előrejelzést gyakran manuálisan végzik pénzügyi elemzők, és egyszerre időigényes és szubjektív. Az ilyen manuális erőfeszítések különösen nagy kihívást jelentenek a nagyszabású, multinacionális üzleti szervezetek számára, amelyek bevétel-előrejelzéseket igényelnek a termékcsoportok és földrajzi területek széles skálájára vonatkozóan, több részletességi szinten. Ehhez nemcsak pontosságra van szükség, hanem az előrejelzések hierarchikus koherenciájára is.
Bosch egy multinacionális vállalat, amely számos ágazatban tevékenykedik, beleértve az autógyártást, az ipari megoldásokat és a fogyasztási cikkeket. Tekintettel a pontos és koherens bevétel-előrejelzésnek az egészséges üzleti működésre gyakorolt hatására, a Bosch Mesterséges Intelligencia Központ A BCAI jelentős összegeket fektet be a gépi tanulás (ML) használatába, hogy javítsa a pénzügyi tervezési folyamatok hatékonyságát és pontosságát. A cél a manuális folyamatok enyhítése azáltal, hogy ML-en keresztül ésszerű alapbevételi előrejelzéseket adunk, és csak alkalmanként van szükség a pénzügyi elemzőknek az iparági és területi ismereteiket használó korrekciókra.
E cél elérése érdekében a BCAI kifejlesztett egy belső előrejelzési keretrendszert, amely képes nagy léptékű hierarchikus előrejelzéseket biztosítani számos alapmodell testreszabott együttesein keresztül. A metatanuló az egyes idősorokból kinyert jellemzők alapján választja ki a legjobban teljesítő modelleket. A kiválasztott modellek előrejelzései ezután átlagolódnak az összesített előrejelzés elkészítéséhez. Az építészeti tervezés modularizált és bővíthető egy REST-stílusú interfész megvalósításával, amely további modellek bevonásával lehetővé teszi a teljesítmény folyamatos javítását.
A BCAI együttműködött a Amazon ML Solutions Lab (MLSL), hogy beépítsék a mély neurális hálózaton (DNN) alapuló bevétel-előrejelzési modellek legújabb fejlesztéseit. A neurális előrejelzők legújabb fejlesztései számos gyakorlati előrejelzési probléma legkorszerűbb teljesítményét mutatták be. A hagyományos előrejelzési modellekhez képest sok neurális előrejelző képes beépíteni az idősorok további kovariánsait vagy metaadatait. A CNN-QR és a DeepAR+ két készen kapható modellt tartalmaz Amazon előrejelzés, valamint egy egyedi Transzformátor-modell, amely segítségével betanították Amazon SageMaker. A három modell a neurális előrejelzőkben gyakran használt kódoló gerinchálózatok reprezentatív készletét fedi le: konvolúciós neurális hálózat (CNN), szekvenciális visszatérő neurális hálózat (RNN) és transzformátor alapú kódolók.
Az egyik legfontosabb kihívás, amellyel a BCAI-MLSL partnerség szembesült, az volt, hogy megbízható és ésszerű előrejelzéseket adjon a COVID-19 hatása alatt, amely példa nélküli globális esemény, amely nagy ingadozást okoz a globális vállalati pénzügyi eredményekben. Mivel a neurális előrejelzők előzményadatokon vannak kiképezve, a volatilisabb időszakokból származó eloszláson kívüli adatok alapján generált előrejelzések pontatlanok és megbízhatatlanok lehetnek. Ezért javasoltuk egy maszkolt figyelemmechanizmus hozzáadását a Transformer architektúrához a probléma megoldására.
A neurális előrejelzők egyetlen együttes modellként csomagolhatók, vagy külön-külön is beépíthetők a Bosch modell-univerzumába, és könnyen elérhetők a REST API-végpontokon keresztül. Olyan megközelítést javasolunk a neurális előrejelzők összeállítására, amelyek utólagos tesztek eredményein keresztül versenyképesek és robusztus teljesítményt nyújtanak az idő múlásával. Ezenkívül számos klasszikus hierarchikus egyeztetési technikát megvizsgáltunk és értékeltünk annak biztosítására, hogy az előrejelzések koherensen aggregálódjanak a termékcsoportok, földrajzi területek és üzleti szervezetek között.
Ebben a bejegyzésben a következőket mutatjuk be:
- Az előrejelzés és a SageMaker egyéni modellképzés alkalmazása hierarchikus, nagy léptékű idősoros előrejelzési problémákra
- Hogyan lehet egyedi modelleket kombinálni kész modellekkel az előrejelzésből
- Hogyan csökkenthetjük a zavaró események, például a COVID-19 előrejelzési problémákra gyakorolt hatását
- Végpontok közötti előrejelzési munkafolyamat felépítése AWS-en
Kihívások
Két kihívással foglalkoztunk: hierarchikus, nagy léptékű bevétel-előrejelzés létrehozásával, valamint a COVID-19 világjárvány hosszú távú előrejelzésekre gyakorolt hatásával.
Hierarchikus, nagy léptékű bevétel-előrejelzés
A pénzügyi elemzők feladata a legfontosabb pénzügyi adatok előrejelzése, beleértve a bevételeket, a működési költségeket és a K+F kiadásokat. Ezek a mutatók üzleti tervezési betekintést nyújtanak az összesítés különböző szintjein, és lehetővé teszik az adatvezérelt döntéshozatalt. Minden automatizált előrejelzési megoldásnak előrejelzéseket kell biztosítania az üzletági összesítés tetszőleges szintjén. A Boschnál az aggregációkat csoportosított idősorokként képzelhetjük el, mint a hierarchikus struktúra általánosabb formáját. A következő ábra egy egyszerűsített példát mutat be kétszintű szerkezettel, amely a Bosch hierarchikus bevétel-előrejelzési struktúráját utánozza. A teljes bevétel több szintű aggregációra van felosztva termék és régió alapján.
A Boschnál előrejelezni kívánt idősorok teljes száma milliós léptékű. Figyelje meg, hogy a legfelső szintű idősorok akár termékek, akár régiók szerint oszthatók fel, így több útvonal is létrehozható az alsó szintű előrejelzésekhez. A bevételt a hierarchia minden csomópontjában előre kell jelezni, 12 hónapos előrejelzési horizonttal. Havi előzményadatok állnak rendelkezésre.
A hierarchikus struktúra az alábbi űrlap segítségével ábrázolható összegző mátrix jelölésével S (Hyndman és Athanasopoulos):
![]()
Ebben az egyenletben Y egyenlő a következővel:

Itt, b a legalacsonyabb szintű idősort jelenti időben t.
A COVID-19 világjárvány hatásai
A COVID-19 világjárvány jelentős kihívásokat támasztott az előrejelzések terén a munka és a társadalmi élet szinte minden területére kifejtett bomlasztó és példátlan hatásai miatt. A bevételek hosszú távú előrejelzése szempontjából a zavar váratlan downstream hatásokat is hozott. Ennek a problémának a szemléltetésére a következő ábra egy mintaidősort mutat be, ahol a termékbevétel jelentősen csökkent a világjárvány kezdetén, majd fokozatosan helyreállt. Egy tipikus neurális előrejelzési modell a bevételi adatokat, beleértve az elosztáson kívüli (OOD) COVID-időszakot is, mint történelmi kontextus bemenetet, valamint a modellképzés alapjait veszi figyelembe. Ennek eredményeként az elkészített előrejelzések már nem megbízhatóak.

Modellezési megközelítések
Ebben a részben a különféle modellezési megközelítéseinket tárgyaljuk.
Amazon előrejelzés
A Forecast egy teljesen felügyelt AI/ML szolgáltatás az AWS-től, amely előre konfigurált, korszerű idősoros előrejelzési modelleket biztosít. Ezeket az ajánlatokat egyesíti az automatizált hiperparaméter-optimalizáláshoz, az együttes modellezéshez (a Forecast által biztosított modellekhez) és a valószínűségi előrejelzés generálásához szükséges belső képességekkel. Ez lehetővé teszi az egyéni adatkészletek egyszerű feldolgozását, az adatok előfeldolgozását, az előrejelzési modellek betanítását és a robusztus előrejelzések létrehozását. A szolgáltatás moduláris felépítése lehetővé teszi továbbá, hogy egyszerűen lekérdezzünk és kombináljunk előrejelzéseket további, párhuzamosan fejlesztett egyedi modellekből.
A Forecast két neurális előrejelzőt tartalmaz: CNN-QR és DeepAR+. Mindkettő felügyelt mély tanulási módszer, amely a teljes idősor-adatkészlet globális modelljét képezi. Mind a CNNQR, mind a DeepAR+ modell képes statikus metaadat-információkat fogadni az egyes idősorokról, amelyek esetünkben a megfelelő termék, régió és üzleti szervezet. Automatikusan hozzáadnak olyan időbeli jellemzőket is, mint az év hónapja a modell bevitelének részeként.
Transzformátor figyelemfelkeltő maszkokkal a COVID-hoz
A Transformer architektúra (Vaswani et al.), amelyet eredetileg természetes nyelvi feldolgozásra (NLP) terveztek, a közelmúltban az idősoros előrejelzés népszerű építészeti választásává vált. Itt a leírt Transformer architektúrát használtuk Zhou et al. valószínűségi log ritka figyelem nélkül. A modell egy tipikus architektúra-tervet használ egy kódoló és egy dekódoló kombinálásával. A bevétel-előrejelzéshez úgy konfiguráljuk a dekódert, hogy közvetlenül a 12 hónapos horizont előrejelzését adja ki, ahelyett, hogy hónapról hónapra generálná az előrejelzést autoregresszív módon. Az idősorok gyakorisága alapján további időhöz kapcsolódó jellemzők, például az év hónapja adódnak hozzá bemeneti változóként. A metainformációt leíró további kategorikus változók (termék, régió, üzleti szervezet) egy betanítható beágyazási rétegen keresztül kerülnek a hálózatba.
A következő ábra a Transformer architektúrát és a figyelemmaszkolási mechanizmust szemlélteti. A figyelem maszkolása az összes kódoló és dekódoló rétegben narancssárga színnel van kiemelve, hogy megakadályozza, hogy az OOD adatok befolyásolják az előrejelzéseket.

Figyelemmaszkok hozzáadásával mérsékeljük az OOD környezeti ablakok hatását. A modell arra van kiképezve, hogy nagyon kevés figyelmet fordítson a COVID-időszakra, amely maszkoláson keresztül kiugró értékeket tartalmaz, és maszkolt információkkal végez előrejelzést. A figyelemmaszk a dekóder és a kódoló architektúra minden rétegében megtalálható. A maszkolt ablak megadható manuálisan vagy egy outlier-észlelési algoritmuson keresztül. Ezenkívül, ha olyan időablakot használ, amely kiugró értékeket tartalmaz képzési címkékként, a veszteségek nem terjednek vissza. Ez a figyelemmaszkoláson alapuló módszer alkalmazható más ritka események által okozott zavarok és OOD esetek kezelésére, és javíthatja az előrejelzések robusztusságát.
Modell együttes
A modellegyüttes gyakran felülmúlja az egyes modelleket az előrejelzésben – javítja a modell általánosíthatóságát, és jobban kezeli a változó periodicitású és időszakos jellemzőkkel rendelkező idősoradatokat. Számos modellegyüttes stratégiát építünk be a modell teljesítményének és az előrejelzések robusztusságának javítása érdekében. A mély tanulási modell-együttes egyik gyakori formája a különböző véletlenszerű súlyozási inicializálásokkal vagy különböző képzési korszakokból származó modellfutások eredményeinek összesítése. Ezt a stratégiát használjuk a Transformer modellre vonatkozó előrejelzések készítésére.
A különböző modellarchitektúrák (például Transformer, CNNQR és DeepAR+) továbbépítéséhez egy pánmodell-együttes stratégiát használunk, amely a visszateszt eredményei alapján kiválasztja az egyes idősorokhoz a legjobb k legjobban teljesítő modellt, és megkapja azok eredményeit. átlagok. Mivel az utólagos tesztek eredményei közvetlenül exportálhatók a betanított Forecast modellekből, ez a stratégia lehetővé teszi számunkra, hogy kihasználjuk a kulcsrakész szolgáltatások, például a Forecast előnyeit az egyéni modellekből, például a Transformerből származó fejlesztésekkel. Az ilyen végpontok közötti modellegyüttes megközelítés nem igényel metatanuló képzését vagy idősor-jellemzők kiszámítását a modell kiválasztásához.
Hierarchikus egyeztetés
A keretrendszer alkalmazkodik ahhoz, hogy a hierarchikus előrejelzési egyeztetés utófeldolgozási lépéseiként a technikák széles skáláját beépítse, beleértve az alulról felfelé (BU), az előrejelzési arányokkal felülről lefelé történő egyeztetést (TDFP), a közönséges legkisebb négyzetet (OLS) és a súlyozott legkisebb négyzetet ( WLS). Az ebben a bejegyzésben szereplő összes kísérleti eredmény felülről lefelé történő egyeztetéssel és előrejelzési arányokkal került jelentésre.
Építészeti áttekintés
Automatizált, teljes körű munkafolyamatot fejlesztettünk ki az AWS-en, hogy bevétel-előrejelzéseket készítsünk olyan szolgáltatások felhasználásával, mint a Forecast, a SageMaker, Amazon egyszerű tárolási szolgáltatás (Amazon S3), AWS Lambda, AWS lépésfunkciókés AWS Cloud Development Kit (AWS CDK). A telepített megoldás egyedi idősoros előrejelzéseket biztosít a REST API segítségével Amazon API átjáró, az eredmények előre meghatározott JSON formátumban történő visszaadásával.
A következő diagram a végpontok közötti előrejelzési munkafolyamatot mutatja be.

Az architektúra legfontosabb tervezési szempontjai a sokoldalúság, a teljesítmény és a felhasználóbarátság. A rendszernek kellően sokoldalúnak kell lennie ahhoz, hogy változatos algoritmusokat tartalmazzon a fejlesztés és a telepítés során, minimális szükséges változtatásokkal, és könnyen bővíthető, ha a jövőben új algoritmusokat adunk hozzá. A rendszernek emellett minimális többletköltséget kell biztosítania, és támogatnia kell a párhuzamos képzést mind a Forecast, mind a SageMaker számára, hogy csökkentse a képzési időt és gyorsabban megkapja a legfrissebb előrejelzést. Végül a rendszernek könnyen használhatónak kell lennie kísérleti célokra.
A végpontok közötti munkafolyamat sorban fut végig a következő modulokon:
- Előfeldolgozó modul az adatok újraformázásához és átalakításához
- Modell-oktatómodul, amely magában foglalja az előrejelzési modellt és a SageMaker egyéni modelljét (mindkettő párhuzamosan fut)
- Utófeldolgozási modul, amely támogatja a modellegyüttest, a hierarchikus egyeztetést, a mérőszámokat és a jelentéskészítést
A Step Functions állapotgépként szervezi és hangszereli a munkafolyamatot a végétől a végéig. Az állapotgép futtatása egy JSON-fájllal van konfigurálva, amely tartalmazza az összes szükséges információt, beleértve a korábbi bevételi CSV-fájlok helyét az Amazon S3-ban, az előre jelzett kezdési időt és a modell hiperparaméter-beállításait a végpontok közötti munkafolyamat futtatásához. Aszinkron hívások jönnek létre a modelltanítás párhuzamosítására az állapotgépben, lambda függvények segítségével. Az Amazon S3 tárolja az összes előzményadatot, konfigurációs fájlt, előrejelzési eredményt, valamint a közbenső eredményeket, például a visszatesztelési eredményeket. A REST API az Amazon S3 tetejére épül, hogy lekérdezhető felületet biztosítson az előrejelzési eredmények lekérdezéséhez. A rendszer bővíthető új előrejelzési modellekkel és támogató funkciókkal, például előrejelzési vizualizációs jelentések generálásával.
Értékelés
Ebben a részben részletezzük a kísérlet beállítását. A kulcsfontosságú összetevők közé tartozik az adatkészlet, az értékelési mérőszámok, a visszatesztelési ablakok, valamint a modell beállítása és betanítása.
adatbázisba
A Bosch pénzügyi adatainak védelme érdekében, miközben értelmes adatkészletet használunk, olyan szintetikus adatkészletet használtunk, amely hasonló statisztikai jellemzőkkel rendelkezik, mint a Bosch egyik üzleti egységéből származó valós bevételi adatkészlet. Az adatkészlet összesen 1,216 idősort tartalmaz havi gyakorisággal rögzítve, 2016 januárjától 2022 áprilisáig. Az adatkészlet 877 idősort tartalmaz a legrészletesebb szinten (alsó idősor), a megfelelő csoportos idősor szerkezettel. S összegző mátrixként. Minden idősorhoz három statikus kategorikus attribútum tartozik, amelyek megfelelnek a termékkategóriának, régiónak és szervezeti egységnek a valós adatkészletben (a szintetikus adatokban névtelenül).
Értékelési mérőszámok
A modell teljesítményének kiértékeléséhez és az összehasonlító elemzéshez a medián-átlagos arktangens abszolút százalékos hibáját (median-MAAPE) és a súlyozott-MAAPE-t használjuk, amelyek a Bosch szabványos mérőszámai. A MAAPE az üzleti környezetben általánosan használt átlagos abszolút százalékos hiba (MAPE) mérőszám hiányosságait orvosolja. A Median-MAAPE áttekintést ad a modell teljesítményéről azáltal, hogy kiszámítja az egyes idősorokra egyedileg számított MAAPE mediánját. A súlyozott-MAAPE az egyes MAAPE-k súlyozott kombinációját jelenti. A súlyok az egyes idősorok bevételének a teljes adatkészlet összesített bevételéhez viszonyított arányát jelentik. A súlyozott-MAAPE jobban tükrözi az előrejelzés pontosságának downstream üzleti hatásait. Mindkét mérőszám az 1,216 idősorból álló teljes adathalmazra vonatkozik.
Visszateszt ablakok
A modellek teljesítményének összehasonlítására 12 hónapos visszatesztelési ablakokat használunk. A következő ábra szemlélteti a kísérletekben használt backtest ablakokat, és kiemeli a megfelelő képzési és hiperparaméter-optimalizálási (HPO) adatokat. A COVID-19 kezdete utáni visszatesztelési ablakok esetében az eredményt a 2020 áprilisa és májusa közötti OOD-bemenetek befolyásolják a bevételi idősorból megfigyelt adatok alapján.

Modell beállítása és betanítása
A Transformer képzéshez kvantilis veszteséget használtunk, és minden idősort a történelmi átlagérték alapján skáláztunk, mielőtt betápláltuk a Transformerbe, és kiszámítottuk a képzési veszteséget. A végső előrejelzések újraskálázásra kerülnek a pontossági mutatók kiszámításához, a MeanScaler segítségével. GluonTS. Kontextusablakot használunk az elmúlt 18 hónap havi bevételi adataival, amelyeket a HPO-n keresztül választottunk ki a 2018 júliusától 2019 júniusáig tartó visszateszt ablakban. Az egyes idősorok további metaadatai statikus kategorikus változók formájában beágyazáson keresztül kerülnek a modellbe. réteget, mielőtt a transzformátorrétegekhez táplálná. A Transformert öt különböző véletlenszerű súlyozási inicializálással tanítjuk, és minden futásra átlagoljuk az elmúlt három korszak előrejelzési eredményeit, összesen 15 modellt. Az öt modell edzési futás párhuzamosítható az edzési idő csökkentése érdekében. A maszkos Transformer esetében a 2020. áprilistól májusig tartó hónapokat jelöljük kiugróként.
Az összes Forecast modell képzésnél engedélyeztük az automatikus HPO-t, amely egy felhasználó által megadott visszatesztelési periódus alapján tudja kiválasztani a modellt és a képzési paramétereket, amely a képzéshez és a HPO-hoz használt adatablakban az utolsó 12 hónapra van beállítva.
Kísérleti eredmények
Az álarcos és maszkos transzformátorokat ugyanazon hiperparaméterkészlet használatával képeztük ki, és összehasonlítottuk a teljesítményüket a visszateszt ablakoknál közvetlenül a COVID-19-sokk után. A maszkolt Transformerben a két maszkolt hónap 2020 áprilisa és májusa. Az alábbi táblázat egy 12 hónapos előrejelzési ablakkal rendelkező, 2020 júniusától kezdődő visszatesztelési időszak eredményeit mutatja. Megfigyelhető, hogy a maszkolt Transformer folyamatosan felülmúlja a maszkolt verziót. .

A továbbiakban elvégeztük a modellegyüttes stratégia értékelését a visszateszt eredményei alapján. Különösen azt a két esetet hasonlítjuk össze, amikor csak a legjobban teljesítő modell van kiválasztva, és amikor a két legjobban teljesítő modell van kiválasztva, és a modellátlagolást az előrejelzések átlagértékének kiszámításával végezzük. Az alábbi ábrákon az alapmodellek és az együttes modellek teljesítményét hasonlítjuk össze. Figyelje meg, hogy a neurális előrejelzők egyike sem teljesít folyamatosan jobb teljesítményt a gördülő visszateszt ablakok során.


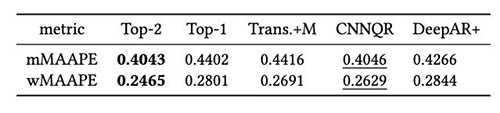
A következő táblázat azt mutatja, hogy átlagosan az első két modell együttes modellezése adja a legjobb teljesítményt. A CNNQR a második legjobb eredményt adja.
Következtetés
Ez a bejegyzés bemutatta, hogyan lehet végpontok közötti ML-megoldást felépíteni nagyszabású előrejelzési problémákra az előrejelzés és a SageMakeren betanított egyéni modell kombinálásával. Az üzleti igényektől és az ML-ismeretektől függően használhat egy teljesen felügyelt szolgáltatást, például az előrejelzést az előrejelzési modell felépítési, betanítási és telepítési folyamatának tehermentesítésére; készítse el egyedi modelljét speciális hangolási mechanizmusokkal a SageMaker segítségével; vagy modellösszeállítást végezzen a két szolgáltatás kombinálásával.
Ha segítségre van szüksége az ML használatának felgyorsításához termékeiben és szolgáltatásaiban, kérjük, forduljon a Amazon ML Solutions Lab program.
Referenciák
Hyndman RJ, Athanasopoulos G. Előrejelzés: alapelvek és gyakorlat. OTexts; 2018 május 8.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Csak a figyelem kell. A neurális információfeldolgozó rendszerek fejlődése. 2017;30.
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Informer: Beyond hatékony transzformátor hosszú sorozatú idősoros előrejelzéshez. InProceedings of AAAI 2021, február 2.
A szerzőkről
 Goktug Cinar vezető ML-tudós, valamint a Robert Bosch LLC és a Bosch Mesterséges Intelligencia Központ ML és statisztikai alapú előrejelzésének műszaki vezetője. Vezeti az előrejelzési modellek, a hierarchikus konszolidáció és a modellkombinációs technikák kutatását, valamint azt a szoftverfejlesztő csapatot, amely ezeket a modelleket skálázza és a belső végpontok közötti pénzügyi előrejelző szoftver részeként szolgálja ki.
Goktug Cinar vezető ML-tudós, valamint a Robert Bosch LLC és a Bosch Mesterséges Intelligencia Központ ML és statisztikai alapú előrejelzésének műszaki vezetője. Vezeti az előrejelzési modellek, a hierarchikus konszolidáció és a modellkombinációs technikák kutatását, valamint azt a szoftverfejlesztő csapatot, amely ezeket a modelleket skálázza és a belső végpontok közötti pénzügyi előrejelző szoftver részeként szolgálja ki.
 Michael Binder a Bosch Global Services terméktulajdonosa, ahol koordinálja a vállalat egészére kiterjedő prediktív analitikai alkalmazás fejlesztését, bevezetését és bevezetését a kulcsfontosságú pénzügyi adatok nagyszabású automatizált adatközpontú előrejelzéséhez.
Michael Binder a Bosch Global Services terméktulajdonosa, ahol koordinálja a vállalat egészére kiterjedő prediktív analitikai alkalmazás fejlesztését, bevezetését és bevezetését a kulcsfontosságú pénzügyi adatok nagyszabású automatizált adatközpontú előrejelzéséhez.
 Horváth Adrián Szoftverfejlesztő a Bosch Center for Artificial Intelligence-nél, ahol rendszereket fejleszt és tart karban különböző előrejelzési modelleken alapuló előrejelzések létrehozásához.
Horváth Adrián Szoftverfejlesztő a Bosch Center for Artificial Intelligence-nél, ahol rendszereket fejleszt és tart karban különböző előrejelzési modelleken alapuló előrejelzések létrehozásához.
 Panpan Xu vezető alkalmazott tudós és menedzser az Amazon ML Solutions Labnál az AWS-nél. Gépi tanulási algoritmusok kutatásán és fejlesztésén dolgozik nagy hatású ügyfélalkalmazásokhoz számos ipari ágazatban, hogy felgyorsítsa az AI és a felhő alkalmazását. Kutatási területe a modell értelmezhetősége, az ok-okozati elemzés, a humán in-the-loop AI és az interaktív adatvizualizáció.
Panpan Xu vezető alkalmazott tudós és menedzser az Amazon ML Solutions Labnál az AWS-nél. Gépi tanulási algoritmusok kutatásán és fejlesztésén dolgozik nagy hatású ügyfélalkalmazásokhoz számos ipari ágazatban, hogy felgyorsítsa az AI és a felhő alkalmazását. Kutatási területe a modell értelmezhetősége, az ok-okozati elemzés, a humán in-the-loop AI és az interaktív adatvizualizáció.
 Jasleen Grewal az Amazon Web Services alkalmazott tudósa, ahol az AWS-ügyfelekkel dolgozik, hogy valós problémákat oldjanak meg gépi tanulás segítségével, különös tekintettel a precíziós orvostudományra és a genomikára. Erős bioinformatikai, onkológiai és klinikai genomika múlttal rendelkezik. Szenvedélyesen használja az AI/ML és a felhőszolgáltatásokat a betegellátás javítása érdekében.
Jasleen Grewal az Amazon Web Services alkalmazott tudósa, ahol az AWS-ügyfelekkel dolgozik, hogy valós problémákat oldjanak meg gépi tanulás segítségével, különös tekintettel a precíziós orvostudományra és a genomikára. Erős bioinformatikai, onkológiai és klinikai genomika múlttal rendelkezik. Szenvedélyesen használja az AI/ML és a felhőszolgáltatásokat a betegellátás javítása érdekében.
 Selvan Senthivel Senior ML mérnök az Amazon ML Solutions Labnál az AWS-nél, és az ügyfelek segítésére összpontosít a gépi tanulás, a mély tanulási problémák és a végpontok közötti ML megoldások terén. Az Amazon Comprehend Medical alapító mérnöki vezetője volt, és több AWS AI-szolgáltatás tervezésében és felépítésében is közreműködött.
Selvan Senthivel Senior ML mérnök az Amazon ML Solutions Labnál az AWS-nél, és az ügyfelek segítésére összpontosít a gépi tanulás, a mély tanulási problémák és a végpontok közötti ML megoldások terén. Az Amazon Comprehend Medical alapító mérnöki vezetője volt, és több AWS AI-szolgáltatás tervezésében és felépítésében is közreműködött.
 Ruilin Zhang egy SDE az AWS Amazon ML Solutions Labjával. Segít az ügyfeleknek az AWS AI-szolgáltatások átvételében azáltal, hogy megoldásokat készít a gyakori üzleti problémák megoldására.
Ruilin Zhang egy SDE az AWS Amazon ML Solutions Labjával. Segít az ügyfeleknek az AWS AI-szolgáltatások átvételében azáltal, hogy megoldásokat készít a gyakori üzleti problémák megoldására.
 Shane Rai az AWS Amazon ML Solutions Labjának idősebb ML-szakértője. Az iparágak legkülönbözőbb skáláján dolgozik ügyfeleivel annak érdekében, hogy az AWS felhőalapú AI/ML szolgáltatásainak segítségével megoldja legsürgetőbb és leginnovatívabb üzleti igényeiket.
Shane Rai az AWS Amazon ML Solutions Labjának idősebb ML-szakértője. Az iparágak legkülönbözőbb skáláján dolgozik ügyfeleivel annak érdekében, hogy az AWS felhőalapú AI/ML szolgáltatásainak segítségével megoldja legsürgetőbb és leginnovatívabb üzleti igényeiket.
 Lin Lee Cheong az AWS Amazon ML Solutions Lab csapatának alkalmazott tudományos menedzsere. Stratégiai AWS-ügyfeleivel dolgozik a mesterséges intelligencia és a gépi tanulás felfedezése és alkalmazása érdekében, hogy új felismeréseket fedezzen fel és összetett problémákat oldjon meg.
Lin Lee Cheong az AWS Amazon ML Solutions Lab csapatának alkalmazott tudományos menedzsere. Stratégiai AWS-ügyfeleivel dolgozik a mesterséges intelligencia és a gépi tanulás felfedezése és alkalmazása érdekében, hogy új felismeréseket fedezzen fel és összetett problémákat oldjon meg.