
Anda kini dapat melatih kembali model pembelajaran mesin (ML) dan mengotomatiskan alur kerja prediksi batch dengan kumpulan data yang diperbarui Kanvas Amazon SageMaker, sehingga memudahkan untuk terus mempelajari dan meningkatkan performa model serta efisiensi penggerak. Efektivitas model ML bergantung pada kualitas dan relevansi data yang dilatihnya. Seiring berjalannya waktu, pola dasar, tren, dan distribusi data dapat berubah. Dengan memperbarui kumpulan data, Anda memastikan bahwa model belajar dari data terbaru dan representatif, sehingga meningkatkan kemampuannya dalam membuat prediksi yang akurat. Canvas kini mendukung pembaruan kumpulan data secara otomatis dan manual sehingga Anda dapat menggunakan kumpulan data tabular, gambar, dan dokumen versi terbaru untuk melatih model ML.
Setelah model dilatih, Anda mungkin ingin menjalankan prediksi pada model tersebut. Menjalankan prediksi batch pada model ML memungkinkan pemrosesan beberapa titik data secara bersamaan, bukan membuat prediksi satu per satu. Mengotomatiskan proses ini memberikan efisiensi, skalabilitas, dan pengambilan keputusan tepat waktu. Setelah prediksi dibuat, prediksi tersebut dapat dianalisis, dikumpulkan, atau divisualisasikan lebih lanjut untuk mendapatkan wawasan, mengidentifikasi pola, atau membuat keputusan berdasarkan hasil yang diprediksi. Canvas kini mendukung penyiapan konfigurasi prediksi batch otomatis dan mengaitkan kumpulan data ke dalamnya. Saat kumpulan data terkait disegarkan, baik secara manual atau terjadwal, alur kerja prediksi batch akan dipicu secara otomatis pada model yang sesuai. Hasil prediksi dapat dilihat secara inline atau diunduh untuk ditinjau nanti.
Dalam postingan ini, kami menunjukkan cara melatih ulang model ML dan mengotomatiskan prediksi batch menggunakan kumpulan data yang diperbarui di Canvas.
Ikhtisar solusi
Untuk kasus penggunaan kami, kami berperan sebagai analis bisnis untuk perusahaan e-niaga. Tim produk ingin kami menentukan metrik paling penting yang memengaruhi keputusan pembelian pembeli. Untuk melakukan hal ini, kami melatih model ML di Canvas dengan kumpulan data sesi online situs web pelanggan dari perusahaan. Kami mengevaluasi performa model dan, jika diperlukan, melatih ulang model tersebut dengan data tambahan untuk melihat apakah model tersebut meningkatkan performa model yang ada atau tidak. Untuk melakukannya, kami menggunakan kemampuan kumpulan data pembaruan otomatis di Canvas dan melatih ulang model ML yang ada dengan kumpulan data pelatihan versi terbaru. Lalu kami mengonfigurasi alur kerja prediksi batch otomatis—saat kumpulan data prediksi terkait diperbarui, maka secara otomatis memicu pekerjaan prediksi batch pada model dan membuat hasilnya tersedia untuk kami tinjau.
Langkah-langkah alur kerjanya adalah sebagai berikut:
- Unggah data sesi online situs web pelanggan yang diunduh ke Layanan Penyimpanan Sederhana Amazon (Amazon S3) dan buat kumpulan data pelatihan baru Canvas. Untuk daftar lengkap sumber data yang didukung, lihat Mengimpor data di Amazon SageMaker Canvas.
- Bangun model ML dan analisis metrik kinerjanya. Lihat langkah-langkah tentang caranya buat Model ML khusus di Canvas dan mengevaluasi kinerja model.
- Siapkan pembaruan otomatis pada dataset pelatihan yang ada dan unggah data baru ke lokasi Amazon S3 yang mendukung dataset ini. Setelah selesai, versi kumpulan data baru akan dibuat.
- Gunakan kumpulan data versi terbaru untuk melatih kembali model ML dan menganalisis performanya.
- Mendirikan prediksi batch otomatis pada versi model yang berkinerja lebih baik dan melihat hasil prediksi.
Anda dapat melakukan langkah-langkah ini di Canvas tanpa menulis satu baris kode pun.
Ikhtisar data
Dataset terdiri dari vektor fitur milik 12,330 sesi. Kumpulan data tersebut dibentuk sehingga setiap sesi akan menjadi milik pengguna yang berbeda dalam periode 1 tahun untuk menghindari kecenderungan terhadap kampanye, hari khusus, profil pengguna, atau periode tertentu. Tabel berikut menguraikan skema data.
| Nama kolom | Tipe data | Deskripsi Produk |
Administrative |
Numeric | Jumlah halaman yang dikunjungi oleh pengguna untuk aktivitas terkait manajemen akun pengguna. |
Administrative_Duration |
Numeric | Jumlah waktu yang dihabiskan dalam kategori halaman ini. |
Informational |
Numeric | Jumlah halaman jenis ini (informasional) yang dikunjungi pengguna. |
Informational_Duration |
Numeric | Jumlah waktu yang dihabiskan dalam kategori halaman ini. |
ProductRelated |
Numeric | Jumlah halaman jenis ini (terkait produk) yang dikunjungi pengguna. |
ProductRelated_Duration |
Numeric | Jumlah waktu yang dihabiskan dalam kategori halaman ini. |
BounceRates |
Numeric | Persentase pengunjung yang memasuki situs web melalui halaman tersebut dan keluar tanpa memicu tugas tambahan apa pun. |
ExitRates |
Numeric | Tingkat keluar rata-rata dari halaman yang dikunjungi pengguna. Ini adalah persentase orang yang meninggalkan situs Anda dari halaman tersebut. |
Page Values |
Numeric | Nilai halaman rata-rata dari halaman yang dikunjungi oleh pengguna. Ini adalah nilai rata-rata untuk laman yang dikunjungi pengguna sebelum membuka laman sasaran atau menyelesaikan transaksi e-niaga (atau keduanya). |
SpecialDay |
Biner | Fitur “Hari Spesial” menunjukkan kedekatan waktu kunjungan situs dengan hari istimewa tertentu (seperti Hari Ibu atau Hari Valentine) yang mana sesinya lebih mungkin diselesaikan dengan transaksi. |
Month |
Kategorikal | Bulan kunjungan. |
OperatingSystems |
Kategorikal | Sistem operasi pengunjung. |
Browser |
Kategorikal | Browser yang digunakan oleh pengguna. |
Region |
Kategorikal | Wilayah geografis tempat sesi dimulai oleh pengunjung. |
TrafficType |
Kategorikal | Sumber lalu lintas yang digunakan pengguna untuk memasuki situs web. |
VisitorType |
Kategorikal | Apakah pelanggan tersebut adalah pengguna baru, pengguna kembali, atau lainnya. |
Weekend |
Biner | Jika pelanggan mengunjungi situs web pada akhir pekan. |
Revenue |
Biner | Jika pembelian telah dilakukan. |
Pendapatan adalah kolom target, yang akan membantu kami memprediksi apakah pembeli akan membeli suatu produk atau tidak.
Langkah pertama adalah unduh kumpulan data yang akan kita gunakan. Perhatikan bahwa kumpulan data ini berasal dari Repositori Pembelajaran Mesin UCI.
Prasyarat
Untuk panduan ini, selesaikan langkah-langkah prasyarat berikut:
- Pisahkan CSV yang diunduh yang berisi 20,000 baris menjadi beberapa file potongan yang lebih kecil.
Hal ini agar kami dapat menampilkan fungsionalitas pembaruan kumpulan data. Pastikan semua file CSV memiliki header yang sama, jika tidak, Anda mungkin mengalami kesalahan ketidakcocokan skema saat membuat kumpulan data pelatihan di Canvas.

- Buat bucket S3 dan unggah
online_shoppers_intentions1-3.csvke ember S3.

- Sisihkan 1,500 baris dari CSV yang diunduh untuk menjalankan prediksi batch setelah model ML dilatih.
- Lepaskan
Revenuekolom dari file-file ini sehingga ketika Anda menjalankan prediksi batch pada model ML, itulah nilai yang akan diprediksi oleh model Anda.
Pastikan semua predict*.csv file memiliki header yang sama, jika tidak, Anda mungkin mengalami kesalahan ketidakcocokan skema saat membuat kumpulan data prediksi (inferensi) di Canvas.

- Lakukan langkah-langkah yang diperlukan untuk menyiapkan domain SageMaker dan aplikasi Canvas.
Buat kumpulan data
Untuk membuat himpunan data di Canvas, selesaikan langkah-langkah berikut:
- Di Kanvas, pilih Dataset di panel navigasi.
- Pilih membuat Dan pilihlah Datar.

- Beri nama pada kumpulan data Anda. Untuk postingan ini, kami menyebut dataset pelatihan kami
OnlineShoppersIntentions. - Pilih membuat.

- Pilih sumber data Anda (untuk postingan ini, sumber data kami adalah Amazon S3).
Perhatikan bahwa pada tulisan ini, fungsionalitas pembaruan kumpulan data hanya didukung untuk Amazon S3 dan sumber data yang diunggah secara lokal.
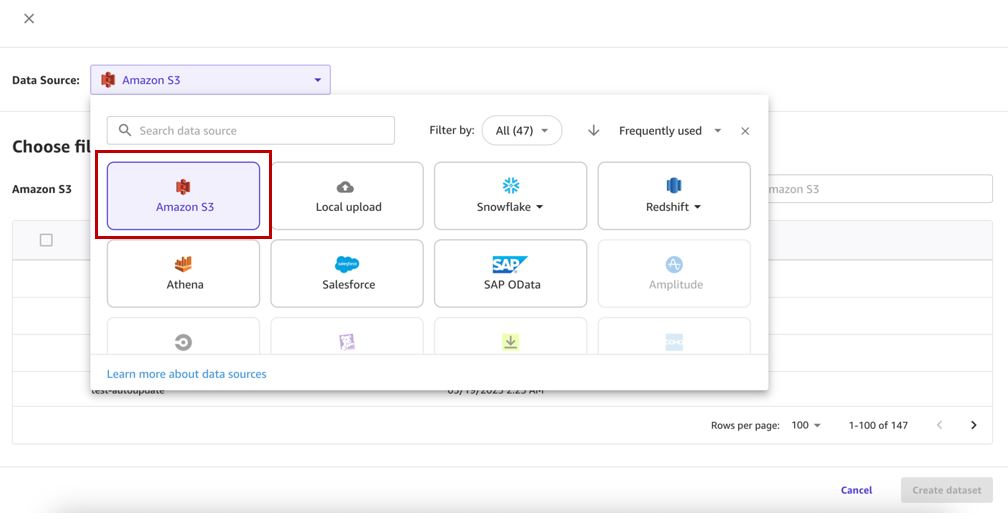
- Pilih keranjang yang sesuai dan unggah file CSV untuk kumpulan data.
Anda sekarang dapat membuat kumpulan data dengan banyak file.

- Pratinjau semua file dalam kumpulan data dan pilih Buat set data.

Kami sekarang memiliki versi 1 OnlineShoppersIntentions kumpulan data dengan tiga file dibuat.
- Pilih kumpulan data untuk melihat detailnya.

Grafik Data tab menunjukkan pratinjau kumpulan data.
- Pilih Detail kumpulan data untuk melihat file yang berisi kumpulan data.
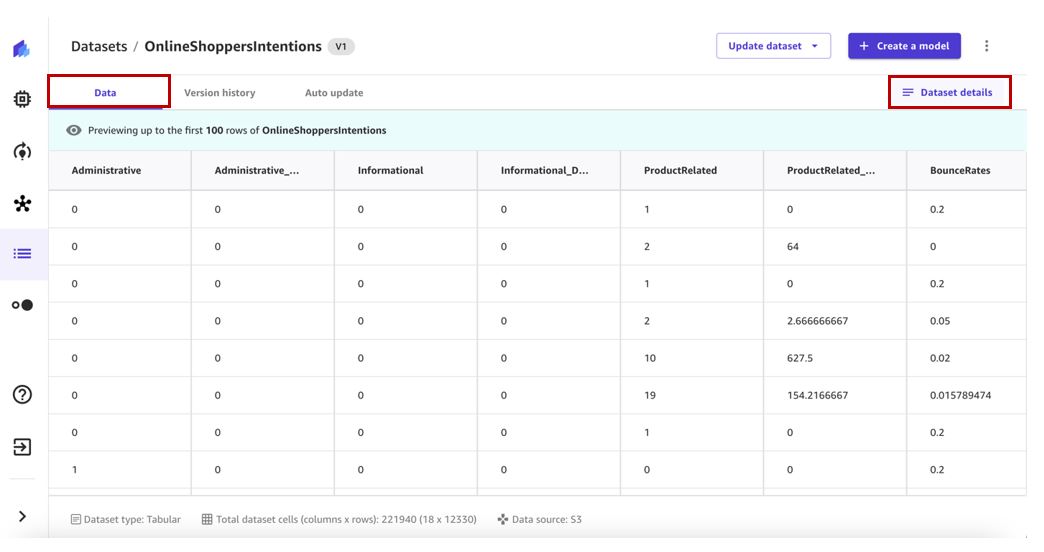
Grafik File kumpulan data panel mencantumkan file yang tersedia.

- Pilih Sejarah Versi tab untuk melihat semua versi kumpulan data ini.
Kita dapat melihat versi dataset pertama kita memiliki tiga file. Versi berikutnya akan menyertakan semua file dari versi sebelumnya dan akan memberikan tampilan data kumulatif.
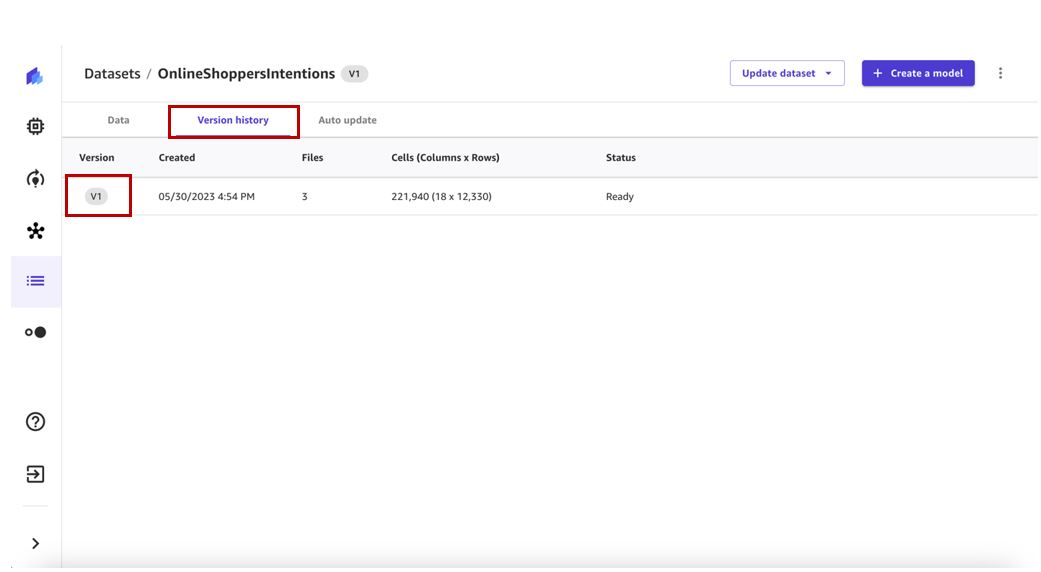
Latih model ML dengan set data versi 1
Mari kita latih model ML dengan versi 1 dari kumpulan data kita.
- Di Kanvas, pilih Model saya di panel navigasi.
- Pilih Model baru.
- Masukkan nama model (misalnya,
OnlineShoppersIntentionsModel), pilih jenis masalah, dan pilih membuat.
- Pilih kumpulan data. Untuk posting ini, kami memilih
OnlineShoppersIntentionsHimpunan data.
Secara default, Canvas akan mengambil versi himpunan data terbaru untuk pelatihan.

- pada Membangun tab, pilih kolom target yang akan diprediksi. Untuk postingan ini, kita memilih kolom Pendapatan.
- Pilih Membangun cepat.

Pelatihan model akan memakan waktu 2–5 menit untuk diselesaikan. Dalam kasus kami, model yang dilatih memberi kami skor 89%.

Siapkan pembaruan kumpulan data otomatis
Mari perbarui kumpulan data kita menggunakan fungsi pembaruan otomatis dan masukkan lebih banyak data serta lihat apakah performa model meningkat dengan kumpulan data versi baru. Kumpulan data juga dapat diperbarui secara manual.
- pada Dataset halaman, pilih
OnlineShoppersIntentionskumpulan data dan pilih Perbarui kumpulan data. - Anda bisa memilih Pembaruan manual, yang merupakan opsi pembaruan satu kali, atau Pembaruan otomatis, yang memungkinkan Anda memperbarui kumpulan data secara otomatis sesuai jadwal. Untuk postingan kali ini, kami menampilkan fitur update otomatis.

Anda dialihkan ke Pembaruan otomatis tab untuk kumpulan data yang sesuai. Kita bisa melihatnya Aktifkan pembaruan otomatis saat ini dinonaktifkan.

- Beralih Aktifkan pembaruan otomatis untuk mengaktifkan dan menentukan sumber data (saat tulisan ini dibuat, sumber data Amazon S3 didukung untuk pembaruan otomatis).
- Pilih frekuensi dan masukkan waktu mulai.
- Simpan pengaturan konfigurasi.

Konfigurasi kumpulan data pembaruan otomatis telah dibuat. Itu dapat diedit kapan saja. Ketika tugas pembaruan kumpulan data terkait dipicu pada jadwal yang ditentukan, tugas tersebut akan muncul di Riwayat pekerjaan bagian.

- Selanjutnya, mari kita unggah
online_shoppers_intentions4.csv,online_shoppers_intentions5.csv, danonline_shoppers_intentions6.csvfile ke bucket S3 kami.

Kita dapat melihat file kita di dataset-update-demo Ember S3.

Pekerjaan pembaruan kumpulan data akan dipicu pada jadwal yang ditentukan dan membuat versi kumpulan data baru.

Ketika pekerjaan selesai, himpunan data versi 2 akan memiliki semua file dari versi 1 dan file tambahan yang diproses oleh pekerjaan pembaruan himpunan data. Dalam kasus kami, versi 1 memiliki tiga file dan tugas pembaruan mengambil tiga file tambahan, sehingga versi himpunan data final memiliki enam file.
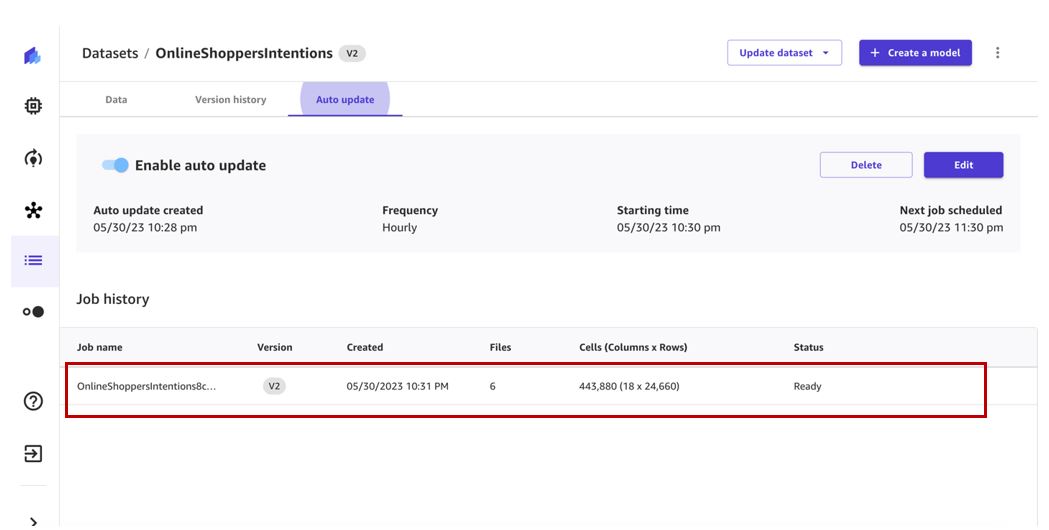
Kita dapat melihat versi baru yang dibuat di Riwayat versi Tab.

Grafik Data tab berisi pratinjau kumpulan data dan menyediakan daftar semua file dalam versi terbaru kumpulan data.

Latih kembali model ML dengan kumpulan data yang diperbarui
Mari kita latih kembali model ML kita dengan kumpulan data versi terbaru.
- pada Model saya halaman, pilih model Anda.
- Pilih Tambahkan versi.
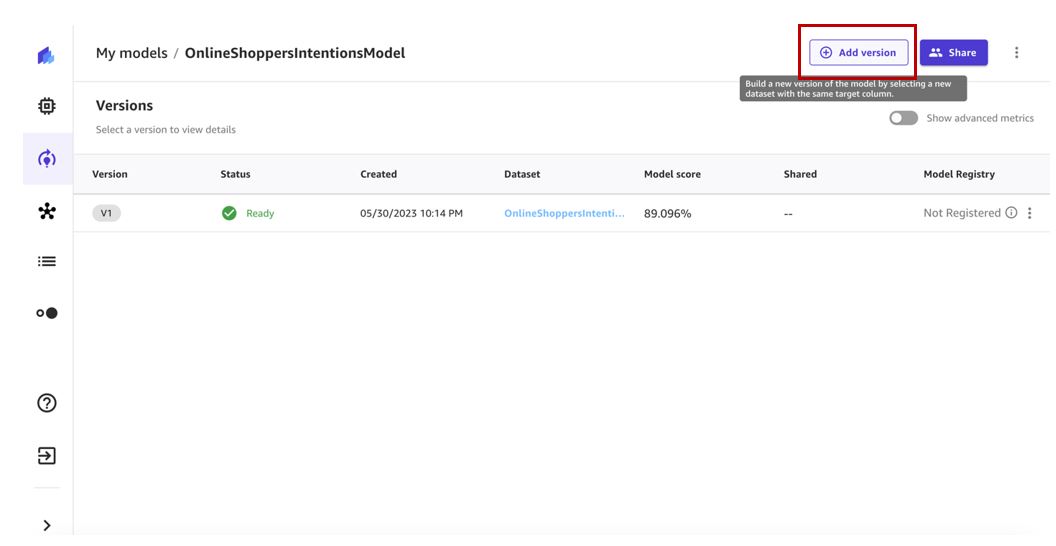
- Pilih versi kumpulan data terbaru (v2 dalam kasus kami) dan pilih Pilih set data.
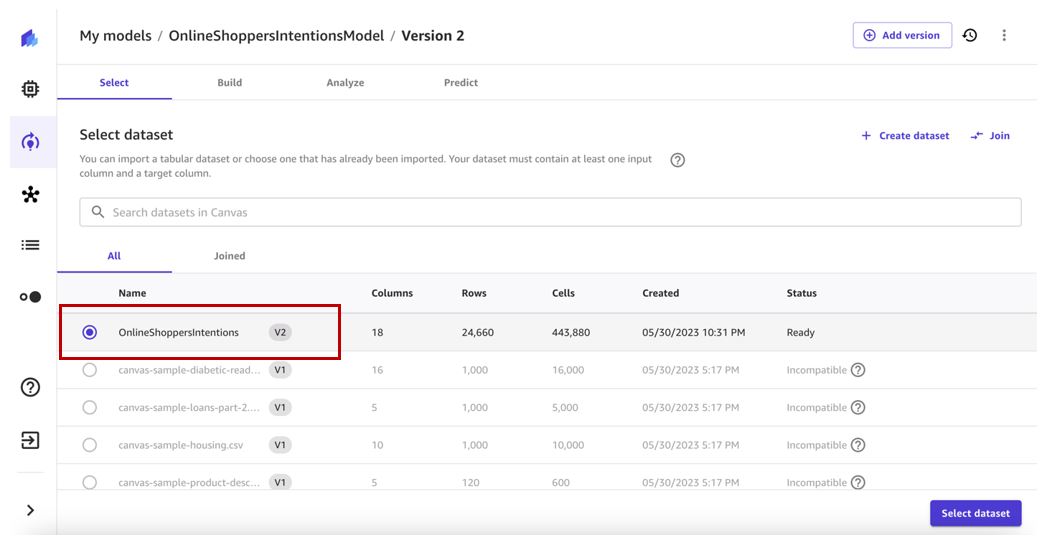
- Pertahankan kolom target dan konfigurasi build serupa dengan versi model sebelumnya.

Saat pelatihan selesai, mari kita evaluasi performa model. Tangkapan layar berikut menunjukkan bahwa menambahkan data tambahan dan melatih ulang model ML telah membantu meningkatkan performa model kami.

Buat kumpulan data prediksi
Dengan model ML yang dilatih, mari buat kumpulan data untuk prediksi dan jalankan prediksi batch di dalamnya.
- pada Dataset halaman, buat kumpulan data tabel.
- Masukkan nama dan pilih membuat.

- Di bucket S3 kami, unggah satu file dengan 500 baris untuk diprediksi.

Selanjutnya, kami menyiapkan pembaruan otomatis pada kumpulan data prediksi.
- Beralih Aktifkan pembaruan otomatis untuk mengaktifkan dan menentukan sumber data.
- Pilih frekuensi dan tentukan waktu mulai.
- Simpan konfigurasi.
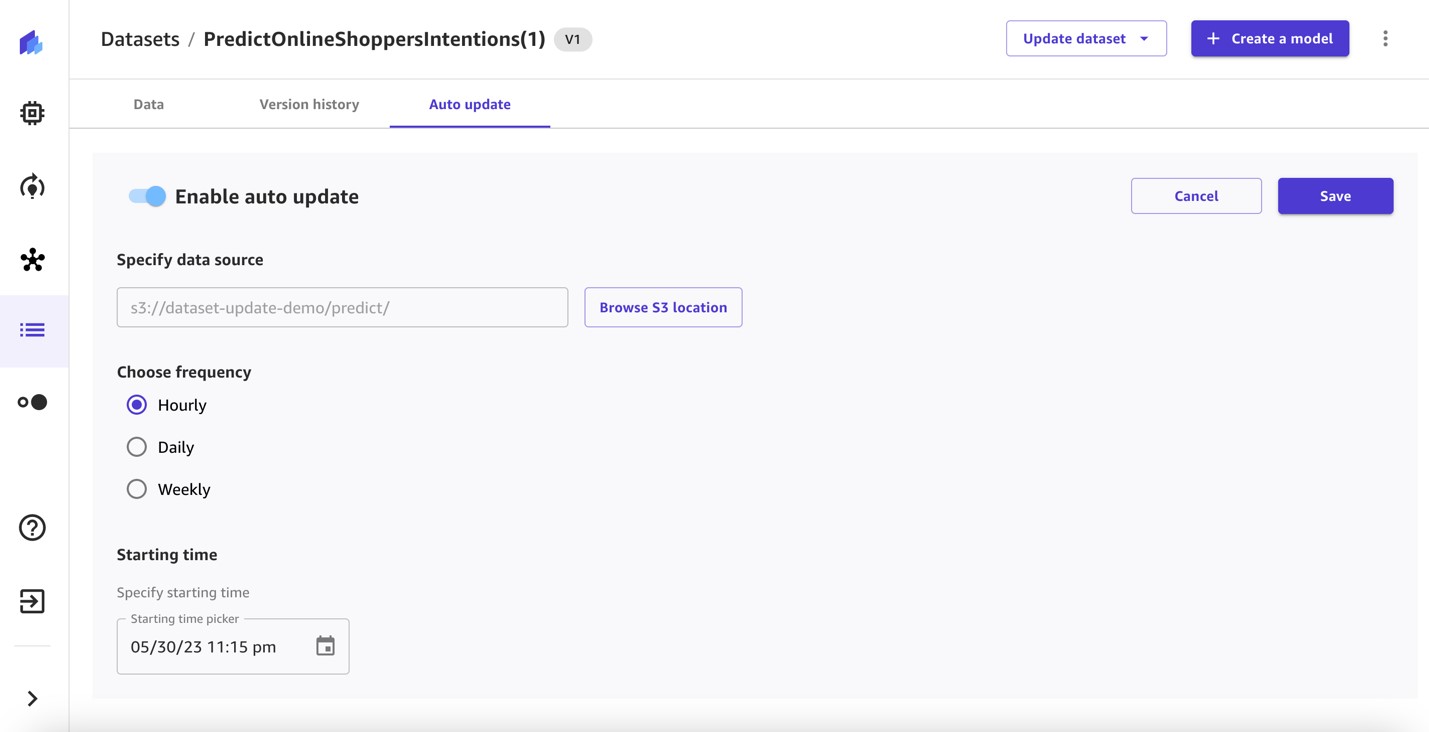
Otomatiskan alur kerja prediksi batch pada kumpulan data prediksi yang diperbarui secara otomatis
Pada langkah ini, kami mengonfigurasi alur kerja prediksi batch otomatis.
- pada Model saya halaman, navigasikan ke versi 2 model Anda.
- pada Meramalkan tab, pilih Prediksi batch dan secara otomatis.
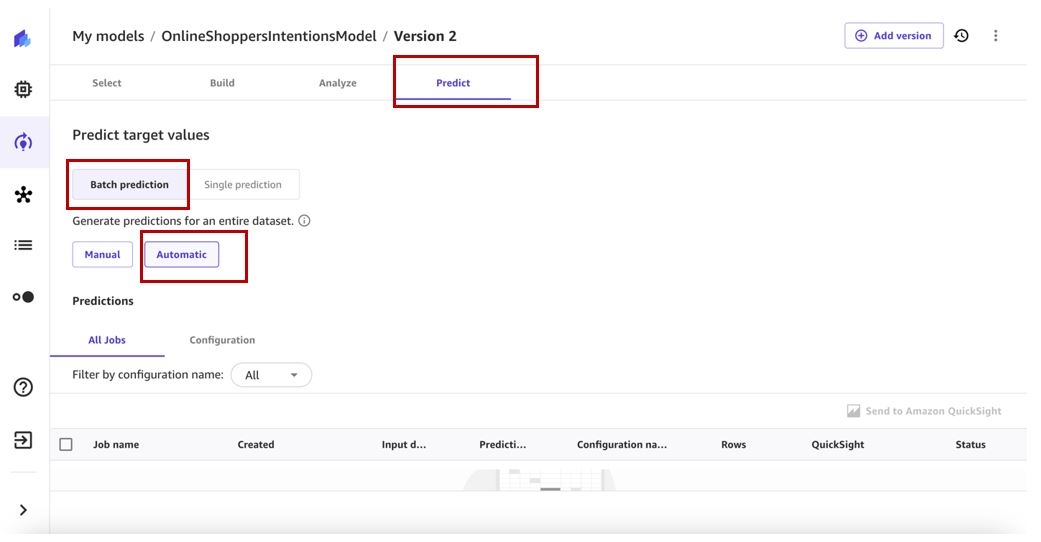
- Pilih Pilih set data untuk menentukan kumpulan data untuk menghasilkan prediksi.

- Pilih
predictdataset yang kita buat tadi dan pilih Pilih kumpulan data.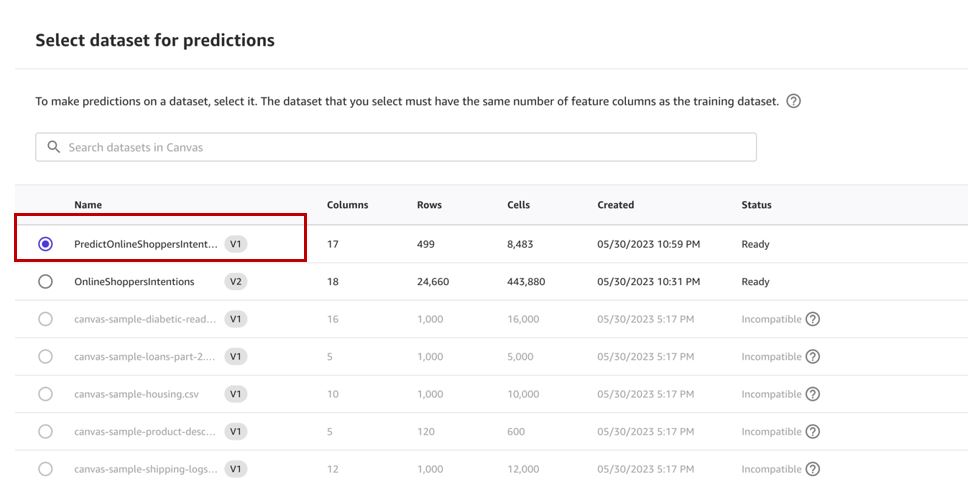
- Pilih Mendirikan.

Kami sekarang memiliki alur kerja prediksi batch otomatis. Hal ini akan dipicu ketika Predict kumpulan data diperbarui secara otomatis.

Sekarang mari kita unggah lebih banyak file CSV ke predict folder S3.
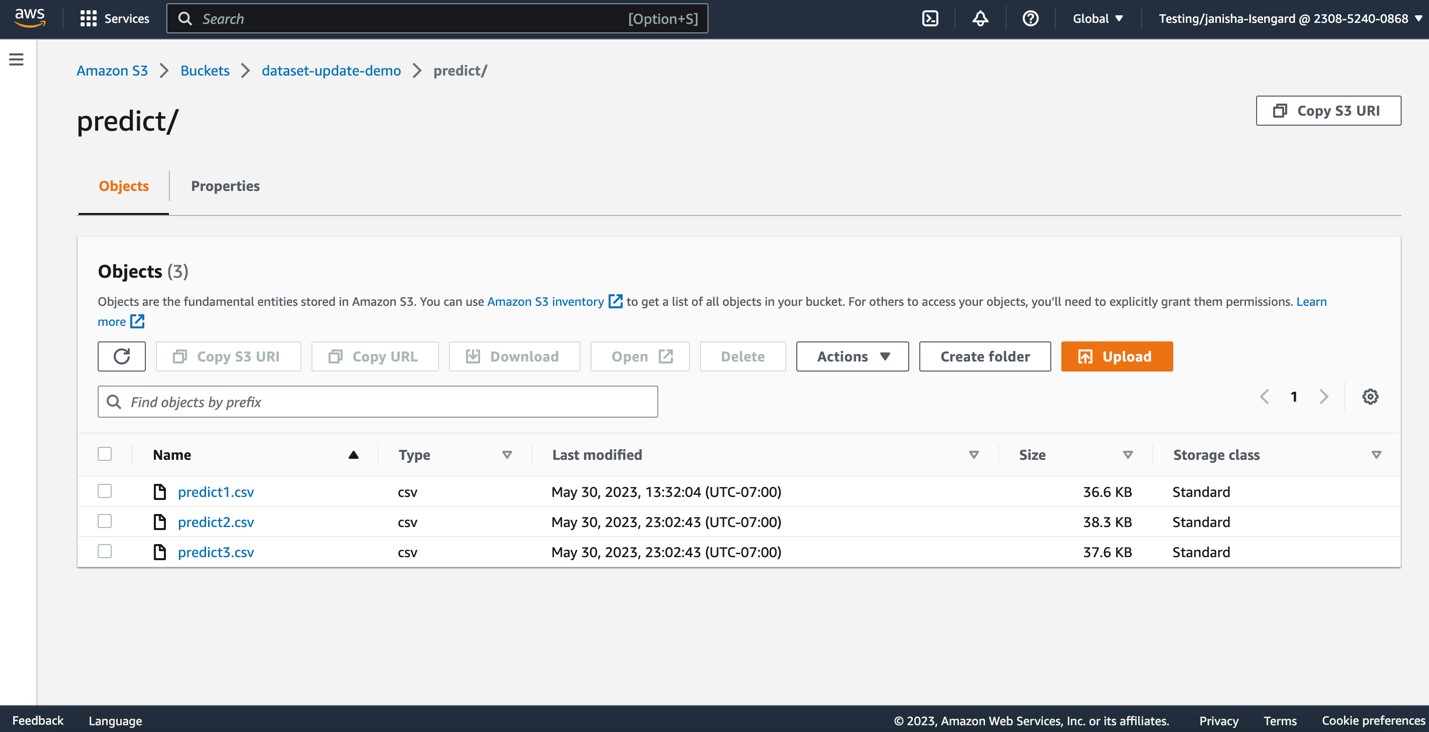
Operasi ini akan memicu pembaruan otomatis predict Himpunan data.
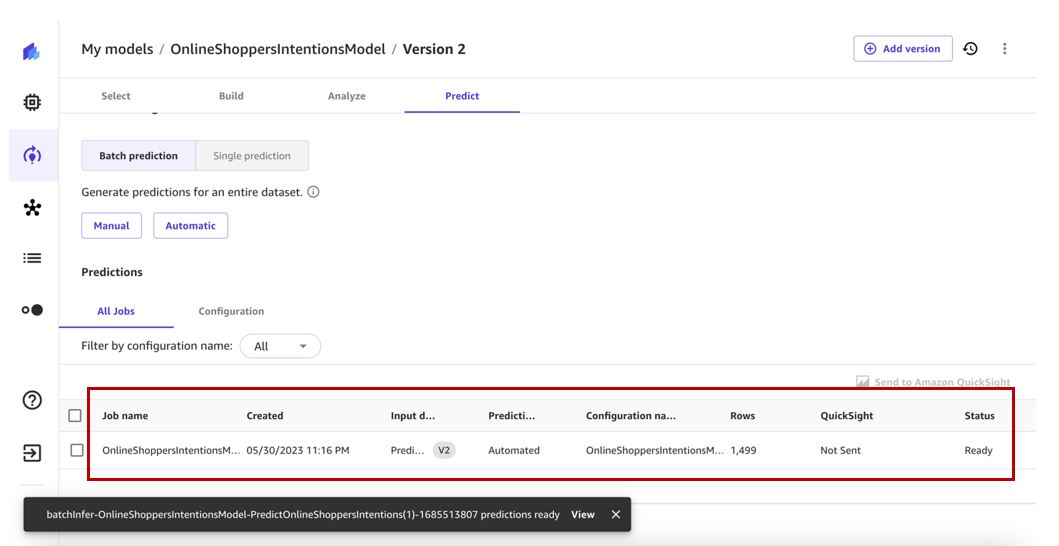
Hal ini pada gilirannya akan memicu alur kerja prediksi batch otomatis dan menghasilkan prediksi untuk kita lihat.

Kami dapat melihat semua otomatisasi di Otomasi .

Berkat pembaruan himpunan data otomatis dan alur kerja prediksi batch otomatis, kita dapat menggunakan versi terbaru dari himpunan data tabular, gambar, dan dokumen untuk melatih model ML, dan membangun alur kerja prediksi batch yang dipicu secara otomatis pada setiap pembaruan himpunan data.
Membersihkan
Untuk menghindari dikenakan biaya di masa mendatang, keluarlah dari Canvas. Canvas menagih Anda selama durasi sesi, dan kami menyarankan Anda keluar dari Canvas saat Anda tidak menggunakannya. Mengacu pada Keluar dari Amazon SageMaker Canvas lebih lanjut.
Kesimpulan
Dalam postingan ini, kami membahas bagaimana kami dapat menggunakan kemampuan pembaruan kumpulan data baru untuk membuat versi kumpulan data baru dan melatih model ML kami dengan data terbaru di Canvas. Kami juga menunjukkan bagaimana kami dapat mengotomatiskan proses menjalankan prediksi batch secara efisien pada data yang diperbarui.
Untuk memulai perjalanan ML berkode rendah/tanpa kode, lihat Panduan Pengembang Kanvas Amazon SageMaker.
Terima kasih khusus kepada semua orang yang berkontribusi pada peluncuran ini.
Tentang Penulis
 Janisha Anand adalah Manajer Produk Senior di tim SageMaker No/Low-Code ML, yang mencakup SageMaker Canvas dan SageMaker Autopilot. Dia menikmati kopi, tetap aktif, dan menghabiskan waktu bersama keluarganya.
Janisha Anand adalah Manajer Produk Senior di tim SageMaker No/Low-Code ML, yang mencakup SageMaker Canvas dan SageMaker Autopilot. Dia menikmati kopi, tetap aktif, dan menghabiskan waktu bersama keluarganya.
 Prashanth adalah Insinyur Pengembangan Perangkat Lunak di Amazon SageMaker dan terutama bekerja dengan produk kode rendah dan tanpa kode SageMaker.
Prashanth adalah Insinyur Pengembangan Perangkat Lunak di Amazon SageMaker dan terutama bekerja dengan produk kode rendah dan tanpa kode SageMaker.
 Esha Dutta adalah Insinyur Pengembangan Perangkat Lunak di Amazon SageMaker. Dia berfokus pada pembuatan alat dan produk ML untuk pelanggan. Di luar pekerjaan, dia menikmati alam bebas, yoga, dan hiking.
Esha Dutta adalah Insinyur Pengembangan Perangkat Lunak di Amazon SageMaker. Dia berfokus pada pembuatan alat dan produk ML untuk pelanggan. Di luar pekerjaan, dia menikmati alam bebas, yoga, dan hiking.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Keuangan EVM. Antarmuka Terpadu untuk Keuangan Terdesentralisasi. Akses Di Sini.
- Grup Media Kuantum. IR/PR Diperkuat. Akses Di Sini.
- PlatoAiStream. Kecerdasan Data Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/retrain-ml-models-and-automate-batch-predictions-in-amazon-sagemaker-canvas-using-updated-datasets/