
在数据仓库中,一个 尺寸 是一种对事实和度量进行分类以使用户能够回答业务问题的结构。 举例说明,在典型的销售领域中,客户、时间或产品是维度,而销售交易是事实。 维度中的属性会随着时间而改变——客户可以改变他们的地址,员工可以从承包商职位调到全职职位,或者产品可以有多次修订。 A 缓慢变化的维度 (SCD) 是一种数据仓库概念,包含相对静态的数据,这些数据可以在一段时间内缓慢变化。 数据仓库中维护的 SCD 主要分为三种类型:类型 1(无历史记录)、类型 2(完整历史记录)和类型 3(有限历史记录)。 变更数据捕获 (CDC) 是数据库的一个特征,它提供识别两次数据库加载之间发生变化的数据的能力,以便可以对发生变化的数据执行操作。
随着全球各地的组织都在使用数据湖对其数据平台进行现代化改造 亚马逊简单存储服务 (Amazon S3),在数据湖中处理 SCD 可能具有挑战性。 如果源系统不提供一种机制来识别数据湖中处理的更改数据,并且如果数据源恰好是半结构化而不是数据库,则数据处理会变得非常复杂,这就变得更具挑战性。 处理 2 类 SCD 的主要目标是准确定义数据集的开始和结束日期,以跟踪数据湖内的变化,因为这为消费应用程序提供了时间点报告功能。
在这篇文章中,我们重点演示如何识别半结构化源 (JSON) 的更改数据并捕获完整的历史数据更改(SCD 类型 2)并将它们存储在 S3 数据湖中,使用 AWS胶水 和开放数据湖格式 达美网. 此实现支持以下用例:
- 跟踪具有开始和结束日期的 2 类 SCD,以识别当前和完整的历史记录,以及一个标志,以识别数据湖中已删除的记录(逻辑删除)
- 使用消费工具,例如 亚马逊雅典娜 无缝查询历史记录
解决方案概述
这篇文章使用示例员工数据集通过端到端用例演示了解决方案。 该数据集表示员工详细信息,例如 ID、姓名、地址、电话号码、是否是承包商等。 为演示 SCD 实施,请考虑以下假设:
- 数据工程团队每天收到的文件是记录的完整快照,不包含任何识别源记录更改的机制
- 该团队的任务是实施 SCD 类型 2 功能,以从源中识别新的、更新的和删除的记录,并保留数据湖中的历史变化
- 因为源系统不提供CDC能力,所以需要开发一种机制来识别新的、更新的和删除的记录,并将它们持久化到数据湖层
架构实现如下:
- 源系统在 S3 着陆桶中提取文件(通过使用提供的生成示例记录来模拟此步骤 AWS Lambda 功能进入着陆桶)
- AWS Glue 作业(Delta 作业)选择源数据文件并处理来自先前文件加载的更改数据(新插入、对现有记录的更新以及从源中删除的记录)到 S3 数据湖(处理层存储桶)
- 该架构采用开放的数据湖格式(Delta),将S3数据湖构建为Delta Lake,是可变的,因为新的变化可以更新,新的插入可以追加,源删除可以准确识别和标记与
delete_flag折扣值 - AWS Glue 爬虫对数据进行编目,Athena 可以查询这些数据
下图说明了我们的体系结构。

先决条件
在开始之前,请确保您具备以下先决条件:
部署解决方案
对于此解决方案,我们提供了一个 CloudFormation 模板,用于设置架构中包含的服务,以实现可重复部署。 此模板创建以下资源:
- 两个 S3 存储桶:一个用于存储样本员工数据的登陆存储桶和一个用于可变数据湖(Delta 湖)的处理层存储桶
- 用于生成样本记录的 Lambda 函数
- 一个 AWS Glue 提取、转换和加载 (ETL) 作业,用于处理从登陆存储桶到已处理存储桶的源数据
要部署解决方案,请完成以下步骤:
- 启动堆栈 启动 CloudFormation 堆栈:
![]()
- 输入堆栈名称。
- 选择 我承认AWS CloudFormation可能会使用自定义名称创建IAM资源.
- 创建堆栈.
CloudFormation 堆栈部署完成后,导航到 AWS CloudFormation 控制台以注意以下资源 输出 标签:
- 数据湖资源 – S3 存储桶
scd-blog-landing-xxxx和scd-blog-processed-xxxx(称为是scd-blog-landing和scd-blog-processed在本文的后续部分中) - 示例记录生成器 Lambda 函数 –
SampleDataGenaratorLambda-<CloudFormation Stack Name>(称为是SampleDataGeneratorLambda) - AWS Glue 数据目录数据库 –
deltalake_xxxxxx(称为是deltalake) - AWS Glue 增量作业 –
<CloudFormation-Stack-Name>-src-to-processed(称为是src-to-processed)
请注意,在您的账户中部署 CloudFormation 堆栈会产生 AWS 使用费。
测试 SCD 类型 2 实施
基础设施到位后,您就可以测试整体解决方案设计并从员工数据集中查询历史记录。 这篇文章旨在针对真实的客户用例实施,您每天都可以获得完整的快照数据。 我们测试 SCD 实施的以下几个方面:
- 为初始加载运行 AWS Glue 作业
- 模拟一个源没有变化的场景
- 通过添加新记录、修改和删除现有记录来模拟插入、更新和删除场景
- 模拟删除记录作为新插入返回的场景
生成示例员工数据集
要测试解决方案,在开始初始数据摄取之前,需要确定数据源。 为简化该步骤,已在您刚刚部署的 CloudFormation 堆栈中部署了一个 Lambda 函数。

打开功能,配置一个测试事件,默认 hello-world 模板事件 JSON,如以下屏幕截图所示。 在不对模板进行任何更改的情况下提供事件名称并保存测试事件。

测试 调用测试事件,该事件调用 Lambda 函数来生成示例记录。

当 Lambda 函数完成调用时,您将能够在登陆存储桶中看到以下示例员工数据集。
运行 AWS Glue 作业
确认您是否在路径中看到员工数据集 s3://scd-blog-landing/dataset/employee/. 您可以下载数据集并在 VS Code 等代码编辑器中将其打开。 以下是数据集的示例:
下载数据集并准备好,因为您将为将来的用例修改数据集以模拟插入、更新和删除。 为您生成的示例数据集将与您在前面的示例中看到的完全不同。
要运行作业,请完成以下步骤:
- 在 AWS Glue 控制台上,选择 工作机会 在导航窗格中。
- 选择工作
src-to-processed. - 点击 运行 标签,选择 运行.
首次运行 AWS Glue 作业时,该作业会从登陆存储桶路径中读取员工数据集,并将数据作为增量表提取到已处理的存储桶中。

作业完成后,您可以创建一个爬虫来查看初始数据加载。 以下屏幕截图显示了可用的数据库 数据库 页面上发布服务提醒。

- 爬行 在导航窗格中。
- 创建爬虫.

- 为您的爬虫命名
delta-lake-crawler,然后选择 下一页.

- 选择 未 对于已经映射到 AWS Glue 表的数据。
- 添加数据源.

- 点击 数据源 下拉菜单,选择 三角洲湖.
- 输入增量表的路径。
- 选择 创建本机表.
- 添加 Delta Lake 数据源.

- 下一页.

- 选择由 CloudFormation 模板创建的角色,然后选择 下一页.

- 选择由 CloudFormation 模板创建的数据库,然后选择 下一页.

- 创建爬虫.

- 选择您的爬虫并选择 运行.

查询数据
爬虫完成后,可以看到它创建的表。

要查询数据,请完成以下步骤:
- 选择员工表并在 行动 菜单中选择 查看数据.

您将被重定向到 Athena 控制台。 如果您没有最新的 Athena 引擎,请使用最新的 Athena 引擎创建一个新的 Athena 工作组。
- 下 行政和支持部门 在导航窗格中,选择 工作小组.

- 创建工作组.

- 为工作组提供名称,例如
DeltaWorkgroup. - 选择 雅典娜 SQL 作为引擎,然后选择 雅典娜引擎版本 3 查询引擎版本.

- 创建工作组.

- 创建工作组后,选择工作组 (
DeltaWorkgroup) 在 Athena 查询编辑器的下拉菜单中。

- 运行以下查询
employee表:
注意:在运行上述查询之前,从 CloudFormation 输出更新正确的数据库名称。
你可以观察到 employee 表有 25 条记录。 以下屏幕截图显示了带有一些样本记录的总员工记录。

Delta 表存储在 emp_key,它对每个更改都是唯一的,用于跟踪更改。 这 emp_key 为每次插入、更新和删除创建,并可用于查找与单个文件相关的所有更改 emp_id.
emp_key 使用SHA256哈希算法创建,如下代码所示:
执行插入、更新和删除
在对数据集进行更改之前,让我们再运行一次相同的作业。 假设来自源的当前负载与初始负载相同且没有变化,则 AWS Glue 作业不应对数据集进行任何更改。 作业完成后,运行前面的 Select 在 Athena 查询编辑器中查询并确认仍有 25 条具有以下值的活动记录:
- 包含该列的所有 25 条记录
isCurrent=true - 包含该列的所有 25 条记录
end_date=Null - 包含该列的所有 25 条记录
delete_flag=false
在您确认之前的作业使用这些值运行后,让我们修改我们的初始数据集,进行以下更改:
- 更改
isContractor标记为false(将其更改为true如果您的数据集已经显示false)emp_id=12. - 删除整行
emp_id=8(确保将记录保存在文本编辑器中,因为我们在另一个用例中使用该记录)。 - 复制行
emp_id=25并插入一个新行。 改变emp_id成为26,并确保也更改其他列的值。
进行这些更改后,员工源数据集类似于以下代码(为了便于阅读,我们只包含了前三个步骤中描述的更改记录):
- 现在,上传改变的
fake_emp_data.json文件到相同的源前缀。
- 将更改后的员工数据集上传到 Amazon S3 后,导航到 AWS Glue 控制台并运行该作业。
- 作业完成后,在 Athena 查询编辑器中运行以下查询,并确认总共有 27 条具有以下值的记录:
注意:在运行上述查询之前,从 CloudFormation 输出更新正确的数据库名称。

- 在 Athena 查询编辑器中运行另一个查询并确认返回了 4 条具有以下值的记录:
注意:在运行上述查询之前,从 CloudFormation 输出更新正确的数据库名称。

你会看到两条记录 emp_id=12:
- 一个
emp_id=12具有以下值的记录(对于作为初始加载的一部分摄取的记录):emp_key=44cebb094ef289670e2c9325d5f3e4ca18fdd53850b7ccd98d18c7a57cb6d4b4isCurrent=falsedelete_flag=falseend_date=’2023-03-02’
- 第二个
emp_id=12具有以下值的记录(对于作为源更改的一部分摄取的记录):emp_key=b60547d769e8757c3ebf9f5a1002d472dbebebc366bfbc119227220fb3a3b108isCurrent=truedelete_flag=falseend_date=Null(或空字符串)
记录为 emp_id=8 作为此运行的一部分在源中删除的那个将仍然存在,但对值进行以下更改:
isCurrent=falseend_date=’2023-03-02’delete_flag=true
将使用以下值插入新员工记录:
emp_id=26isCurrent=trueend_date=NULL(或空字符串)delete_flag=false
请注意 emp_key 实际表格中的值可能与此处提供的示例不同。
- 对于删除,我们检查基表中的 emp_id 以及新的源文件并内部连接 emp_key。
- 如果条件评估为真,我们将检查员工基表 emp_key 是否等于新更新的 emp_key,并获取当前未删除的记录(isCurrent=true 和 delete_flag=false)。
- 我们将新文件中的删除更改与所有匹配删除条件行的基表合并,并更新以下内容:
isCurrent=falsedelete_flag=trueend_date=current_date
请参见以下代码:
- 对于更新和插入,我们检查条件是否为基表
employee.emp_id等于new changes.emp_id和employee.emp_key等于new changes.emp_key, 而只检索当前记录。 - 如果此条件评估为
true, 然后我们得到当前记录 (isCurrent=true和delete_flag=false). - 我们通过更新以下内容来合并更改:
- 如果第二个条件评估为
true:isCurrent=falseend_date=current_date
- 或者,如果第二个条件的计算结果为,我们将按如下方式插入整行
false:emp_id=new record’s emp_keyemp_key=new record’s emp_keyfirst_name=new record’s first_namelast_name=new record’s last_nameaddress=new record’s addressphone_number=new record’s phone_numberisContractor=new record’s isContractorstart_date=current_dateend_date=NULL(或空字符串)isCurrent=truedelete_flag=false
- 如果第二个条件评估为
请参见以下代码:
作为最后一步,让我们将之前更改中删除的记录恢复到源数据集中,看看它是如何重新插入到 employee 数据湖中的表并观察如何维护完整的历史记录。
让我们修改上一步中更改的数据集并进行以下更改。
- 添加删除的
emp_id=8回到数据集.
进行这些更改后,我的员工源数据集类似于以下代码(为了便于阅读,我们只包含了上一步中描述的添加记录):
{"emp_id":8,"first_name":"Teresa","last_name":"Estrada","Address":"339 Scott ValleynGonzalesfort, PA 18212","phone_number":"435-600-3162","isContractor":false}
- 将更改后的员工数据集文件上传到相同的源前缀。

- 上传更改后
fake_emp_data.json数据集到 Amazon S3,导航到 AWS Glue 控制台并再次运行该作业。 - 作业完成后,在 Athena 查询编辑器中运行以下查询,并确认总共有 28 条具有以下值的记录:
注意:在运行上述查询之前,从 CloudFormation 输出更新正确的数据库名称。

- 运行以下查询并确认有 5 条记录:
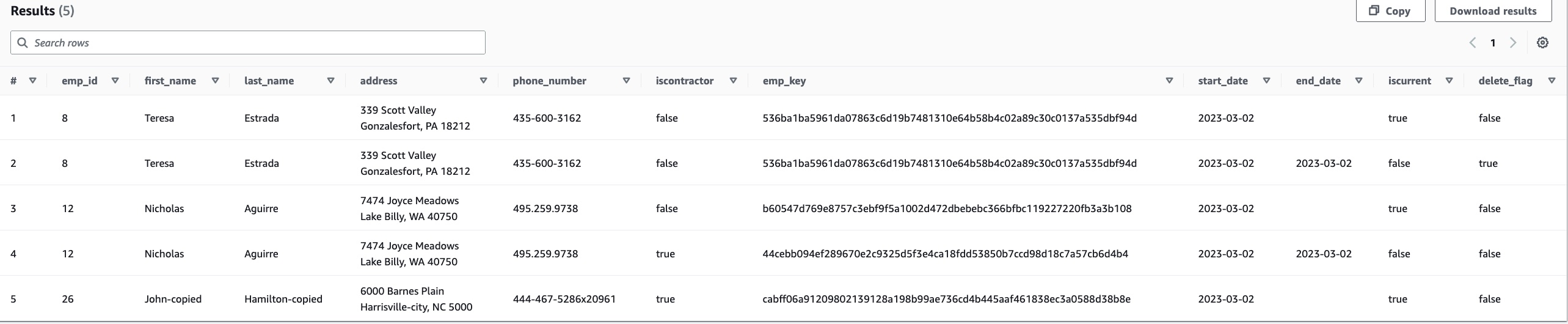
你会看到两条记录 emp_id=8:
- 一个
emp_id=8具有以下值的记录(已删除的旧记录):emp_key=536ba1ba5961da07863c6d19b7481310e64b58b4c02a89c30c0137a535dbf94disCurrent=falsedeleted_flag=trueend_date=’2023-03-02’
- 另一个
emp_id=8具有以下值的记录(上次运行时插入的新记录):emp_key=536ba1ba5961da07863c6d19b7481310e64b58b4c02a89c30c0137a535dbf94disCurrent=truedeleted_flag=falseend_date=NULL(或空字符串)
emp_key 实际表格中的值可能与此处提供的示例不同。 另请注意,因为这是在后续加载中重新插入的相同删除记录,没有任何更改,因此不会更改 emp_key.
最终用户示例查询
以下是一些示例最终用户查询,以演示如何遍历员工变更数据历史记录以进行报告:
- 查询1 – 检索当月(例如,2023 年 XNUMX 月)离开组织的所有员工的列表。

前面的查询将返回两个离开组织的员工记录。
- 查询2 – 检索当月(例如 2023 年 XNUMX 月)加入组织的新员工列表。
注意:在运行上述查询之前,从 CloudFormation 输出更新正确的数据库名称。

前面的查询将返回 23 个加入组织的活跃员工记录。
- 查询3 – 查找组织中任何给定员工的历史记录(在本例中为员工 18)。
注意:在运行上述查询之前,从 CloudFormation 输出更新正确的数据库名称。

在前面的查询中,我们可以观察到员工 18 在离开组织之前对其员工记录进行了两次更改。
请注意,此示例中提供的数据结果与您根据 Lambda 函数生成的示例数据在特定记录中看到的结果不同。
清理
当您完成此解决方案的试验后,清理您的资源,以防止产生 AWS 费用:
- 清空 S3 存储桶。
- 从 AWS CloudFormation 控制台删除堆栈。
结论
在本文中,我们演示了当源系统无法提供变更数据捕获功能时,如何使用 AWS 识别半结构化数据源的更改数据并在 S2 Delta Lake 上保留历史更改(SCD 类型 3)胶水。 您可以进一步扩展此解决方案,使下游应用程序能够根据数据湖中捕获的 CDC 数据构建其他自定义项。
此外,您可以使用以下方法将此解决方案扩展为编排的一部分 AWS步骤功能 或您的组织熟悉的其他常用协调器。 您还可以通过在适当的地方添加分区来扩展此解决方案。 您还可以通过以下方式维护增量表 压实 小文件。
关于作者
 尼思·戈文达西万,是 AWS 专业服务的数据湖架构师,他通过实施大数据和分析解决方案帮助客户开始他们的现代数据架构之旅。 工作之余,Nith 是一名狂热的板球迷,业余时间几乎观看所有板球比赛,喜欢长途驾驶和国际旅行。
尼思·戈文达西万,是 AWS 专业服务的数据湖架构师,他通过实施大数据和分析解决方案帮助客户开始他们的现代数据架构之旅。 工作之余,Nith 是一名狂热的板球迷,业余时间几乎观看所有板球比赛,喜欢长途驾驶和国际旅行。
 维杰维尔普拉 是 AWS 专业服务的数据架构师。 他帮助客户实施大数据和分析解决方案。 工作之余,他喜欢与家人共度时光、旅行、远足和骑自行车。
维杰维尔普拉 是 AWS 专业服务的数据架构师。 他帮助客户实施大数据和分析解决方案。 工作之余,他喜欢与家人共度时光、旅行、远足和骑自行车。
 斯里哈什·阿达里 是 Amazon Web Services (AWS) 的高级解决方案架构师,他帮助客户从业务成果逆向工作,以在 AWS 上开发创新解决方案。 多年来,他帮助多个客户进行跨行业垂直的数据平台转型。 他的核心专业领域包括技术战略、数据分析和数据科学。 在业余时间,他喜欢运动、狂看电视节目和弹奏 Tabla。
斯里哈什·阿达里 是 Amazon Web Services (AWS) 的高级解决方案架构师,他帮助客户从业务成果逆向工作,以在 AWS 上开发创新解决方案。 多年来,他帮助多个客户进行跨行业垂直的数据平台转型。 他的核心专业领域包括技术战略、数据分析和数据科学。 在业余时间,他喜欢运动、狂看电视节目和弹奏 Tabla。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/implement-slowly-changing-dimensions-in-a-data-lake-using-aws-glue-and-delta/