
概要
人工知能 (AI) はさまざまな業界で大きな進歩を遂げており、ヘルスケアも例外ではありません。 ヘルスケアにおける AI の中で最も有望な分野の XNUMX つは自然言語処理 (NLP) です。これは、より効率的で正確なデータ分析とコミュニケーションを促進することで、患者ケアに革命をもたらす可能性を秘めています。
NLP は、ヘルスケアの分野におけるゲーム チェンジャーであることが証明されています。 NLP は、医療提供者が患者ケアを提供する方法を変革しています。 集団の健康管理から病気の検出まで、NLP は医療従事者が情報に基づいた意思決定を行い、より良い治療結果を提供できるよう支援しています。
学習目標
- ヘルスケアにおける NLP と AI の使用の理解と分析
- NLP の基本を理解する
- ヘルスケアで一般的に使用されるいくつかの NLP ライブラリについて知る
- ヘルスケアにおける NLP のユースケースについて学ぶ
この記事は、の一部として公開されました データサイエンスブログソン.
目次
- ヘルスケアで AI と NLP を使用する動機
- 自然言語処理とは何ですか?
- NLP で使用されるさまざまな手法
3.1 ルールベースのテクニック
3.2 機械学習モデルを用いた統計手法
3.3 転移学習 - さまざまな NLP ライブラリとそのフレームワーク
- 大規模言語モデル (LLM) とは?
- 臨床テキストにおける NLP – 異なるアプローチの必要性
- ヘルスケア業界で使用されるいくつかの NLP ライブラリ
- 臨床データセットを理解する
- さまざまな種類の臨床データとは?
- ヘルスケア業界における NLP のユースケースとアプリケーション
- クリニカル テキストで NLP パイプラインを構築する方法
11.1 ソリューション設計
11.2 ステップバイステップのコード - まとめ
ヘルスケアで AI と NLP を使用する動機
使用の動機 AI 医療における NLP は、医療費を削減しながら、患者のケアと治療結果を改善することに根ざしています。 ヘルスケア業界は、EMR、臨床ノート、健康関連のソーシャル メディアの投稿など、患者の健康と治療結果に関する貴重な洞察を提供できる膨大な量のデータを生成します。 ただし、このデータの多くは構造化されておらず、手動で分析することは困難です。
さらに、ヘルスケア業界は、人口の高齢化、慢性疾患の割合の増加、医療専門家の不足など、いくつかの課題に直面しています。
これらの課題により、より効率的かつ効果的な医療提供の必要性が高まっています。
NLP は、構造化されていない医療データから貴重な洞察を提供することで、患者のケアと治療結果を改善し、医療従事者がより多くの情報に基づいて臨床上の意思決定を行うのをサポートできます。
自然言語処理とは何ですか?
自然言語処理 (NLP) は、コンピューターと人間の言語間の相互作用を扱う人工知能 (AI) のサブフィールドです。 計算技術を使用して、人間の言語を分析、理解、生成します。 NLP は、音声認識、機械翻訳、感情分析、テキスト要約など、多くのアプリケーションで使用されています。
ここでは、さまざまな NLP テクニック、ライブラリ、およびフレームワークについて説明します。
NLP で使用されるさまざまな手法
NLP 業界で一般的に使用されている XNUMX つの手法があります。
1. ルールベースの手法: 定義済みの文法規則と辞書に依存する
2. 統計手法: 機械学習アルゴリズムを使用して言語を分析および理解する
3. を使用した大規模な言語モデル 転移学習
これは、さまざまな NLP タスクを備えた標準の NLP パイプラインです。
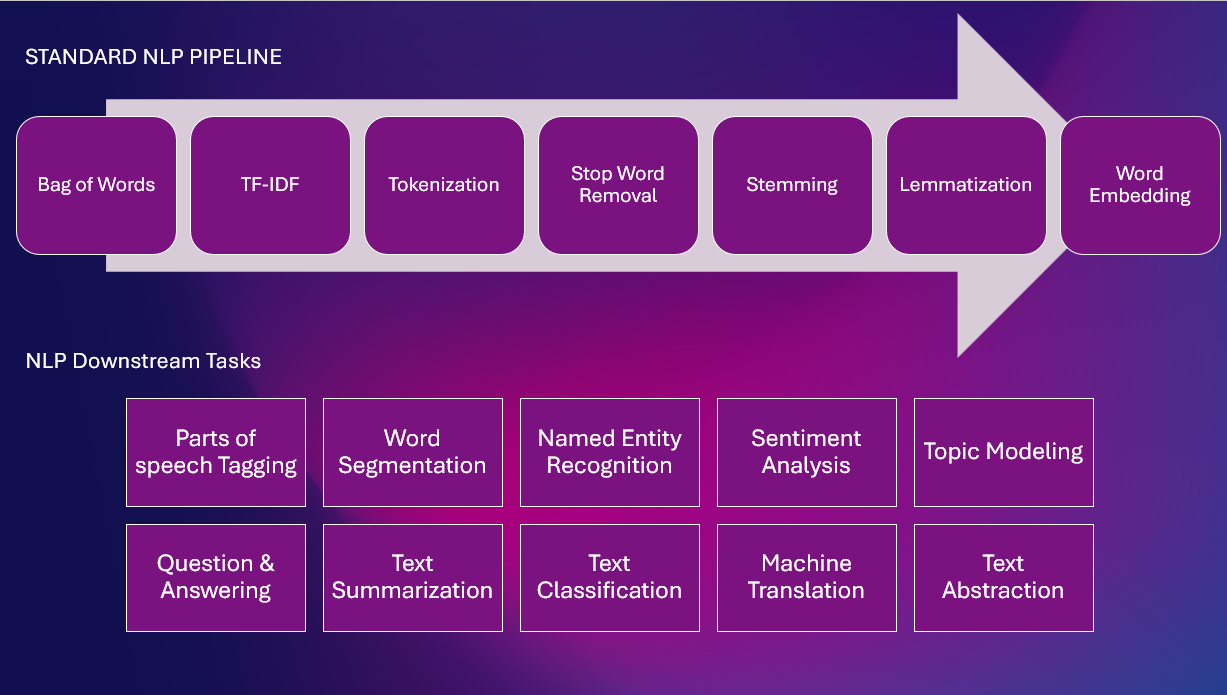
ルールベースの手法
これらの手法には、一連の手作りのルールまたはパターンを作成して、テキストから意味のある情報を抽出することが含まれます。 ルールベースのシステムは通常、名前付きエンティティや特定のキーワードなどのターゲット情報に一致する特定のパターンを定義し、それらのパターンに基づいてその情報を抽出することによって機能します。 ルールベースのシステム 高速で信頼性が高く、簡単ですが、定義されたルールの品質と数によって制限され、保守と更新が難しい場合があります。
たとえば、名前付きエンティティ認識のためのルールベースのシステムは、テキスト内の固有名詞を識別し、それらを人、場所、組織、病気、薬などの事前定義されたエンティティ タイプに分類するように設計できます。システムはシリーズを使用します。人名の大文字化や組織の特定のキーワードなど、各エンティティ タイプの条件に一致するテキスト内のパターンを識別するためのルール。
機械学習モデルを使用した統計手法
これらの手法では、統計アルゴリズムを使用してデータのパターンを学習し、それらのパターンに基づいて予測を行います。 機械学習モデルは、大量の注釈付きデータでトレーニングできるため、ルールベースのシステムよりも柔軟でスケーラブルになります。 NLP では、次のようないくつかのタイプの機械学習モデルが使用されます。 決定木, ランダムな森, サポートベクターマシン, ニューラルネットワーク.
たとえば、感情分析用の機械学習モデルは、各テキストが肯定的、否定的、または中立としてタグ付けされた注釈付きテキストの大規模なコーパスでトレーニングできます。 モデルは、肯定的なテキストと否定的なテキストを区別するデータ内の統計的パターンを学習し、それらのパターンを使用して、目に見えない新しいテキストを予測します。 このアプローチの利点は、ルールで明示的に定義されていない感情パターンをモデルが識別できることです。
転移学習
これらの手法は、ルールベースのモデルと機械学習モデルの長所を組み合わせたハイブリッド アプローチです。 転移学習では、特定のタスクまたはドメインを微調整するための開始点として、事前にトレーニングされた機械学習モデル (大量のテキスト コーパスでトレーニングされた言語モデルなど) を使用します。 このアプローチは、事前トレーニング済みのモデルから学習した一般的な知識を活用して、トレーニングに必要なラベル付きデータの量を減らし、特定のタスクでより迅速かつ正確な予測を可能にします。
たとえば、名前付きエンティティ認識への転移学習アプローチは、注釈付きの医療テキストの小さなコーパスで事前にトレーニングされた言語モデルを微調整できます。 モデルは、事前トレーニング済みのモデルから学習した一般的な知識から開始し、その重みを調整して、医療テキストのパターンによりよく一致させます。 このアプローチにより、トレーニングに必要なラベル付きデータの量が削減され、医療分野での名前付きエンティティ認識のより正確なモデルが得られます。
さまざまな NLP ライブラリとそのフレームワーク
さまざまなライブラリが、幅広い NLP 機能を提供します。 そのような :

自然言語処理 (NLP) ライブラリとフレームワークは、NLP アプリケーションの開発と展開を支援するソフトウェア ツールです。 いくつかの NLP ライブラリとフレームワークが利用可能で、それぞれに長所、短所、重点分野があります。
これらのツールは、サポートするアルゴリズムの複雑さ、処理できるモデルのサイズ、使いやすさ、カスタマイズの程度によって異なります。
大規模言語モデル (LLM) とは?
大規模な言語モデルは、大量のデータでトレーニングされます。 人間のようなテキストを生成し、幅広い NLP タスクを高精度で実行できます。
大規模な言語モデルの例とそれぞれの簡単な説明を次に示します。
GPT-3 (生成事前トレーニング済みトランスフォーマー 3): OpenAI によって開発された GPT-3 は、ディープ ラーニング アルゴリズムを使用して人間のようなテキストを生成するトランスフォーマー ベースの大規模な言語モデルです。 大量のテキスト データ コーパスでトレーニングされているため、プロンプトに基づいて、一貫性のある文脈的に適切なテキスト応答を生成できます。
ベルト (変圧器からの双方向エンコーダ表現): Google によって開発された BERT は、大規模なテキスト データ コーパスで事前トレーニングされたトランスフォーマー ベースの言語モデルです。 センテンス内の単語間のコンテキストと関係をエンコードすることにより、固有表現認識、質問応答、テキスト分類など、幅広い NLP タスクでうまく機能するように設計されています。
ロベルタ (堅牢に最適化された BERT アプローチ): Facebook AI によって開発された RoBERTa は、NLP タスク用に微調整および最適化された BERT のバリアントです。 これは、より大きなテキスト データのコーパスでトレーニングされており、BERT とは異なるトレーニング戦略を使用しているため、NLP ベンチマークでのパフォーマンスが向上しています。
ELMo (言語モデルからの埋め込み): Allen Institute for AI によって開発された ELMo は、双方向の LSTM (Long Short-Term Memory) ネットワークを使用して、テキスト データの大規模なコーパスから言語表現を学習する、コンテキスト化された深い単語表現モデルです。 ELMo は、特定の NLP タスク用に微調整したり、他の機械学習モデルの特徴抽出器として使用したりできます。
ULMFiT (ユニバーサル言語モデルの微調整): FastAI によって開発された ULMFiT は、少量のタスク固有の注釈付きデータを使用して、特定の NLP タスクで事前トレーニング済みの言語モデルを微調整する転移学習手法です。 ULMFiT は、幅広い NLP ベンチマークで最先端のパフォーマンスを達成しており、NLP における転移学習の主要な例と見なされています。
臨床テキストにおける NLP: 異なるアプローチの必要性
臨床テキストは構造化されていないことが多く、多くの医療専門用語や頭字語が含まれているため、従来の NLP モデルが理解して処理することは困難です。 さらに、臨床テキストには、病気、薬、患者情報、診断、治療計画などの重要な情報が含まれていることが多く、この医療情報を正確に抽出して理解できる特殊な NLP モデルが必要です。
臨床テキストに異なる NLP モデルが必要なもう XNUMX つの理由は、EHR、臨床ノート、放射線レポートなど、統合する必要があるさまざまなソースにまたがる大量のデータが含まれていることです。 これには、テキストを処理して理解し、さまざまなソース間でデータをリンクして統合し、臨床的に受け入れられる関係を確立できるモデルが必要です。
最後に、臨床テキストには機密性の高い患者情報が含まれていることが多く、HIPAA などの厳格な規制によって保護する必要があります。 臨床テキストの処理に使用される NLP モデルは、有用な洞察を提供しながら、患者の機密情報を識別して保護できなければなりません。
ヘルスケア業界で使用されるいくつかの NLP ライブラリ
医療内のテキスト データには、臨床テキストやその他の医療文書などのさまざまなソースから医療情報を抽出できる特殊な自然言語処理 (NLP) システムが必要です。
以下は、医療分野に固有の NLP ライブラリとモデルのリストです。
スペイシー: これは、医療分野を含むさまざまな分野向けのすぐに使えるモデルを提供するオープンソースの NLP ライブラリです。
シスパシー: 科学および生物医学のテキストに特化してトレーニングされた spaCy の特殊バージョンであり、医療テキストの処理に最適です。
バイオバート: 生物医学分野向けに特別に設計された事前トレーニング済みの変換器ベースのモデル。 Wiki + Books + PubMed + PMC で事前にトレーニングされています。
クリニカルBERT: MIMIC-III データベースから臨床メモと退院の概要を処理するように設計された別の事前トレーニング済みモデル。
Med7: 電子医療記録 (EHR) でトレーニングされ、診断、投薬、臨床検査を含む XNUMX つの重要な臨床概念を抽出する変換器ベースのモデル。
DisMod-ML: NLP 手法を使用して医療テキストを処理する疾患モデリングの確率モデリング フレームワーク。
メディック: テキストから医療情報を抽出するためのルールベースの NLP システム。
これらは、特に医療分野向けに設計された一般的な NLP ライブラリとモデルの一部です。 事前トレーニング済みのモデルからルールベースのシステムまで、さまざまな機能を提供し、医療機関が医療テキストを効果的に処理するのに役立ちます。
NER モデルでは、spaCy と Scispacy を使用します。 これらのライブラリは、Google colab またはローカル インフラストラクチャで比較的簡単に実行できます。
BioBERT および ClinicalBERT のリソース集約型の大規模言語モデルには、GPU とより高度なインフラストラクチャが必要です。
臨床データセットを理解する
医療テキスト データは、電子カルテ (EHR)、医学雑誌、臨床ノート、医療 Web サイト、データベースなど、さまざまなソースから取得できます。 これらのソースの中には、NLP モデルのトレーニングに使用できる公開データセットを提供するものもあれば、データにアクセスする前に承認と倫理的考慮が必要なものもあります。 医療テキスト データのソースには、次のものがあります。
1. などのオープンソースの医療コーパス MIMIC-Ⅲデータベース は、2001 年から 2012 年の間にベス イスラエル ディーコネス メディカル センターで治療を受けた患者から得た、オープンにアクセスできる大規模な電子医療記録 (EHR) データベースです。データベースには、患者の人口統計、バイタル サイン、臨床検査、投薬、手順、看護師や医師などの医療専門家からのメモ。 さらに、データベースには、ICU の種類、滞在期間、結果など、患者の ICU 滞在に関する情報が含まれています。 MIMIC-III のデータは匿名化されており、研究目的で使用して、予測モデルや臨床意思決定支援システムの開発をサポートできます。
2. 国立医学図書館 ClinicalTrials.gov ウェブサイトには、臨床試験データと疾患監視データがあります。
3. 国立衛生研究所の国立医学図書館、国立バイオテクノロジー情報センター (NCBI)、および世界保健機関(誰)
4. 病院、診療所、製薬会社などの医療機関や組織は、電子カルテ、臨床記録、医療記録、医療レポートを通じて大量の医療テキスト データを生成します。
5. PubMed や CINAHL などの医学研究ジャーナルやデータベースには、膨大な量の医学研究論文や抄録が掲載されています。
6. Twitter などのソーシャル メディア プラットフォームは、患者の視点、医薬品のレビュー、および経験に関するリアルタイムの洞察を提供できます。
医療テキスト データを使用して NLP モデルをトレーニングするには、データの品質と関連性を考慮し、データが適切に前処理およびフォーマットされていることを確認することが重要です。 さらに、機密性の高い医療情報を取り扱う際には、倫理的および法的考慮事項を順守することが重要です。
さまざまな種類の臨床データとは?
ヘルスケアでは、いくつかのタイプの臨床データが一般的に使用されています。

臨床データとは、患者の病歴、診断、治療、検査結果、画像検査、およびその他の関連する健康情報を含む、個人の医療に関する情報を指します。
EHR/EMRデータ 人口統計データ (これには、年齢、性別、民族性、連絡先情報などの個人情報が含まれます)、患者生成データ (このタイプのデータは、患者報告アウトカム測定および患者を通じて収集された情報を含む、患者自身によって生成されます) にリンクされています。 -生成された健康データ。)
その他のデータセットは次のとおりです。
ゲノムデータ: このタイプは、DNA 配列やマーカーなど、個人の遺伝情報に関連しています。
ウェアラブル デバイス データ: このデータには、フィットネス トラッカーや心臓モニターなどのウェアラブル デバイスから収集された情報が含まれます。
各タイプの臨床データは、患者の健康状態を包括的に把握する上で独自の役割を果たし、医療提供者や研究者がさまざまな方法で使用して、患者のケアを改善し、治療の決定を通知します。
ヘルスケア業界における NLP のユースケースとアプリケーション
自然言語処理 (NLP) は医療業界で広く採用されており、いくつかのユースケースがあります。 著名なもののいくつかは次のとおりです。
人口の健康: NLP を使用して、医療記録、調査、請求データなどの大量の非構造化医療データを処理し、パターン、相関関係、洞察を特定できます。 これは、人々の健康状態を監視し、病気を早期に発見するのに役立ちます。
患者ケア: NLP を使用して、患者の電子医療記録 (EHR) を処理し、診断、投薬、症状などの重要な情報を抽出できます。 この情報は、患者のケアを改善し、個別化された治療を提供するために使用できます。
病気の検出: NLP を使用して、科学記事、ニュース記事、ソーシャル メディアの投稿などの大量のテキスト データを処理し、感染症の発生を検出できます。
臨床意思決定支援システム (CDSS): NLP を使用して患者の電子医療記録を分析し、医療提供者にリアルタイムの意思決定支援を提供できます。 これにより、可能な限り最良の治療オプションを提供し、全体的なケアの質を向上させることができます。
臨床試験: NLP は、臨床試験データを処理して、相関関係と潜在的な新しい治療法を特定できます。
薬物有害事象: NLP を使用して大量の薬物安全性データを処理し、有害事象や薬物相互作用を特定できます。
プレシジョン ヘルス: NLP を使用してゲノム データと医療記録を処理し、個々の患者に合わせた治療オプションを特定できます。
医療従事者の効率改善: NLP は、医療コーディング、データ入力、請求処理などの日常的なタスクを自動化できるため、医療専門家はより良い患者ケアの提供に専念できます。
これらは、NLP がヘルスケア業界にどのように革命をもたらしたかのほんの一例です。 NLP テクノロジーが進歩し続けるにつれて、将来的に医療における NLP のより革新的な使用法が見られることが期待できます。
クリニカル テキストで NLP パイプラインを構築する方法
SciSpacy NER Model for Clinical Text を使用して段階的な Spacy パイプラインを開発します。
DevOps Tools Engineer試験のObjective : このプロジェクトは、SciSpacy を利用してカスタムの名前付きエンティティ認識を臨床テキストで実行する NLP パイプラインを構築することを目的としています。
結果: 結果として、臨床テキストから疾患、薬、および薬の投与量に関する情報を抽出し、さまざまな NLP ダウンストリーム アプリケーションで利用できます。
ソリューション設計:
以下は、Clinical Text からエンティティ情報を抽出するための高レベルのソリューションです。 NER 抽出は、ほとんどの NLP パイプラインで使用される重要な NLP タスクです。
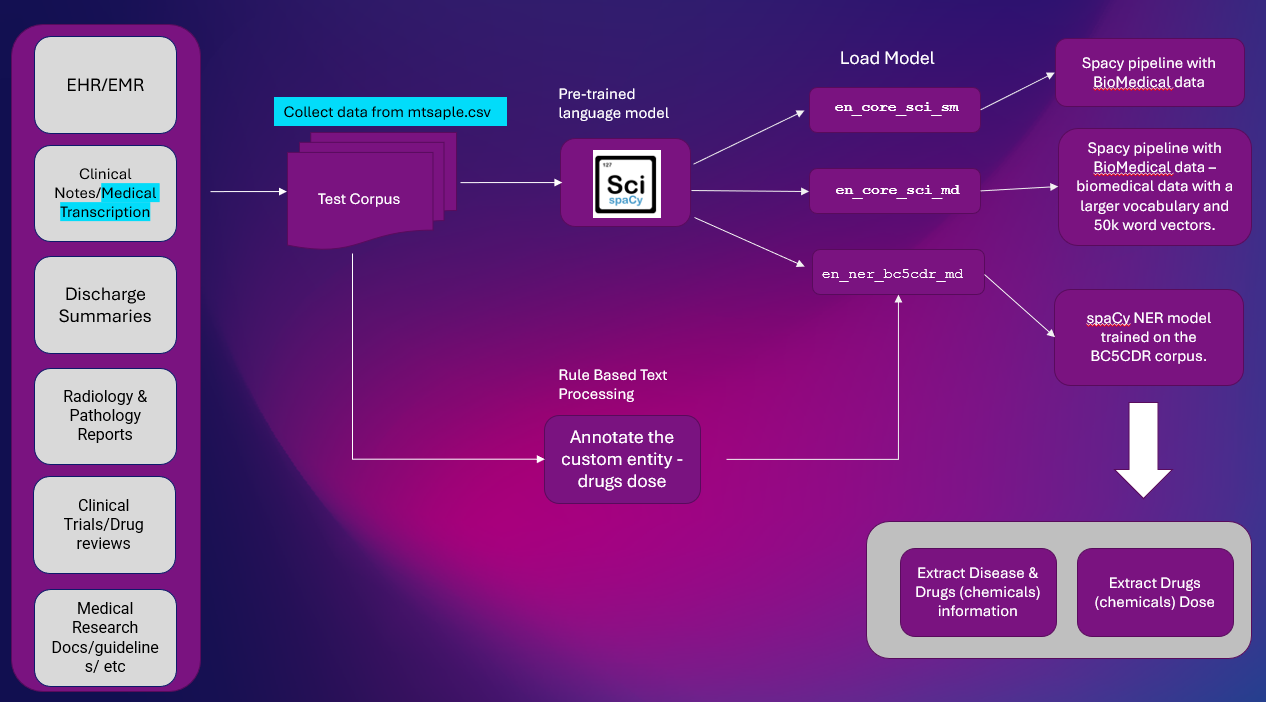
プラットフォーム: グーグルコラボ
NLP ライブラリ: SpaCy & SciSpacy
データセット: mtsample.csv (mtsample から破棄されたデータ)。
私達は使ったことがある シスパシー 事前訓練された NER モデル en_ner_bc5cdr_md-0.5.1 病気や薬を抽出する。 薬物は化学物質として抽出されます。
en_ner_bc5cdr_md-0.5.1 は、生物医学分野における固有表現認識 (NER) の spaCy モデルです。
「bc5cdr」は BC5CDR コーパス、モデルのトレーニングに使用される生物医学テキスト コーパス。 名前の「md」は生物医学ドメインを指します。 名前の「0.5.1」はモデルのバージョンを表します。
mtsample.csv のサンプル「転写」テキストを使用し、ルールベースのパターンを使用して注釈を付けて、薬物投与量を抽出します。
ステップバイステップのコード:
spacy & scispacy パッケージをインストールします。 spaCy モデルは、トークン化、品詞のタグ付け、名前付きエンティティの認識など、特定の NLP タスクを実行するように設計されています。
!pip install -U spacy !pip install scispacy
cispacy ベース モデルと NER モデルをインストールする
en_ner_bc5cdr_md-0.5.1 モデルは、生物医学テキスト内の名前付きエンティティ (病気、遺伝子、薬など) を化学物質として認識するように特別に設計されています。
このモデルは、情報抽出、テキスト分類、質問応答など、生物医学分野の NLP タスクに役立ちます。
!pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_sm-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_md-0.5.1.tar.gz !pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_ner_bc5cdr_md-0.5.1.tar.gz
他のパッケージをインストールする
pip インストール レンダリング
パッケージのインポート
import scispacy import spacy #コアモデル import en_core_sci_sm import en_core_sci_md
#NER 固有のモデル import en_ner_bc5cdr_md #spacy からデータを抽出および表示するためのツール import displacecy import pandas as pd
Pythonコード:
サンプル データを使用してモデルをテストする
# 使用する特定の文字起こしを選択 (行 3、列 "transcription") し、scispacy NER モデルをテストします text = mtsample_df.loc[10, "transcription"]

特定のモデルをロード: en_core_sci_sm してテキストを渡す
nlp_sm = en_core_sci_sm.load() doc = nlp_sm(テキスト)
#結果表示
エンティティ抽出 displace_image = displacey.render(doc, jupyter=True,style='ent')

エンティティがここでタグ付けされていることに注意してください。 主に医学用語。 ただし、これらは一般的なエンティティです。
次に、特定のモデルをロードします: en_core_sci_md とテキストを渡します
nlp_md = en_core_sci_md.load() doc = nlp_md(テキスト)
#結果のエンティティ抽出を表示
displace_image = displacey.render(doc, jupyter=True,style='ent')

今回は、数値も en_core_sci_md によってエンティティとしてタグ付けされています。
特定のモデルをロード: en_ner_bc5cdr_md をインポートしてテキストを渡す
nlp_bc = en_ner_bc5cdr_md.load() doc = nlp_bc(text) #結果のエンティティ抽出を表示する displacy_image = displacy.render(doc, jupyter=True,style='ent')

現在、XNUMX つの医療エンティティがタグ付けされています: 疾患と化学物質 (薬物)。
エンティティを表示する
doc.ents の ent の print("TEXT", "START", "END", "ENTITY TYPE"): print(ent.text, ent.start_char, ent.end_char, ent.label_)
テキスト開始終了エンティティ タイプ
病的肥満 26 40 DISEASE
病的肥満 70 84 DISEASE
減量 400 411 病気
マルケイン 1256 1264 ケミカル
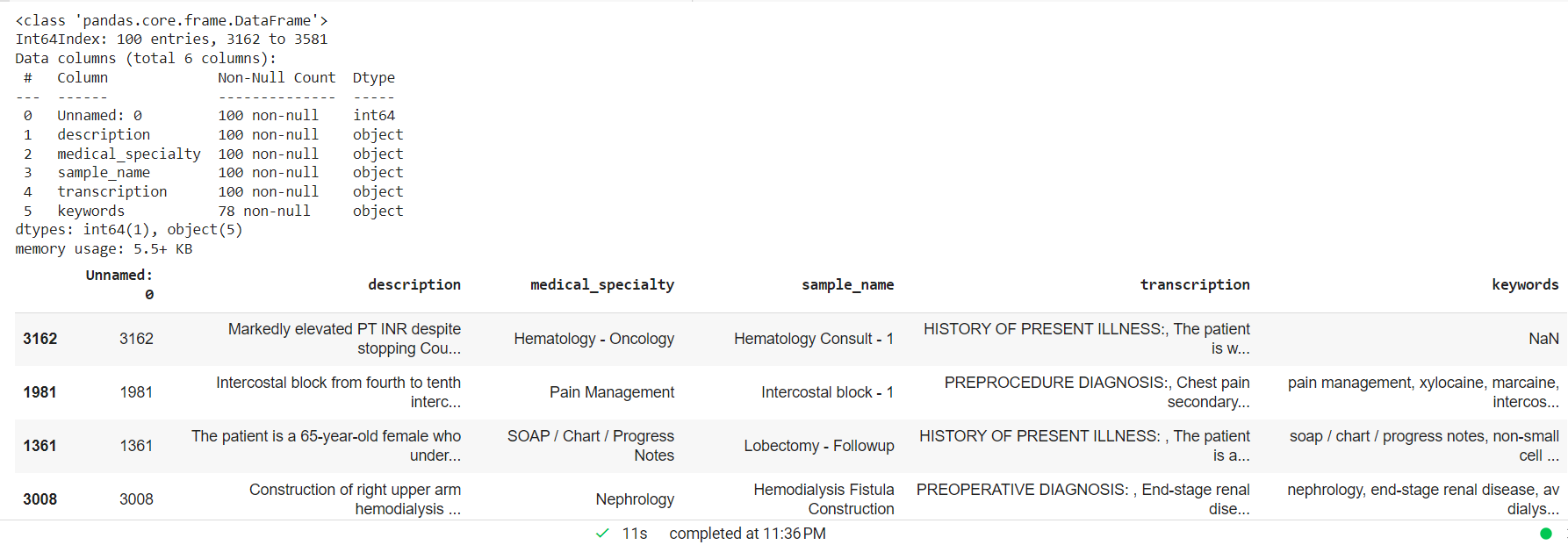
臨床テキストを処理して NAN 値を削除し、カスタム エンティティ モデル用のランダムな小さなサンプルを作成します。
mtsample_df.dropna(subset=['transcription'], inplace=True) mtsample_df_subset = mtsample_df.sample(n=100, replace=False, random_state=42) mtsample_df_subset.info() mtsample_df_subset.head()
spaCyマッチャー – ルールベースのマッチングは正規表現の使用法に似ていますが、spaCy は追加の機能を提供します。 ドキュメント内のトークンと関係を使用すると、NER モデルを利用してエンティティを含むパターンを識別できます。 目標は、テキストから医薬品の名前とその投与量を見つけることです。これは、基準やガイドラインと比較することで、投薬ミスを検出するのに役立ちます。
目標は、テキストから医薬品の名前とその投与量を見つけることです。これは、基準やガイドラインと比較することで、投薬ミスを検出するのに役立ちます。
spacy.matcherからインポートマッチャー
pattern = [{'ENT_TYPE':'CHEMICAL'}, {'LIKE_NUM': True}, {'IS_ASCII': True}] matcher = Matcher(nlp_bc.vocab) matcher.add("DRUG_DOSE", [パターン])
mtsample_df_subset['transcription'] 内の転写用: doc = nlp_bc(transcription) マッチ = matcher(doc) for match_id、start、end マッチ: string_id = nlp_bc.vocab.strings[match_id] # 文字列表現を取得する span = doc[start :end] # 一致したスパンに薬を追加する print(span.text, start, end, string_id,) # nt の病気と薬を doc.ents に追加: print(ent.text, ent.start_char, ent.end_char, ent 。ラベル_)
出力には、臨床テキスト サンプルから抽出されたエンティティが表示されます。
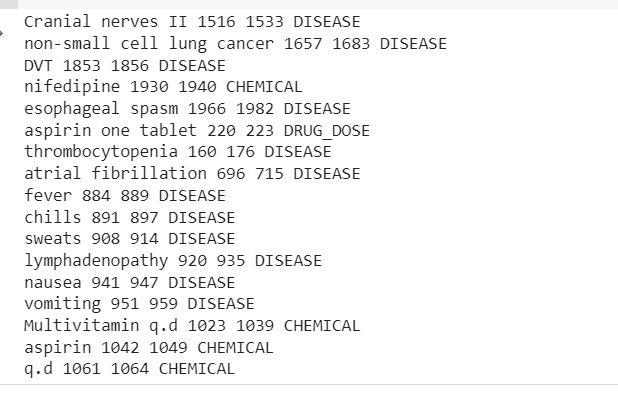
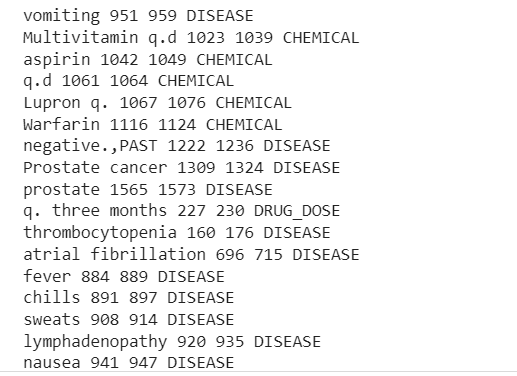
これで、抽出されたパイプラインが表示されます 病気、薬(化学物質)、および薬 - 投与量 臨床テキストからの情報。
いくつかの誤分類がありますが、より多くのデータを使用してモデルのパフォーマンスを向上させることができます。
これらの医療エンティティを、疾患の検出、予測分析、臨床意思決定支援システム、医療テキストの分類、要約、質問応答などのさまざまなタスクで使用できるようになりました。
まとめ
1. この記事では、複雑な医療テキスト データを理解するのに役立つ、医療における NLP の主要な機能のいくつかを調べました。
また、scispaCy と spaCy を実装し、事前トレーニング済みの NER モデルとルールベースのマッチャーを使用してシンプルなカスタム NER モデルを構築しました。 ここでは XNUMX つの NER モデルのみを取り上げましたが、他にも多数のモデルが利用可能であり、膨大な量の追加機能を発見することができます。
2. scispaCy フレームワーク内には、略語の検出、依存関係の解析の実行、個々の文の識別など、探求すべき多数の追加の手法があります。
3. ヘルスケア向け NLP の最新のトレンドには、BioBERT や ClinicalBert などのドメイン固有モデルの開発や、GPT-3 などの大規模言語モデルの使用が含まれます。 これらのモデルは高レベルの精度と効率性を提供しますが、それらを使用すると、バイアス、プライバシー、およびデータの制御に関する懸念も生じます。
AI言語モデルを活用してコードのデバッグからデータの異常検出まで、 (OpenAI によって開発された高度な会話型 AI モデル) は、すでに NLP の世界に大きな影響を与えています。 このモデルは、インターネットからの大量のテキスト データでトレーニングされ、受け取った入力に基づいて人間のようなテキスト レスポンスを生成する機能を備えています。 質問応答、要約、翻訳など、さまざまなタスクに使用できます。 また、モデルは、コードの生成や記事の作成など、特定のユース ケースに合わせて微調整され、これらの特定の領域でのパフォーマンスが向上します。
5. しかし、その多くの利点にもかかわらず、ヘルスケアにおける NLP には課題がないわけではありません。 NLP モデルの正確性と公平性を確保し、データのプライバシーに関する懸念を克服することは、ヘルスケアにおける NLP の可能性を完全に実現するために対処する必要がある課題の一部です。
6. NLP には多くの利点があるため、医療従事者がワークフローに NLP を取り入れて組み込むことは不可欠です。 克服すべき多くの課題がありますが、ヘルスケアにおける NLP は注目して投資する価値のあるトレンドであることは確かです。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/02/extracting-medical-information-from-clinical-text-with-nlp/