
Det här inlägget är skrivet av Goktug Cinar, Michael Binder och Adrian Horvath från Bosch Center for Artificial Intelligence (BCAI).
Intäktsprognoser är en utmanande men ändå avgörande uppgift för strategiska affärsbeslut och finansiell planering i de flesta organisationer. Ofta utförs intäktsprognoser manuellt av finansanalytiker och är både tidskrävande och subjektivt. Sådana manuella ansträngningar är särskilt utmanande för storskaliga, multinationella företagsorganisationer som kräver intäktsprognoser över ett brett spektrum av produktgrupper och geografiska områden på flera nivåer av granularitet. Detta kräver inte bara noggrannhet utan också hierarkisk koherens i prognoserna.
Bosch är ett multinationellt företag med enheter verksamma inom flera sektorer, inklusive fordonsindustrin, industriella lösningar och konsumentvaror. Med tanke på effekten av korrekta och sammanhängande intäktsprognoser på sund affärsverksamhet, Bosch Center for Artificiell Intelligens (BCAI) har investerat kraftigt i användningen av maskininlärning (ML) för att förbättra effektiviteten och noggrannheten i ekonomiska planeringsprocesser. Målet är att lindra de manuella processerna genom att tillhandahålla rimliga intäktsprognoser via ML, med endast enstaka justeringar som behövs av finansanalytikerna som använder sin bransch- och domänkunskap.
För att uppnå detta mål har BCAI utvecklat ett internt prognosramverk som kan tillhandahålla storskaliga hierarkiska prognoser via skräddarsydda ensembler av ett brett utbud av basmodeller. En meta-lärare väljer de bäst presterande modellerna baserat på funktioner som extraherats från varje tidsserie. Prognoserna från de valda modellerna beräknas sedan i medeltal för att få den aggregerade prognosen. Den arkitektoniska designen är modulariserad och utbyggbar genom implementeringen av ett REST-liknande gränssnitt, vilket möjliggör kontinuerlig prestandaförbättring genom inkludering av ytterligare modeller.
BCAI samarbetade med Amazon ML Solutions Lab (MLSL) för att införliva de senaste framstegen inom djupa neurala nätverk (DNN)-baserade modeller för intäktsprognoser. De senaste framstegen inom neurala prognosmakare har visat på toppmodern prestanda för många praktiska prognosproblem. Jämfört med traditionella prognosmodeller kan många neurala prognosmakare införliva ytterligare kovariater eller metadata för tidsserien. Vi inkluderar CNN-QR och DeepAR+, två hyllmodeller i Amazon Prognos, samt en anpassad Transformer-modell tränad med Amazon SageMaker. De tre modellerna täcker en representativ uppsättning av kodarryggraden som ofta används i neurala prognosmakare: faltningsneurala nätverk (CNN), sekventiellt återkommande neurala nätverk (RNN) och transformatorbaserade kodare.
En av de viktigaste utmaningarna för BCAI-MLSL-partnerskapet var att tillhandahålla robusta och rimliga prognoser under påverkan av COVID-19, en global händelse utan motstycke som orsakar stor volatilitet i globala företags finansiella resultat. Eftersom neurala prognosmakare är utbildade på historiska data, kan de prognoser som genereras baserat på out-of-distribution data från de mer flyktiga perioderna vara felaktiga och opålitliga. Därför föreslog vi tillägget av en maskerad uppmärksamhetsmekanism i Transformer-arkitekturen för att lösa detta problem.
De neurala prognosmakarna kan kombineras som en ensemblemodell eller integreras individuellt i Boschs modelluniversum och lätt nås via REST API-slutpunkter. Vi föreslår ett tillvägagångssätt för att ensemble neurala prognosmakare genom backtestresultat, vilket ger konkurrenskraftig och robust prestanda över tid. Dessutom undersökte och utvärderade vi ett antal klassiska hierarkiska avstämningstekniker för att säkerställa att prognoser aggregeras konsekvent över produktgrupper, geografier och affärsorganisationer.
I det här inlägget visar vi följande:
- Hur man tillämpar Forecast och SageMaker anpassade modellträning för hierarkiska, storskaliga tidsserieprognosproblem
- Hur man sammanställer anpassade modeller med hyllmodeller från Forecast
- Hur man minskar effekten av störande händelser som covid-19 på prognosproblem
- Hur man bygger ett end-to-end prognosarbetsflöde på AWS
Utmaningar
Vi tog oss an två utmaningar: att skapa hierarkiska, storskaliga intäktsprognoser och effekten av covid-19-pandemin på långsiktiga prognoser.
Hierarkisk, storskalig intäktsprognoser
Finansanalytiker har till uppgift att prognostisera finansiella nyckeltal, inklusive intäkter, driftskostnader och FoU-utgifter. Dessa mätvärden ger affärsplaneringsinsikter på olika nivåer av aggregering och möjliggör datadrivet beslutsfattande. Varje automatiserad prognoslösning måste tillhandahålla prognoser på alla godtyckliga nivåer av affärslinjeaggregation. Hos Bosch kan aggregeringarna föreställas som grupperade tidsserier som en mer generell form av hierarkisk struktur. Följande figur visar ett förenklat exempel med en struktur på två nivåer, som efterliknar den hierarkiska intäktsprognosstrukturen hos Bosch. Den totala intäkten är uppdelad i flera nivåer av aggregering baserat på produkt och region.
Det totala antalet tidsserier som behöver prognostiseras hos Bosch är i miljonskala. Lägg märke till att tidsserierna på toppnivå kan delas upp efter antingen produkter eller regioner, vilket skapar flera vägar till prognoser på bottennivån. Intäkten måste prognostiseras vid varje nod i hierarkin med en prognoshorisont på 12 månader framåt i tiden. Månatlig historisk data finns tillgänglig.
Den hierarkiska strukturen kan representeras med hjälp av följande form med notationen av en summeringsmatris S (Hyndman och Athanasopoulos):
![]()
I denna ekvation, Y är lika med följande:

Här, b representerar bottennivåns tidsserie vid tidpunkten t.
Effekterna av covid-19-pandemin
Covid-19-pandemin medförde betydande utmaningar för prognoser på grund av dess störande och aldrig tidigare skådade effekter på nästan alla aspekter av arbete och socialt liv. För långsiktig intäktsprognoser medförde störningen också oväntade nedströmseffekter. För att illustrera detta problem visar följande figur ett exempel på tidsserier där produktintäkterna upplevde en betydande nedgång i början av pandemin och gradvis återhämtade sig efteråt. En typisk neural prognosmodell kommer att ta intäktsdata inklusive covid-perioden utanför distributionen (OOD) som den historiska kontextinmatningen, såväl som grundsanningen för modellträning. Till följd av detta är de framtagna prognoserna inte längre tillförlitliga.

Modelleringsmetoder
I det här avsnittet diskuterar vi våra olika modelleringsmetoder.
Amazon Prognos
Forecast är en fullt hanterad AI/ML-tjänst från AWS som tillhandahåller förkonfigurerade, toppmoderna tidsserieprognosmodeller. Den kombinerar dessa erbjudanden med dess interna möjligheter för automatisk hyperparameteroptimering, ensemblemodellering (för modellerna som tillhandahålls av Forecast) och probabilistisk prognosgenerering. Detta gör att du enkelt kan mata in anpassade datauppsättningar, förbearbeta data, träna prognosmodeller och generera robusta prognoser. Tjänstens modulära design gör det möjligt för oss att enkelt fråga och kombinera förutsägelser från ytterligare anpassade modeller utvecklade parallellt.
Vi har två neurala prognosinstrument från Forecast: CNN-QR och DeepAR+. Båda är övervakade metoder för djupinlärning som tränar en global modell för hela tidsseriedataset. Både CNNQR- och DeepAR+-modellerna kan ta in statisk metadatainformation om varje tidsserie, som är motsvarande produkt, region och affärsorganisation i vårt fall. De lägger också automatiskt till tidsmässiga funktioner som månad på året som en del av indata till modellen.
Transformator med uppmärksamhetsmasker för COVID
Transformatorarkitekturen (Vaswani et al.), ursprungligen designad för naturlig språkbehandling (NLP), framstod nyligen som ett populärt arkitektoniskt val för tidsserieprognoser. Här använde vi Transformer-arkitekturen som beskrivs i Zhou et al. utan probabilistisk logg sparsam uppmärksamhet. Modellen använder en typisk arkitekturdesign genom att kombinera en kodare och en avkodare. För intäktsprognoser konfigurerar vi avkodaren att direkt mata ut prognosen för 12-månadershorisonten istället för att generera prognosen månad för månad på ett autoregressivt sätt. Baserat på frekvensen av tidsserien, läggs ytterligare tidsrelaterade funktioner som månad på året till som indatavariabel. Ytterligare kategoriska variabler som beskriver metainformationen (produkt, region, affärsorganisation) matas in i nätverket via ett träningsbart inbäddningslager.
Följande diagram illustrerar transformatorarkitekturen och uppmärksamhetsmaskeringsmekanismen. Uppmärksamhetsmaskering tillämpas i alla kodar- och avkodarskikt, som markerats i orange, för att förhindra att OOD-data påverkar prognoserna.

Vi mildrar effekten av OOD-kontextfönster genom att lägga till uppmärksamhetsmasker. Modellen är tränad att lägga väldigt lite uppmärksamhet på covid-perioden som innehåller extremvärden via maskering, och utför prognoser med maskerad information. Uppmärksamhetsmasken appliceras i varje lager av dekoder- och kodararkitekturen. Det maskerade fönstret kan antingen specificeras manuellt eller genom en algoritm för detektering av extremvärden. Dessutom, när du använder ett tidsfönster som innehåller extremvärden som träningsetiketter, sprids inte förlusterna tillbaka. Denna uppmärksamhetsmaskningsbaserade metod kan användas för att hantera störningar och OOD-fall orsakade av andra sällsynta händelser och förbättra prognosernas robusthet.
Modellensemble
Modellensemblen överträffar ofta enskilda modeller för prognoser – den förbättrar modellens generaliserbarhet och är bättre på att hantera tidsseriedata med varierande egenskaper i periodicitet och intermittens. Vi införlivar en serie modellensemblestrategier för att förbättra modellens prestanda och robusthet i prognoser. En vanlig form av modellensemble för djupinlärning är att samla resultat från modellkörningar med olika slumpmässiga viktinitieringar, eller från olika träningsepoker. Vi använder denna strategi för att få prognoser för transformatormodellen.
För att ytterligare bygga en ensemble ovanpå olika modellarkitekturer, såsom Transformer, CNNQR och DeepAR+, använder vi en pan-modell ensemblestrategi som väljer de topp-k bäst presterande modellerna för varje tidsserie baserat på backtestresultaten och erhåller deras medelvärden. Eftersom backtestresultat kan exporteras direkt från utbildade Forecast-modeller, gör denna strategi det möjligt för oss att dra fördel av nyckelfärdiga tjänster som Forecast med förbättringar från anpassade modeller som Transformer. En sådan end-to-end-modellensemblemetod kräver inte utbildning av en meta-lärare eller beräkning av tidsseriefunktioner för modellval.
Hierarkisk försoning
Ramverket är anpassningsbart för att införliva ett brett spektrum av tekniker som efterbearbetningssteg för hierarkisk prognosavstämning, inklusive bottom-up (BU), top-down avstämning med prognosproportioner (TDFP), ordinär minsta kvadrat (OLS) och viktad minsta kvadrat ( WLS). Alla experimentella resultat i det här inlägget rapporteras med avstämning uppifrån och ned med prognostiserade proportioner.
Arkitekturöversikt
Vi utvecklade ett automatiserat end-to-end-arbetsflöde på AWS för att generera intäktsprognoser med hjälp av tjänster inklusive Forecast, SageMaker, Amazon enkel lagringstjänst (Amazon S3), AWS Lambda, AWS stegfunktioneroch AWS Cloud Development Kit (AWS CDK). Den distribuerade lösningen tillhandahåller individuella tidsserieprognoser genom ett REST API som använder Amazon API Gateway, genom att returnera resultaten i fördefinierat JSON-format.
Följande diagram illustrerar arbetsflödet för prognoser från början till slut.

Viktiga designöverväganden för arkitekturen är mångsidighet, prestanda och användarvänlighet. Systemet bör vara tillräckligt mångsidigt för att införliva en mångsidig uppsättning algoritmer under utveckling och driftsättning, med minimala nödvändiga ändringar, och kan enkelt utökas när nya algoritmer läggs till i framtiden. Systemet bör också lägga till minimal overhead och stödja parallelliserad träning för både Forecast och SageMaker för att minska träningstiden och få den senaste prognosen snabbare. Slutligen bör systemet vara enkelt att använda för experimentändamål.
Arbetsflödet från slut till ände löper sekventiellt genom följande moduler:
- En förbearbetningsmodul för omformatering och transformation av data
- En modellutbildningsmodul som innehåller både Prognosmodellen och anpassad modell på SageMaker (båda körs parallellt)
- En efterbehandlingsmodul som stöder modellensemble, hierarkisk avstämning, mätvärden och rapportgenerering
Step Functions organiserar och orkestrerar arbetsflödet från ände till slut som en tillståndsmaskin. Tillståndsmaskinkörningen konfigureras med en JSON-fil som innehåller all nödvändig information, inklusive platsen för de historiska intäkts-CSV-filerna i Amazon S3, prognosens starttid och inställningar för modellhyperparameter för att köra arbetsflödet från slut till slut. Asynkrona anrop skapas för att parallellisera modellträning i tillståndsmaskinen med hjälp av Lambda-funktioner. All historisk data, konfigurationsfiler, prognosresultat, såväl som mellanresultat som backtesting-resultat lagras i Amazon S3. REST-API:et är byggt ovanpå Amazon S3 för att tillhandahålla ett frågebart gränssnitt för sökning av prognosresultat. Systemet kan utökas för att införliva nya prognosmodeller och stödjande funktioner som att generera prognosvisualiseringsrapporter.
Utvärdering
I det här avsnittet beskriver vi experimentinställningen. Nyckelkomponenter inkluderar datamängden, utvärderingsstatistik, backtestfönster och modellinställning och utbildning.
dataset
För att skydda Boschs ekonomiska integritet samtidigt som vi använder en meningsfull datauppsättning använde vi en syntetisk datauppsättning som har liknande statistiska egenskaper som en verklig intäktsdatauppsättning från en affärsenhet hos Bosch. Datauppsättningen innehåller totalt 1,216 2016 tidsserier med intäkter registrerade i en månatlig frekvens, som täcker januari 2022 till april 877. Datauppsättningen levereras med XNUMX tidsserier på den mest granulära nivån (nedre tidsserien), med en motsvarande grupperad tidsseriestruktur representerad som en summeringsmatris S. Varje tidsserie är associerad med tre statiska kategoriska attribut, som motsvarar produktkategori, region och organisationsenhet i den verkliga datamängden (anonymiserad i den syntetiska datan).
Utvärderingsvärden
Vi använder median-Mean Arctangent Absolute Percentage Error (median-MAAPE) och viktad-MAAPE för att utvärdera modellens prestanda och utföra jämförande analys, vilket är standardmåtten som används hos Bosch. MAAPE åtgärdar bristerna i MAP-måttet (Mean Absolute Percentage Error) som vanligtvis används i affärssammanhang. Median-MAAPE ger en översikt över modellens prestanda genom att beräkna medianen för MAAPEs individuellt beräknade för varje tidsserie. Weighted-MAAPE rapporterar en viktad kombination av de individuella MAAPE:erna. Vikterna är andelen av intäkterna för varje tidsserie jämfört med den aggregerade intäkten för hela datamängden. Weighted-MAAPE återspeglar bättre nedströms affärseffekter av prognostiseringsnoggrannheten. Båda måtten rapporteras på hela datamängden med 1,216 XNUMX tidsserier.
Backtest-fönster
Vi använder rullande 12-månaders baktestfönster för att jämföra modellprestanda. Följande figur illustrerar backtest-fönstren som används i experimenten och belyser motsvarande data som används för träning och hyperparameteroptimering (HPO). För backtest-fönster efter att COVID-19 startar, påverkas resultatet av OOD-indata från april till maj 2020, baserat på vad vi observerade från intäktstidsserien.

Modelluppsättning och utbildning
För Transformer-träning använde vi kvantilförlust och skalade varje tidsserie med dess historiska medelvärde innan vi matade in den i Transformer och beräknade träningsförlusten. De slutliga prognoserna skalas tillbaka för att beräkna noggrannhetsmåtten, med hjälp av MeanScaler implementerad i GluonTS. Vi använder ett sammanhangsfönster med månatlig intäktsdata från de senaste 18 månaderna, vald via HPO i backtest-fönstret från juli 2018 till juni 2019. Ytterligare metadata om varje tidsserie i form av statiska kategoriska variabler matas in i modellen via en inbäddning lagret innan det matas till transformatorlagren. Vi tränar Transformatorn med fem olika slumpmässiga viktinitieringar och snittar prognosresultaten från de tre senaste epokerna för varje körning, totalt i genomsnitt 15 modeller. De fem modellträningskörningarna kan parallelliseras för att minska träningstiden. För den maskerade Transformer anger vi månaderna från april till maj 2020 som extremvärden.
För all Forecast-modellutbildning aktiverade vi automatisk HPO, som kan välja modell och träningsparametrar baserat på en användarspecificerad backtestperiod, som är inställd på de senaste 12 månaderna i datafönstret som används för träning och HPO.
Experimentresultat
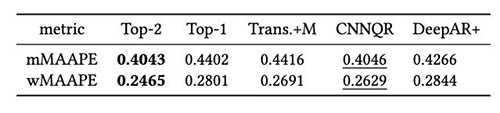
Vi tränar maskerade och omaskerade transformatorer med samma uppsättning hyperparametrar och jämförde deras prestanda för backtest-fönster direkt efter COVID-19-chock. I den maskerade Transformer är de två maskerade månaderna april och maj 2020. Följande tabell visar resultaten från en serie backtest-perioder med 12-månaders prognosfönster från juni 2020. Vi kan observera att den maskerade Transformer konsekvent överträffar den omaskerade versionen .

Vi utförde vidare utvärdering av modellensemblestrategin baserat på backtestresultat. I synnerhet jämför vi de två fallen då endast den bäst presterande modellen väljs mot när de två bäst presterande modellerna väljs, och modellmedelvärdesberäkning utförs genom att beräkna medelvärdet för prognoserna. Vi jämför prestanda för basmodellerna och ensemblemodellerna i följande figurer. Lägg märke till att ingen av de neurala prognosmakarna konsekvent överträffar andra för de rullande bakåttestfönstren.


Följande tabell visar att ensemblemodellering av de två översta modellerna i genomsnitt ger bäst prestanda. CNNQR ger det näst bästa resultatet.
Slutsats
Det här inlägget demonstrerade hur man bygger en heltäckande ML-lösning för storskaliga prognosproblem genom att kombinera Forecast och en anpassad modell utbildad på SageMaker. Beroende på dina affärsbehov och ML-kunskaper kan du använda en helt hanterad tjänst som Forecast för att ladda ner bygg-, tränings- och implementeringsprocessen för en prognosmodell; bygg din anpassade modell med specifika inställningsmekanismer med SageMaker; eller utför modellsammansättning genom att kombinera de två tjänsterna.
Om du vill ha hjälp med att påskynda användningen av ML i dina produkter och tjänster, vänligen kontakta Amazon ML Solutions Lab programmet.
Referensprojekt
Hyndman RJ, Athanasopoulos G. Prognos: principer och praxis. OTexter; 2018 maj 8.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Uppmärksamhet är allt du behöver. Framsteg inom neurala informationsbehandlingssystem. 2017;30.
Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, Zhang W. Informatör: Beyond effektiv transformator för långa sekvenser av tidsserier. InProceedings of AAAI 2021 2 feb.
Om författarna
 Goktug Cinar är en ledande ML-forskare och teknisk ledare för ML och statistikbaserad prognos vid Robert Bosch LLC och Bosch Center for Artificial Intelligence. Han leder forskningen av prognosmodeller, hierarkisk konsolidering och modellkombinationstekniker samt mjukvaruutvecklingsteamet som skalar dessa modeller och tjänar dem som en del av den interna end-to-end finansiell prognosmjukvara.
Goktug Cinar är en ledande ML-forskare och teknisk ledare för ML och statistikbaserad prognos vid Robert Bosch LLC och Bosch Center for Artificial Intelligence. Han leder forskningen av prognosmodeller, hierarkisk konsolidering och modellkombinationstekniker samt mjukvaruutvecklingsteamet som skalar dessa modeller och tjänar dem som en del av den interna end-to-end finansiell prognosmjukvara.
 Michael Binder är produktägare på Bosch Global Services, där han koordinerar utvecklingen, driftsättningen och implementeringen av den företagsomfattande applikationen för prediktiv analys för storskalig automatiserad datadriven prognos av finansiella nyckeltal.
Michael Binder är produktägare på Bosch Global Services, där han koordinerar utvecklingen, driftsättningen och implementeringen av den företagsomfattande applikationen för prediktiv analys för storskalig automatiserad datadriven prognos av finansiella nyckeltal.
 Adrian Horvath är en mjukvaruutvecklare på Bosch Center for Artificial Intelligence, där han utvecklar och underhåller system för att skapa förutsägelser baserade på olika prognosmodeller.
Adrian Horvath är en mjukvaruutvecklare på Bosch Center for Artificial Intelligence, där han utvecklar och underhåller system för att skapa förutsägelser baserade på olika prognosmodeller.
 Panpan Xu är senior tillämpad forskare och chef med Amazon ML Solutions Lab på AWS. Hon arbetar med forskning och utveckling av Machine Learning-algoritmer för högeffektiva kundapplikationer i en mängd olika industriella vertikaler för att påskynda deras AI- och molninförande. Hennes forskningsintresse inkluderar modelltolkbarhet, kausalanalys, human-in-the-loop AI och interaktiv datavisualisering.
Panpan Xu är senior tillämpad forskare och chef med Amazon ML Solutions Lab på AWS. Hon arbetar med forskning och utveckling av Machine Learning-algoritmer för högeffektiva kundapplikationer i en mängd olika industriella vertikaler för att påskynda deras AI- och molninförande. Hennes forskningsintresse inkluderar modelltolkbarhet, kausalanalys, human-in-the-loop AI och interaktiv datavisualisering.
 Jasleen Grewal är en tillämpad forskare på Amazon Web Services, där hon arbetar med AWS-kunder för att lösa verkliga problem med hjälp av maskininlärning, med särskilt fokus på precisionsmedicin och genomik. Hon har en stark bakgrund inom bioinformatik, onkologi och klinisk genomik. Hon brinner för att använda AI/ML och molntjänster för att förbättra patientvården.
Jasleen Grewal är en tillämpad forskare på Amazon Web Services, där hon arbetar med AWS-kunder för att lösa verkliga problem med hjälp av maskininlärning, med särskilt fokus på precisionsmedicin och genomik. Hon har en stark bakgrund inom bioinformatik, onkologi och klinisk genomik. Hon brinner för att använda AI/ML och molntjänster för att förbättra patientvården.
 Selvan Senthivel är Senior ML Engineer med Amazon ML Solutions Lab på AWS, med fokus på att hjälpa kunder med maskininlärning, djupinlärningsproblem och end-to-end ML-lösningar. Han var en av grundarna av Amazon Comprehend Medical och bidrog till designen och arkitekturen av flera AWS AI-tjänster.
Selvan Senthivel är Senior ML Engineer med Amazon ML Solutions Lab på AWS, med fokus på att hjälpa kunder med maskininlärning, djupinlärningsproblem och end-to-end ML-lösningar. Han var en av grundarna av Amazon Comprehend Medical och bidrog till designen och arkitekturen av flera AWS AI-tjänster.
 Ruilin Zhang är en SDE med Amazon ML Solutions Lab på AWS. Han hjälper kunder att använda AWS AI-tjänster genom att bygga lösningar för att lösa vanliga affärsproblem.
Ruilin Zhang är en SDE med Amazon ML Solutions Lab på AWS. Han hjälper kunder att använda AWS AI-tjänster genom att bygga lösningar för att lösa vanliga affärsproblem.
 Shane Rai är en Sr. ML-strateg med Amazon ML Solutions Lab på AWS. Han arbetar med kunder inom ett brett spektrum av branscher för att lösa deras mest pressande och innovativa affärsbehov med hjälp av AWS:s bredd av molnbaserade AI/ML-tjänster.
Shane Rai är en Sr. ML-strateg med Amazon ML Solutions Lab på AWS. Han arbetar med kunder inom ett brett spektrum av branscher för att lösa deras mest pressande och innovativa affärsbehov med hjälp av AWS:s bredd av molnbaserade AI/ML-tjänster.
 Lin Lee Cheong är en Applied Science Manager med Amazon ML Solutions Lab-teamet på AWS. Hon arbetar med strategiska AWS-kunder för att utforska och tillämpa artificiell intelligens och maskininlärning för att upptäcka nya insikter och lösa komplexa problem.
Lin Lee Cheong är en Applied Science Manager med Amazon ML Solutions Lab-teamet på AWS. Hon arbetar med strategiska AWS-kunder för att utforska och tillämpa artificiell intelligens och maskininlärning för att upptäcka nya insikter och lösa komplexa problem.